初识Kudu:介绍并安装Apache Kudu
发布时间: 2023-12-19 20:33:51 阅读量: 42 订阅数: 49 

Apache Kudu 介绍
# 第一章:Kudu概述
## 1.1 什么是Apache Kudu
Apache Kudu是一个开源的、高性能的、分布式的列式存储引擎。它是一个在Hadoop生态系统中用于存储和分析数据的核心组件。Kudu结合了HDFS的可靠性和低成本存储以及HBase的快速随机访问能力,为用户提供了一个既支持分析又支持交互式分析的存储解决方案。
## 1.2 Kudu的特点和优势
- **高性能**: Kudu能够实现低延迟和高吞吐量的数据读写操作,尤其适用于实时分析和交互式分析场景。
- **低延迟**: Kudu能够在毫秒级别提供数据查询和分析的响应,适合需要实时决策支持的业务场景。
- **横向可扩展**: Kudu的分布式架构能够很容易地进行横向扩展,以支持大规模的数据存储和处理需求。
## 1.3 Kudu与传统存储引擎的对比
传统的存储引擎例如HDFS和HBase在一些场景下存在一些局限性,比如HDFS存储成本低、可靠性高,但不支持实时分析;HBase支持实时随机访问,但对于复杂的分析查询性能有限。Kudu能够在两者之间取得平衡,既提供了高性能的实时分析能力,又支持随机访问,使得它在大数据存储和分析领域有着独特的优势。
## 2. 第二章:Kudu的架构和组件
### 2.1 Master节点
Kudu的Master节点是集群的协调者,负责元数据的管理、负载均衡、故障转移和协调操作。它维护了整个集群的状态信息,包括表的模式(schema)、副本的分布和健康状况等。Master节点也负责接收和处理客户端和Tablet服务器的元数据变更请求,以及创建和删除Tablet服务器。在Kudu集群中,通常会有多个Master节点,通过Raft一致性算法来保证数据的一致性和高可用性。
### 2.2 Tablet服务器
Tablet服务器是Kudu集群中的工作节点,负责存储和管理数据。每个Tablet服务器负责管理一个或多个数据表的特定范围(range)的数据。它们负责数据的持久化、副本的复制以及处理客户端的读写请求。Tablet服务器之间会相互通信,以保证数据的一致性和高可用性。Kudu的数据存储是基于Raft协议的日志复制和状态机复制机制,确保数据的一致性和持久性。
### 2.3 数据模型
Kudu的数据模型是建立在分布式、高度可扩展的结构之上的。Kudu的表由一系列的行(row)和列(column)组成,支持按主键进行快速的随机访问(random access)。Kudu的行式存储和列式存储结合的数据模型,使得它可以同时满足随机访问和分析查询的需求。数据表可以定义复杂的数据模式,并支持范围查询等传统数据库的功能。Kudu的数据模型设计支持水平扩展,可以轻松应对大规模的数据存储和分析需求。
以上是Kudu架构和组件的介绍,下一步我们将探讨Kudu的安装准备。
### 3. 第三章:Kudu的安装准备
Apache Kudu作为一个高性能的存储引擎,它的安装和部署是非常重要的。在这一章节中,我们将详细讨论Kudu的安装准备工作。
#### 3.1 硬件和软件要求
在安装Kudu之前,我们需要确保硬件和软件满足一定的要求,以便保证Kudu的正常运行和性能表现。
##### 硬件要求
- CPU: 推荐使用多核处理器,以提供更好的并发处理能力。
- 内存: 至少8GB RAM,具体需求根据数据量和并发访问量进行调整。
- 存储: SSD固态硬盘,或者高性能的机械硬盘。
##### 软件要求
- 操作系统: Linux系统(例如CentOS、Ubuntu)、或者使用Docker容器进行部署。
- Java: 需要安装Java环境,Kudu是用Java编写的,因此依赖Java环境。
#### 3.2 部署环境准备
在进行Kudu的安装前,需要进行一些环境准备工作,包括网络设置、用户和权限设置等。
##### 网络设置
确保Kudu所在的服务器节点之间能够相互通信,建议配置静态IP地址以避免动态IP的变化导致通信异常。
##### 用户和权限设置
创建一个专门的用户用于运行Kudu服务,设置必要的权限以保证Kudu在运行过程中能够正常访问相关资源。
#### 3.3 安装Kudu
Kudu的安装分为两个部分:安装Kudu的软件包和配置Kudu的环境。
##### 安装Kudu软件包
可以通过源码编译、二进制包安装、Docker镜像等方式安装Kudu的软件包,选择适合自己的安装方式进行安装。
##### 配置Kudu的环境
安装完成后,需要进行一些必要的配置工作,包括修改配置文件、启动Kudu服务等。
### 4. 第四章:配置和管理Kudu
Apache Kudu的配置和管理是确保其高性能和稳定运行的关键步骤。本章将介绍Kudu的配置文件解析、节点的管理和监控以及如何将Kudu集成到Hadoop生态系统中。
#### 4.1 Kudu配置文件解析
Kudu使用多个配置文件来控制其行为。其中最重要的是`kudu-tserver.conf`和`kudu-master.conf`。这些文件通常位于`/etc/kudu/conf`目录下。
以下是一个简单的`kudu-tserver.conf`配置文件示例:
```bash
# Kudu Tablet Server configuration file
# Tablet server unique identifier
tserver_id=1
# Kudu master addresses
master_addresses=master1.example.com,master2.example.com,master3.example.com:7051
# The address and port on which this server should listen for HTTP requests
http_addresses=0.0.0.0
# Directory in which to store table data
data_dirs=/data/kudu/tablet
# Log directory
log_dir=/var/log/kudu/tserver
```
而`kudu-master.conf`的配置与`tserver.conf`类似,主要是指定Master节点的配置信息。
#### 4.2 Kudu节点的管理和监控
Kudu提供了一组命令行工具来管理和监控集群状态,其中包括`kudu`、`kudu-master`和`kudu-tserver`。通过这些工具可以进行集群状态查询、错误日志查看、节点启动和停止等操作。
例如,要启动一个Kudu Tablet Server,可以使用以下命令:
```bash
sudo service kudu-tserver start
```
要检查集群状态,可以使用以下命令:
```bash
kudu cluster ksck master1.example.com,master2.example.com,master3.example.com:7051
```
#### 4.3 集成Kudu到Hadoop生态系统
Kudu可以轻松集成到Hadoop生态系统中,与HDFS、Hive、Impala等组件协同工作,提供更加强大的数据存储和分析能力。
例如,可以使用`kudu-spark_2.x`包来实现Kudu与Spark的集成,从而在Spark中直接读写Kudu表数据。
```java
import org.apache.kudu.spark.kudu.KuduContext;
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession.builder().appName("KuduIntegration").getOrCreate();
KuduContext kuduContext = new KuduContext("kudu.master1.example.com:7051,kudu.master2.example.com:7051", spark.sparkContext());
// 读取Kudu表数据到DataFrame
Dataset<Row> kuduDF = spark.read().format("org.apache.kudu.spark.kudu").option("kudu.master", "kudu.master1.example.com:7051,kudu.master2.example.com:7051").option("kudu.table", "my_table").load();
// 在DataFrame中操作数据
kuduDF.createOrReplaceTempView("kudu_table");
spark.sql("SELECT * FROM kudu_table WHERE id = 100").show();
// 将DataFrame数据写入Kudu表
kuduDF.write().format("org.apache.kudu.spark.kudu").option("kudu.master", "kudu.master1.example.com:7051,kudu.master2.example.com:7051").option("kudu.table", "my_table").save();
```
通过以上步骤,可以将Kudu与Spark无缝集成,实现对Kudu表数据的读写操作。
### 第五章:Kudu的使用和应用
Kudu作为一个列式存储引擎,具有高性能和低延迟的特点,同时也支持随机访问,使其在数据存储和分析方面具有广泛的应用价值。本章将介绍Kudu的使用场景及应用案例,包括数据导入导出、数据分析和实际生产环境中的应用案例。
#### 5.1 Kudu的数据导入和导出
Kudu提供了多种方式进行数据导入和导出,包括Kudu客户端工具、Sqoop、Flume等工具的集成,以及各种编程语言的API。下面以Python为例,演示如何使用Kudu Python API进行数据的导入和导出。
```python
from kudu.client import Partitioning, FailIfRPCFails
import kudu
import random
# 连接Kudu master
client = kudu.connect(host='kudu_master_host', port=7051)
# 创建表对象
table_name = "sample_table"
schema = kudu.schema([
('id', int, 'primary key'),
('name', str)
])
partitioning = Partitioning().add_hash_partitions(column_names=['id'], num_buckets=3)
client.create_table(table_name, schema, partitioning)
# 打开表
table = client.table(table_name)
# 插入数据
session = client.new_session()
for i in range(10):
upsert = table.new_upsert()
upsert['id'] = random.randint(1, 100)
upsert['name'] = 'user' + str(i)
session.apply(upsert)
session.flush()
# 查询数据
scanner = table.scanner()
for row in scanner.read_rows():
print(row)
# 关闭连接
client.close()
```
代码说明:此Python代码演示了如何使用Kudu Python API创建表、插入数据、查询数据并关闭连接。
#### 5.2 使用Kudu进行数据分析
Kudu支持复杂的数据分析操作,包括聚合、连接、过滤等,可以通过各种编程语言的API或者SQL等方式进行数据分析。下面以Java为例,演示如何使用Kudu Java API进行数据分析。
```java
import org.apache.kudu.client.*;
public class KuduDataAnalysis {
public static void main(String[] args) {
KuduClient client = new KuduClient.KuduClientBuilder("kudu_master_host").defaultAdminOperationTimeoutMs(6000).build();
try {
KuduTable table = client.openTable("sample_table");
KuduScanner scanner = client.newScannerBuilder(table)
.setProjectedColumnNames("id", "name")
.build();
while (scanner.hasMoreRows()) {
RowResultIterator results = scanner.nextRows();
while (results.hasNext()) {
RowResult result = results.next();
System.out.println("id: " + result.getInt("id") + ", name: " + result.getString("name"));
}
}
} catch (KuduException e) {
e.printStackTrace();
} finally {
try {
client.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
}
```
代码说明:此Java代码演示了如何使用Kudu Java API进行数据分析,包括打开表、扫描数据并输出结果。
#### 5.3 Kudu在实际生产环境中的应用案例
Kudu在实际生产环境中具有广泛的应用价值,例如在数据仓库、实时分析、日志存储分析等方面均有应用案例。以下是一个简单的实际应用场景案例:
**场景:** 某公司需要存储并实时分析海量的日志数据,以便进行业务监控和优化。
**解决方案:** 公司选择使用Kudu作为日志数据的存储引擎,通过日志收集系统将日志数据实时写入Kudu表中,并使用Kudu的高性能和低延迟特点进行实时分析和查询。
**结果:** Kudu的高性能和低延迟确保了日志数据的快速存储和查询,使得公司能够及时监控业务状况并快速作出优化策略。
以上是Kudu在实际生产环境中的一个应用案例,表明了Kudu在大数据存储和分析方面的优势和应用前景。
## 第六章:Kudu的性能调优
在本章中,我们将深入讨论如何对Kudu进行性能调优,以确保其在实际应用中能够发挥最佳性能。
### 6.1 优化Kudu的读写性能
在实际应用中,我们经常需要对Kudu的读写性能进行优化,以确保系统能够快速响应和处理大规模数据。以下是一些优化建议:
#### 6.1.1 数据分布优化
可以通过合理的数据分布来优化读写性能。例如,可以将热点数据放置在更多的Tablet服务器上,从而减少单个Tablet服务器上的数据量,提高读写性能。
```python
# Python代码示例
# 优化数据分布
kudu_client.create_table(table_name, schema, partitioning=partitioning, replicas=3)
```
#### 6.1.2 使用压缩技术
Kudu支持对数据进行压缩存储,可以选择合适的压缩算法来减小数据存储空间,并提高读取性能。
```java
// Java代码示例
// 使用压缩技术
Table table = client.openTable(tableName);
ScanToken token = client.newScanTokenBuilder(table).
setRequestedSchema(schema).
setProjectedColumnNames(projectedColumnNames).
build();
```
#### 6.1.3 利用分区和副本
合理设置数据的分区和副本策略,可以有效地提高读写性能和容错能力。
```go
// Go语言代码示例
// 利用分区和副本
client.CreateTable(ctx, tableName, tableSchema, opt.PartitionByRange("hash(id, 16)"), opt.NumReplicas(3))
```
### 6.2 Kudu与查询性能优化
针对Kudu的查询性能,我们可以采取一些优化措施,以下是一些常见的优化方法:
#### 6.2.1 创建合适的索引
根据实际查询需求,创建合适的索引能够大幅提高查询性能。
```javascript
// JavaScript代码示例
// 创建索引
db.collection.createIndex( { "field": 1 } )
```
#### 6.2.2 使用数据分区键进行查询
利用数据分区键进行查询,可以减少扫描的数据量,提升查询性能。
```python
# Python代码示例
# 使用数据分区键进行查询
query = client.query(table)
query.add_predicate_key_column("id", ">=", 1000)
```
### 6.3 处理Kudu性能瓶颈的方法
当Kudu在实际应用中出现性能瓶颈时,我们需要有针对性地进行调优,以下是一些处理性能瓶颈的方法:
#### 6.3.1 监控和调优Master节点
通过监控Master节点的负载情况和性能指标,及时调优Master节点的资源配置,以应对潜在的性能瓶颈。
```java
// Java代码示例
// 监控Master节点性能
KuduMaster.getMetrics()
```
#### 6.3.2 Tablet服务器负载均衡
对于Tablet服务器的负载均衡也是处理性能瓶颈的重要手段,需要根据负载情况进行合理的调优。
```go
// Go语言代码示例
// Tablet服务器负载均衡
client.TabletBalancer.Run()
```
以上是Kudu性能调优的一些方法和建议,通过合理的读写优化、查询优化和处理性能瓶颈,可以使Kudu在实际应用中发挥最佳性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"Kudu"为主题,深入探讨了Apache Kudu在大数据处理和实时分析领域的应用。文章首先介绍了Kudu的基本概念与架构,并分享了安装部署的实践经验。随后详细阐述了在Kudu中进行表格设计、模式定义以及数据加载和写入性能优化的方法。此外,还深入讨论了数据读取、查询优化、数据压缩和存储优化等方面的实践经验。同时,还涵盖了Kudu与Hadoop生态系统的集成兼容性、实时数据分析与预测、负载均衡与性能调优、数据安全与权限管理、数据迁移与冷热数据分离策略等多个方面的内容。最后,还对Kudu与Spark的深度整合、流式数据处理、时间序列数据处理及与Kafka的数据流整合等具体应用场景进行了探讨,以及Kudu的容错与故障恢复机制分析和在物联网领域的数据存储与分析应用。通过本专栏的阅读,读者可以深入了解Kudu在实时大数据处理中的应用实践,并掌握相关的技术方法和实现策略。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【掌握UML用例图】:网上购物场景实战分析与最佳实践

# 摘要
统一建模语言(UML)用例图是软件工程中用于需求分析和系统设计的关键工具。本文从基础知识讲起,深入探讨了UML用例图在不同场景下的应用,并通过网上购物场景的实例,提供实战绘制技巧和最佳实践。文中对如何识别参与者、定义用例、以及绘制用例图的布局规则进行了系统化阐述,并指出了常见错误及修正方法。
电源管理对D类放大器影响:仿真案例精讲
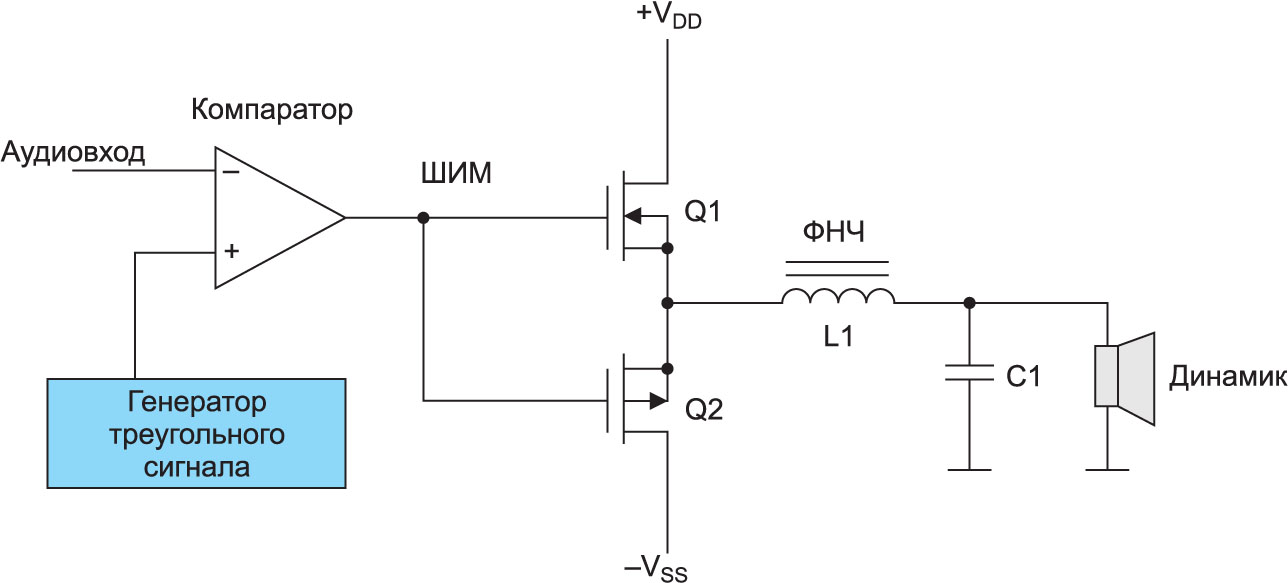
# 摘要
电源管理是确保电子系统高效稳定运行的关键环节,尤其在使用D类放大器时,其重要性更为凸显。本文首先概述了电源管理和D类放大器的基础理论,重点介绍了电源管理的重要性、D类放大器的工作原理及其效率优势,以及电源噪声对D类放大器性能的影响。随后,文章通过仿真实践展示了如何搭建仿真环境、分析电源噪声,并对D类放大器进行仿真优化。通过实例研究,本文探讨了电源管理在提升D类放大器性能方面的应用,并展望了未来新
【DirectX Repair工具终极指南】:掌握最新增强版使用技巧,修复运行库故障

# 摘要
本文对DirectX技术进行了全面的概述,并详细介绍了DirectX Repair工具的安装、界面解析以及故障诊断与修复技巧。通过对DirectX故障类型的分类和诊断流程的阐述,提供了常见故障的修复方法和对比分析。文章进一步探讨了工具的进阶使用,包括高级诊断工具的应用、定制修复选项和复杂故障案例研究。同时,本文还涉及到DirectX Repair工具的
全面解析:二级齿轮减速器设计的10大关键要点
# 摘要
本文全面阐述了二级齿轮减速器的设计与分析,从基础理论、设计要点到结构设计及实践应用案例进行了详细探讨。首先介绍了齿轮传动的原理、参数计算、材料选择和热处理工艺。接着,深入探讨了减速比的确定、齿轮精度、轴承和轴的设计,以及箱体设计、传动系统布局和密封润滑系统设计的关键点。文章还包含了通过静力学、动力学仿真和疲劳可靠性分析来确保设计的可靠性和性能。最后,通过工业应用案例分析和维护故障诊断,提出了二级齿轮减速器在实际应用中的表现和改进措施。本文旨在为相关领域工程师提供详尽的设计参考和实践指导。
# 关键字
齿轮减速器;传动原理;设计分析;结构设计;仿真分析;可靠性评估;工业应用案例
参
帧间最小间隔优化全攻略:网络工程师的实践秘籍

# 摘要
帧间最小间隔作为网络通信中的重要参数,对网络性能与稳定性起着关键作用。本文首先概述了帧间间隔的概念与重要性,随后探讨了其理论基础和现行标准,分析了网络拥塞与帧间间隔的关系,以及如何进行有效的调整策略。在实践章节中,本文详述了网络设备的帧间间隔设置方法及其对性能的影响,并分享了实时监控与动态调整的策略。通过案例分析,本文还讨论了帧间间隔优化在企业级网络中的实际应用和效果评估。最后,本文展望了帧间间隔优化的高级应
5G通信技术与叠层封装技术:揭秘最新研发趋势及行业地位

# 摘要
本文旨在探讨5G通信技术与叠层封装技术的发展及其在现代电子制造行业中的应用。首先概述了5G通信技术和叠层封装技术的基本概念及其在电子行业中的重要性。接着深入分析了5G通信技术的核心原理、实践应用案例以及面临的挑战和发展趋势。在叠层封装技术方面,本文论述了其理论基础、在半导体领域的应用以及研发的新趋势。最后,文章着重讨论了5G与叠层封装技术如何融合发展,以及它们共同对未来电子制造行业的
【Cadence设计工具箱】:符号与组件管理,打造定制化电路库
# 摘要
本文系统地介绍了Cadence设计工具箱的应用,从符号管理的基础技巧到高级技术,再到组件管理策略与实践,深入探讨了如何高效构建和维护定制化电路库。文中详细阐释了符号与组件的创建、编辑、分类、重用等关键环节,并提出了自动化设计流程的优化方案。此外,本文通过案例研究,展示了从项目需求分析到最终测试验证的整个过程,并对设计工具箱的未来发展趋势进行了展望,特别强调了集成化、兼容性以及用户体
TMS320F280系列电源管理设计:确保系统稳定运行的关键——电源管理必修课

# 摘要
本论文深入探讨了TMS320F280系列在电源管理方面的技术细节和实施策略。首先,概述了电源管理的基本理论及其重要性,接着详细分析了电源管理相关元件以及国际标准。在实践部分,文章介绍了TMS320F280系列电源管理电路设计的各个
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )