【代码一致性保证】:GitHub多仓库同步机制的终极指南
发布时间: 2024-12-06 15:55:02 阅读量: 101 订阅数: 24 

cole_02_0507.pdf
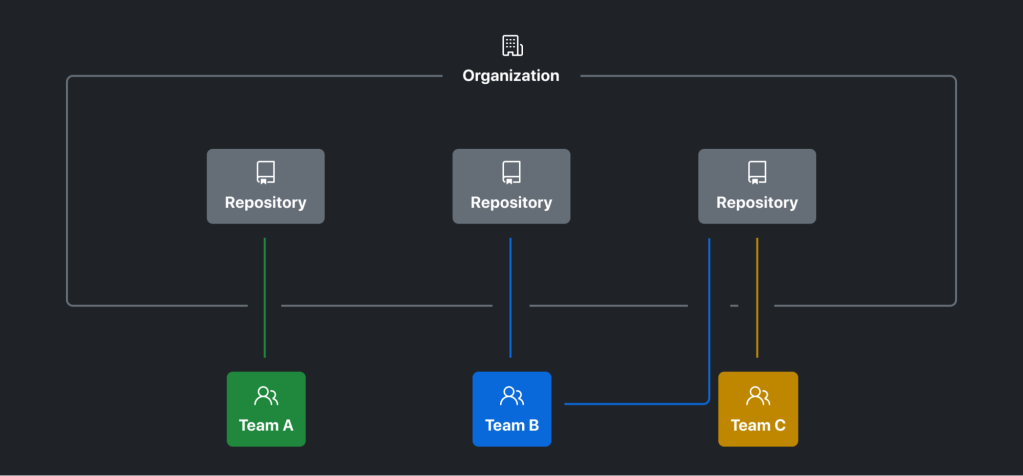
# 1. 代码一致性保证的重要性
在现代软件开发过程中,代码一致性是确保软件质量和维护性的关键因素之一。随着开发团队规模的扩大和项目复杂性的增加,保持代码的一致性变得越来越具有挑战性。代码一致性不仅仅是指代码风格的统一,更重要的是确保各个开发环境、分支和版本之间的代码变更能够同步更新,减少因版本差异而导致的错误和不一致性。
## 1.1 对团队协作的影响
当团队成员在不同的分支上工作时,如果缺乏有效的同步机制,很容易导致代码冲突和重复工作。这种情况下,团队成员需要花费大量时间来解决冲突,严重影响了开发效率和团队士气。
## 1.2 对软件质量的影响
代码一致性能够确保在整个项目中应用同样的编程标准和逻辑,从而提高代码的可读性、可维护性和可扩展性。这有助于减少潜在的bug,提高软件的整体质量。
## 1.3 对代码管理的影响
有效的一致性保证策略可以帮助开发者更轻松地管理代码变更历史,追溯特定功能或错误修复的来源。这样不仅有利于版本控制,也使得代码审查过程更加高效和精确。
在下一章,我们将深入探讨GitHub多仓库同步的理论基础,理解其在保证代码一致性方面所扮演的关键角色。
# 2. GitHub多仓库同步的理论基础
### 2.1 版本控制系统的同步机制
#### 2.1.1 版本控制概念
版本控制是一种记录文件或代码随时间变化的方式,它允许多个人协同工作,同时追踪和管理对源代码的每一次修改。版本控制系统(VCS)在软件开发中占据核心地位,不仅保证了代码的历史记录完整性,还提供了分支、合并以及回滚到先前版本的能力。在多仓库同步的语境下,版本控制变成了多仓库间保持一致性和协作的关键技术。
#### 2.1.2 同步原理与方法
同步机制是指在多个仓库之间保持数据一致性的技术或过程。常见的原理包括:
- **拉取(Pull)**:从远程仓库获取最新的更改并合并到本地仓库。
- **推送(Push)**:将本地仓库的更改发送到远程仓库。
- **合并(Merge)**:将两个或多个分支的更改合并到一个分支中。
- **变基(Rebase)**:重新应用一系列提交,通常用于同步分支并保持历史线性。
### 2.2 Git在多仓库环境中的作用
#### 2.2.1 Git的核心概念
Git是一个分布式版本控制系统,它的核心概念包括:
- **仓库(Repository)**:存储项目元数据和对象数据库的目录。
- **提交(Commit)**:代表更改集合的一个节点,包含提交信息、作者信息和指向父提交的指针。
- **分支(Branch)**:一个轻量级的指向提交快照的指针。
- **远程仓库(Remote)**:版本库的一个副本,位于远程服务器上。
Git的设计哲学让其成为管理多仓库同步的理想选择,能够应对复杂的同步需求。
#### 2.2.2 Git在代码一致性中的应用
Git在保持代码一致性方面发挥着至关重要的作用。它使用哈希函数来唯一标识每个提交,确保了内容的完整性。此外,Git的合并和变基操作使得开发者能够在保持代码线性历史的同时,同步不同分支上的更改。
### 2.3 同步策略的分类
#### 2.3.1 基于分支的同步策略
分支是代码隔离和实验的理想选择,基于分支的同步策略允许开发者在主分支之外的分支上工作,然后将更改合并回主分支。这种方式促进了并行开发,但需要仔细的分支管理和同步策略来避免冲突。
#### 2.3.2 基于标签的同步策略
标签用于标记特定时间点的项目状态,通常在发布版本时使用。基于标签的同步策略允许团队同步到特定版本,同时在不影响主开发线的情况下继续开发新特性。
```mermaid
graph LR
A[开始] --> B[创建分支]
B --> C[开发更改]
C --> D[提交更改]
D --> E[合并回主分支]
E --> F[发布标签]
F --> G[同步到标签]
```
以上是一个简化的流程图,展示了基于分支和标签的同步策略的基本步骤。每一步骤都有可能涉及复杂的操作,因此需要明确的策略指导和自动化工具的支持。
# 3. GitHub多仓库同步实践指南
为了实现多仓库同步,我们不仅需要理解理论基础,还需要通过实践来搭建和优化同步环境。本章节将详细探讨如何搭建GitHub多仓库同步环境,编写同步脚本,并实现与优化同步策略。
## 3.1 搭建多仓库同步环境
### 3.1.1 初始化本地仓库
在开始同步之前,首先需要在本地初始化一个新的Git仓库。这通常涉及以下步骤:
```bash
# 创建一个新的目录作为项目根目录
mkdir myproject
cd myproject
# 初始化Git仓库
git init
# 添加远程仓库地址,这里以GitHub为例
git remote add origin https://github.com/user/myproject.git
# 验证远程仓库地址是否添加成功
git remote -v
```
上述步骤会创建一个新的本地Git仓库,并将其与远程GitHub仓库关联起来。`git init`命令用于初始化仓库,而`git remote add`命令则用于设置远程仓库的名称(默认为`origin`)和URL。
### 3.1.2 连接远程仓库
在本地仓库初始化之后,我们需要设置一个远程仓库以便同步。这里需要注意的是,对于多仓库同步,可能需要连接多个远程仓库。
```bash
# 添加额外的远程仓库
git remote add other-origin https://github.com/user/otherproject.git
# 将本地分支推送到新的远程仓库
git push -u other-origin master
```
在上述操作中,`git remote add`命令用于添加第二个远程仓库`other-origin`。随后,我们可以使用`git push`命令将本地的`master`分支内容推送到新的远程仓库。
## 3.2 编写同步脚本
### 3.2.1 使用Shell脚本自动化同步过程
为了简化多仓库同步过程,可以编写Shell脚本来自动化这一流程。下面是一个简单的示例脚本:
```bash
#!/bin/bash
# 定义远程仓库变量
REMOTE1="https://github.com/user/myproject.git"
REMOTE2="https://github.com/user/otherproject.git"
# 克隆远程仓库
git clone $REMOTE1
cd myproject
git remote add other-origin $REMOTE2
# 拉取所有分支
git fetch --all
# 这里可以添加更多的同步逻辑
# ...
# 切换到目标分支
git checkout master
# 合并远程分支到本地分支
git merge other-origin/master
# 推送到远程仓库
git push origin master
```
在这个脚本中,我们定义了两个远程仓库的URL,并克隆了第一个远程仓库。接着,我们添加了第二个远程仓库,并同步了所有分支。最后,我们切换到`master`分支,并将第二个远程仓库的`master`分支合并到本地`master`分支,然后推送到第一个远程仓库。
### 3.2.2 脚本中常见的逻辑处理
在脚本的同步逻辑中,我们可能会遇到各种情况,比如合并冲突。因此,脚本需要有处理这些情况的逻辑。下面是一个处理合并冲突的示例:
```bash
# 假设在合并过程中发生冲突
if [ $? -ne 0 ]; then
echo "Merge conflict detected, please resolve it manually."
exit 1
fi
```
上述脚本片段在合并操作失败后(即合并冲突发生时)提示用户手动解决冲突,并终止脚本的进一步执行。这是一种常见的错误处理逻辑。
## 3.3 同步策略的实现与优化
### 3.3.1 同步策略的实现
在实现同步策略时,需要考虑的关键点包括如何保持代码的实时性、如何避免数据丢失以及如何处理潜在的冲突。下面是一个基于分支的同步策略实现示例:
```mermaid
graph LR
A[本地仓库] -->|推送| B[远程仓库1]
A -->|推送| C[远程仓库2]
B -->|拉取| A
C -->|拉取| A
```
在上述流程中,我们通过`git push`和`git pull`操作将本地仓库与多个远程仓库进行同步。Mermaid流程图展示了本地仓库与两个远程仓库之间的同步关系。
### 3.3.2 同步过程中性能与一致性的平衡
在同步过程中,我们面临性能和一致性之间的权衡。为了提高性能,可以使用`git fetch --depth`命令来限制克隆的提交历史深度,减少网络传输的数据量。
```bash
# 仅获取最近的20次提交
git fetch --depth 20
```
然而,减少提交历史的深度可能会影响一致性检查的准确性,因此需要在性能优化和数据一致性之间找到一个合理的平衡点。
# 4. 高级同步技术与工具
在前面的章节中,我们已经探讨了GitHub多仓库同步的基础知识,并且通过实践指南逐步了解了如何搭建同步环境以及编写同步脚本。在本章中,我们将深入探讨一些高级同步技术与工具,这些技术与工具能够帮助我们更好地实现自动化、高效和稳定的同步流程。
## 4.1 使用GitHub Actions自动化同步
### 4.1.1 GitHub Actions的基本使用
GitHub Actions是GitHub提供的自动化工具,它允许开发者自动化软件开发工作流程,从而在代码提交、合并请求以及在不同的事件发生时执行自定义脚本或命令。使用GitHub Actions进行自动化同步主要包括以下步骤:
1. 在GitHub仓库中创建一个新的`.github/workflows`目录。
2. 在该目录下创建一个`.yml`文件,这将定义一个工作流。
3. 编写工作流文件,指定触发条件、任务和运行环境。
以下是一个简单的GitHub Actions工作流示例:
```yaml
name: Sync Repositories
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
sync-repos:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Sync repositories
run: |
# 这里可以放置同步脚本的命令
./sync-repos.sh
```
工作流在`on`字段中定义了触发条件,即在`main`分支上的`push`或`pull_request`操作时触发。
### 4.1.2 配置自定义的同步工作流
创建自定义工作流的关键在于根据项目需求编写脚本。下面是一个`sync-repos.sh`脚本的示例,它使用SSH密钥进行认证来同步代码:
```bash
#!/bin/bash
# 设置远程仓库信息
Remote1=git@github.com:user/repo1.git
Remote2=git@github.com:user/repo2.git
# 设置本地仓库目录
Repo1Path=/path/to/local/repo1
Repo2Path=/path/to/local/repo2
# 使用SSH进行同步
git -C "$Repo1Path" pull $Remote1
git -C "$Repo2Path" pull $Remote2
```
在GitHub Actions中运行此脚本时,需要确保环境中有必要的SSH密钥。可以通过GitHub Secrets来安全地存储和使用私钥。
## 4.2 采用第三方工具优化同步
### 4.2.1 第三方同步工具的选择与配置
除了GitHub Actions,还有许多第三方工具可以用来优化代码同步。这些工具包括但不限于:
- **Snyk**: 用于检测代码中的安全漏洞。
- **Dependabot**: 自动创建pull request来更新依赖项。
- **Renovate**: 类似于Dependabot,但提供更多的自定义选项。
配置这些工具通常涉及将它们添加到GitHub仓库的设置中,并根据需要提供配置参数。例如,使用Dependabot来自动更新依赖项可以这样配置:
```yaml
version: 2
updates:
- package-ecosystem: "npm"
directory: "/"
schedule:
interval: "daily"
```
### 4.2.2 工具在复杂环境下的同步实践
在复杂的同步环境中,可能需要处理多个分支、多个仓库以及不同类型的依赖项。在这种情况下,重要的是确保每个工具都能正确地配置以满足特定需求。例如,在使用Snyk时,可能需要配置特定的策略来忽略已知的、不影响安全的漏洞。这可以通过在仓库中添加`.snyk`文件来实现:
```yaml
version: 1
ignore:
unsaved: false
paths:
- "myIgnoredFolder/**"
issues:
- name: "npm:Prototype Pollution"
justification: "This is a known issue with a library we use."
```
这个配置告诉Snyk忽略`myIgnoredFolder`文件夹中的特定漏洞。
## 4.3 处理合并冲突与代码审查
### 4.3.1 合并冲突的自动与手动解决
自动化同步过程中不可避免地会遇到合并冲突。处理这些冲突的一种方法是使用工具来自动解决它们。例如,使用`git merge`命令时可以带上`--strategy-option=theirs`参数:
```bash
git merge origin/main --strategy-option=theirs
```
这会自动以远程分支为准来解决冲突。然而,这种方法并不总是理想的,因为它可能会导致数据丢失。在处理复杂的冲突时,手动解决通常是更安全的选择。
### 4.3.2 利用代码审查保证代码质量
代码审查是保证代码质量的重要环节,即使在自动化同步的环境下也不例外。GitHub本身提供了Pull Request功能,可以集成到同步工作流中来实现代码审查。在审查过程中,可以检查代码变更是否符合项目的编码标准,并确保改动不会引入新的问题。
总结来说,高级同步技术与工具可以帮助我们实现更高效、更安全的同步流程,但同时也要求开发者具备更深入的了解和精细的配置能力。通过在实践中不断优化和调整这些工具和技术,我们可以达到事半功倍的效果。
# 5. 安全性和维护性考量
## 5.1 同步过程中的安全最佳实践
在代码库的同步过程中,安全是一个不可忽视的方面。随着代码库的共享和复制,未经授权访问的风险也相应增加。因此,在进行GitHub多仓库同步时,需要实施一系列安全最佳实践来保证数据的安全性和完整性。
### 5.1.1 访问权限管理
确保只有授权用户才能访问和修改代码库是至关重要的。Git提供了灵活的权限管理机制,可以通过访问控制列表(ACL)来控制对仓库的访问。在GitHub上,这一机制主要通过两种方式实现:团队和分支保护规则。
1. **团队管理权限** - 在组织中,可以创建不同的团队,并为每个团队分配对仓库的访问权限。例如,核心开发团队可能需要对所有分支有完全访问权限,而测试团队可能只需要读取权限。这种分级管理可以减少误操作的风险,并确保数据安全。
2. **分支保护规则** - 对于关键分支(如主分支),应设置分支保护规则以防止被直接推送。这包括要求代码通过拉取请求(Pull Request),经过审查和自动检查后,才能合并到主分支。
### 5.1.2 代码审计与合规性
代码审计是确保代码库安全性的关键过程。它涉及到检查代码是否存在安全漏洞、不良的编程实践,或者是非授权的代码变更。GitHub支持集成多种代码审查工具,这可以帮助识别潜在的问题。
1. **集成代码审查工具** - 可以将如SonarQube这样的静态代码分析工具集成到CI/CD流程中。这类工具能够对代码库进行自动化扫描,检测出潜在的安全问题和代码质量问题。
2. **合规性策略** - 不同的行业和公司可能有不同的合规性要求,如GDPR或HIPAA。GitHub提供了策略来帮助组织满足这些要求,例如通过保护个人信息和敏感数据。
## 5.2 同步系统的长期维护策略
### 5.2.1 定期同步与备份
为了保持多个仓库的同步,定期执行同步操作是必要的。此外,对于同步系统本身,定期备份是维护其稳定性和可用性的关键措施。
1. **定期执行同步** - 应当设置一个定期执行的同步计划,可以使用定时任务(cron job)或其他调度工具来自动化这一过程。这样做可以确保任何代码变更都被及时地推送到所有相关仓库。
2. **备份策略** - 备份不仅是数据恢复的基础,也是防止数据丢失的重要措施。同步系统需要一个有效的备份策略,确保数据安全并能快速恢复。这可能包括定期备份数据库和文件系统,以及使用版本控制历史记录作为备份的一部分。
### 5.2.2 持续集成与持续部署(CI/CD)的整合
同步代码库只是整个软件开发流程中的一环。为了确保代码能够顺利地从开发到生产的每一步都保持一致和安全,需要将同步机制整合到CI/CD流程中。
1. **CI/CD流程** - 通过自动化测试、代码构建和部署,CI/CD流程能够提高软件质量并加快开发周期。将同步逻辑集成到这个流程中,可以在代码变更后立即执行同步,确保所有环境(开发、测试、生产)中的代码保持最新和一致。
2. **自动化监控与报警** - 整合同步机制到CI/CD流程的同时,还需要实现监控和报警机制,以便在同步失败或出现异常情况时及时响应。这可能包括监控仓库状态、同步执行结果以及生产环境的健康状况。
以上内容已按照Markdown格式要求进行编排,并且包含了安全性和维护性方面的重要知识点。请根据这些内容,继续后续章节的创作。
# 6. 案例研究与未来展望
## 6.1 典型同步案例分析
### 6.1.1 开源项目的同步策略
在开源项目中,同步机制是保持多个贡献者代码一致性的关键。一个典型的案例是Linux内核的开发,该项目由全球成千上万的开发者共同维护。Linux内核使用了严格的分支管理策略,主分支(master或main)始终保持稳定和可发布的状态。
为了维持代码一致性,Linux内核采用了一种分层同步策略:
- **维护者合并分支**:贡献者提交的代码首先合并到维护者的个人分支上。
- **代码审查**:维护者在合并前进行代码审查,确保代码质量。
- **临时发布分支**:通过创建临时发布分支来测试和验证新功能或修复。
- **主分支合并**:经过充分测试和审查的代码最终合并到主分支。
此外,采用的自动化工具如`scripts/get_maintainer.pl`来辅助找出负责特定代码块的维护者,保证了同步的效率和准确性。
### 6.1.2 企业内部多仓库同步实例
在企业环境中,多仓库同步策略的实施可能会更加复杂,因为需要满足不同的业务需求和安全要求。以下是一个企业内部实施多仓库同步的案例:
- **基础架构**:企业内部使用GitLab作为代码托管服务,配合GitLab CI/CD工具。
- **同步策略**:使用GitLab的“派生仓库”功能,将主仓库的变更自动派生到各个团队的子仓库中。每个子仓库可以有自己的开发分支,但合并回主仓库前必须经过严格的测试和代码审查。
- **权限管理**:采用GitLab的权限管理功能,将不同的权限分配给不同角色的用户,例如将推送权限仅限于核心开发团队成员,而普通开发者仅有拉取权限。
- **自动化与优化**:利用GitLab CI/CD在代码提交后自动执行测试和部署流程,确保代码变更不会破坏现有功能。
## 6.2 GitHub同步机制的未来发展趋势
### 6.2.1 随着技术进步的潜在变化
随着技术的进步,尤其是在分布式系统和网络技术方面,GitHub的同步机制将会迎来以下变化:
- **性能优化**:通过改进的网络协议和更有效的数据压缩技术,实现更快的代码同步速度。
- **更智能的合并策略**:利用人工智能和机器学习技术,自动解决合并冲突和预测代码变更的潜在影响。
- **去中心化的同步模型**:随着区块链等技术的发展,未来的同步可能趋向去中心化,减少对中心服务器的依赖。
### 6.2.2 新兴工具和服务的影响
新兴的工具和服务也会对GitHub的同步机制产生影响:
- **持续集成与持续部署(CI/CD)工具**:集成更先进的CI/CD工具,以提供更灵活和高效的同步工作流。
- **代码审查工具**:更好的代码审查工具可以帮助维护者更高效地审查代码,确保代码质量。
- **开发环境集成**:与VS Code等开发环境更紧密的集成,允许开发者在编写代码的同时进行代码审查和同步操作,提高开发效率。
这些新兴工具和服务将推动GitHub同步机制的优化,使得软件开发过程更加流畅和高效。未来,开发者将能够在保持代码一致性的同时,享受到更加强大和智能化的同步体验。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 GitHub 多仓库管理策略,提供了一系列全面指南,帮助您优化项目管理、确保代码一致性、扩展项目规模、规划多仓库架构、提升团队协作、实现模块化管理、设计大型项目结构、管理分支、自动化依赖管理、监控和优化性能、分析依赖图以及优化仓库大小。通过遵循这些策略,您可以提升 GitHub 多仓库项目的效率、协作和可维护性。本专栏是 GitHub 项目管理人员和开发人员的必备资源,旨在帮助他们充分利用多仓库架构的优势,打造高效、可扩展且易于维护的软件系统。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
BT1120实践案例分析:如何在IT项目中成功实施新协议标准

# 摘要
本文系统地介绍了BT1120协议标准的各个方面,包括其技术框架、设计原则、网络通信机制、实施策略、案例分析以及未来展望。BT1120协议旨在提供一个安全、高效、可扩展的通信基
【文档从生到死】:10个关键点全面解读文档生命周期管理策略
# 摘要
文档生命周期管理涉及文档从创建、组织、使用、协作到维护和更新的全过程。本文全面概述了文档管理的各个方面,包括文档的创建原则、内容管理、组织存储、使用和协作策略、以及维护更新流程。特别强调了文档的访问权限管理、协作工具的选择、分发发布监控,以及自动化工具的应用对提高文档管理效率的重要性。此外,本文还探讨了文档管理的高级策略,如数据分析优化管理策略,以及云
【海康威视测温客户端使用手册】:全面覆盖操作详解与故障排除

# 摘要
海康威视测温客户端作为一款高效的体温监测工具,广泛应用于疫情防控等场景。本文首先概述了客户端的基本概念和安装配置要求,详细介绍了系统要求、安装
【变频器全攻略】:掌握变频器技术的7大实用技能,专家教你如何从零开始
# 摘要
变频器技术作为工业自动化领域中的一项重要技术,广泛应用于电机调速和节能降耗。本文首先概述了变频器技术的基本概念,然后深入探讨了其基础理论知识,包括工作原理、控制技术以及选型指南。接着,文章详细介绍了变频器的安装与调试流程,包括准备工作、安装步骤、参数设置、试运行和故障排除技巧。此外,还涉及了变频器的日常维护与故障处理方法,以及在节能降耗和网络通信中的高级应用。本文旨在为工程技术人员提供系统化的变频器知识,帮助他们在实际应用中更有效地
PowerDesigner关联设计宝典:从业务规则到数据模型优化
-%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D0%BD%D0%BE%D0%B9%2001.png)
# 摘要
本文综合探讨了PowerDesigner在业务规则关联设计、数据模型构建与优化以及高级关联设计技术等方面的应用
图像噪声分析:Imatest实战技巧大揭秘
# 摘要
图像噪声分析是评估图像质量的关键步骤,对提升成像系统的性能至关重要。本文首先介绍图像噪声分析的基础知识,然后详细阐述了Imatest软件的界面、功能以及如何解读图像质量指标,包括信噪比、动态范围和色彩还原度。通过分类讨论不同的噪声类型,本文揭示了随机噪声与固定模式噪声的特性和来源。接着,文中演示了如何使用Imatest进行噪声测量,并对测试设置、参数调整和结果解读进行了深入讲解。
栈与队列:C++数据结构实战,算法效率提升秘籍

# 摘要
本文深入探讨了栈与队列这两种基础数据结构的基本概念、在C++中的实现、在算法中的应用、以及如何优化算法效率。通过分析栈与队列的原理和特性,本文阐述了C++模板类Stack和Queue的实现细节,并通过实例展示了它们在深度优先搜索、表达式求值、广度优先搜索等算法中的应用。进一步地,本文探讨了栈与队列在操作系
【TP.VST69T.PB763性能提升攻略】:硬件升级的终极指南

# 摘要
本文旨在探讨TP.VST69T.PB763系统性能提升的全面方案。首先,概述了性能提升的必要性和总体思路,随后,深入分析了硬件升级的理论基础,包括硬件架构解析、升级的可行性与风险评估、性能测试与基准对比。核心硬件升级部分,详细介绍了处理器、内存和存储解决方案的升级策略及其实践中的注意事项。接着,探讨了外围设备与扩展能力的提升,包括显卡、网络通信模块以及外设扩
【PDF技术处理秘籍】:TI-LMK04832.pdf案例研究,快速上手
# 摘要
PDF(便携式文档格式)已成为全球范围内交换文档的标准格式之一。本文首先概述了PDF技术处理的基本知识,然后深入分析了PDF文件结构,包括其组成元素、逻辑组织、以及字体和图像处理技术。接着,文章探讨了PDF文档编辑和转换的实用技巧,包括文档的编辑、安全与权限设置,以及与其他格式的转换方法。进一步,本文研究了PDF自动化处理的高级应用
【角色建模大师课】:独门秘籍,打造游戏角色的生动魅力

# 摘要
游戏角色开发是游戏制作的核心部分,涉及到从基础建模到优化发布的一系列技术流程。本文首先介绍了游戏角色建模的基础知识和设计原则,强调了设计中的艺术性和功能性,以及如何将角色融入游戏世界观中。随后,文章深入探讨了游戏角色建模技术,包括基础工具的使用、高级建模技巧以及材质与贴图的制作。在角色动画与表现方面,本文分析了动画基础和高级技术,提供了动画实践案例以助理解。最后,本文重点讨论了游戏角色的优化与发布流程,确保角色在不
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )