深入了解Kubernetes:简介与基本概念
发布时间: 2024-01-22 07:03:03 阅读量: 48 订阅数: 33 

kubernetes基础
# 1. 引言
## 1.1 什么是Kubernetes
Kubernetes是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。它提供了一种便捷的方式来管理容器,使得开发人员可以关注应用程序本身,而无需过多关注底层基础设施的细节。
Kubernetes通过定义和管理容器化应用程序的运行方式,实现了应用程序的自动化部署、自动扩展、自动修复和自动管理。它提供了一个可靠的容器编排平台,使得应用程序的部署和运维更加简单高效。
## 1.2 Kubernetes的应用背景
近年来,容器技术的迅速发展改变了应用程序的交付方式。传统的应用程序交付依赖于虚拟机或物理机,而容器技术将应用程序与其依赖的运行环境进行了隔离,使得应用程序具备了更高的可移植性和可扩展性。
然而,容器化应用程序的管理和运维也带来了一系列的挑战。容器的数量庞大,部署、扩展、管理和监控都需要进行有效的协调。这就需要一个容器编排平台来解决这些问题,而Kubernetes就是应对这些挑战的一个理想选择。
Kubernetes的出现极大地简化了容器化应用程序的管理和运维工作。它提供了诸多功能和工具,使得用户能够轻松地部署、扩展和管理容器化应用程序。同时,Kubernetes还具备高可靠性、伸缩性和可扩展性,能够适应不同规模和复杂度的应用场景。
在接下来的章节中,我们将深入探讨Kubernetes的基础知识、工作原理、高级功能,以及它在容器生态系统中的角色和应用案例。同时,我们还将分享一些Kubernetes的最佳实践,帮助读者更好地理解和使用这一先进的容器编排平台。
# 2. Kubernetes基础知识
Kubernetes是一个开源的容器编排引擎,用于自动化部署、扩展和操作应用程序容器。本章将介绍Kubernetes的基础知识,包括架构概述、核心概念解析和Kubernetes集群管理。
#### 2.1 架构概述
Kubernetes的架构分为Master节点和多个Worker节点。Master节点负责集群的控制管理,包括调度、控制器管理和资源管理等功能;而Worker节点则负责运行应用程序容器,接收Master节点的指令并执行。
#### 2.2 核心概念解析
##### 2.2.1 Pod
Pod是Kubernetes中最小的调度单位,它可以包含一个或多个紧密关联的容器。这些容器共享网络和存储,它们被一起部署、扩展、迁移和删除。以下是一个Pod的示例yaml配置文件:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
```
##### 2.2.2 Service
Service定义了一组Pod的访问规则,通常用于暴露一个应用程序的网络服务。它可以根据标签选择器找到匹配的Pod,并为其分配一个稳定的网络地址。以下是一个Service的示例yaml配置文件:
```yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
```
##### 2.2.3 ReplicaSet
ReplicaSet确保指定数量的Pod副本始终在运行。当Pod意外终止或被删除时,ReplicaSet会自动创建新的Pod副本以替换它。以下是一个ReplicaSet的示例yaml配置文件:
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
```
##### 2.2.4 Deployment
Deployment管理Pod的部署,它可以对ReplicaSet进行升级和扩展,从而实现应用程序的滚动更新。以下是一个Deployment的示例yaml配置文件:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:1.17
ports:
- containerPort: 80
```
#### 2.3 Kubernetes集群管理
Kubernetes集群通常由Master节点和多个Worker节点组成,通过kubectl命令行工具或Kubernetes API进行管理。在集群中,Master节点负责管理整个集群的状态,而Worker节点负责运行工作负载。集群管理员可以通过Master节点进行资源调度、监控和故障排除等操作,以确保集群的稳定和健壮运行。
以上是Kubernetes基础知识的介绍,下一章将深入探讨Kubernetes的工作原理。
# 3. Kubernetes的工作原理
Kubernetes是一个分布式的容器编排平台,它由Master节点和Worker节点组成,通过不同的控制器和调度器来管理和调度容器的运行。本章将介绍Kubernetes的工作原理,包括Master节点与Worker节点、控制器的作用与类型、调度器的作用与策略,以及服务发现与负载均衡。
### 3.1 Master节点与Worker节点
Kubernetes的Master节点是整个集群的控制中心,负责管理和调度集群中的各个Worker节点,以及监控和管理Pod、Service、ReplicaSet等资源。Master节点通常包括以下组件:
- API Server(API服务器):提供Kubernetes集群的API接口,其他组件通过API Server进行通信和交互。
- Scheduler(调度器):负责决定将新创建的Pod调度到哪个Worker节点上运行。
- Controller Manager(控制器管理器):包含多个控制器,负责处理集群中各种资源的自动化操作和管理,例如创建或删除Pod。
- etcd(分布式键值数据库):用于存储集群的配置信息和状态。
Worker节点是实际运行应用程序和容器的主机,每个Worker节点上都会运行一个称为kubelet的服务,负责管理单个节点上的容器和镜像。Worker节点通常包括以下组件:
- kubelet:负责将Master节点分配的Pod在节点上创建和管理。
- Container Runtime(容器运行时):负责运行容器,常见的容器运行时包括Docker、containerd等。
- kube-proxy:负责为Pod提供网络代理和负载均衡功能。
### 3.2 控制器的作用与类型
控制器是Kubernetes中的重要组件,负责保证集群中各种资源的目标状态与实际状态一致。控制器通过不断地监听集群中的变化和事件,对资源进行操作和管理,以确保集群处于期望的状态。
Kubernetes提供了多种类型的控制器,包括以下几种常见的类型:
- ReplicationController:用于确保Pod的副本数与期望值一致。
- ReplicaSet:是ReplicationController的升级版,提供更丰富的选择条件和管理方式。
- Deployment:用于管理应用程序的部署,支持滚动升级和回滚操作。
- StatefulSet:用于管理有状态应用程序,确保Pod的唯一性和稳定性。
- DaemonSet:用于在集群的每个节点上运行一个Pod的副本,常用于运行后台任务等。
### 3.3 调度器的作用与策略
调度器是Kubernetes集群中非常重要的组件,负责将新创建的Pod调度到合适的Worker节点上运行。调度器根据集群中各个节点的资源利用率、节点负载等因素进行决策,选择最佳的节点进行调度。
Kubernetes的调度器采用策略插件的方式进行调度决策,可以根据实际需求选择不同的策略。常见的调度策略包括:
- 指定节点调度:将Pod调度到指定的节点上运行。
- 资源需求调度:根据Pod的资源需求(如CPU、内存)匹配合适的节点。
- 节点亲和性调度:根据节点的标签进行匹配,将具有特定标签的Pod调度到匹配的节点上。
- 节点污点和容忍度调度:节点污点是一个阻碍Pod被调度的标记,而容忍度是Pod对节点污点的忽略程度。
### 3.4 服务发现与负载均衡
Kubernetes提供了内建的服务发现和负载均衡功能,可以实现应用程序的高可用和水平扩展。
- Service:Kubernetes的Service可以将一组具有相同标签的Pod作为一个逻辑组进行管理,提供统一的访问入口和服务发现机制。
- 负载均衡:Kubernetes的Service可以通过集群内部的负载均衡器,将请求均衡分发给后端的Pod副本,提供高可用的服务。
- Ingress:Ingress是Kubernetes集群中用于配置HTTP和HTTPS路由的一种资源对象,可以将外部的HTTP或HTTPS请求路由到不同的Service上。
以上就是Kubernetes的工作原理介绍,包括Master节点与Worker节点、控制器的作用与类型、调度器的作用与策略,以及服务发现与负载均衡的功能。通过对这些概念和原理的理解,可以更好地使用和管理Kubernetes集群。
# 4. Kubernetes的高级功能
Kubernetes作为一个成熟的容器编排平台,不仅提供了基本的容器管理能力,还提供了许多高级功能,帮助用户更好地管理和运维容器化应用。本章将介绍一些Kubernetes的高级功能和使用方法。
### 4.1 水平扩展与自动缩容
在容器化应用中,根据负载情况动态地扩展或缩小应用实例的数量非常重要。Kubernetes提供了水平扩展和自动缩容的功能,可以根据一定的条件来自动调节应用实例的数量。
#### 4.1.1 水平扩展
Kubernetes使用ReplicaSet来管理应用的实例数量。通过调整ReplicaSet的副本数,可以实现水平扩展应用的能力。下面是一个示例的ReplicaSet定义:
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:latest
```
在上面的示例中,设置`replicas: 3`即可将`myapp`的实例数量扩展到3个。
#### 4.1.2 自动缩容
Kubernetes还可以根据一定的条件自动缩小应用的实例数量。例如,可以根据CPU利用率或内存占用率来判断是否需要缩小实例数量。
```yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-autoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 75
```
上面的示例定义了一个水平自动缩放的配置,通过设置`targetAverageUtilization`来指定CPU利用率的阈值,当CPU利用率超过阈值时,自动缩小实例数量。
### 4.2 滚动升级与回滚
在进行应用升级时,需要保证应用的可用性。Kubernetes提供了滚动升级和回滚的功能,可以在不中断服务的情况下进行应用的升级和回滚操作。
#### 4.2.1 滚动升级
滚动升级是指逐步替换应用实例的过程,通过控制升级速度和检查升级结果,保证应用能够平稳过渡。可以通过Deployment来实现滚动升级,示例如下:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v2
```
在上面的示例中,设置`maxSurge`为1表示允许同时创建新的实例,`maxUnavailable`为1表示允许同时关闭的旧的实例。
#### 4.2.2 回滚
当应用升级出现问题时,需要及时回滚到上一个版本以保证应用的稳定性。Kubernetes提供了回滚机制,可以快速回退到之前的版本。
```bash
kubectl rollout undo deployment/myapp
```
执行上述命令即可回滚到上一个版本的应用。
### 4.3 状态监控与日志管理
在运维容器化应用时,状态监控和日志管理是非常重要的。Kubernetes集成了多种监控和日志系统,可以帮助用户更好地了解应用的运行状态和进行故障排查。
### 4.4 安全与权限控制
安全和权限控制是容器化平台的核心要素之一。Kubernetes提供了多种安全机制,例如身份认证、权限控制、网络策略等,可以保障应用和集群的安全。
## 结语
本章介绍了Kubernetes的一些高级功能,包括水平扩展与自动缩容、滚动升级与回滚、状态监控与日志管理以及安全与权限控制。这些功能能够帮助用户更好地管理和运维容器化应用,提高应用的可靠性和安全性。在实际使用中,根据具体的需求和场景,可以选择合适的功能来满足业务需求。
# 5. Kubernetes生态系统
Kubernetes作为一个开源的容器管理平台,在生态系统中有着丰富的支持和整合,涵盖了容器运行时、存储管理、网络管理、监控与日志系统等方面。本章将对Kubernetes生态系统进行介绍和分析。
#### 5.1 容器运行时(Container Runtime)
容器运行时是Kubernetes集群中用于运行容器的软件组件,它负责创建和管理容器。常见的容器运行时包括Docker、containerd、cri-o等。Kubernetes支持多种容器运行时,用户可以根据自身需求选择合适的容器运行时用于集群管理。
#### 5.2 存储管理
在Kubernetes中,存储管理扮演着至关重要的角色。它包括持久化存储和临时存储,用于容器中数据的存储和管理。Kubernetes提供了多种存储卷类型,如emptyDir、hostPath、NFS、Ceph等,并支持动态存储卷的创建和管理,使得存储资源的调度和管理更加灵活和高效。
#### 5.3 网络管理
Kubernetes的网络管理是保证容器间通信和外部访问的关键组成部分。Kubernetes网络模型主要包括Pod间通信、Pod与Service的通信、集群内部和集群外部的通信等。常见的Kubernetes网络方案包括Flannel、Calico、Cilium等,它们提供了不同的网络拓扑和功能特性,用户可以根据需求选择合适的网络方案。
#### 5.4 监控与日志系统
在Kubernetes集群中,监控与日志系统对于实时监控集群状态、分析问题和故障排查非常重要。Prometheus、Grafana、ELK Stack等是常用的Kubernetes监控和日志系统组件,它们可以实现集群资源利用率监控、日志收集和分析、告警通知等功能,为Kubernetes集群的稳定运行提供了有力支持。
以上是Kubernetes生态系统的主要内容,它们为Kubernetes的稳定运行和持续发展提供了强大的支持和解决方案。
# 6. 使用案例与最佳实践
在本章中,我们将探讨一些使用Kubernetes的实际案例和最佳实践。
### 6.1 使用Kubernetes部署应用程序
使用Kubernetes部署应用程序是Kubernetes最常见和基础的使用方式之一。下面我们将以一个Python Flask应用为例,介绍如何使用Kubernetes进行应用程序的部署。
首先,我们需要编写一个Dockerfile来构建我们的应用程序的Docker镜像。下面是一个示例的Dockerfile:
```dockerfile
FROM python:3.8
WORKDIR /app
COPY requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY . /app
CMD [ "python", "app.py" ]
```
接下来,我们可以使用Docker命令构建并推送镜像到Docker Hub:
```bash
docker build -t your-image-name:tag .
docker push your-image-name:tag
```
然后,在Kubernetes中创建一个Deployment和一个Service来部署我们的应用程序。下面是一个示例的Deployment资源文件:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: your-deployment
spec:
replicas: 3
selector:
matchLabels:
app: your-app
template:
metadata:
labels:
app: your-app
spec:
containers:
- name: your-container
image: your-image-name:tag
ports:
- containerPort: 5000
```
创建Deployment:
```bash
kubectl apply -f your-deployment.yaml
```
接下来,我们需要创建一个Service,使得应用程序能够被访问到。下面是一个示例的Service资源文件:
```yaml
apiVersion: v1
kind: Service
metadata:
name: your-service
spec:
selector:
app: your-app
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
```
创建Service:
```bash
kubectl apply -f your-service.yaml
```
现在,我们的应用程序已经成功部署到Kubernetes集群中了。我们可以通过访问Service的外部IP来访问应用程序。
### 6.2 多集群管理与跨云平台部署
Kubernetes支持多集群管理,可以将多个Kubernetes集群组合在一起,形成一个大规模的容器化管理平台。这为应用程序的部署和管理提供了更高的灵活性和可靠性。
另外,Kubernetes也支持跨云平台部署,可以在不同的云厂商平台上部署和管理应用程序。这为企业提供了更大的选择权和灵活性。
首先,我们需要创建一个Kubernetes集群并将其添加到管理平台中。可以使用以下命令来创建一个新的集群:
```bash
kubeadm init
```
然后,我们需要将其他的集群添加到管理平台中。可以使用以下命令来添加新的集群:
```bash
kubeadm join --token YOUR_TOKEN YOUR_MASTER_NODE_IP:YOUR_MASTER_NODE_PORT
```
最后,我们可以使用Kubectl命令来管理这些集群:
```bash
kubectl config use-context YOUR_CONTEXT
kubectl get nodes
kubectl get pods --all-namespaces
```
通过以上步骤,我们就可以在一个管理平台中管理多个Kubernetes集群了。
### 6.3 最佳实践分享
在使用Kubernetes的过程中,我们可以遵循一些最佳实践来提高应用程序的可靠性和性能。
首先,我们可以使用健康检查来监控应用程序的状态,并自动进行故障恢复。Kubernetes提供了Readiness Probe和Liveness Probe来实现健康检查。
其次,我们可以使用Horizontal Pod Autoscaling来实现应用程序的自动水平扩展和缩容。这可以根据流量和负载情况来调整应用程序的副本数量。
此外,我们可以使用滚动升级和回滚来更新应用程序的版本。Kubernetes的Deployment资源提供了滚动升级和回滚的功能,可以确保应用程序的升级过程不会中断服务。
最后,我们可以使用监控和日志系统来监控应用程序的运行情况和进行故障排查。Kubernetes的生态系统中有很多监控和日志系统,如Prometheus和EFK等。
通过以上最佳实践,我们可以更好地管理和运维我们的应用程序。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入探索Kubernetes和Linux-pod的生命周期与健康检测高级应用,并提供一系列相关文章。首先,我们将了解Kubernetes的简介与基本概念,并从零开始搭建Kubernetes集群。随后,我们将深入研究Kubernetes中的调度策略,优化Pod资源分配与管理,并探讨弹性伸缩和自动扩展的实现。此外,我们还将介绍Kubernetes中的服务发现与负载均衡机制,以及Pod安全性与策略设置。另外,我们将详细讲解Linux容器技术,包括Docker和Containerd,以及Kubernetes中的健康检测机制和使用Liveness Probe与Readiness Probe。我们还将深入研究Kubernetes中的故障检测与自愈机制,以及Pod状态管理与调节。最后,我们将研究基于Kubernetes的应用更新与滚动发布策略,以及多集群管理与跨集群通信的实施。通过本专栏,您将全面了解Kubernetes和Linux-pod的高级应用与管理技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
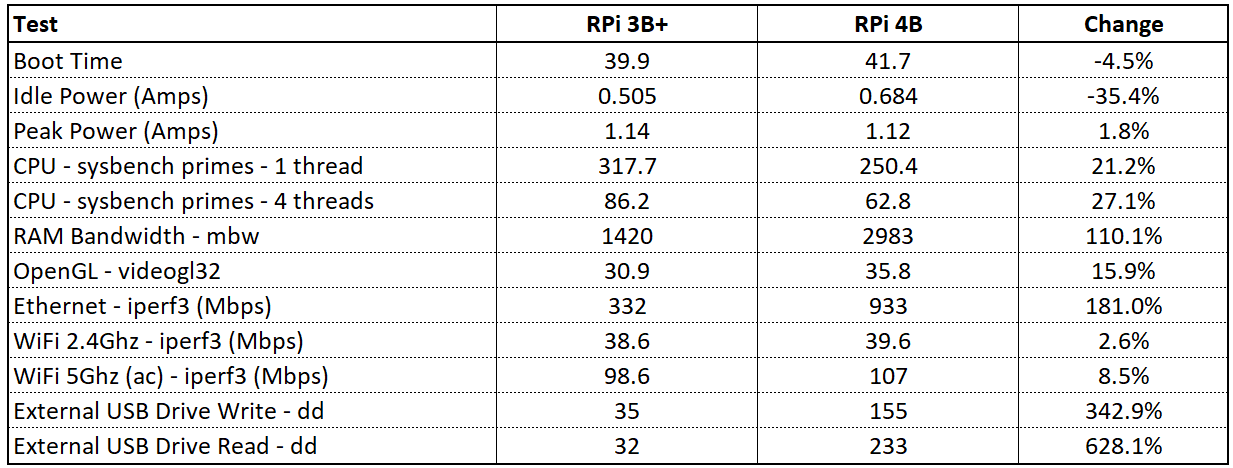
Odroid XU4与Raspberry Pi比较分析
# 摘要
本文详细比较了Odroid XU4与Raspberry Pi的硬件规格、操作系统兼容性、性能测试与应用场景分析,并进行了成本效益分析。通过对比处理器性能、内存存储能力、扩展性和连接性等多个维度,揭示了两款单板计算机的优劣。文章还探讨了它们在图形处理、视频播放、科学计算和IoT应用等方面的实际表现,并对初次购买成本与长期运营维护成本进行了
WinRAR CVE-2023-38831漏洞全生命周期管理:从漏洞到补丁

# 摘要
WinRAR CVE-2023-38831漏洞的发现引起了广泛关注,本文对这一漏洞进行了全面概述和分析。我们深入探讨了漏洞的技术细节、成因、利用途径以及受影响的系统和应用版本,评估了漏洞的潜在风险和影响等级。文章还提供了详尽的漏洞应急响应策略,包括初步的临时缓解措施、长期修复
【数据可视化个性定制】:用Origin打造属于你的独特图表风格

# 摘要
随着数据科学的发展,数据可视化已成为传达复杂信息的关键手段。本文详细介绍了Origin软件在数据可视化领域的应用,从基础图表定制到高级技巧,再到与其他工具的整合,最后探讨了最佳实践和未来趋势。通过Origin丰富的图表类型、强大的数据处理工具和定制化脚本功能,用户能够深入分析数据并创建直观的图表。此外,本文还探讨了如何利用Origin的自动化和网络功能实现高效的数据可视化协作和分享。通
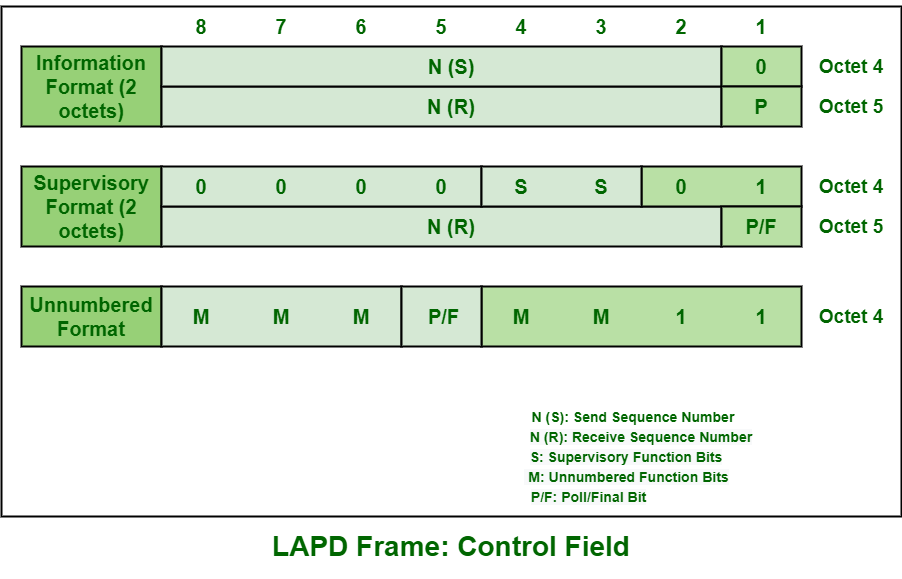
【初学者到专家】:LAPD与LAPDm帧结构的学习路径与进阶策略
# 摘要
本文全面阐述了LAPD(Link Access Procedure on the D-channel)和LAPDm(LAPD modified)协议的帧结构及其相关理论,并深入探讨了这两种协议在现代通信网络中的应用和重要性。首先,对LAPD和LAPDm的帧结构进行概述,重点分析其组成部分与控制字段。接着,深入解析这两种协议的基础理论,包括历史发展、主要功能与特点
医学成像革新:IT技术如何重塑诊断流程

# 摘要
本文系统探讨了医学成像技术的历史演进、IT技术在其中的应用以及对诊断流程带来的革新。文章首先回顾了医学成像的历史与发展,随后深入分析了IT技术如何改进成像设备和数据管理,特别是数字化技术与PACS的应用。第三章着重讨论了IT技术如何提升诊断的精确性和效率,并阐述了远程医疗和增强现实技术在医学教育和手术规划中的应用。接着,文章探讨了数据安全与隐私保护的挑战,以及加密
TriCore工具链集成:构建跨平台应用的链接策略与兼容性解决

# 摘要
本文对TriCore工具链在跨平台应用构建中的集成进行了深入探讨。文章首先概述了跨平台开发的理论基础,包括架构差异、链接策略和兼容性问题的分析。随后,详细介绍了TriCore工具链的配置、优化以及链接策略的实践应用,并对链接过程中的兼容性
【ARM调试技巧大公开】:在ARMCompiler-506中快速定位问题

# 摘要
本文详述了ARM架构的调试基础,包括ARM Compiler-506的安装配置、程序的编译与优化、调试技术精进、异常处理与排错,以及调试案例分析与实战。文中不仅提供安装和配置ARM编译器的具体步骤,还深入探讨了代码优化、工具链使用、静态和动态调试、性能分析等技术细节。同时,本文还对ARM异常机制进行了解
【远程桌面工具稳定安全之路】:源码控制与版本管理策略
# 摘要
本文系统地介绍了远程桌面工具与源码控制系统的概念、基础和实战策略。文章首先概述了远程桌面工具的重要性,并详细介绍了源码控制系统的理论基础和工具分类,包括集中式与分布式源码控制工具以及它们的工作流程。接着,深入讨论了版本管理策略,包括版本号规范、分支模型选择和最佳实践。本文还探讨了远程桌面工具源码控制策略中的安全、权限管理、协作流程及持续集成。最后,文章展望了版本管理工具与
【网络连接优化】:用AT指令提升MC20芯片连接性能,效率翻倍(权威性、稀缺性、数字型)

# 摘要
随着物联网设备的日益普及,MC20芯片在移动网络通信中的作用愈发重要。本文首先概述了网络连接优化的重要性,接着深入探讨了AT指令与MC20芯片的通信原理,包括AT指令集的发展历史、结构和功能,以及MC20芯片的网络协议栈。基于理论分析,本文阐述了AT指令优化网络连接的理论基础,着重于网络延迟、吞吐量和连接质量的评估。实
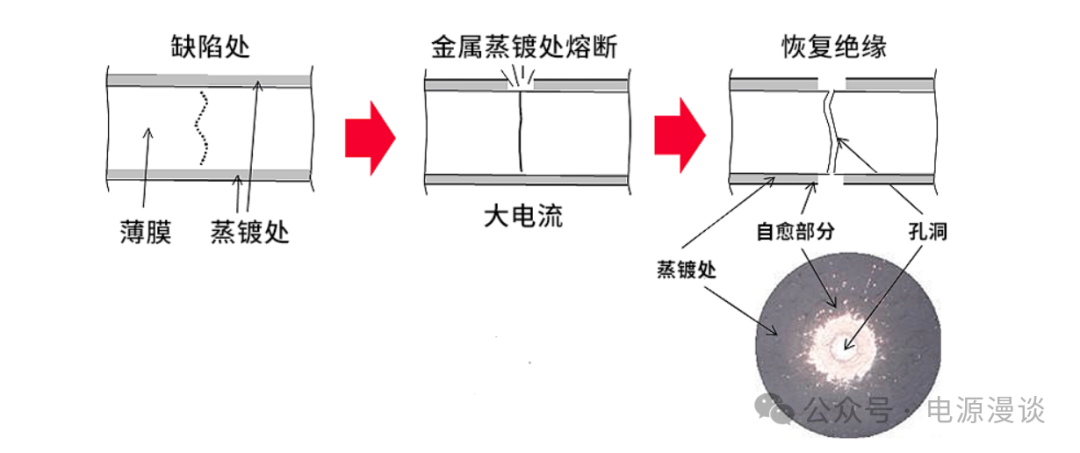
【系统稳定性揭秘】:液态金属如何提高计算机物理稳定性
# 摘要
随着计算机硬件性能的不断提升,计算机物理稳定性面临着前所未有的挑战。本文综述了液态金属在增强计算机稳定性方面的潜力和应用。首先,文章介绍了液态金属的理论基础,包括其性质及其在计算机硬件中的应用。其次,通过案例分析,探讨了液态金属散热和连接技术的实践,以及液态金属在提升系统稳定性方面的实际效果。随后,对液态金属技术与传统散热材
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )