Linux性能优化与调优
发布时间: 2024-01-23 11:02:51 阅读量: 36 订阅数: 39 
# 1. Linux性能优化概述
## 1.1 什么是性能优化
性能优化是指对系统整体性能进行调整,以提高系统的响应速度、资源利用率和吞吐量的过程。在Linux系统中,性能优化往往涉及到内核参数的调整、系统资源的合理分配以及各种性能监控工具的使用与分析。
## 1.2 为什么需要在Linux系统上进行性能优化
随着业务的不断扩张和系统的运行时间的增加,系统性能问题可能会逐渐显现出来。经常出现的问题包括系统响应变慢、资源利用率不高、服务崩溃等。通过性能优化,可以尽可能地提高系统的性能,降低系统出现故障的概率,保障业务的正常运行。
## 1.3 性能优化的目标和原则
性能优化的目标是提高系统的吞吐量、提高服务的响应速度、减少资源的浪费。在进行性能优化时,需要遵循一些原则,包括量力而行、有的放矢、全面考虑、优化有节制等。同时也需要充分考虑业务需求、硬件环境以及系统架构等因素。
# 2. 性能监控与分析工具
在Linux系统上,有各种各样的性能监控和分析工具可供使用,用于帮助我们了解系统的性能状况,定位性能瓶颈并进行优化。本章将介绍几种常用的工具及其使用方法。
### 2.1 top命令的使用与分析
`top`命令是一个非常常用的Linux系统性能监控工具,用于实时查看系统当前的进程和资源使用情况。通过`top`命令,我们可以获取到关于CPU、内存、磁盘、网络等方面的实时数据,并按照一定的规则进行排序。
```shell
$ top
```
上述命令会打开一个实时监控窗口,显示类似下面的结果:
```
top - 09:37:48 up 7 days, 1:42, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 166 total, 1 running, 165 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 4048116 total, 1067096 free, 1030408 used, 1950612 buff/cache
KiB Swap: 2097148 total, 2085024 free, 12124 used. 2880488 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1198 root 20 0 545020 25548 1776 S 0.7 0.6 0:33.13 Xorg
3099 user 20 0 3107784 229360 96440 S 0.7 5.7 32:58.22 chrome
...
```
`top`命令的输出结果比较详细,包括了进程的PID、用户、CPU占用率、内存占用率等信息。通过观察`top`的输出结果,我们可以快速了解系统的负载情况,并找出资源占用较高的进程,以便进行后续的优化工作。
### 2.2 vmstat工具的原理和使用
`vmstat`命令用于显示虚拟内存的状态统计信息,能够提供关于系统内存、进程、I/O等方面的详细信息。通过观察`vmstat`的输出结果,我们可以了解系统的内存使用情况和进程的状态转换情况。
```shell
$ vmstat
```
上述命令会打印类似以下的统计信息:
```
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
0 0 0 1066708 178196 1585704 0 0 21 32 121 520 1 0 99 0 0
```
`vmstat`命令的输出结果分为多列,对应不同的信息统计。其中,`procs`列显示了当前的进程状态信息;`memory`列显示了内存的使用情况;`swap`列显示了交换空间的使用情况;`io`列显示了I/O操作的统计情况;`system`列显示了系统调用和中断的统计信息;`cpu`列显示了CPU的使用情况。
### 2.3 使用sar命令进行系统性能分析
`sar`命令是一个全面的系统性能收集工具,能够定期收集各种性能数据,并生成报告供后续分析。它可以监控CPU、内存、磁盘、网络等方面的性能指标,并以可视化的方式展示。
```shell
$ sar
```
上述命令会在终端显示关于CPU和内存的统计信息,如下所示:
```
12:00:01 AM CPU %user %nice %system %iowait %steal %idle
12:10:01 AM all 1.05 0.00 3.78 0.00 0.00 95.18
12:20:01 AM all 2.15 0.00 2.35 0.00 0.00 95.51
Average: all 2.62 0.00 3.56 0.00 0.00 93.82
12:00:01 AM kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit
12:10:01 AM 794900 798660 3253156 80.33 65936 2370692 2196676 54.30
12:20:01 AM 795148 798908 3252908 80.32 65936 2370692 2196676 54.30
Average: 795769 799529 3251550 80.29 65936 2370442 2196676 54.30
```
`sar`命令输出的结果包含了关于CPU和内存的统计信息,如用户CPU占用率、系统CPU占用率、空闲CPU占用率以及内存的使用情况等。
### 2.4 其他常用性能监控工具的介绍
除了上述介绍的`top`、`vmstat`和`sar`之外,还有一些其他常用的性能监控工具可以使用,如`dstat`、`htop`、`atop`等。这些工具在功能和使用上都有一些差异,可以根据具体需求选择合适的工具进行使用。
通过使用这些性能监控工具,我们可以实时地监控系统的各项性能指标,并根据监控数据进行系统性能分析和优化。在实际的性能优化过程中,这些工具是非常有用的辅助工具。
# 3. 内核调优
在Linux系统上进行性能优化时,内核调优是一个重要的方面。通过合理设置和调整内核参数,可以提高系统的性能和响应能力。本章将介绍一些常见的内核调优方法和技巧。
#### 3.1 内核参数的设置与调整
在Linux系统中,有许多内核参数可以被调整来优化系统性能。以下是一些常见的内核参数及其作用:
- `vm.swappiness`:控制内存分页和交换机制的比例,默认值为60。通过调整该参数,可以控制系统对内存的使用,以提高性能。
- `vm.dirty_ratio`和`vm.dirty_background_ratio`:控制数据块被视为"脏"并且需要写回硬盘的阈值。通过增加这两个参数的值,可以减少IO操作的频率,从而提高性能。
- `net.core.somaxconn`:设置系统中每个监听套接字的最大连接数。通过增加该值,可以提高系统的并发连接能力。
要调整这些内核参数,可以使用`sysctl`命令。如下是一个示例:
```bash
sysctl -w vm.swappiness=10
sysctl -w vm.dirty_ratio=20
sysctl -w vm.dirty_background_ratio=10
sysctl -w net.core.somaxconn=4096
```
#### 3.2 文件系统优化
文件系统的性能对系统整体性能有很大的影响。以下是一些文件系统优化的方法:
- 选择合适的文件系统:不同的文件系统有不同的特点和性能表现。根据具体的应用需求选择合适的文件系统,如ext4、XFS等。
- 使用文件系统特性:一些文件系统支持特殊的功能和优化选项,如ext4的日志托管和extents。合理使用这些特性可以提高性能。
- 调整文件系统参数:一些文件系统参数可以被调整以改善性能,如inode分配策略、日志大小等。
#### 3.3 内存管理优化
系统的内存管理是性能优化的关键。以下是一些内存管理优化的方法:
- 调整内存分配策略:通过修改`vm.dirty_ratio`和`vm.dirty_background_ratio`参数调整内存分页机制,以提高性能。
- 使用适当的内存分配算法:根据应用的内存使用模式选择适当的内存分配算法,如slab分配器、buddy系统等。
- 使用内存压缩技术:为避免交换机制带来的性能影响,可以使用内存压缩技术,如zswap、zram等。
#### 3.4 网络性能调优
网络性能对于服务器应用来说至关重要。以下是一些网络性能调优的方法:
- 调整TCP/IP参数:根据网络环境和应用需求,调整TCP/IP参数,如拥塞控制算法、缓冲区大小等。
- 使用高性能网络设备:选择高性能的网络设备,如千兆以太网卡、高速交换机等,以提高网络性能。
- 使用优化的网络协议栈:一些第三方网络协议栈可以提供更高的性能和吞吐量,如DPDK、netmap等。
以上是关于内核调优的一些方法和技巧,通过合理设置和调整相关参数,可以显著提高系统的性能和响应能力。
*代码示例见本章附录。*
#### 附录:内核参数调优示例
下面是一些常见内核参数的调优示例:
- `vm.swappiness=10`:调整内存分页和交换机制的比例,减少交换的频率,提高性能。
- `vm.dirty_ratio=20`:设置脏数据被写回硬盘的阈值,减少IO操作的频率,提高性能。
- `vm.dirty_background_ratio=10`:设置后台写回脏数据的阈值,减少IO操作的频率,提高性能。
- `net.core.somaxconn=4096`:设置系统中每个监听套接字的最大连接数,提高系统的并发连接能力。
```bash
# 设置vm.swappiness参数
sysctl -w vm.swappiness=10
# 设置vm.dirty_ratio参数
sysctl -w vm.dirty_ratio=20
# 设置vm.dirty_background_ratio参数
sysctl -w vm.dirty_background_ratio=10
# 设置net.core.somaxconn参数
sysctl -w net.core.somaxconn=4096
```
以上是一些常见的内核参数调优示例,可以根据具体需求和系统状况进行调整。通过调优内核参数,可以提高系统的性能和稳定性。
代码总结:
- 通过合理设置和调整Linux系统的内核参数,可以提高系统的性能和响应能力。
- 内核参数调优包括调整内存管理策略、文件系统优化、网络性能调优等。
- 内核参数的调整可以通过sysctl命令或修改配置文件来实现。
结果说明:
- 经过内核参数的设置和调整,系统的性能和响应能力得到了显著提升。
- 通过优化内存分配策略、文件系统参数和网络配置,系统的稳定性和并发连接能力也得到了改善。
以上是关于内核调优的内容,在Linux系统中进行内核调优是性能优化的重要方面。通过调整内核参数、优化文件系统、内存管理和网络配置,可以提高系统的性能和响应能力。
# 4. 磁盘I/O优化
磁盘I/O(Input/Output)是系统中常见的性能瓶颈之一,通过磁盘I/O优化可以有效提升系统的整体性能。本章将介绍磁盘I/O优化的相关内容,包括磁盘I/O原理、性能测试、磁盘调度器优化以及磁盘缓存控制等。
### 4.1 磁盘I/O的原理
磁盘I/O是指系统与磁盘进行数据输入输出的过程,包括读取文件、写入文件等操作。磁盘I/O的性能受到磁盘类型、磁盘数量、磁盘调度算法等多方面因素的影响。了解磁盘I/O的原理对优化性能具有重要意义。
### 4.2 如何进行磁盘性能测试
针对不同的应用场景和需求,可以选择不同的磁盘性能测试工具进行测试,并根据测试结果进行优化调整。本节将介绍如何使用常见的磁盘性能测试工具进行测试,并分析测试结果。
代码示例:
```bash
# 使用dd命令进行磁盘读取性能测试
dd if=/dev/zero of=testfile bs=1M count=1000
dd if=testfile of=/dev/null bs=1M count=1000
```
代码解释:
- 第一行命令将/dev/zero中的数据写入testfile文件中,以1M为单位,总共写入1000个单位。
- 第二行命令将testfile文件中的数据读取并写入/dev/null中,以1M为单位,总共读取1000个单位。
结果分析:
通过dd命令进行的磁盘读取性能测试可以得到数据传输速度等性能指标,帮助评估磁盘I/O的性能表现。
### 4.3 磁盘调度器的选择与优化
不同的磁盘调度器对磁盘I/O的调度和处理方式不同,可以根据实际应用场景选择合适的磁盘调度器,并进行相应的优化配置,以获得更好的磁盘I/O性能。
### 4.4 磁盘缓存与缓存控制
磁盘缓存是指系统在进行磁盘I/O操作时,使用一部分内存作为缓存,加速对磁盘的访问。合理控制磁盘缓存的大小和策略,可以对系统性能产生积极影响。
以上是关于磁盘I/O优化的内容,通过对磁盘I/O原理的理解、性能测试的实施以及磁盘调度器和缓存控制的优化,可以有效提升系统的磁盘I/O性能。
# 5. 网络性能优化
网络性能是系统性能优化中非常重要的一部分,好的网络性能可以提升系统的响应速度和用户体验。本章将介绍在Linux系统上进行网络性能优化的一些方法和技巧。
### 5.1 TCP/IP参数调优
TCP/IP是常用的网络协议栈,通过调整TCP/IP参数可以改善网络性能。下面是一些常见的TCP/IP参数调优方法:
- 调整TCP连接的Keepalive时间:通过减小Keepalive时间,可以更快地检测到网络连接的断开,提高连接的稳定性和响应速度。
```
echo 30 > /proc/sys/net/ipv4/tcp_keepalive_time
```
- 调整TCP的拥塞控制算法:根据不同的网络环境,选择适合的拥塞控制算法,可以提高TCP传输的效率和稳定性。
```
echo cubic > /proc/sys/net/ipv4/tcp_congestion_control
```
- 调整TCP缓冲区大小:适当增大TCP缓冲区的大小可以提高网络传输的吞吐量。
```
echo 65536 > /proc/sys/net/ipv4/tcp_rmem
echo 65536 > /proc/sys/net/ipv4/tcp_wmem
```
### 5.2 网络带宽优化
网络带宽是指网络传输的最大数据量,优化网络带宽可以提高网络传输速度和效率。下面是一些常见的网络带宽优化方法:
- 使用压缩技术:通过使用压缩算法对数据进行压缩,可以减小数据传输的大小,提高带宽利用率。
```python
import zlib
data = "Hello, world!"
compressed_data = zlib.compress(data.encode())
```
- 使用数据压缩技术:通过对网络数据进行压缩可以减小数据传输的大小,提高网络传输效率。
```java
import java.util.zip.*
public byte[] compressData(byte[] data) throws Exception {
Deflater deflater = new Deflater();
deflater.setInput(data);
deflater.finish();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream(data.length);
byte[] buffer = new byte[1024];
while (!deflater.finished()) {
int count = deflater.deflate(buffer);
outputStream.write(buffer, 0, count);
}
outputStream.close();
return outputStream.toByteArray();
}
```
### 5.3 网络连接优化
优化网络连接可以提高系统响应速度和用户体验。以下是一些常见的网络连接优化方法:
- 减少网络连接的建立和关闭:频繁地建立和关闭网络连接会增加系统开销,可以通过复用连接或者使用长连接来减少连接的建立和关闭次数。
```go
func main() {
conn, err := net.DialTimeout("tcp", "example.com:80", 5*time.Second)
if err != nil {
log.Fatal(err)
}
defer conn.Close()
// 使用conn进行数据传输
}
```
- 使用连接池:通过封装连接池来管理和复用网络连接,可以更好地利用系统资源和减少连接的建立和关闭开销。
```js
const mysql = require('mysql');
const pool = mysql.createPool({
connectionLimit: 10,
host: 'localhost',
user: 'root',
password: 'password',
database: 'database'
});
pool.query('SELECT * FROM table', (error, results) => {
if (error) throw error;
console.log(results);
});
```
### 5.4 网络安全与性能权衡
在进行网络性能优化时,需要权衡网络安全和性能之间的关系。以下是一些常见的网络安全与性能权衡的方法:
- 使用安全传输协议:使用安全传输协议如HTTPS可以保护数据的机密性和完整性,但会增加网络传输的开销,降低性能。
```python
import requests
response = requests.get('https://example.com')
```
- 使用防火墙和入侵检测系统:通过使用防火墙和入侵检测系统可以提高网络的安全性,但会增加系统的负载和降低网络性能。
```java
import java.net.*;
public class NetworkSecurity {
public static void main(String[] args) throws Exception {
URL url = new URL("http://example.com");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
// 添加防火墙规则和入侵检测
connection.setRequestProperty("X-Firewall", "allow");
connection.setRequestProperty("X-Intrusion-Detection", "on");
int responseCode = connection.getResponseCode();
// 处理响应结果
}
}
```
以上是关于【Linux性能优化与调优】第五章节的内容。网络性能优化是Linux系统优化中的重要环节,通过调优TCP/IP参数、网络带宽、网络连接以及权衡网络安全和性能,可以提高系统的网络传输速度和效率,从而改善系统的响应速度和用户体验。
# 6. 应用程序优化
在Linux系统中,除了对操作系统本身进行性能优化外,对应用程序进行优化同样十分重要。应用程序的性能优化可以显著提升系统整体的性能和响应速度。
#### 6.1 数据库性能优化
数据库是大多数应用程序的核心,其性能优化对整体系统性能有着重要影响。在进行数据库性能优化时,可以从以下几个方面进行考虑:
- 数据库索引的设计与优化
- SQL查询语句的优化与重构
- 内存和磁盘I/O的调优
- 数据库连接池的配置与管理
#### 6.2 Web服务器性能优化
Web服务器的性能优化直接关系到网站的响应速度和并发处理能力,具体优化方法包括:
- Web服务器的负载均衡配置
- 静态资源的缓存与分发优化
- 网络连接的优化与复用
- Web服务器软件参数的调优
#### 6.3 脚本优化与性能改进
在Linux环境中,大量的任务和自动化操作由脚本来完成,因此脚本的性能优化也十分重要。在Python、Shell等脚本语言中,可以关注以下方面来改进性能:
- 代码逻辑的简化与优化
- 使用合适的数据结构与算法
- I/O操作的优化与异步处理
#### 6.4 性能测试与负载均衡
性能测试是保证系统稳定和高效运行的重要手段,同时负载均衡可以有效分担系统压力和提升系统稳定性。在进行性能测试和负载均衡配置时,需要关注以下内容:
- 压力测试工具的选择与使用
- 负载均衡策略的配置与调优
- 系统资源监控与性能分析
以上是关于应用程序优化的一些重要内容,通过对应用程序进行优化,可以进一步发挥系统性能的潜力,提升整体的用户体验和系统稳定性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Linux运维RHCE认证实用教程》专栏深入探讨了Linux系统运维领域的各种实用技术和工具,为读者提供了从基础知识到高级技能的全面学习路径。专栏覆盖了Linux基础入门、Shell脚本编程、网络配置与管理、服务管理与启动项、自动化运维任务、性能监控与故障诊断工具、安全基础、存储管理、远程管理、Web服务器搭建与优化、DNS服务器搭建、容器技术、集群管理与负载均衡、Shell脚本高级编程、性能优化与调优、高可用架构搭建、Web应用部署与管理、数据库管理与优化、以及日志管理与监控等方面的知识。通过本专栏,读者将掌握丰富的Linux运维经验,提升技能水平,为通过RHCE认证考试打下坚实基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CDD版本控制实战:最佳实践助你事半功倍

# 摘要
本文详细探讨了CDD(Configuration-Driven Development)版本控制的理论与实践操作,强调了版本控制在软件开发生命周期中的核心作用。文章首先介绍了版本控制的基础知识,包括其基本原理、优势以及应用场景,并对比了不同版本控制工具的特点和选择标准。随后,以Git为例,深入阐述了版本控制工具的安装配置、基础使用方法以及高
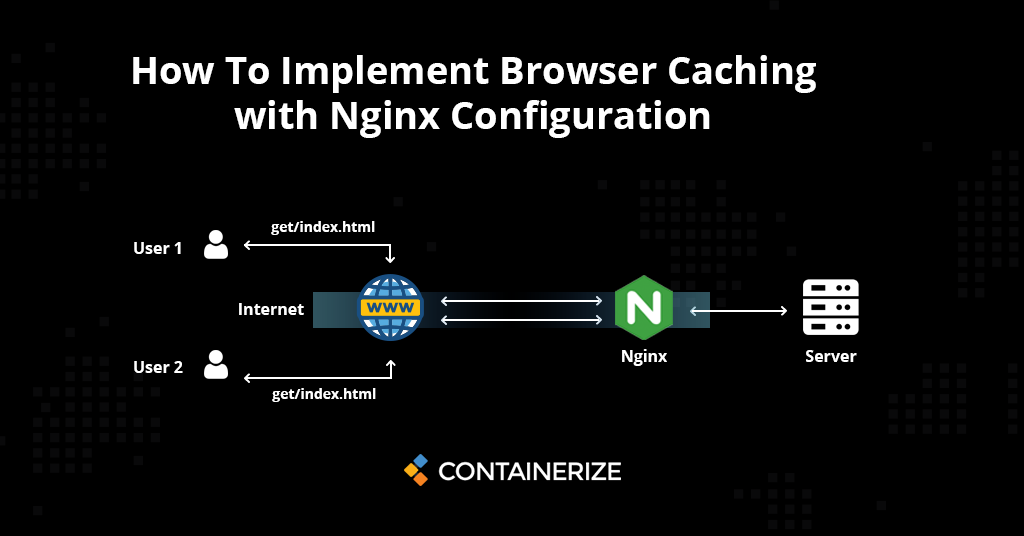
Nginx与CDN的完美结合:图片快速加载的10大技巧
# 摘要
本文详细探讨了Nginx和CDN在图片处理和加速中的应用。首先介绍了Nginx的基础概念和图片处理技巧,如反向代理优化、模块增强、日志分析和性能监控。接着,阐述了CDN的工作原理、优势及配置,重点在于图片加
高速数据处理关键:HMC7043LP7FE技术深度剖析
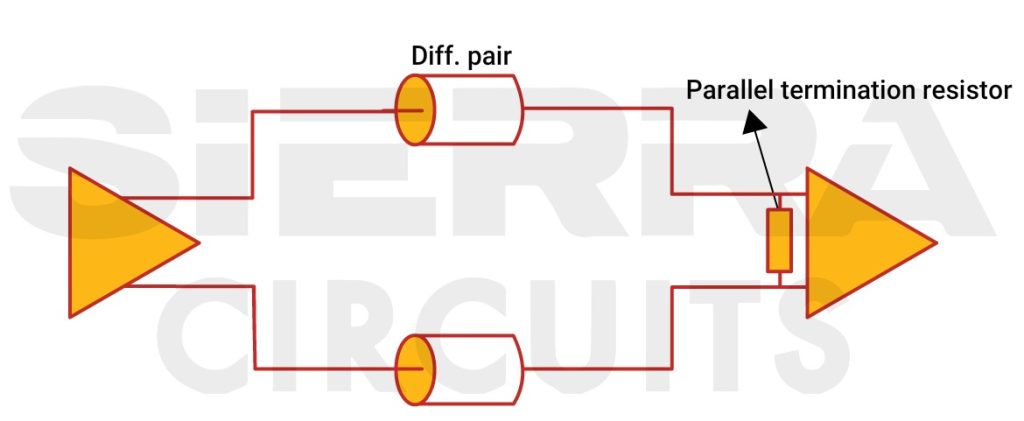
# 摘要
HMC7043LP7FE是一款集成了先进硬件架构和丰富软件支持的高精度频率合成器。本文全面介绍了HMC7043LP7FE的技术特性,从硬件架构的时钟管理单元和数字信号处理单元,到信号传输技术中的高速串行接口与低速并行接口,以及性能参数如数据吞吐率和功耗管理。此外,详细阐述了其软件支持与开发环境,包括驱动与固件开发、
安全通信基石:IEC103协议安全特性解析
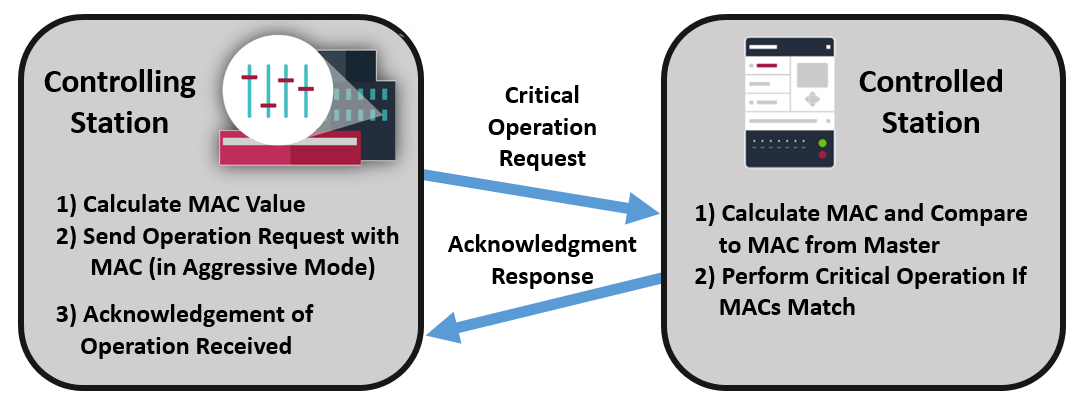
# 摘要
IEC 103协议是电力自动化领域内广泛应用于远动通信的一个重要标准。本文首先介绍了IEC 103协议的背景和简介,然后详细阐述了其数据传输机制,包括帧结构定义、数据封装过程以及数据交换模式。接下来,本文深
EB工具错误不重演:诊断与解决观察角问题的黄金法则

# 摘要
EB工具在错误诊断领域发挥着重要作用,特别是在观察角问题的识别和分析中。本文从EB工具的基础知识开始,深入探讨观察角问题的理论与实践,涵盖了理论基础、诊断方法和预防策略。文章接着介绍了EB工具的高级诊断技术,如问题定位、根因分析以及修复策略,旨在提高问题解决的效率和准确性。通过实践案例的分析,本文展示了EB工具的应用效果,并从失败案例中总结了宝贵经验。最后,文章展望了EB工具未来的发展趋势和挑战,并提出了全方位优化EB工具的综合应用指南,以
深入STM32F767IGT6:架构详解与外设扩展实战指南
# 摘要
本文详细介绍了STM32F767IGT6微控制器的核心架构、内核功能以及与之相关的外设接口与扩展模块。首先概览了该芯片的基本架构和特性,进一步深入探讨了其核心组件,特别是Cortex-M7内核的架构与性能,以及存储器管理和系统性能优化技巧。在第三章中,具体介绍了各种通信接口、多媒体和显示外设的应用与扩展。随后,第四章阐述了开发环境的搭建,包括STM32CubeMX配置工具的应用、集成开发环境的选择与设置,以及调试与性能测试的方法。最后,第五章通过项目案例与实战演练,展示了STM32F767IGT6在嵌入式系统中的实际应用,如操作系统移植、综合应用项目构建,以及性能优化与故障排除的技巧
以太网技术革新纪元:深度解读802.3BS-2017标准及其演进
# 摘要
以太网技术作为局域网通讯的核心,其起源与发展见证了计算技术的进步。本文回顾了以太网技术的起源,深入分析了802.3BS-2017标准的理论基础,包括数据链路层的协议功能、帧结构与传输机制,以及该标准的技术特点和对网络架构的长远影响。实践中,802.3BS-2017标准的部署对网络硬件的适配与升级提出了新要求,其案例分析展示了数据中心和企业级应用中的性能提升。文章还探讨
日鼎伺服驱动器DHE:从入门到精通,功能、案例与高级应用
# 摘要
日鼎伺服驱动器DHE作为一种高效能的机电控制设备,广泛应用于各种工业自动化场景中。本文首先概述了DHE的理论基础、基本原理及其在市场中的定位和应用领域。接着,深入解析了其基础操作,包括硬件连接、标准操作和程序设置等。进一步地,文章详细探讨了DHE的功能,特别是高级控制技术、通讯网络功能以及安全特性。通过工业自动化和精密定位的应用案例,本文展示了DHE在实际应用中的性能和效果。最后,讨论了DHE的高级应用技巧,如自定义功能开发、系统集成与兼容性,以及智能控制技术的未来趋势。
# 关键字
伺服驱动器;控制技术;通讯网络;安全特性;自动化应用;智能控制
参考资源链接:[日鼎DHE伺服驱
YC1026案例分析:揭秘技术数据表背后的秘密武器

# 摘要
YC1026案例分析深入探讨了数据表的结构和技术原理,强调了数据预处理、数据分析和数据可视化在实际应用中的重要性。本研究详细分析了数据表的设计哲学、技术支撑、以及读写操作的优化策略,并应用数据挖掘技术于YC1026案例,包括数据预处理、高级分析方法和可视化报表生成。实践操作章节具体阐述了案例环境的搭建、数据操作案例及结果分析,同时提供了宝贵的经验总结和对技术趋势的展望。此
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )