使用Python进行数据可视化:Matplotlib入门教程
发布时间: 2023-12-28 13:02:41 阅读量: 47 订阅数: 34 
# 第一章:数据可视化简介
数据可视化在数据分析和展示中扮演着至关重要的角色。通过图表和图形的方式,能够更直观地呈现数据的规律和趋势,帮助人们更好地理解数据。Python作为一种功能强大且易于学习的编程语言,在数据可视化领域拥有广泛的应用。而Matplotlib库作为Python中最知名的数据可视化库之一,提供了丰富的绘图功能,可用于创建各种类型的图表和图形。
在本章节中,我们将介绍数据可视化的重要性,Python在数据可视化中的应用以及Matplotlib库的基本概述。这些内容将为后续学习Matplotlib库打下坚实的基础。
## 2. 第二章:Matplotlib基础
Matplotlib是一个Python的绘图库,可以用来创建各种静态、交互式和动画图表。在这一章中,我们将介绍Matplotlib库的基础知识,包括安装方法、创建简单图表的步骤以及图表的主要组成部分。
### 2.1 安装Matplotlib库
要安装Matplotlib库,可以使用pip命令:
```bash
pip install matplotlib
```
### 2.2 创建简单的图表
使用Matplotlib库创建一个简单的图表非常容易。首先,导入Matplotlib库,然后使用`plt.plot()`函数传入数据即可创建一个简单的线性图表。例如,以下是一个简单的线性图表的代码示例:
```python
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
plt.plot(x, y)
plt.show()
```
### 2.3 图表的主要组成部分
Matplotlib创建的图表包括许多主要组成部分,如图表标题、坐标轴标签、图例等。在创建图表时,我们可以通过调用相应的函数来添加、修改这些组成部分。下面是一个简单的例子:
```python
plt.plot(x, y)
plt.title('Simple Linear Plot')
plt.xlabel('X-axis Label')
plt.ylabel('Y-axis Label')
plt.legend(['Line 1'])
plt.show()
```
以上是Matplotlib基础的一些介绍,接下来我们将深入学习Matplotlib的各种图表类型和更多高级功能。
### 3. 第三章:线性图和散点图
数据可视化中,线性图和散点图是常用的展示数据关系的方式。本章将介绍如何使用Matplotlib库绘制线性图和散点图,以及如何对图形进行样式和颜色的自定义。
#### 3.1 绘制基本线性图
线性图是用于展示两个变量之间关系的常用图表类型。我们将学习如何使用Matplotlib库绘制简单的线性图,并通过示例演示其应用场景。
#### 3.2 自定义线性图的样式和颜色
除了基本的线性图外,我们还可以对线性图的样式和颜色进行自定义,使图表更具美感和表达力。本节将详细介绍如何对线性图进行样式和颜色的定制化。
#### 3.3 绘制散点图并添加趋势线
散点图是用于观察两个变量之间关系的有效方式,而趋势线则可以帮助我们更直观地理解数据的趋势。我们将学习如何使用Matplotlib库绘制散点图,并添加趋势线以更好地呈现数据关系。
以上便是第三章的内容大纲,接下来我们将详细介绍每个小节的内容,并附上相应的Python示例代码和图表展示。
### 4. 第四章:条形图和直方图
条形图和直方图是常用于展示分类变量和连续变量的图表类型,它们可以直观地展示数据的分布情况和对比关系。
#### 4.1 创建基本条形图
在Matplotlib中,可以使用`bar`函数创建基本的条形图,简单来说,条形图用于展示不同类别的数据之间的比较关系,例如展示不同产品的销售量对比等。
```python
import matplotlib.pyplot as plt
# 数据
categories = ['A', 'B', 'C', 'D']
values = [23, 45, 56, 78]
# 创建条形图
plt.bar(categories, values)
# 设置图表标题和坐标轴标签
plt.title('Sales Volume by Category')
plt.xlabel('Categories')
plt.ylabel('Sales Volume')
# 显示图表
plt.show()
```
通过上述代码,我们可以绘制出基本的条形图,展示不同类别的销售量对比情况。
#### 4.2 绘制分组条形图
有时候我们需要对比不同类别在不同条件下的数据,这时就需要使用分组条形图来展示数据的分布情况。
```python
import numpy as np
# 数据
categories = ['A', 'B', 'C', 'D']
values1 = [23, 45, 56, 78]
values2 = [35, 50, 60, 70]
x = np.arange(len(categories)) # the label locations
width = 0.35 # the width of the bars
fig, ax = plt.subplots()
bars1 = ax.bar(x - width/2, values1, width, label='Group 1')
bars2 = ax.bar(x + width/2, values2, width, label='Group 2')
# 添加标签和标题
ax.set_xlabel('Categories')
ax.set_ylabel('Values')
ax.set_title('Comparison of Groups in Different Categories')
ax.set_xticks(x)
ax.set_xticklabels(categories)
ax.legend()
# 显示图表
plt.show()
```
上述代码中,我们使用了`subplots`来创建多个子图表,然后使用`bar`函数绘制出不同组别在不同类别下的数据对比情况。
#### 4.3 绘制直方图并添加密度曲线
直方图常用来表示连续变量的分布情况,通过统计落在每个分箱区间的数据点数量来展示数据的分布情况,而密度曲线则在直方图的基础上,通过对数据进行平滑处理,展示出数据的密度分布。
```python
# 生成一组随机数据作为示例
data = np.random.normal(0, 1, 1000)
# 创建直方图
count, bins, ignored = plt.hist(data, 30, density=True, alpha=0.5, color='b', edgecolor='black')
# 添加密度曲线
plt.plot(bins, 1/(np.sqrt(2 * np.pi)) * np.exp( - (bins - 0)**2 / (2 * 1**2) ), linewidth=2, color='r')
# 添加标题和标签
plt.title('Histogram with Density Plot')
plt.xlabel('Value')
plt.ylabel('Density')
# 显示图表
plt.show()
```
上述代码中,我们首先使用`hist`函数创建直方图,然后通过添加密度曲线的方式,展示连续变量的密度分布情况。
通过以上内容,我们对Matplotlib库中的条形图和直方图有了深入的了解,下一节我们将继续探讨Matplotlib库中其他类型的数据可视化方法。
## 第五章:盒须图和饼图
数据可视化中的盒须图和饼图是常用的图表类型,用于展示数据的分布和比例。在本章中,我们将学习如何使用Matplotlib库绘制盒须图和饼图,并对其进行进一步的定制和美化。
### 5.1 绘制盒须图
盒须图(Box plot)是一种用于显示数据分布情况的统计图表。它展示了一组数据的最大值、最小值、中位数、上下四分位数以及异常值。使用Matplotlib库的`boxplot()`函数可以轻松绘制盒须图。
### 5.2 自定义盒须图
除了基本的盒须图外,我们还可以对盒须图进行进一步的自定义,比如修改颜色、线型、添加标题和标签等。这些定制操作可以帮助我们更好地呈现数据的特征和趋势。
### 5.3 创建基本饼图
饼图(Pie chart)是一种常见的图表类型,用于显示数据的相对比例。Matplotlib库中的`pie()`函数可以帮助我们快速绘制基本的饼图,并可以进行颜色、标签、阴影等方面的定制。
### 5.4 添加标签和阴影到饼图
在绘制饼图的基础上,我们还可以通过添加标签和阴影效果来增强图表的可读性和美观性。这些小技巧可以让饼图更加生动形象,吸引读者的注意力。
通过本章的学习,读者将掌握如何利用Matplotlib库绘制盒须图和饼图,并且了解如何对图表进行定制和优化,使得数据可视化更加生动和有效。
### 6. 第六章:进阶技巧和应用
在本章中,我们将讨论一些Matplotlib的进阶技巧和实际应用场景。
#### 6.1 子图表的创建
在Matplotlib中,我们可以使用子图表来同时展示多个图表,以便于比较和分析不同数据之间的关系。以下是一个简单的示例,演示如何创建包含多个子图表的布局:
```python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2*np.pi, 400)
y = np.sin(x**2)
fig, axs = plt.subplots(2)
fig.suptitle('Subplots示例')
axs[0].plot(x, y)
axs[1].scatter(x, y)
```
上述代码中,我们使用`plt.subplots`创建了一个包含两个子图表的布局,然后分别在每个子图表中绘制了线性图和散点图。
#### 6.2 教程综合案例分析
为了更好地理解Matplotlib的应用,让我们以一个综合案例来展示如何利用Matplotlib进行数据可视化。我们将使用一个真实数据集,并结合前面章节所学的知识,绘制出更加复杂的图表,以实现对数据的更深层次分析。
#### 6.3 Matplotlib在真实项目中的应用
最后,我们将探讨Matplotlib在真实项目中的应用场景,包括但不限于数据报表、科学研究、金融分析和工程可视化等领域。我们将深入了解Matplotlib如何在这些领域发挥重要作用,并为读者提供更多灵感和实践经验。
通过本章内容的学习,读者将对Matplotlib库有着更深入的理解,并能够运用其更丰富的功能和技巧,实现更复杂、更具有实际应用意义的数据可视化任务。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏涵盖了各种数据分析领域的关键知识和技术。从基础的Excel数据处理和Python数据分析入门开始,到使用Python进行数据可视化和统计分析,再到机器学习和数据挖掘算法的深入理解,以及时间序列预测和大数据处理技术的应用,专栏囊括了数据分析的各个方面。同时,还介绍了图像处理与分析、数据可视化艺术、网络数据分析和数据质量管理等实用技术。此外,还对时间序列预测方法、数据处理与可视化工具、实验设计和高效数据分析工具进行了对比分析。无论您是初学者还是有经验的数据分析师,这个专栏都能为您提供实用的知识和技能。无论您是在学术界还是在商业领域,这个专栏都将成为您提升数据分析能力的绝佳资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【网络配置进阶】RTL8188EE用户指南:打造无与伦比的无线网络体验

# 摘要
本文旨在为读者提供对RTL8188EE无线网卡的全面了解和设置指南。首先,概述了无线网络的基础知识,包括通信原理、网络协议和标准、以及网络配置与优化的基础知识。接着,详细介绍了RTL8188EE无
Allegro 172版DFA Package spacing技巧大揭秘:一文掌握间距合规之道
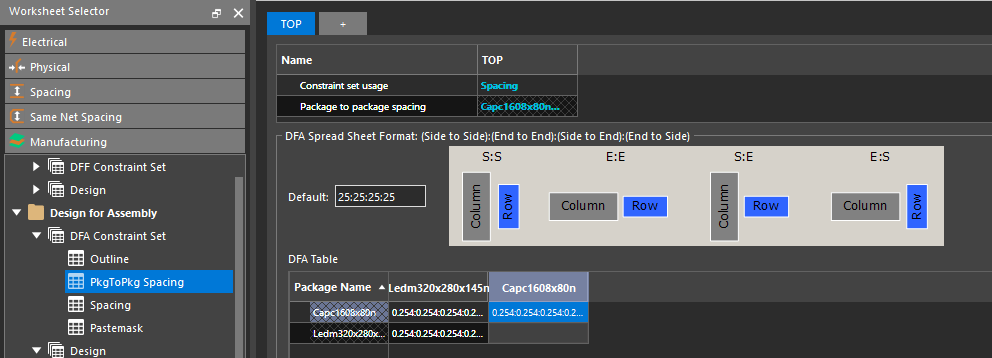
# 摘要
本文系统地介绍了Allegro 172版DFA Package在间距合规方面的应用,旨在帮助设计工程师高效地进行间距合规检查和管理。文章首先概述了间距规则的理论基础及其在设计前准备的重要性,接着
【卷积块细粒度优化】:性能提升的关键技术与实战分析
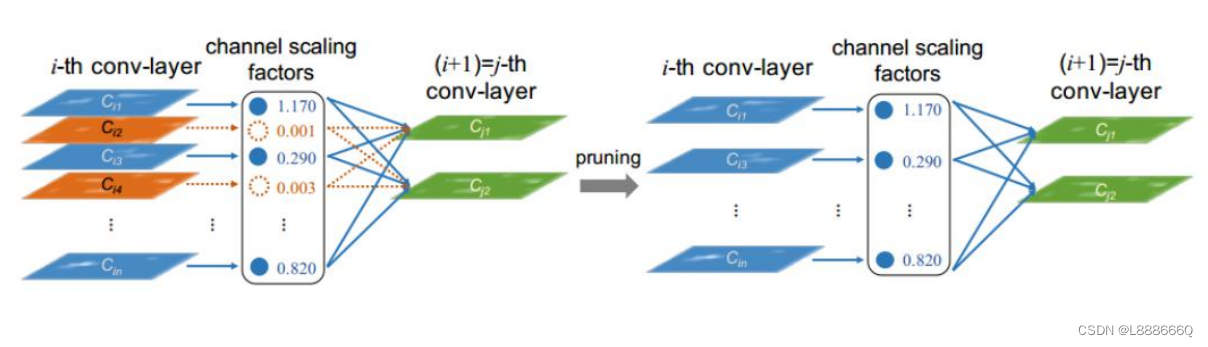
# 摘要
本文系统性地探讨了卷积神经网络(CNN)的基础理论、优化目标及细粒度优化技术。第一章介绍了CNN的基础知识及其优化目标,第二章详细解析了卷积块的理论及其核心组成部分,包括卷积层和激活函数的作用原理,以及权重初始化与正则化的应用。此外,讨论了卷积块深度和宽度的优化策略。第三章则深入细粒度优化技术的实践,包含卷积核的精细化设计、网络剪枝与量化技术,以及硬件加速与优化的考量。第四章分析了细粒度优化技术
【SAP批量用户管理攻略】:从零到英雄,掌握高效创建与维护的终极秘籍

# 摘要
本文对SAP系统用户管理进行了全面的概述,涵盖了用户创建、权限分配、批量操作、监控审计、数据备份恢复以及高级技巧和优化。文章首先介绍用户和角色的基本理论,随后详细解析了SAP权限模型的工作机制。接着,重点论述了批量创建和维护SAP用户的实用技术,包括数据源准备、自动化创建和同步更新。在实践应用章节中,文章详细探讨了用户活动监控
【指示灯识别的机器学习方法】:理论与实践结合
# 摘要
本文全面探讨了机器学习在指示灯识别中的应用,涵盖了基础理论、特征工程、机器学习模型及其优化策略。首先介绍了机器学习的基础和指示灯识别的重要性。随后,详细阐述了从图像处理到颜色空间分析的特征提取方法,以及特征选择和降维技术,结合实际案例分析和工具使用,展示了特征工程的实践过程。接着,讨论了传统和深度学习模
【跨平台开发策略】《弹壳特攻队》的一次编码,处处运行之道

# 摘要
随着移动设备和应用的多样化发展,跨平台开发成为了软件行业的重要趋势。本文首先概述了跨平台开发的理论基础与原则,强调其理念、优势以及关键技术。随后,以游戏《弹壳特攻队》为案例,分析了其跨平台开发的实践,包括技术选型、兼容性处理和性能优化。进阶篇探讨了高级技巧,并对社区支持和工具发展趋势进行了考察。最后,总结篇基于《弹壳特
PDMS碰撞检测攻略:确保设计零失误的五大技巧
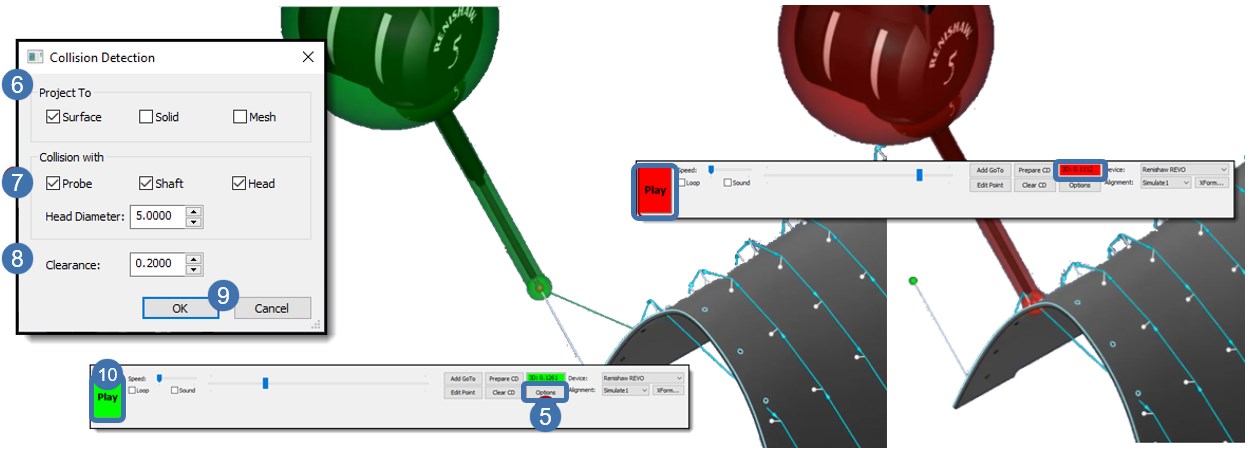
# 摘要
本论文对PDMS碰撞检测技术进行了全面的概述,详细阐述了碰撞检测的理论基础,包括数学原理、空间分割技术以及碰撞检测流程和优化策略。接着,探讨了在PDMS模型准备、参数设置和碰撞报告解读等方面的实践技巧。进阶应用部分,重点介绍了动态模拟技术在碰撞检测中的应用、复杂系统中的碰撞检测挑战和碰撞检测结果的可视化技术。通过对工业设计、建筑设计和船舶海洋工程中碰撞检测应用的案例研究,深
WLC3504配置实战手册:无线安全与网络融合的终极指南

# 摘要
WLC3504无线控制器作为网络管理的核心设备,在保证网络安全、配置网络融合特性以及进行高级网络配置方面扮演着关键角色。本文首先概述了WLC3504无线控制器的基本功能,然后深入探讨了其无线安全配置的策略和高级安全特性,包括加密、认证、访问控制等。接着,文章分析了网络融合功能,解释了无线与有线网络融合的理论与配置方法,并讨论
ME系列存储监控与维护宝典:系统稳定运行的秘诀大公开
# 摘要
本文全面介绍了ME系列存储系统的概述、存储监控的基础知识和技术原理、存储维护的策略与方法以及高级存储监控与维护技术的应用。通过对监控工具选择与部署、定期维护流程和故障排除技巧等方面的探讨,深入分析了存储系统稳定性与性能优化的重要性。同时,预测性维护、存储自动化和跨平台管理等高级技术的应用被详细阐述,以提供有效的存储系统管理方案。案例研究与经验分享部分强调了理论与实践相结合的重要性,对未来存储监控与维护技
MATLAB在光学测量与数据处理中的作用:深入探讨与实践
# 摘要
MATLAB软件在光学测量领域中扮演着重要的角色,不仅因为其强大的数据处理能力,还因为其在图像增强、特征提取、模型建立和实验控制等方面提供了丰富的工具和算法。本文全面介绍了MATLAB的基础知识以及在光学测量中的应用,从数据处理到实验设计控制,阐述了MATLAB如何提高测量精度和效率。通过光学信号的捕获、处理、特征提取和模型建立
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )