Python基础入门:数据类型与变量
发布时间: 2023-12-11 11:23:24 阅读量: 36 订阅数: 49 

Python基础教程——变量类型
# 1. Python基础概述
## 1.1 Python简介
Python是一种高级、解释型、面向对象的编程语言。由Guido van Rossum于1991年首次发布。Python具有简洁、易读、易学的语法,被广泛应用于Web开发、科学计算、人工智能、数据分析等领域。
## 1.2 为什么学习Python
学习Python有以下几个理由:
- **简单易学**:Python语法简洁清晰,易于理解和学习,适合初学者入门。
- **广泛应用**:Python可以应用于各种领域,如Web开发、数据分析、人工智能等,拥有丰富的生态系统。
- **高效开发**:Python有很多强大的开发工具和框架,可以大幅提升开发效率。
- **大量资源**:Python有庞大的开源社区,提供丰富的资源和库供开发者使用。
## 1.3 Python的应用领域
Python在各个领域都有广泛的应用,包括但不限于:
- **Web开发**:Python的Web框架(如Django、Flask)可以快速构建高效的Web应用程序。
- **科学计算**:科学计算库(如NumPy、SciPy、Pandas)使Python成为了进行数据分析和科学研究的首选语言。
- **人工智能**:Python拥有多个流行的机器学习和深度学习库(如Scikit-Learn、TensorFlow、PyTorch),用于开发智能系统和算法。
- **自动化和脚本编写**:Python易于编写和执行脚本,可用于自动化任务、系统管理和网络编程。
- **游戏开发**:Python的游戏开发框架(如Pygame)使得编写游戏逻辑和图形化界面变得简单。
Python的应用领域非常广泛,它的简单性和可扩展性使得它成为开发者们喜爱的编程语言之一。在我们深入学习Python的基础知识之前,让我们先了解一下Python的数据类型与变量。
# 2. 数据类型
在Python中,数据类型是指变量所能容纳的数据的种类。Python提供了多种内置的数据类型,每种数据类型都有其特定的特点和使用方式。
### 2.1 数值类型
数值类型是Python中最基本的数据类型之一,它包括整型(int)和浮点型(float)。
整型是指不带小数点的数字,可以是正数、负数或零。比如`-3`、`0`、`5`都是整型。可以使用`type()`函数来查看一个变量的数据类型。
```python
x = 10
print(type(x)) # 输出:<class 'int'>
```
浮点型是指带有小数点的数字,可以是正数、负数或零。比如`3.14`、`-2.5`都是浮点型。
```python
y = 3.14
print(type(y)) # 输出:<class 'float'>
```
### 2.2 字符串类型
字符串类型(str)用于表示文本数据,以引号(单引号或双引号)包裹起来。比如`'Hello'`、`"Python"`都是字符串。
```python
s = 'Hello'
print(type(s)) # 输出:<class 'str'>
```
字符串可以通过索引和切片来访问其中的字符或子串。
```python
s = 'Hello Python'
print(s[0]) # 输出:H,索引从0开始
print(s[6:11]) # 输出:Python,切片包含开始索引,不包含结束索引
```
### 2.3 布尔类型
布尔类型(bool)用于表示真(True)或假(False)的值。
```python
b1 = True
b2 = False
print(type(b1)) # 输出:<class 'bool'>
print(b1 and b2) # 输出:False
print(b1 or b2) # 输出:True
print(not b1) # 输出:False
```
布尔类型常用于条件判断和逻辑运算。
### 2.4 列表、元组和字典
除了基本的数值类型和字符串类型外,Python还提供了一些复杂的数据类型,包括列表(list)、元组(tuple)和字典(dict)。
列表是一种有序的数据集合,可以包含任意类型的数据,用方括号(`[]`)表示。列表中的每个数据项是通过索引访问的。
```python
my_list = [1, 'a', True]
print(type(my_list)) # 输出:<class 'list'>
print(my_list[1]) # 输出:a
```
元组也是一种有序的数据集合,与列表类似,但是元组是不可变的,用圆括号(`()`)表示。
```python
my_tuple = (2, 'b', False)
print(type(my_tuple)) # 输出:<class 'tuple'>
print(my_tuple[2]) # 输出:False
```
字典是一种键值对(key-value)的数据集合,用花括号(`{}`)表示。每个键值对中的键和值之间使用冒号(`:`)分隔。
```python
my_dict = {'name': 'Alice', 'age': 25, 'gender': 'female'}
print(type(my_dict)) # 输出:<class 'dict'>
print(my_dict['name']) # 输出:Alice
```
以上是Python中常见的数据类型,它们在实际的编程过程中非常常用。理解和掌握不同的数据类型可以帮助我们更灵活地处理和操作数据。在后续的学习中,我们将会进一步探讨这些数据类型的使用方法。
# 3. 变量与赋值
#### 3.1 变量的定义与命名规范
在Python中,变量是用来存储数据的。当您创建一个变量时,您实际上正在分配内存空间,用于存储变量的值。
变量的命名需要遵循以下规范:
- 变量名只能包含字母、数字、下划线,且不能以数字开头。
- 变量名不能使用Python的关键字和保留字,如`if`、`else`、`for`等。
- 变量名是大小写敏感的,即`apple`和`Apple`是两个不同的变量名。
```python
# 合法的变量名示例
age = 25
name = "Alice"
is_student = True
total_marks_1 = 95.5
# 非法的变量名示例
8ball = "No" # 不能以数字开头
for = 10 # 不能使用关键字作为变量名
FavoriteColor = "Blue" # 变量名是大小写敏感的
```
#### 3.2 变量的赋值与使用
在Python中,变量的赋值是通过`=`符号实现的。当您为变量赋值时,您实际上是在将一个值存储到变量名所指向的内存位置。
```python
name = "Bob" # 将字符串"Bob"赋值给变量name
age = 30 # 将整数30赋值给变量age
# 使用变量
print(name) # 输出变量name的值:"Bob"
print("Age:", age) # 输出变量age的值:"30"
```
#### 3.3 变量的数据类型转换
在Python中,可以通过一些内置函数来实现不同数据类型之间的转换。
```python
# 将字符串转换为整数
str_number = "25"
int_number = int(str_number) # 使用int()函数将字符串转换为整数
print(int_number) # 输出:25
# 将整数转换为字符串
age = 25
age_str = str(age) # 使用str()函数将整数转换为字符串
print(age_str) # 输出:"25"
```
以上是关于变量与赋值的基本内容,理解和掌握这些知识将有助于您更好地进行Python编程。
# 4. 基本操作
在Python中,我们可以使用基本操作来对数据进行各种操作和处理。本章将介绍几种常见的基本操作,包括算术操作、比较操作、逻辑操作和成员运算符。
### 4.1 算术操作
算术操作用于对数值进行基本的数学运算。以下是Python支持的常见算术操作符:
- 加法:使用`+`号进行相加
- 减法:使用`-`号进行相减
- 乘法:使用`*`号进行相乘
- 除法:使用`/`号进行相除
- 取模:使用`%`号进行取模运算,求两个数相除的余数
- 幂运算:使用`**`进行幂运算,求一个数的某个次方
例如,我们可以进行以下算术操作:
```python
num1 = 10
num2 = 3
# 加法
result1 = num1 + num2
print("加法结果:", result1) # 输出:13
# 减法
result2 = num1 - num2
print("减法结果:", result2) # 输出:7
# 乘法
result3 = num1 * num2
print("乘法结果:", result3) # 输出:30
# 除法
result4 = num1 / num2
print("除法结果:", result4) # 输出:3.3333333333333335
# 取模
result5 = num1 % num2
print("取模结果:", result5) # 输出:1
# 幂运算
result6 = num1 ** num2
print("幂运算结果:", result6) # 输出:1000
```
### 4.2 比较操作
比较操作用于对数据进行比较判断,返回布尔类型的结果。以下是Python支持的常见比较操作符:
- 相等:使用`==`判断两个值是否相等
- 不等:使用`!=`判断两个值是否不相等
- 大于:使用`>`判断左侧值是否大于右侧值
- 小于:使用`<`判断左侧值是否小于右侧值
- 大于等于:使用`>=`判断左侧值是否大于等于右侧值
- 小于等于:使用`<=`判断左侧值是否小于等于右侧值
例如,我们可以进行以下比较操作:
```python
num1 = 10
num2 = 3
# 相等判断
result1 = num1 == num2
print("相等判断结果:", result1) # 输出:False
# 不等判断
result2 = num1 != num2
print("不等判断结果:", result2) # 输出:True
# 大于判断
result3 = num1 > num2
print("大于判断结果:", result3) # 输出:True
# 小于判断
result4 = num1 < num2
print("小于判断结果:", result4) # 输出:False
# 大于等于判断
result5 = num1 >= num2
print("大于等于判断结果:", result5) # 输出:True
# 小于等于判断
result6 = num1 <= num2
print("小于等于判断结果:", result6) # 输出:False
```
### 4.3 逻辑操作
逻辑操作用于对布尔值进行逻辑运算。以下是Python支持的常见逻辑操作符:
- 与:使用`and`进行逻辑与运算
- 或:使用`or`进行逻辑或运算
- 非:使用`not`进行逻辑非运算
逻辑操作通常用于条件判断和控制流程。例如,我们可以进行以下逻辑操作:
```python
num1 = 10
num2 = 3
# 与运算
result1 = (num1 > 5) and (num2 < 5)
print("与运算结果:", result1) # 输出:True
# 或运算
result2 = (num1 > 5) or (num2 < 5)
print("或运算结果:", result2) # 输出:True
# 非运算
result3 = not (num1 > num2)
print("非运算结果:", result3) # 输出:False
```
### 4.4 成员运算符
成员运算符用于判断一个值是否存在于列表、字符串或其他可迭代对象中。以下是Python支持的成员运算符:
- `in`:判断一个值是否存在于可迭代对象中,如果存在则返回`True`,否则返回`False`
- `not in`:判断一个值是否不存在于可迭代对象中,如果不存在则返回`True`,否则返回`False`
例如,我们可以进行以下成员运算:
```python
num1 = 10
num2 = [1, 2, 3, 4, 5]
# in运算
result1 = num1 in num2
print("in运算结果:", result1) # 输出:False
# not in运算
result2 = num1 not in num2
print("not in运算结果:", result2) # 输出:True
```
通过本章的介绍,我们可以看到在Python中,基本操作可以帮助我们对数据进行各种操作和处理,从而实现更复杂的逻辑和功能。掌握这些基本操作对于进行Python编程非常重要。在下一章节中,我们将介绍字符串操作,让我们继续学习吧。
# 5. 字符串操作
5.1 字符串的基本操作
在Python中,字符串是不可变的序列,可以通过索引和切片来访问和操作字符串中的字符。下面是一些常见的字符串基本操作示例:
```python
# 字符串索引
my_string = "Hello, World!"
print(my_string[0]) # 输出第一个字符"H"
print(my_string[-1]) # 输出倒数第一个字符"!"
# 字符串切片
print(my_string[7:12]) # 输出"World"
print(my_string[:5]) # 输出"Hello"
print(my_string[7:]) # 输出"World!"
```
代码总结:通过索引和切片操作,可以方便地获取字符串中的字符或子串。
结果说明:上述代码执行后,分别输出了字符串的第一个字符、最后一个字符,以及通过切片获取的子串,验证了字符串的基本操作。
5.2 字符串的格式化
字符串格式化是将变量插入到字符串中的一种常见操作,Python中有多种字符串格式化的方式,其中使用`format`方法是较为通用的一种方式。
```python
# 字符串格式化
name = "Alice"
age = 25
print("My name is {} and I am {} years old.".format(name, age))
```
代码总结:通过`format`方法可以将变量插入到字符串中,形成格式化的输出。
结果说明:执行上述代码后,输出"My name is Alice and I am 25 years old.",达到了字符串的格式化效果。
5.3 字符串的常用方法
Python提供了丰富的字符串处理方法,常用的包括对字符串的大小写转换、分割、连接和替换等操作。
```python
# 字符串常用方法
my_string = "hello, world!"
print(my_string.upper()) # 输出大写字符串"HELLO, WORLD!"
print(my_string.split(",")) # 输出['hello', ' world!']
print(my_string.replace("hello", "hi")) # 输出"hi, world!"
```
代码总结:通过字符串的常用方法,可以实现对字符串的大小写转换、分割、连接和替换等操作。
结果说明:执行上述代码后,分别输出了大写字符串、分割后的子串列表和替换后的字符串,验证了字符串常用方法的功能。
# 6. 复合数据类型
在Python中,复合数据类型指的是可以存储多个不同类型的元素的数据类型。Python提供了三种常见的复合数据类型:列表、元组和字典。它们分别具有不同的特点和用法,下面我们将逐一介绍它们的操作和常用方法。
### 6.1 列表的操作与方法
列表是Python中最简单也是最常用的数据类型之一。它是一个有序的可变序列,在一个方括号内用逗号分隔各个元素,可以包含任意类型的数据。下面是一些常用的列表操作和方法:
- **创建列表**:可以使用方括号来创建一个空列表,也可以直接在方括号中添加元素来创建包含元素的列表。例如:
```python
# 创建一个空列表
empty_list = []
# 创建一个包含元素的列表
number_list = [1, 2, 3, 4, 5]
```
- **访问列表元素**:可以通过索引来访问列表中的元素,索引从0开始。例如:
```python
# 访问列表中的第一个元素
first_element = number_list[0]
```
- **修改列表元素**:可以通过索引来修改列表中的元素。例如:
```python
# 修改列表中的第一个元素
number_list[0] = 10
```
- **添加元素到列表**:可以使用`append()`方法向列表末尾添加一个元素。例如:
```python
# 添加元素到列表末尾
number_list.append(6)
```
- **删除列表元素**:可以使用`del`语句或`remove()`方法删除列表中的元素。例如:
```python
# 删除列表中的第一个元素
del number_list[0]
# 删除列表中的指定元素
number_list.remove(3)
```
- **列表的切片**:可以通过切片操作来获取列表的子列表。例如:
```python
# 获取列表的前三个元素
sub_list = number_list[:3]
# 获取列表的最后两个元素
sub_list = number_list[-2:]
```
- **列表的长度**:可以使用`len()`函数获取列表的长度。例如:
```python
# 获取列表的长度
length = len(number_list)
```
以上只是列表的一些基本操作和方法,还有很多其他方法可以用来操作列表,如`insert()`方法用于在指定位置插入元素,`sort()`方法用于对列表进行排序等。
### 6.2 元组的操作与方法
元组是Python中的另一种有序数据类型,它与列表的区别在于元组是不可变的,即创建后不能被修改。元组使用圆括号来表示,可以包含任意类型的数据。下面是一些常用的元组操作和方法:
- **创建元组**:可以使用圆括号来创建一个空元组,也可以直接在圆括号中添加元素来创建包含元素的元组。例如:
```python
# 创建一个空元组
empty_tuple = ()
# 创建一个包含元素的元组
number_tuple = (1, 2, 3, 4, 5)
```
- **访问元组元素**:可以通过索引来访问元组中的元素,索引从0开始。例如:
```python
# 访问元组中的第一个元素
first_element = number_tuple[0]
```
- **元组的切片**:与列表一样,可以通过切片操作来获取元组的子元组。例如:
```python
# 获取元组的前三个元素
sub_tuple = number_tuple[:3]
# 获取元组的最后两个元素
sub_tuple = number_tuple[-2:]
```
- **元组的长度**:可以使用`len()`函数获取元组的长度。例如:
```python
# 获取元组的长度
length = len(number_tuple)
```
### 6.3 字典的操作与方法
字典是Python中另一种常用的复合数据类型,它是一个无序的键值对集合。每个键值对在字典中是唯一的,键是不可变对象,值可以是任意类型的数据。下面是一些常用的字典操作和方法:
- **创建字典**:可以使用大括号来创建一个空字典,也可以直接在大括号中添加键值对来创建包含键值对的字典。例如:
```python
# 创建一个空字典
empty_dict = {}
# 创建一个包含键值对的字典
student_dict = {"name": "Alice", "age": 18, "gender": "female"}
```
- **访问字典元素**:可以通过键来访问字典中的值。例如:
```python
# 访问字典中的值
name = student_dict["name"]
```
- **修改字典元素**:可以通过键来修改字典中的值。例如:
```python
# 修改字典中的值
student_dict["age"] = 19
```
- **添加键值对到字典**:可以使用赋值语句来添加键值对到字典。例如:
```python
# 添加键值对到字典
student_dict["address"] = "123 Street"
```
- **删除字典元素**:可以使用`del`语句或`pop()`方法删除字典中的键值对。例如:
```python
# 删除字典中的键值对
del student_dict["gender"]
# 删除字典中的指定键值对,并返回其值
age = student_dict.pop("age")
```
- **字典的长度**:可以使用`len()`函数获取字典的长度。例如:
```python
# 获取字典的长度
length = len(student_dict)
```
以上只是字典的一些基本操作和方法,还有其他一些方法可以用来操作字典,如`keys()`方法用于获取字典的键集合,`values()`方法用于获取字典的值集合等。
本章介绍了Python中三种常见的复合数据类型:列表、元组和字典。它们分别具有不同的特点和用法,可以根据实际需求选择合适的数据类型来存储和操作数据。通过学习本章的内容,你应该能够更好地理解和运用这些复合数据类型。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏主题为python机器学习,旨在向读者介绍python在机器学习领域的基础知识和常用库的使用。首先,我们将深入讲解Python的基础知识,包括数据类型、变量、流程控制和循环等内容。然后,我们将详细介绍NumPy库的使用,包括数组和矩阵运算。接着,我们将重点介绍Pandas库,包括数据结构和数据分析。同时,我们将使用Matplotlib库展示数据可视化和图表绘制的技巧。进一步,我们将深入学习Scikit-learn库的机器学习原理和应用。随后,我们将详细介绍不同分类算法,包括K近邻算法和朴素贝叶斯分类算法等。然后,我们将研究不同的回归算法,如线性回归和逻辑回归。另外,我们还将介绍聚类算法,包括K均值聚类算法和层次聚类与DBSCAN算法。特征工程也是重要的一部分,我们将介绍数据预处理、特征选择、特征提取和降维技术。最后,我们将学习模型评估方法,包括交叉验证和评估指标,以及解析支持向量机和神经网络与深度学习基础。通过这个专栏,读者可以全面了解python机器学习的相关概念和实践技巧,为进一步深入学习打下坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
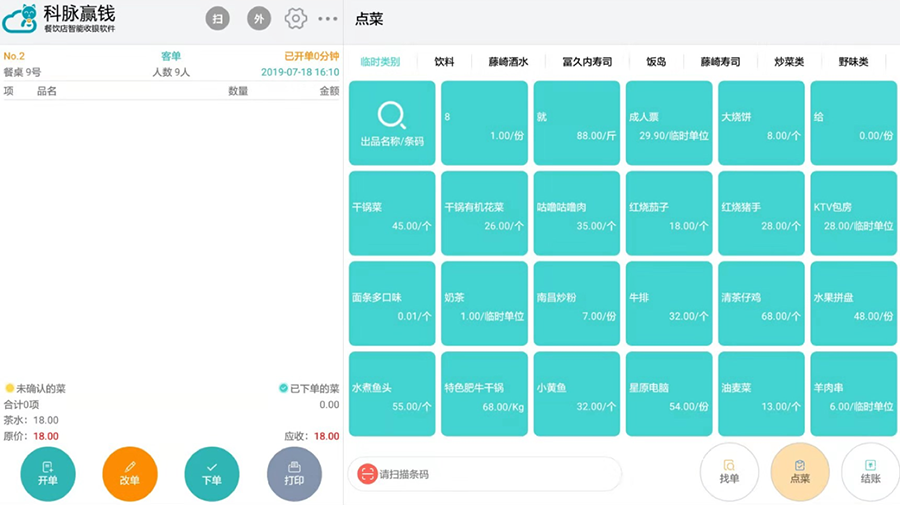
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
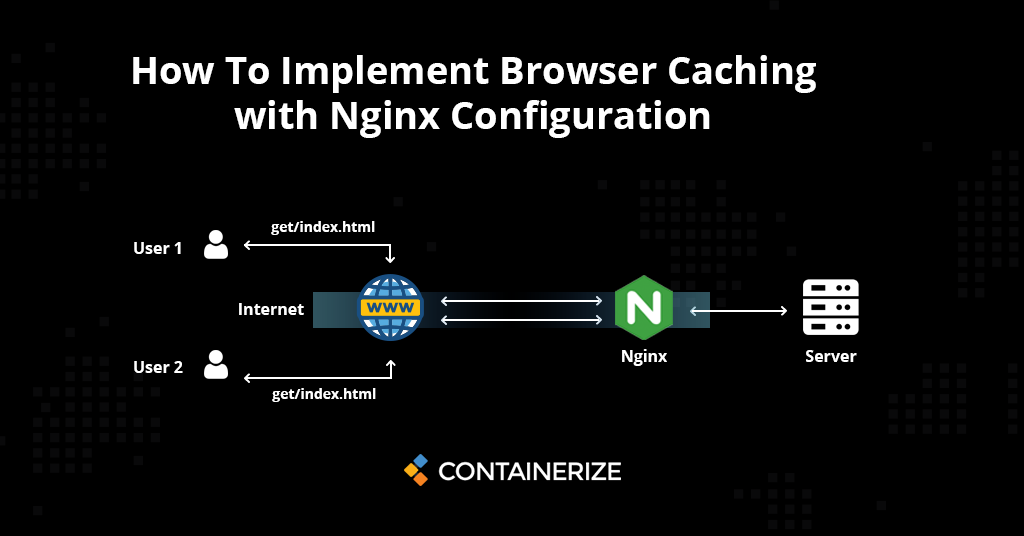
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )