在Spring3.2中使用JDBC进行数据库操作
发布时间: 2023-12-15 06:47:33 阅读量: 28 订阅数: 35 

关于Spring的JDBC连接mysql.docx
## 章节一:介绍Spring3.2和JDBC
### 1.1 Spring3.2框架概述
Spring是一个轻量级的开源Java框架,主要用于构建企业级应用程序。它通过提供丰富的功能来简化Java开发,包括IoC(控制反转)、AOP(面向切面编程)、事务管理、数据访问等。
#### 控制反转(IoC)
控制反转是Spring框架的核心概念之一。它通过将对象之间的依赖关系的创建和管理交给外部容器来实现,从而解耦了应用程序的各个模块。
#### 面向切面编程(AOP)
面向切面编程是Spring框架的另一个重要特性。它通过在应用程序中插入切面(Aspect)来实现横切关注点的模块化,例如日志记录、事务管理等。
#### 数据访问
Spring框架提供了对各种数据访问技术的支持,包括JDBC、ORM(对象关系映射)、JPA(Java持久化API)等。其中,JDBC是一种常见的数据库访问技术,下面将对其进行简单介绍。
### 1.2 JDBC简介及在Spring中的作用
Java Database Connectivity(JDBC)是Java语言中用于与关系型数据库进行通信的API。它提供了一组接口和类,用于连接、查询和操作数据库。
在Spring框架中,JDBC被广泛应用于数据访问层(DAO)的开发。它提供了JdbcTemplate类,可以简化对数据库的操作,同时结合Spring的事务管理,可以实现更加简洁、安全的数据库访问。
### 章节二:配置Spring3.2环境
在开始使用Spring框架之前,我们需要配置Spring环境。本章将介绍如何配置Spring3.2的IoC容器和数据源。
#### 2.1 配置Spring IoC容器
Spring的IoC(Inversion of Control)容器是Spring的核心功能之一,它负责管理和装配应用程序中的对象。以下是配置Spring IoC容器的步骤:
首先,我们需要在项目中引入Spring的相关依赖。在Maven项目中,可以在`pom.xml`文件中添加以下依赖项:
```xml
<dependencies>
<!-- Spring Core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>3.2.0.RELEASE</version>
</dependency>
<!-- Spring Context -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.2.0.RELEASE</version>
</dependency>
</dependencies>
```
然后,我们需要创建一个Spring的配置文件,通常以`.xml`作为后缀名,例如`applicationContext.xml`。在配置文件中,定义和配置需要被IoC容器管理的Bean。
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 声明一个Bean -->
<bean id="userService" class="com.example.UserService">
<!-- 可以在这里配置Bean的属性 -->
<!-- <property name="propertyName" value="propertyValue"/> -->
</bean>
<!-- 声明其他的Bean -->
<!-- ... -->
</beans>
```
以上是一个简单的Spring配置文件示例,其中声明了一个`userService`的Bean。我们可以在这个配置文件中配置其他的Bean。
接下来,在应用程序的入口处(例如`main`方法或Servlet初始化方法)加载Spring的IoC容器:
```java
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
// 加载Spring的IoC容器
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
// 从容器中获取Bean
UserService userService = context.getBean("userService", UserService.class);
// 使用userService进行业务操作
// ...
}
}
```
通过调用`ClassPathXmlApplicationContext`的构造方法加载Spring的IoC容器,并通过`getBean`方法从容器中获取需要的Bean。
#### 2.2 配置数据源
在使用Spring进行数据库操作时,我们通常需要配置一个数据源。数据源是一个连接池,用于管理数据库连接。Spring可以集成常见的数据源,如Apache Commons DBCP、C3P0等。
在Spring中配置数据源的步骤如下:
首先,我们需要在项目中引入相应的数据源依赖。以使用Apache Commons DBCP数据源为例,在`pom.xml`文件中添加以下依赖项:
```xml
<dependencies>
<!-- Spring Core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>3.2.0.RELEASE</version>
</dependency>
<!-- Spring Context -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.2.0.RELEASE</version>
</dependency>
<!-- Apache Commons DBCP -->
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
</dependencies>
```
然后,在Spring的配置文件中配置数据源。以下是使用Apache Commons DBCP数据源的示例配置:
```xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 配置数据源 -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<!-- 数据库连接信息 -->
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mydb"/>
<property name="username" value="root"/>
<property name="password" value="password"/>
<!-- 连接池配置 -->
<property name="initialSize" value="5"/>
<property name="maxActive" value="10"/>
</bean>
</beans>
```
以上配置中,我们使用了Apache Commons DBCP数据源,并配置了数据

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Spring3.2》专栏涵盖了涉及Spring框架3.2版本的广泛主题,适合初学者和有经验的开发人员。专栏的文章从搭建第一个Spring应用入门,到深入探讨控制反转和依赖注入,讲解了Bean生命周期,构建可扩展的Web应用,进行面向切面编程,详解事务管理,实现面向接口编程,数据访问与持久化,以及整合JPA和Hibernate进行对象关系映射。另外,还包括了声明式事务管理,缓存提高应用性能,测试驱动开发,构建RESTful Web服务,实现安全认证和授权,国际化与本地化,消息驱动开发,构建分布式应用,以及异步编程提升应用性能等内容。无论您是想在Spring框架中构建应用程序还是解决特定问题,这个专栏都将为您提供有益的参考和指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【TongWeb配置精要】:结构分析与维护策略,专家级管理指南

# 摘要
本文详细介绍了TongWeb的架构、配置、高级配置、插件与模块管理、故障诊断与处理以及自动化管理与部署。首先概述了TongWeb的基础架构,并对其环境配置进行了深入探讨,包括系统的安装、部署、安全设置和性能优化。接着,文中阐述了负载均衡、集群配置、数据源与连接池管理、日志管理与监控等高级配置技巧。文章还涉及了插件与模块的安装、配置、开发、集成和维护策略,以及如何进行故障诊断和处理,预防性
【代码质量与重构的艺术】:提高软件可维护性的实践指南

# 摘要
代码质量是软件工程中的核心议题,它直接关系到软件的可维护性、可扩展性与长期稳定性。本文深入探讨了代码质量的评估与度量方法,以及重构的理论基础、实践技巧和工具支持。文中强调了定义和理解代码质量的重要性,并介绍了评估代码质量的多种方法,包括静态代码分析工具的使用。此外,本文详细论述了重构的定义、原则、模式、策略以
【STM32G030F6P6时钟系统深度解析】:保证系统稳定性与精确时序
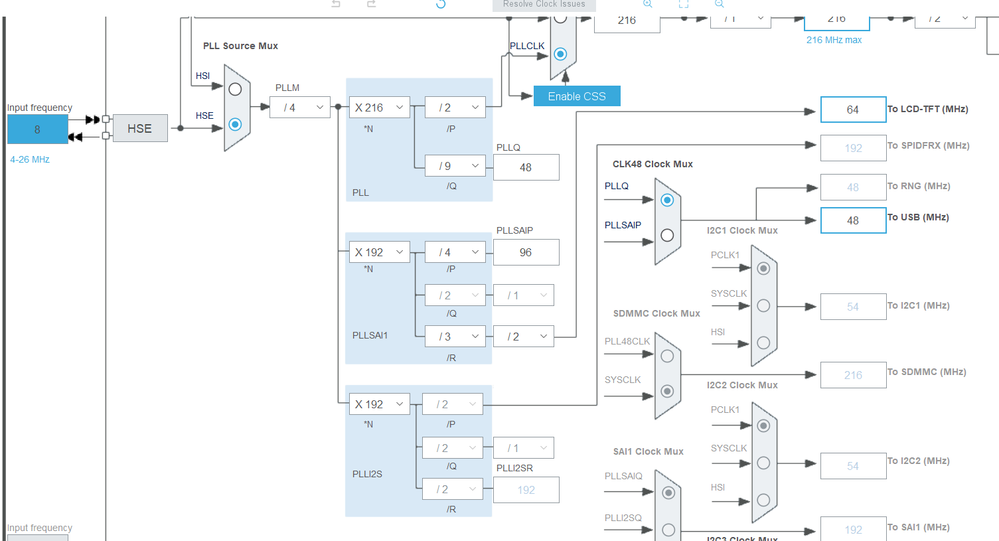
# 摘要
本文深入探讨了STM32G030F6P6微控制器的时钟系统设计与配置,涵盖了时钟源特性、时钟生成器设计、时钟域管理、时钟故障处理以及时钟精度和稳定性提升等多个方面。文章首先介绍了时钟系统的基础理论,详细解析了内部和外部时钟源,时钟生成器的原理和设计,以及同步时钟域的设计原则和交叉问题。接着,通
电气暂态分析提升篇:EMTP-ATP高级技巧大公开

# 摘要
本文旨在详细介绍电气暂态分析的基础理论、EMTP-ATP软件的建模技巧以及高级仿真功能,并探讨其在电力系统暂态分析中的实践应用。通过分析暂态与稳态的不同,数学描述暂态过程,并介绍电路元件模型及参数设定,本文深入阐述了如何利用EMTP-ATP进行电力网络拓扑分析和矩阵运算。进一步,本文讨论了如何使用EMTP-ATP模拟暂态过程、集成动态元
【数据挖掘工具箱实用指南】:掌握这10种工具提升挖掘效率

# 摘要
数据挖掘作为从大量数据中提取有用信息和知识的技术,对现代社会的信息处理和决策支持起着关键作用。本文从数据挖掘的基础知识和重要性讲起,深入探讨了数据预处理技术,包括数据清洗、转换技巧和特征工程。随后,详细剖析了分类、聚类、关联规则学习等常用数据挖掘算法,并介绍了R语言、Python和SQL等数据挖掘工具箱的实践应用。最后,文章还探索了深度学习在数据挖掘中的应用,文本分析技术,以
实时监控Fanuc机器人变量:5分钟学会数据捕捉与分析技巧!
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2019/k/O/Iu5DJVRBaPF31KVCjMMg/print-2019-03-08-11-47-27-a7oai.jpg)
# 摘要
本文全面介绍了实时监控Fa
色彩管理大师课:高分辨率显示屏中的色彩魔法

# 摘要
本文全面探讨了色彩管理的科学基础、技术应用和未来趋势。第一章介绍色彩理论及其感知机制,为理解色彩管理打下基础。第二章深入解析高分辨率显示屏技术,包括不同显示技术的特点和专业显示器的差异。第三章讨论软件与硬件在色彩管理中的协同工作,以及硬件校准和色彩同步的重要性。第四章专注于色彩空间的原理和转换技术,探讨如何通过颜色管
【PSAT动态仿真揭秘】:理论到实践的完整路径
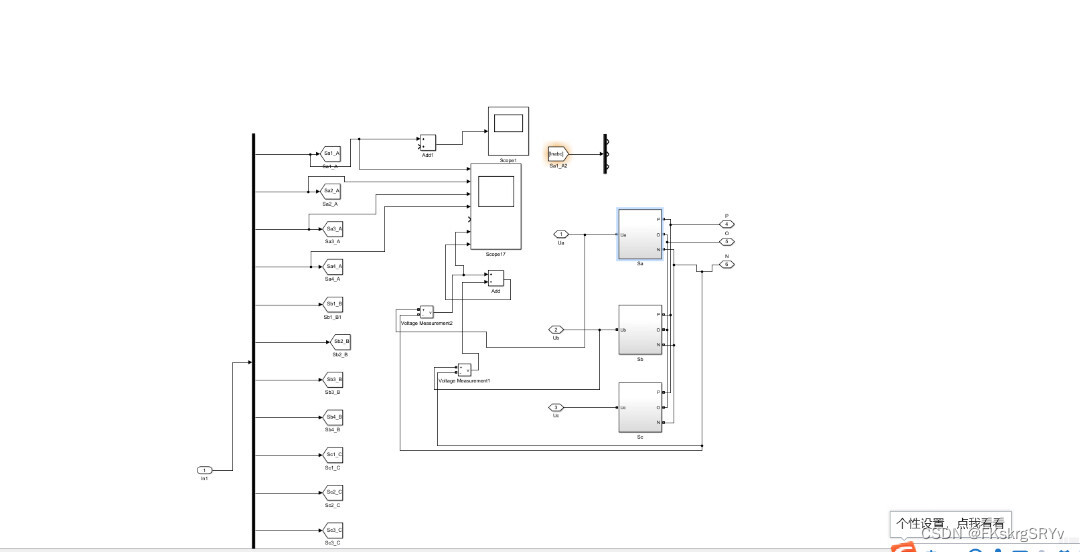
# 摘要
本文主要介绍了PSAT动态仿真的基础理论、工具安装与配置、仿真模型构建、在电力系统规划中的应用以及高级应用和未来展望。首先,对PSAT仿真工具的安装与配置进行详细介绍,包括系统兼容性要求、安装步骤、用户界面及基本操作和仿真参数的设置。接着,深入探讨了PSAT动态仿真模型的构建,包括电力系统元件模型的创建、系统稳定性和控制的仿真以及多机系统仿真的实现。此外,本文还分析了PSAT在电力系
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )