用python代码实现爬取自己嘉兴10日内的天气预报
时间: 2024-01-26 16:24:24 浏览: 27
好的,以下是示例代码:
```python
import requests
from bs4 import BeautifulSoup
url = 'http://www.weather.com.cn/weather/101210301.shtml' # 嘉兴市天气预报页面的链接
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
days = soup.select('.day') # 获取未来7天的日期
weathers = soup.select('.wea') # 获取未来7天的天气状况
temperatures = soup.select('.tem') # 获取未来7天的温度区间
for i in range(7):
print(days[i].text, weathers[i].text, temperatures[i].text)
```
运行此代码即可输出嘉兴市未来7天的天气预报。如果需要获取10天内的预报,则需要修改链接中的数字,例如:
- 101210301:嘉兴市
- 101210401:桐乡市
- 101210412:海宁市
- 101210403:嘉善县
- 101210404:海盐县
根据需要选择对应的数字即可。
相关问题
用python代码实现爬取自己嘉兴10日内的天气预报并生成一个网站
好的,以下是一个简单的Python爬虫示例,可以爬取嘉兴市某个气象网站的天气预报数据,并将数据存储到本地的SQLite数据库中。同时,还可以使用Flask框架开发一个简单的天气预报网站,展示最近10天的天气信息。
1. 确定数据来源:我们可以使用中国天气网(http://www.weather.com.cn)提供的天气预报数据,具体的URL是:http://www.weather.com.cn/weather/101210301.shtml
2. 编写爬虫程序:我们可以使用Python的requests和BeautifulSoup库来实现爬虫程序。具体的代码如下:
```python
import requests
from bs4 import BeautifulSoup
import sqlite3
# 爬取天气预报数据
def get_weather_data():
url = 'http://www.weather.com.cn/weather/101210301.shtml'
r = requests.get(url)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
# 获取最近10天的天气预报数据
weather_list = []
for i in range(1, 11):
date_str = soup.select_one(f'#day_{i} > h1').text
date = date_str.split('(')[0]
weather = soup.select_one(f'#day_{i} > p.wea').text
temperature = soup.select_one(f'#day_{i} > p.tem').text
weather_list.append((date, weather, temperature))
return weather_list
# 存储天气预报数据到SQLite数据库
def save_to_database(weather_list):
conn = sqlite3.connect('weather.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS weather
(date text, weather text, temperature text)''')
c.execute('DELETE FROM weather')
c.executemany('INSERT INTO weather VALUES (?, ?, ?)', weather_list)
conn.commit()
conn.close()
if __name__ == '__main__':
weather_list = get_weather_data()
save_to_database(weather_list)
```
3. 开发网站:我们可以使用Flask框架来实现一个简单的天气预报网站。具体的代码如下:
```python
from flask import Flask, render_template
import sqlite3
app = Flask(__name__)
# 获取天气预报数据
def get_weather_data():
conn = sqlite3.connect('weather.db')
c = conn.cursor()
c.execute('SELECT * FROM weather')
weather_list = c.fetchall()
conn.close()
return weather_list
# 渲染天气预报网站页面
@app.route('/')
def index():
weather_list = get_weather_data()
return render_template('index.html', weather_list=weather_list)
if __name__ == '__main__':
app.run()
```
4. 前端设计:我们可以使用HTML和CSS来实现网站页面的设计,同时使用Jinja2模板来渲染数据。具体的代码如下:
```html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>嘉兴天气预报</title>
<style>
table {
border-collapse: collapse;
width: 80%;
margin: auto;
}
th, td {
border: 1px solid black;
text-align: center;
padding: 10px;
}
th {
background-color: #f2f2f2;
}
</style>
</head>
<body>
<h1>嘉兴天气预报</h1>
<table>
<tr>
<th>日期</th>
<th>天气</th>
<th>温度</th>
</tr>
{% for weather in weather_list %}
<tr>
<td>{{ weather[0] }}</td>
<td>{{ weather[1] }}</td>
<td>{{ weather[2] }}</td>
</tr>
{% endfor %}
</table>
</body>
</html>
```
5. 部署网站:将以上代码保存到一个目录中,启动Python虚拟环境,安装所需的依赖库,并运行`python app.py`即可启动网站。需要注意的是,生产环境中应该使用Gunicorn或者uWSGI等Web服务器来部署网站,并使用Nginx或者Apache等反向代理服务器进行负载均衡和安全保护。
以上是一个简单的Python爬虫和网站开发示例,具体的实现过程可能会有所不同。希望对您有所帮助。
python爬取自己家乡10日内的天气预报
好的,这个问题可以使用 Python 中的 requests 和 BeautifulSoup 库来实现。首先需要找到一个提供天气预报信息的网站,例如中国天气网。
以下是一个简单的代码示例,可以爬取中国天气网上自己家乡10日内的天气预报:
```python
import requests
from bs4 import BeautifulSoup
# 设置城市名称和城市代码
city_name = "xxx" # 替换成你自己的城市名称
city_code = "xxx" # 替换成你自己的城市代码
# 构造请求URL
url = f"http://www.weather.com.cn/weather/{city_code}.shtml"
# 发送请求
response = requests.get(url)
# 解析HTML内容
soup = BeautifulSoup(response.content, "html.parser")
weather_items = soup.find_all("div", class_="t")
# 输出未来10天的天气预报
for item in weather_items:
date = item.find("h1").text
weather = item.find(class_="wea").text
temperature = item.find(class_="tem").text.strip()
print(f"{date},{weather},{temperature}")
```
需要注意的是,每个城市的代码不同,需要根据实际情况进行替换。
相关推荐
最新推荐
Python爬取数据并实现可视化代码解析
主要介绍了Python爬取数据并实现可视化代码解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
Python3 实现爬取网站下所有URL方式
今天小编就为大家分享一篇Python3 实现爬取网站下所有URL方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
python实现网络爬虫 爬取北上广深的天气数据报告 python.docx
该资源是python实现网络爬虫 爬取北上广深的天气数据的报告 注:可用于期末大作业实验报告
Python爬虫实现爬取百度百科词条功能实例
本文实例讲述了Python爬虫实现爬取百度百科词条功能。分享给大家供大家参考,具体如下: 爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。爬虫从一个或若干初始网页的URL开始...
Python selenium爬取微信公众号文章代码详解
主要介绍了Python selenium爬取微信公众号历史文章代码详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
工业AI视觉检测解决方案.pptx
工业AI视觉检测解决方案.pptx是一个关于人工智能在工业领域的具体应用,特别是针对视觉检测的深入探讨。该报告首先回顾了人工智能的发展历程,从起步阶段的人工智能任务失败,到专家系统的兴起到深度学习和大数据的推动,展示了人工智能从理论研究到实际应用的逐步成熟过程。
1. 市场背景:
- 人工智能经历了从计算智能(基于规则和符号推理)到感知智能(通过传感器收集数据)再到认知智能(理解复杂情境)的发展。《中国制造2025》政策强调了智能制造的重要性,指出新一代信息技术与制造技术的融合是关键,而机器视觉因其精度和效率的优势,在智能制造中扮演着核心角色。
- 随着中国老龄化问题加剧和劳动力成本上升,以及制造业转型升级的需求,机器视觉在汽车、食品饮料、医药等行业的渗透率有望提升。
2. 行业分布与应用:
- 国内市场中,电子行业是机器视觉的主要应用领域,而汽车、食品饮料等其他行业的渗透率仍有增长空间。海外市场则以汽车和电子行业为主。
- 然而,实际的工业制造环境中,由于产品种类繁多、生产线场景各异、生产周期不一,以及标准化和个性化需求的矛盾,工业AI视觉检测的落地面临挑战。缺乏统一的标准和模型定义,使得定制化的解决方案成为必要。
3. 工业化前提条件:
- 要实现工业AI视觉的广泛应用,必须克服标准缺失、场景多样性、设备技术不统一等问题。理想情况下,应有明确的需求定义、稳定的场景设置、统一的检测标准和安装方式,但现实中这些条件往往难以满足,需要通过技术创新来适应不断变化的需求。
4. 行业案例分析:
- 如金属制造业、汽车制造业、PCB制造业和消费电子等行业,每个行业的检测需求和设备技术选择都有所不同,因此,解决方案需要具备跨行业的灵活性,同时兼顾个性化需求。
总结来说,工业AI视觉检测解决方案.pptx着重于阐述了人工智能如何在工业制造中找到应用场景,面临的挑战,以及如何通过标准化和技术创新来推进其在实际生产中的落地。理解这个解决方案,企业可以更好地规划AI投入,优化生产流程,提升产品质量和效率。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL运维最佳实践:经验总结与建议
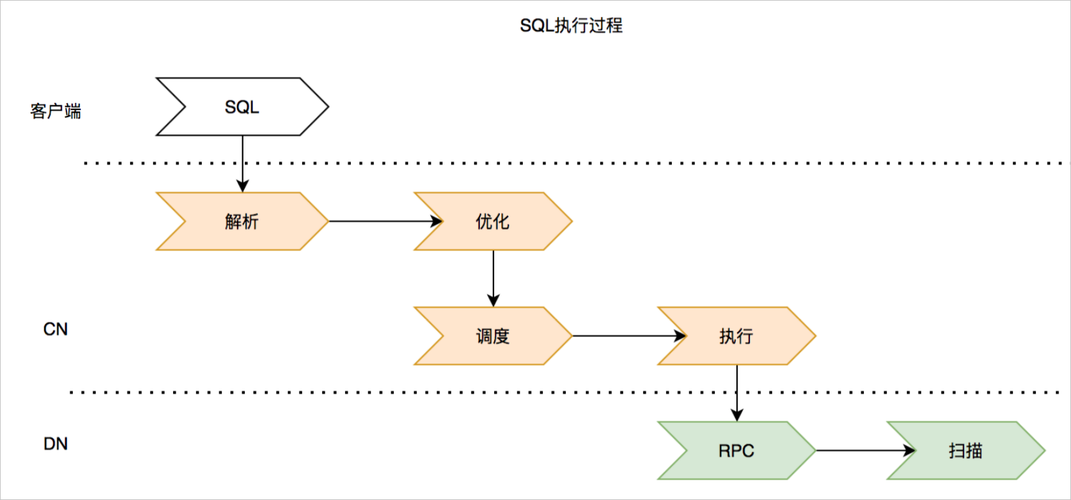
# 1. MySQL运维基础**
MySQL运维是一项复杂而重要的任务,需要深入了解数据库技术和最佳实践。本章将介绍MySQL运维的基础知识,包括:
- **MySQL架构和组件:**了解MySQL的架构和主要组件,包括服务器、客户端和存储引擎。
- **MySQL安装和配置:**涵盖MySQL的安装过
stata面板数据画图
Stata是一个统计分析软件,可以用来进行数据分析、数据可视化等工作。在Stata中,面板数据是一种特殊类型的数据,它包含了多个时间段和多个个体的数据。面板数据画图可以用来展示数据的趋势和变化,同时也可以用来比较不同个体之间的差异。
在Stata中,面板数据画图有很多种方法。以下是其中一些常见的方法
智慧医院信息化建设规划及愿景解决方案.pptx
"智慧医院信息化建设规划及愿景解决方案.pptx"
在当今信息化时代,智慧医院的建设已经成为提升医疗服务质量和效率的重要途径。本方案旨在探讨智慧医院信息化建设的背景、规划与愿景,以满足"健康中国2030"的战略目标。其中,"健康中国2030"规划纲要强调了人民健康的重要性,提出了一系列举措,如普及健康生活、优化健康服务、完善健康保障等,旨在打造以人民健康为中心的卫生与健康工作体系。
在建设背景方面,智慧医院的发展受到诸如分级诊疗制度、家庭医生签约服务、慢性病防治和远程医疗服务等政策的驱动。分级诊疗政策旨在优化医疗资源配置,提高基层医疗服务能力,通过家庭医生签约服务,确保每个家庭都能获得及时有效的医疗服务。同时,慢性病防治体系的建立和远程医疗服务的推广,有助于减少疾病发生,实现疾病的早诊早治。
在规划与愿景部分,智慧医院的信息化建设包括构建完善的电子健康档案系统、健康卡服务、远程医疗平台以及优化的分级诊疗流程。电子健康档案将记录每位居民的动态健康状况,便于医生进行个性化诊疗;健康卡则集成了各类医疗服务功能,方便患者就医;远程医疗技术可以跨越地域限制,使优质医疗资源下沉到基层;分级诊疗制度通过优化医疗结构,使得患者能在合适的层级医疗机构得到恰当的治疗。
在建设内容与预算方面,可能涉及硬件设施升级(如医疗设备智能化)、软件系统开发(如电子病历系统、预约挂号平台)、网络基础设施建设(如高速互联网接入)、数据安全与隐私保护措施、人员培训与技术支持等多个方面。预算应考虑项目周期、技术复杂性、维护成本等因素,以确保项目的可持续性和效益最大化。
此外,"互联网+医疗健康"的政策支持鼓励创新,智慧医院信息化建设还需要结合移动互联网、大数据、人工智能等先进技术,提升医疗服务的便捷性和精准度。例如,利用AI辅助诊断、物联网技术监控患者健康状态、区块链技术保障医疗数据的安全共享等。
智慧医院信息化建设是一项系统工程,需要政府、医疗机构、技术供应商和社会各方共同参与,以实现医疗服务质量的提升、医疗资源的优化配置,以及全民健康水平的提高。在2023年的背景下,这一进程将进一步加速,为我国的医疗健康事业带来深远影响。