使用索引和切片完成下列操作, 创建如下图所示列表 [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]] 在上述列表的基础上通过索引切片创建如下图所示列表 [[44, 43, 42, 41, 40], [24, 23, 22, 21, 20]]
时间: 2023-08-18 08:29:52 浏览: 24
可以通过以下代码完成操作:
```
# 创建原始列表
lst = [[i+j*10 for i in range(5)] for j in range(5)]
print(lst)
# 使用索引切片创建新列表
new_lst = [lst[-1::-1][i][-1::-1] for i in range(2)]
print(new_lst)
```
输出结果为:
```
[[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]]
[[44, 43, 42, 41, 40], [24, 23, 22, 21, 20]]
```
解释一下代码:
首先使用列表生成式创建原始列表 `lst`,然后使用索引切片 `[-1::-1]` 将其翻转,再次使用索引切片 `[-1::-1]` 取出需要的两个子列表,即为新列表 `new_lst`。
相关问题
使用索引和切片完成下列操作 创建如下图所示列表 [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]] 在上述列表的基础上通过索引切片创建如下图所示列表 [[44, 43, 42, 41, 40], [24, 23, 22, 21, 20]]
创建如下列表:
```python
lst = [[j+i*5 for j in range(5)] for i in range(5)]
print(lst)
```
输出:
```
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19], [20, 21, 22, 23, 24]]
```
使用索引切片创建如下列表:
```python
lst_slice = [lst[-1::-1][i][-1::-1] for i in range(4, 2, -1)]
print(lst_slice)
```
输出:
```
[[44, 43, 42, 41, 40], [24, 23, 22, 21, 20]]
```
其中,`lst[-1::-1]` 是将原列表倒序,然后使用切片 `[i][-1::-1]` 获取需要的部分。
使用索引和切片完成下列操作,如果使用列表推导有加分 创建如下图所示列表 [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]]
1. 获取第二行第三个元素,即 12
```
lst = [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]]
element = lst[1][2]
print(element)
```
2. 获取第四行第一列到第三列的元素,即 [30, 31, 32]
```
lst = [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]]
row = lst[3]
elements = row[0:3]
print(elements)
```
3. 获取第一列所有元素,即 [0, 10, 20, 30, 40]
```
lst = [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]]
column = [row[0] for row in lst]
print(column)
```
4. 获取第二行所有元素,即 [10, 11, 12, 13, 14]
```
lst = [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]]
row = lst[1]
print(row)
```
5. 获取第三列所有元素,即 [2, 12, 22, 32, 42]
```
lst = [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34], [40, 41, 42, 43, 44]]
column = [row[2] for row in lst]
print(column)
```
使用列表推导的方式:
```
lst = [[i*5+j for j in range(5)] for i in range(5)]
print(lst)
```
输出:
```
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15, 16, 17, 18, 19], [20, 21, 22, 23, 24]]
```
相关推荐
最新推荐
Python中列表和元组的使用方法和区别详解
- 列表使用方括号`[]`来创建,如`[1, 2, 3]`。 - 元组使用圆括号`()`来创建,如`(1, 2, 3)`。值得注意的是,当元组只包含一个元素时,需要在元素后跟逗号,如`(1,)`,以避免与普通括号混淆。 在选择使用列表还是...
mysql 中存在null和空时创建唯一索引的方法
据库默认值都有null,此时创建唯一索引时要注意了,此时数据库会把空作为多个重复值
SQL优化基础 使用索引(一个小例子)
综上所述,SQL优化的核心在于合理地创建和使用索引。非聚集索引能减少全表扫描,组合索引可以针对多字段查询优化,而覆盖索引则能在不回表的情况下提供所需数据,减少额外的I/O操作。在实际应用中,应根据查询条件和...
C语言实现带头结点的链表的创建、查找、插入、删除操作
在C语言中,创建链表首先需要定义一个结构体来表示链表节点,包含数据域`data`和指向下一个节点的指针`next`。创建带头结点的链表时,需要分配一个头结点并将其`next`指针设置为`NULL`。以下代码展示了如何创建一个...
Python——列表的基本操作
列表:在python中,如果存储多个数据用列表。...接下来,我们可以向列表中添加元素,我们先来看下列表的内存地址,使用id()函数可查看列表中保存元素所在的内存地址,我们先重新定义一个含有元素的列表。 name = [] a =
图书馆管理系统数据库设计与功能详解
"图书馆管理系统数据库设计.pdf"
图书馆管理系统数据库设计是一项至关重要的任务,它涉及到图书信息、读者信息、图书流通等多个方面。在这个系统中,数据库的设计需要满足各种功能需求,以确保图书馆的日常运营顺畅。
首先,系统的核心是安全性管理。为了保护数据的安全,系统需要设立权限控制,允许管理员通过用户名和密码登录。管理员具有全面的操作权限,包括添加、删除、查询和修改图书信息、读者信息,处理图书的借出、归还、逾期还书和图书注销等事务。而普通读者则只能进行查询操作,查看个人信息和图书信息,但不能进行修改。
读者信息管理模块是另一个关键部分,它包括读者类型设定和读者档案管理。读者类型设定允许管理员定义不同类型的读者,比如学生、教师,设定他们可借阅的册数和续借次数。读者档案管理则存储读者的基本信息,如编号、姓名、性别、联系方式、注册日期、有效期限、违规次数和当前借阅图书的数量。此外,系统还包括了借书证的挂失与恢复功能,以防止丢失后图书的不当借用。
图书管理模块则涉及图书的整个生命周期,从基本信息设置、档案管理到征订、注销和盘点。图书基本信息设置包括了ISBN、书名、版次、类型、作者、出版社、价格、现存量和库存总量等详细信息。图书档案管理记录图书的入库时间,而图书征订用于订购新的图书,需要输入征订编号、ISBN、订购数量和日期。图书注销功能处理不再流通的图书,这些图书的信息会被更新,不再可供借阅。图书查看功能允许用户快速查找特定图书的状态,而图书盘点则是为了定期核对库存,确保数据准确。
图书流通管理模块是系统中最活跃的部分,它处理图书的借出和归还流程,包括借阅、续借、逾期处理等功能。这个模块确保了图书的流通有序,同时通过记录借阅历史,方便读者查询自己的借阅情况和超期还书警告。
图书馆管理系统数据库设计是一个综合性的项目,涵盖了用户认证、信息管理、图书操作和流通跟踪等多个层面,旨在提供高效、安全的图书服务。设计时需要考虑到系统的扩展性、数据的一致性和安全性,以满足不同图书馆的具体需求。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
表锁问题全解析:深度解读,轻松解决
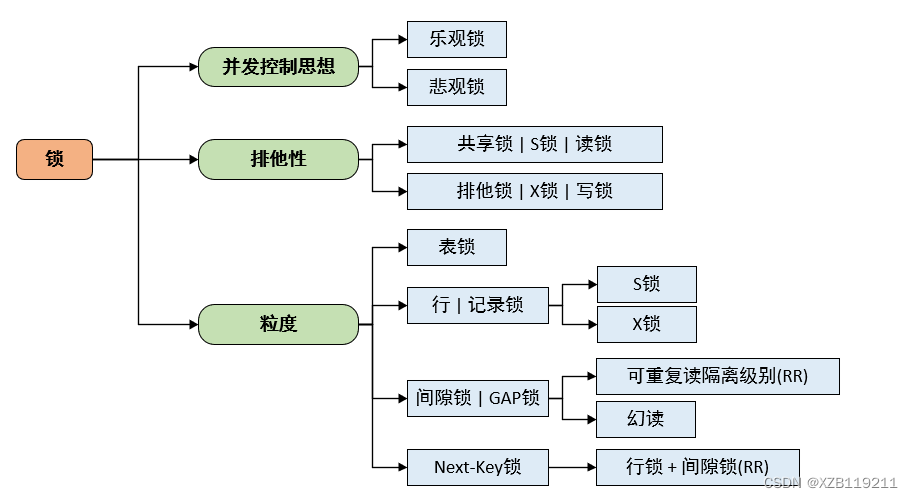
# 1. 表锁基础**
表锁是一种数据库并发控制机制,用于防止多个事务同时修改同一行或表,从而保证数据的一致性和完整性。表锁的工作原理是通过在表或行上设置锁,当一个事务需要访问被锁定的数据时,它必须等待锁被释放。
表锁分为两种类型:行锁和表锁。行锁只锁定被访问的行,而表锁锁定整个表。行锁的粒度更细,可以提高并发性,但开销也更大。表锁的粒度更粗,开销较小,但并发性较低。
表锁还分为共享锁和排他锁。共享锁允许多个事务同时
麻雀搜索算法SSA优化卷积神经网络CNN
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种生物启发式的优化算法,它模拟了麻雀觅食的行为,用于解决复杂的优化问题,包括在深度学习中调整神经网络参数以提高性能。在卷积神经网络(Convolutional Neural Networks, CNN)中,SSA作为一种全局优化方法,可以应用于网络架构搜索、超参数调优等领域。
在CNN的优化中,SSA通常会:
1. **构建种群**:初始化一组随机的CNN结构或参数作为“麻雀”个体。
2. **评估适应度**:根据每个网络在特定数据集上的性能(如验证集上的精度或损失)来评估其适应度。
3. **觅食行为**:模仿
***物流有限公司仓储配送业务SOP详解
"该文档是***物流有限公司的仓储配送业务SOP管理程序,包含了工作职责、操作流程、各个流程的详细步骤,旨在规范公司的仓储配送管理工作,提高效率和准确性。"
在物流行业中,标准操作程序(SOP)是确保业务流程高效、一致和合规的关键。以下是对文件中涉及的主要知识点的详细解释:
1. **工作职责**:明确各岗位人员的工作职责和责任范围,是确保业务流程顺畅的基础。例如,配送中心主管负责日常业务管理、费用控制、流程监督和改进;发运管理员处理运输调配、计划制定、5S管理;仓管员负责货物的收发存管理、质量控制和5S执行;客户服务员则处理客户指令、运营单据和物流数据管理。
2. **操作流程**:文件详细列出了各项操作流程,包括**入库及出库配送流程**,强调了从接收到发货的完整过程,包括验收、登记、存储、拣选、包装、出库等环节,确保货物的安全和准确性。
3. **仓库装卸作业流程**:详细规定了货物装卸的操作步骤,包括使用设备、安全措施、作业标准,以防止货物损坏并提高作业效率。
4. **货物在途跟踪及异常情况处理流程**:描述了如何监控货物在运输途中的状态,以及遇到异常如延误、丢失或损坏时的应对措施,确保货物安全并及时处理问题。
5. **单据流转及保管流程**:规定了从订单创建到完成的单据处理流程,包括记录、审核、传递和存档,以保持信息的准确性和可追溯性。
6. **存货管理**:涵盖了库存控制策略,如先进先出(FIFO)、定期盘点、库存水平的优化,以避免过度库存或缺货。
7. **仓库标志流程**:明确了仓库内的标识系统,帮助员工快速定位货物,提高作业效率。
8. **仓库5S管理及巡检流程**:5S(整理、整顿、清扫、清洁、素养)是提高仓库环境和工作效率的重要工具,巡检流程则确保了5S的持续实施。
9. **仓库建筑设备设施的维护流程**:强调了设备设施的定期检查、保养和维修,以保证其正常运行,避免因设备故障导致的运营中断。
10. **附件清单**:列出所有相关的附件和表格,便于员工参考和执行。
通过这些详尽的SOP,***物流有限公司能够系统化地管理仓储配送业务,确保服务质量,减少错误,提升客户满意度,并为公司的持续改进提供基础。