from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score iris = datasets.lond_iris() iris_X = iris.data iris_y = iris.target X_train,X_test,y_train,y_test = train_test_split(iris_X,iris_y,test_sizo=0.3) knn = KNeighborsClassifier () knn.fit(X_train,y_train) y_knn = knn.predict(X_test) print('分类器得到的分类:\ n ',y_knn) print('真实分类:\ n ',y_test) print('准确率为:',accuracy_score(y_test,y_knn))改写成sklearn库的支持向量机算法对iris数据集进行分类,用python
时间: 2023-12-24 14:11:21 浏览: 24
可以改写成以下代码:
```
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)
svm = SVC()
svm.fit(X_train, y_train)
y_svm = svm.predict(X_test)
print('分类器得到的分类:\n', y_svm)
print('真实分类:\n', y_test)
print('准确率为:', accuracy_score(y_test, y_svm))
```
这里使用的是支持向量机算法进行分类,其他代码和 K 近邻算法的实现类似,只需要将 KNeighborsClassifier 改成 SVC 即可。
相关问题
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score # 导入数据集 data = pd.read_csv("1.csv") # 分割特征和标签 X = data.iloc[:, :-1] y = data.iloc[:, -1] # 将数据集分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建KNN分类器 knn = KNeighborsClassifier(n_neighbors=3) # 训练模型 knn.fit(X_train, y_train) # 预测测试集 y_pred = knn.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy) # 假设有一个新的样本 [5.1, 3.5, 1.4] new_sample = [[1, 27, 19]] # 使用训练好的KNN分类器进行预测 pred = knn.predict(new_sample) # 输出预测结果 print("预测结果:", pred)写一个和这个类似的代码
好的,这里是一个类似的代码,使用Iris数据集进行KNN分类器的训练和预测。与您提供的代码不同的是,这个代码使用了Iris数据集的原始数据而不是从CSV文件中读取数据,并且使用了交叉验证来评估分类器的性能。
```python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建KNN分类器
knn = KNeighborsClassifier(n_neighbors=3)
# 使用交叉验证评估分类器性能
scores = cross_val_score(knn, X_train, y_train, cv=5)
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = knn.score(X_test, y_test)
print("Accuracy:", accuracy)
# 假设有一个新的样本 [5.1, 3.5, 1.4, 0.2]
new_sample = [[5.1, 3.5, 1.4, 0.2]]
# 使用训练好的KNN分类器进行预测
pred = knn.predict(new_sample)
# 输出预测结果
print("预测结果:", iris.target_names[pred])
```
该代码会输出KNN分类器在测试集上的准确率,并且会基于训练好的分类器对一个新的样本进行预测,并输出预测结果。
import pandas as pd from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.feature_selection import SelectKBest, f_classif from sklearn.decomposition import PCA from sklearn.metrics import accuracy_score, classification_report from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score from sklearn.ensemble import RandomForestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC data = load_wine() # 导入数据集 X = pd.DataFrame(data.data, columns=data.feature_names) y = pd.Series(data.target) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) # 构建分类模型 model = LogisticRegression() model.fit(X_train, y_train) # 预测测试集结果 y_pred = model.predict(X_test) #评估模型性能 accuracy = accuracy_score(y_test, y_pred) report = classification_report(y_test, y_pred) print('准确率:', accuracy) # 特征选择 selector = SelectKBest(f_classif, k=6) X_new = selector.fit_transform(X, y) print('所选特征:', selector.get_support()) # 模型降维 pca = PCA(n_components=2) X_new = pca.fit_transform(X_new) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X_new, y, test_size=0.2, random_state=0) def Sf(model,X_train, X_test, y_train, y_test,modelname): mode = model() mode.fit(X_train, y_train) y_pred = mode.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(modelname, accuracy) importance = mode.feature_importances_ print(importance) def Sf1(model,X_train, X_test, y_train, y_test,modelname): mode = model() mode.fit(X_train, y_train) y_pred = mode.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(modelname, accuracy) modelname='支持向量机' Sf1(SVC,X_train, X_test, y_train, y_test,modelname) modelname='逻辑回归' Sf1(LogisticRegression,X_train, X_test, y_train, y_test,modelname) modelname='高斯朴素贝叶斯算法训练分类器' Sf1(GaussianNB,X_train, X_test, y_train, y_test,modelname) modelname='K近邻分类' Sf1(KNeighborsClassifier,X_train, X_test, y_train, y_test,modelname) modelname='决策树分类' Sf(DecisionTreeClassifier,X_train, X_test, y_train, y_test,modelname) modelname='随机森林分类' Sf(RandomForestClassifier,X_train, X_test, y_train, y_test,modelname)加一个画图展示
抱歉,由于我是一个纯文本AI,无法进行画图展示。但是,你可以使用Python中的matplotlib库进行数据可视化。例如,你可以使用以下代码绘制特征重要性条形图:
import matplotlib.pyplot as plt
importance = mode.feature_importances_
features = list(X.columns)
plt.barh(features, importance)
plt.title('Feature Importance')
plt.xlabel('Importance')
plt.show()
这段代码可以在Sf函数中的print(importance)下方添加,并在运行时展示特征重要性条形图。
相关推荐
最新推荐
电信塔施工方案.doc
5G通信行业、网络优化、通信工程建设资料。
29-【智慧城市与政府治理分会场】10亿大数据助推都市治理-30页.pdf
29-【智慧城市与政府治理分会场】10亿大数据助推都市治理-30页.pdf
ABB IRC5 Compact 机器人产品手册
ABB IRC5 Compact 机器人产品手册
LTE容量优化高负荷小区优化指导书.docx
5G通信行业、网络优化、通信工程建设资料
施工工艺及质量检查记录表.docx
5G通信行业、网络优化、通信工程建设资料。
RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
REALTEK 8188FTV 8188eus 8188etv linux驱动程序稳定版本, 支持AP,STA 以及AP+STA 共存模式。 稳定支持linux4.0以上内核。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
:YOLOv1目标检测算法:实时目标检测的先驱,开启计算机视觉新篇章
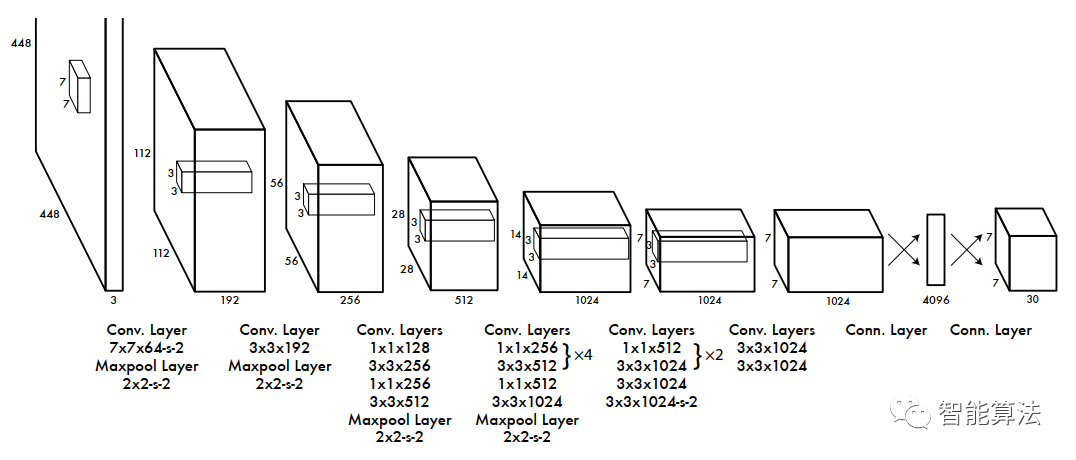
# 1. 目标检测算法概述
目标检测算法是一种计算机视觉技术,用于识别和定位图像或视频中的对象。它在各种应用中至关重要,例如自动驾驶、视频监控和医疗诊断。
目标检测算法通常分为两类:两阶段算法和单阶段算法。两阶段算法,如 R-CNN 和 Fast R-CNN,首先生成候选区域,然后对每个区域进行分类和边界框回归。单阶段算法,如 YOLO 和 SSD,一次性执行检
ActionContext.getContext().get()代码含义
ActionContext.getContext().get() 是从当前请求的上下文对象中获取指定的属性值的代码。在ActionContext.getContext()方法的返回值上,调用get()方法可以获取当前请求中指定属性的值。
具体来说,ActionContext是Struts2框架中的一个类,它封装了当前请求的上下文信息。在这个上下文对象中,可以存储一些请求相关的属性值,比如请求参数、会话信息、请求头、应用程序上下文等等。调用ActionContext.getContext()方法可以获取当前请求的上下文对象,而调用get()方法可以获取指定属性的值。
例如,可以使用 Acti
c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
校园超市商品信息管理系统课程设计旨在帮助学生深入理解程序设计的基础知识,同时锻炼他们的实际操作能力。通过设计和实现一个校园超市商品信息管理系统,学生掌握了如何利用计算机科学与技术知识解决实际问题的能力。在课程设计过程中,学生需要对超市商品和销售员的关系进行有效管理,使系统功能更全面、实用,从而提高用户体验和便利性。
学生在课程设计过程中展现了积极的学习态度和纪律,没有缺勤情况,演示过程流畅且作品具有很强的使用价值。设计报告完整详细,展现了对问题的深入思考和解决能力。在答辩环节中,学生能够自信地回答问题,展示出扎实的专业知识和逻辑思维能力。教师对学生的表现予以肯定,认为学生在课程设计中表现出色,值得称赞。
整个课程设计过程包括平时成绩、报告成绩和演示与答辩成绩三个部分,其中平时表现占比20%,报告成绩占比40%,演示与答辩成绩占比40%。通过这三个部分的综合评定,最终为学生总成绩提供参考。总评分以百分制计算,全面评估学生在课程设计中的各项表现,最终为学生提供综合评价和反馈意见。
通过校园超市商品信息管理系统课程设计,学生不仅提升了对程序设计基础知识的理解与应用能力,同时也增强了团队协作和沟通能力。这一过程旨在培养学生综合运用技术解决问题的能力,为其未来的专业发展打下坚实基础。学生在进行校园超市商品信息管理系统课程设计过程中,不仅获得了理论知识的提升,同时也锻炼了实践能力和创新思维,为其未来的职业发展奠定了坚实基础。
校园超市商品信息管理系统课程设计的目的在于促进学生对程序设计基础知识的深入理解与掌握,同时培养学生解决实际问题的能力。通过对系统功能和用户需求的全面考量,学生设计了一个实用、高效的校园超市商品信息管理系统,为用户提供了更便捷、更高效的管理和使用体验。
综上所述,校园超市商品信息管理系统课程设计是一项旨在提升学生综合能力和实践技能的重要教学活动。通过此次设计,学生不仅深化了对程序设计基础知识的理解,还培养了解决实际问题的能力和团队合作精神。这一过程将为学生未来的专业发展提供坚实基础,使其在实际工作中能够胜任更多挑战。