ReportLab表单设计与处理:创建交互式PDF表单的终极指南
发布时间: 2024-10-02 01:34:44 阅读量: 88 订阅数: 42 

# 1. ReportLab简介与安装
在当今数字化时代,生成高质量的PDF文件已成为业务沟通的必备工具。ReportLab是一款强大的Python库,专注于PDF生成、编辑和转换。它为开发者提供了丰富的API来创建复杂的文档,尤其是专业的表单和报告。
## 1.1 ReportLab库概述
ReportLab的设计哲学是让开发者能够通过编程方式生成任何形式的PDF文档。它提供了从基本的文本和图形处理到复杂的布局管理的所有功能。ReportLab对于需要批量生成PDF文件的场景特别有用,如报告生成、发票打印、表单分发等。
## 1.2 安装ReportLab
在开始使用ReportLab前,首先需要安装它。推荐使用pip进行安装,确保你的Python环境已经配置好。以下是一个简单的安装指令:
```bash
pip install reportlab
```
安装完成后,可以通过Python的交互式环境进行快速检查:
```python
import reportlab
print(reportlab.__version__)
```
如果成功,将输出ReportLab的版本号,表明安装成功。接下来,就可以开始探索ReportLab的文档处理能力了。
# 2. PDF表单设计基础
## 2.1 PDF表单的结构与组成
### 2.1.1 表单元素的基本概念
在PDF表单的世界里,表单元素是构成表单的基本构件。它们就像是建筑中的砖瓦,为表单提供了必要的功能和视觉表现。ReportLab库支持创建多种类型的表单元素,包括文本框、按钮、复选框、单选按钮、列表框等。
理解每种表单元素的功能和用途是构建有效表单的第一步。例如,文本框用于收集用户的自由文本输入,而按钮可以用来触发特定的动作,如提交表单、重置表单等。复选框和单选按钮通常用于收集用户的选择,这些选择是有限且互斥的。
### 2.1.2 表单元素的属性和样式
表单元素的属性定义了元素的行为和表现,例如一个按钮的`onclick`属性可以指定当用户点击按钮时执行的JavaScript函数。样式则定义了表单元素的外观,例如颜色、字体、边框等,它们通过CSS样式的规则进行定义和应用。
使用ReportLab,你可以定义元素的大小、位置、对齐方式等属性,以及应用不同的样式来确保表单既美观又实用。这有助于提高用户体验,使表单信息更加易于理解。
接下来,我们将逐步深入,探讨如何使用ReportLab创建静态表单,这是构建任何交互式表单的基础。
## 2.2 使用ReportLab创建静态表单
### 2.2.1 表单字段的定义和布局
使用ReportLab创建静态表单涉及定义字段以及安排它们的布局。每个字段都有特定的名称和类型,以及可选的属性来控制其行为。例如,创建一个文本输入字段:
```python
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from reportlab.lib import colors
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
# 创建一个PDF画布
c = canvas.Canvas("static_form.pdf", pagesize=letter)
# 定义字段
text_field = c.beginText(100, 750)
text_field.setFont("Helvetica", 12)
text_field.drawString(0, 0, "Enter your name:")
# 绘制字段到PDF
c.drawText(text_field)
c.save()
```
在上面的代码中,我们初始化了一个名为`static_form.pdf`的PDF画布,并定义了一个文本字段。然后,我们在画布上绘制了这个字段,这个过程涉及到了对文本的字体、大小以及位置的设置。
### 2.2.2 表单样式的定制与应用
定制表单样式是一个重要的环节,因为良好的视觉效果可以显著提升用户体验。ReportLab允许我们通过设置不同的属性来定制表单元素的样式。
```python
# 添加自定义字体
pdfmetrics.registerFont(TTFont('MyFont', 'path/to/font.ttf'))
# 设置文本字段的样式
text_field.setFont("MyFont", 12)
text_field.setFill(colors.red)
# 绘制样式化的字段到PDF
c.drawText(text_field)
c.save()
```
在这段代码中,我们首先注册了一个新的字体,然后将文本字段的字体和颜色设置为自定义样式。最终的效果是,该文本字段将会显示为红色的自定义字体。
在本节中,我们已经介绍了如何定义和布局表单字段,以及如何定制和应用表单样式。在下一节中,我们将深入表单数据的预填充与验证,这是确保表单数据准确性和完整性的关键步骤。
# 3. PDF表单的交互式功能
## 3.1 交互式表单字段的创建
### 3.1.1 不同类型交互式字段介绍
在PDF表单中,交互式字段为用户提供了动态交互的能力,例如输入、选择、验证等操作。在ReportLab库中,我们可以创建多种类型的交互式字段,例如文本字段、复选框、单选按钮等。这些字段通过不同的方式与用户进行交云,增加了表单的灵活性和功能性。
- 文本字段:允许用户输入文本信息,可以限制字符类型和数量。
- 复选框:为用户提供多种选择,用户可以勾选零个或多个选项。
- 单选按钮:与复选框类似,但是用户只能选择一个选项。
- 列表框和组合框:提供一个下拉列表或一个可以滚动的列表,方便用户从预设选项中选择。
- 按钮:用于触发表单动作,如提交或重置表单。
### 3.1.2 字段的交互逻辑编写
交互逻辑是PDF表单的核心部分,它定义了字段之间如何相互作用以及用户输入如何被处理。在ReportLab中,我们使用`reportlab.lib.pagesizes`和`reportlab.pdfbase`等模块编写字段的交互逻辑。下面是一个简单的例子,展示如何创建一个文本输入框,并为其添加简单的验证逻辑。
```python
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.lib import colors
from reportlab.pdfgen.form填写 字段创建与逻辑编写
```
在这个例子中,我们首先创建了一个PDF文档,并添加了文本字段。然后,我们通过`setActionOnValidation`方法为文本字段添加了验证逻辑,当用户输入不符合要求时,会弹出提示。
## 3.2 表单动作与JavaScript集成
### 3.2.1 表单动作的种类和用法
表单动作是指在用户交互完成后,触发的一系列响应。在PDF中,这通常涉及到提交数据、导出数据或清空表单等操作。ReportLab允许将JavaScript代码集成到表单动作中,从而实现更复杂的逻辑处理。
- 提交表单:将表单数据发送到服务器或在本地处理。
- 重置表单:清除所有字段的值,将表单恢复到初始状态。
- 导出数据:将用户填写的表单数据保存到本地文件。
- 执行JavaScript:执行一段JavaScript代码来处理表单数据。
### 3.2.2 JavaScript在表单处理中的应用
JavaScript为PDF表单提供了强大的前端处理能力,能够在不与服务器交互的情况下,完成复杂的表单验证和数据处理。
```javascript
// 示例:使用JavaScript验证日期格式
var yourDateField = this.getField("dateField");
var dateString = yourDateField.value;
var datePattern = /^\d{4}-\d{2}-\d{2}$/;
if (datePattern.test(dateString)) {
// 日期格式正确
} else {
app.alert("日期格式错误!");
}
```
在这个JavaScript示例中,我们首先获取了一个名为`dateField`的日期输入字段,然后验证输入的日期字符串是否符合`YYYY-MM-DD`的格式。
## 3.3 表单提交与服务器通信
### 3.3.1 本地提交与远程提交的区别
表单提交可以分为本地提交和远程提交两种类型:
- 本地提交:用户填写表单后,数据会被保存到本地文件系统中。
- 远程提交:数据通过网络发送到远程服务器进行处理。
两种提交方式各有优势,本地提交通常用于不需要服务器处理的场景,而远程提交则适用于需要即时反馈和大数据处理的场景。
### 3.3.2 表单提交后的服务器处理逻辑
在远程提交中,服务器需要具备接收和处理表单数据的能力。通常,服务器端会使用如Python的Flask或Django,Java的Spring框架等来处理HTTP请求。
服务器端的处理逻辑可能包含以下步骤:
1. 解析接收到的表单数据。
2. 验证数据的完整性和正确性。
3. 将数据存储到数据库或进行其他处理。
4. 返回处理结果给客户端。
```python
# 示例:Flask处理表单提交的后端逻辑
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/submit_form', methods=['POST'])
def submit_form():
form_data = request.form.to_dict()
# 处理form_data
# 验证和存储逻辑
return jsonify({"status": "success"})
if __name__ == '__main__':
app.run(debug=True)
```
在这段Python Flask代码中,我们定义了一个路由`/submit_form`用于处理表单提交。当表单以POST请求提交时,服务器会解析表单数据并进行处理,最后返回一个成功状态的响应。
以上就是本章节对PDF表单的交互式功能的详细介绍,通过创建不同类型的交互式字段、与JavaScript的集成以及服务器通信,我们能够设计出既丰富又功能强大的表单应用。接下来的章节将聚焦在高级表单处理技巧上,帮助我们进一步优化和深化表单应用的使用体验。
# 4. 高级表单处理技巧
### 4.1 复杂表单的分页与导航
#### 4.1.1 多页表单的设计方法
在处理复杂的PDF表单时,单页设计往往无法满足需求,多页表单设计就显得尤为关键。多页表单的设计需要考虑页面的流畅转换和用户的填写体验。以下是一些关键的设计方法:
- **页面布局和导航逻辑**:设计时需要考虑表单的视觉布局,以确保用户能够轻松导航。通常,在表单的顶部或底部会放置一个导航条,指示当前页和总页数,方便用户定位自己所处的位置。
- **使用锚点进行跳转**:在ReportLab中,可以利用锚点(Bookmarks)实现表单内的快速跳转。锚点可以作为书签使用,当用户点击锚点时,页面会自动滚动到指定的位置。
- **预览功能的实现**:对于多页表单来说,提供一个预览功能可以大大提升用户体验。用户可以预览填写完成的表

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Python 库文件 ReportLab 为主题,提供了一系列全面的指南和教程,涵盖从入门到高级应用的各个方面。从构建 PDF 文档的基础知识到创建动态 PDF 的高级技巧,再到图表、图形、绘图工具的深入剖析,本专栏旨在帮助读者掌握 ReportLab 的强大功能。此外,还探讨了批量生成文档、动态 PDF 制作、样式管理、表单设计、文档安全、页面布局、图像处理、中文支持、多列布局、自动化报表生成和动态数据可视化等主题,为读者提供全方位的 ReportLab 学习体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
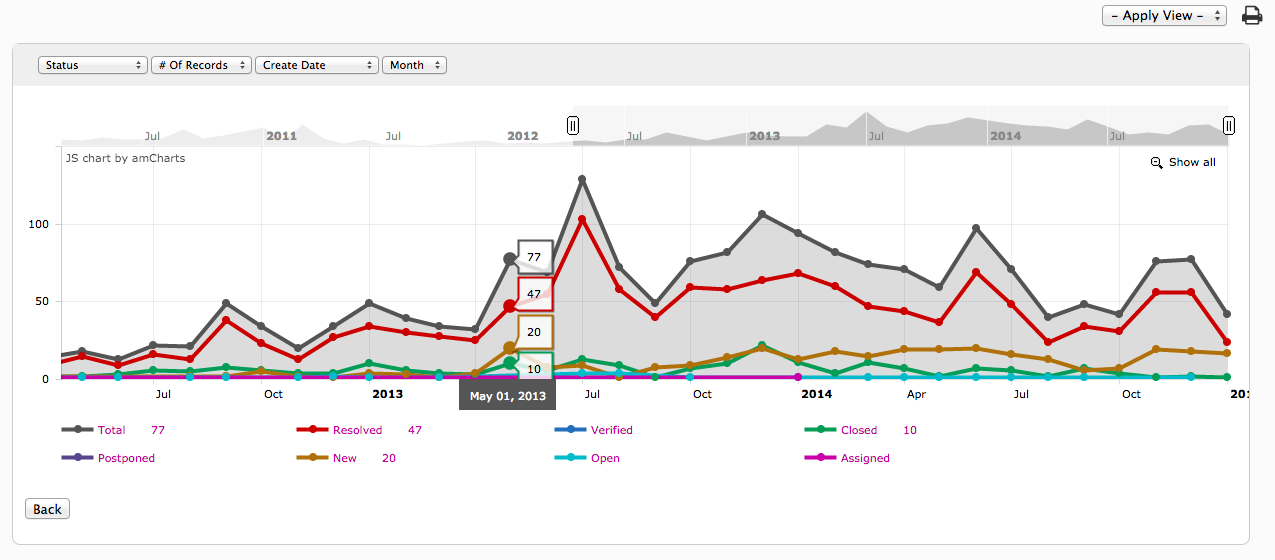
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
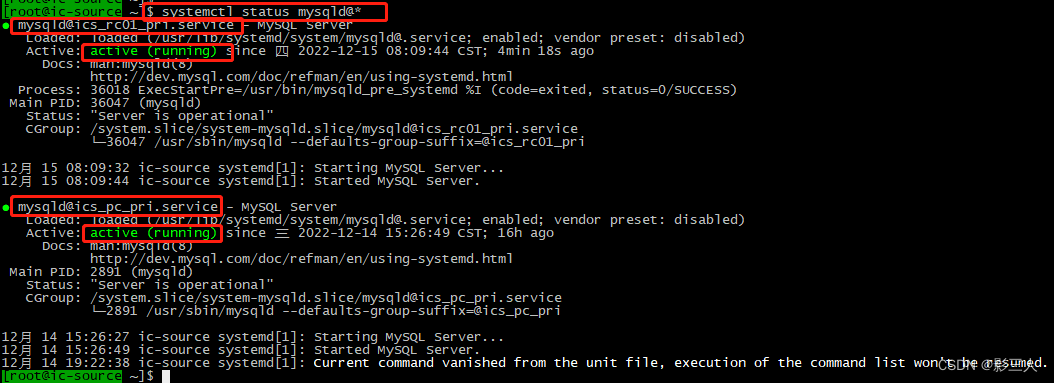
【MySQL日常维护】:运维专家分享的数据库高效维护策略
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
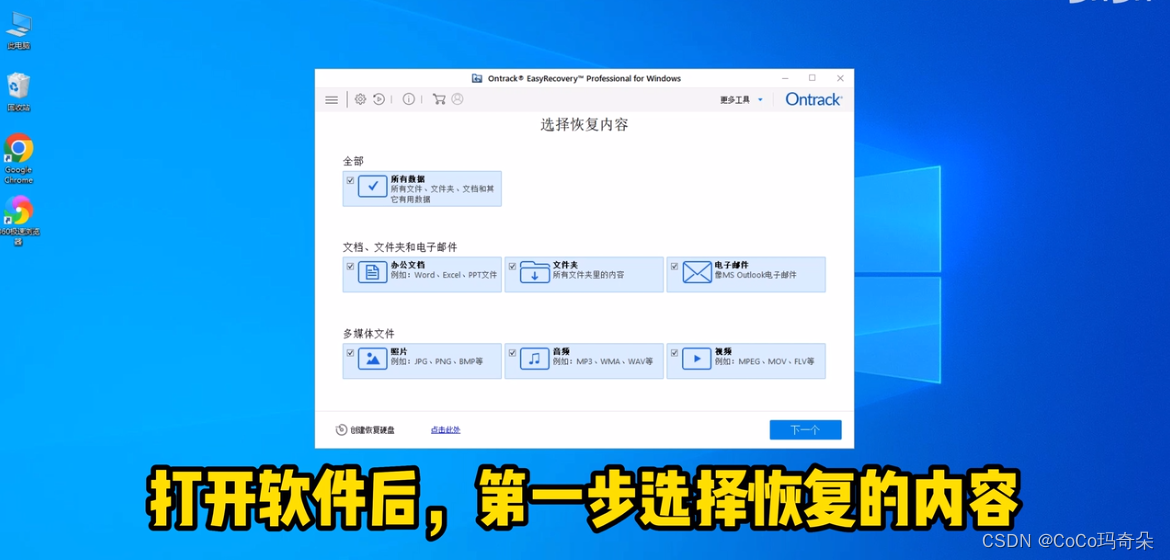
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
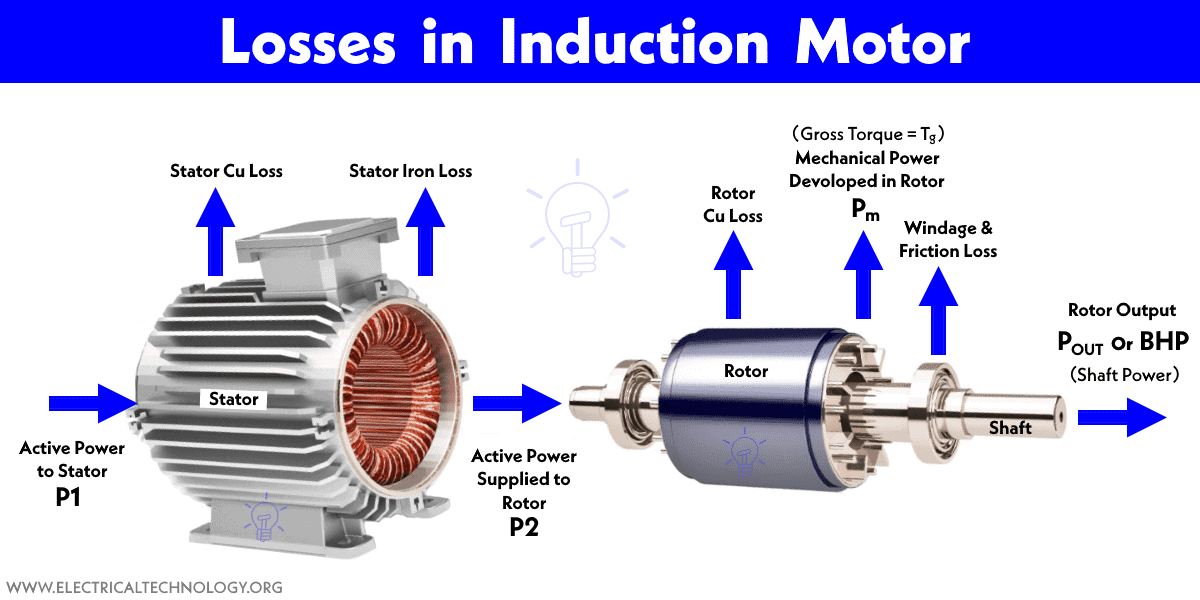
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )