R语言中的金融时间序列数据建模与预测
发布时间: 2024-02-21 02:08:54 阅读量: 1358 订阅数: 130 

R语言进行时间序列分析
# 1. 金融时间序列数据简介
## 1.1 金融时间序列数据的特点
金融时间序列数据是指在特定时间间隔内收集的金融资产价格、交易量、利率等数据。它具有以下特点:
- 非平稳性:金融时间序列数据通常表现出非平稳性,即均值和方差会随时间发生变化。
- 波动性聚集性:金融时间序列数据存在波动性聚集的现象,即波动性的增加或减少往往会持续一段时间。
- 长尾分布:金融时间序列数据的分布往往呈现出长尾分布,即存在较大的极端值。
- 季节性和周期性:金融时间序列数据可能受到季节性和周期性因素的影响,呈现周期性波动。
## 1.2 金融时间序列数据在R语言中的应用
在R语言中,有丰富的金融时间序列数据分析包可供使用,如quantmod、rugarch、forecast等。这些包提供了丰富的函数和工具,方便用户进行金融时间序列数据的处理、分析和建模。同时,R语言也提供了强大的可视化工具,对金融时间序列数据进行直观展示和分析。接下来,我们将介绍在R语言中如何进行金融时间序列数据的分析和建模。
# 2. R语言中的金融时间序列数据分析基础
金融时间序列数据分析是金融领域中非常重要的一部分,通过对时间序列数据的分析可以揭示出数据的规律性及变化趋势,为投资决策提供依据。在R语言中,有丰富的金融时间序列数据分析工具和包,可以方便地进行数据处理、可视化和建模分析。
### 2.1 金融时间序列数据的载入与处理
在R语言中,可以使用`quantmod`等包来加载金融时间序列数据,并进行基本的数据处理。以下是一个简单的示例代码,演示了如何加载并处理金融时间序列数据:
```R
# 安装并加载quantmod包
install.packages("quantmod")
library(quantmod)
# 载入金融时间序列数据
getSymbols("AAPL", from = "2010-01-01", to = "2020-01-01")
head(AAPL)
# 计算收益率
AAPL_returns <- dailyReturn(AAPL$AAPL.Close)
head(AAPL_returns)
```
在这段代码中,首先安装并加载了`quantmod`包,然后使用`getSymbols`函数加载了苹果(AAPL)股票的时间序列数据,接着计算了该股票的每日收益率。
### 2.2 金融时间序列数据的可视化分析
使用R语言可以进行多样化的金融时间序列数据可视化分析,例如绘制股票价格走势图、收益率分布图等。以下是一个简单的示例代码,展示了如何绘制股票价格走势图:
```R
# 绘制股票价格走势图
chartSeries(AAPL, theme = "white")
```
这段代码通过`chartSeries`函数可视化了苹果股票的价格走势图,并可以根据需要进行个性化定制。
通过这些基本的数据载入、处理和可视化方法,我们可以更好地理解金融时间序列数据的特点和规律,为后续的建模和预测工作打下基础。
# 3. 金融时间序列数据建模
在金融领域,时间序列数据建模是非常重要的,通过建立合适的模型可以帮助分析者更好地理解数据变动的规律,并做出有效的预测。以下将介绍金融时间序列数据建模中常用的两种模型:ARIMA 模型和 GARCH 模型。
#### 3.1 ARIMA 模型在金融时间序列数据中的应用
ARIMA 模型(AutoRegressive Integrated Moving Average Model)是一种经典的时间序列预测模型,通过对时间序列数据的自回归项、差分项和移动平均项进行组合,可以很好地拟合许多非平稳时间序列数据。
##### 代码示例(Python):
```python
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
# 载入金融时间序列数据
data = pd.read_csv('financial_data.csv')
# 拟合 ARIMA 模型
model = ARIMA(data, order=(5,1,0))
model_fit = model.fit()
# 打印模型的统计信息
print(model_fit.summary())
```
该代码示例中,我们首先载入金融时间序列数据,然后使用 ARIMA 模型拟合数据,并输出模型的统计信息,包括参数估计、显著性检验等。
#### 3.2 GARCH 模型在金融时间序列数据中的应用
GARCH 模型(Generalized Autoregressive Conditional Heteroskedasticity Model)是用来描述时间序列方差异方差不稳定性的模型,特别适用于金融时间序列数据中存在波动聚集(volatility clustering)的情况。
##### 代码示例(Java):
```java
import org.apache.commons.math3.distribution.NormalDistribution;
import org.apache.commons.math3.stat.regression.SimpleRegression;
import org.apache.commons.math3.stat.descriptive.moment.Variance;
// 载入金融时间序列数据
double[] data = {10.2, 9.8, 10.5, 11.3, 12.1};
// 拟合 GARCH 模型
SimpleRegression regression = new SimpleRegression();
for (int i = 0; i < data.length; i++) {
regression.addData(i, data[i]);
}
double beta = regression.getSlope();
// 计算方差
Variance variance = new Variance();
double var = variance.evaluate(data);
// 计算正态分布下的置信区间
NormalDistribution normal = new NormalDistribution();
double lowerBound = beta - normal.inverseCumulativeProbability(0.975) * Math.sqrt(var);
double upperBound = beta + normal.inverseCumulativeProbability(0.975) * Math.sqrt(var);
```
在这段 Java 代码示例中,我们使用 GARCH 模型拟合金融时间序列数据,并计算出回归系数的置信区间,以评估模型的稳健性。
通过对 ARIMA 和 GARCH 模型的学习与实践,我们可以更好地掌握金融时间序列数据的特点和规律,为数据建模与预测提供有力支持。
# 4. 金融时间序列数据预测
在金融领域,时间序列数据的预测是至关重要的。通过建立预测模型,可以帮助投资者做出更明智的决策,降低投资风险。本章将重点讨论金融时间序列数据预测的方法和案例。
#### 4.1 预测模型的建立与评估
在金融时间序列数据预测中,常用的模型包括ARIMA、GARCH等。我们首先需要建立模型,然后对模型进行评估,以确保预测结果的可靠性。
```python
# 以ARIMA模型为例进行金融时间序列数据预测
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error
# 载入金融时间序列数据
data = pd.read_csv('financial_data.csv')
# 拆分训练集和测试集
train_data = data[:100]
test_data = data[100:]
# 建立ARIMA模型
model = ARIMA(train_data['Price'], order=(5,1,0))
model_fit = model.fit(disp=0)
# 预测未来数据
predictions = model_fit.forecast(steps=len(test_data))[0]
# 评估模型
mse = mean_squared_error(test_data['Price'], predictions)
print("均方误差(MSE):", mse)
```
通过以上代码,我们使用ARIMA模型对金融时间序列数据进行预测,并计算出预测结果与实际结果之间的均方误差作为评估指标。
#### 4.2 金融时间序列数据预测案例分析
接下来,我们将结合实际的金融时间序列数据,进行预测案例分析,以展示预测模型的实际效果。
```python
# 以股票价格预测为例进行案例分析
# 载入股票价格数据
stock_data = pd.read_csv('stock_prices.csv')
# 训练ARIMA模型
model = ARIMA(stock_data['Close'], order=(2,1,2))
model_fit = model.fit(disp=0)
# 预测未来股票价格
predictions = model_fit.forecast(steps=30)[0]
# 可视化预测结果
plt.plot(stock_data['Close'], label='Actual')
plt.plot(range(len(stock_data), len(stock_data)+30), predictions, label='Predicted')
plt.legend()
plt.show()
```
通过以上代码,我们对股票价格进行了预测,并利用可视化工具展示了预测结果与实际结果的对比,以便更直观地评估预测效果。
# 5. 金融时间序列数据建模与预测的实际应用
在本章中,我们将通过两个具体的案例分析,展示金融时间序列数据建模与预测在实际应用中的效果与价值。
#### 5.1 股票价格预测案例分析
在这个案例中,我们将使用历史股票价格数据,建立预测模型,并对未来股票价格进行预测。首先,我们将载入并处理股票价格的时间序列数据,然后通过可视化分析对数据进行初步了解。接下来,我们将尝试不同的建模方法,并使用评估指标对模型的效果进行评估。最后,我们将展示模型的预测结果,并对预测效果进行分析和总结。
#### 5.2 利率变动预测案例分析
在这个案例中,我们将以利率变动数据为例,展示金融时间序列数据建模与预测的实际应用。我们将通过载入利率变动数据,并进行数据处理和可视化分析,来了解利率变动的特征与规律。然后,我们将尝试应用不同的建模方法,例如 ARIMA 模型和 GARCH 模型,来建立利率变动的预测模型。最后,我们将使用实际数据进行预测,并对预测结果进行评估和总结。
通过这两个具体的案例分析,我们将深入探讨金融时间序列数据建模与预测的实际应用,以及在股票价格预测和利率变动预测等领域的价值与挑战。这也将帮助我们更好地理解金融时间序列数据分析的方法与技巧,并为实际问题的解决提供参考与启发。
以上是第五章的内容,希望对你有所帮助。
# 6. 结语与展望
金融时间序列数据建模与预测的挑战与机遇
金融时间序列数据建模与预测是一个充满挑战与机遇的领域。随着金融市场的复杂性不断增加,金融时间序列数据的预测需求也日益增长。然而,金融时间序列数据的非线性、高频波动性和异常值等特点,给建模与预测带来了较大的挑战。
未来发展趋势与建议
在未来,随着人工智能、大数据分析和量化投资等技术的不断发展,金融时间序列数据建模与预测将迎来更多的机遇。建议在模型建立过程中,更加注重对数据的质量和特征提取,结合深度学习、强化学习等技术,建立更加准确、稳健的预测模型,以应对金融市场的复杂变化。
以上是第六章的内容。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《R金融数据分析实践》专栏涵盖了广泛而深入的R语言应用领域,从基础到实践,覆盖了数据分析、数据可视化、数据清洗以及建模技术等方面。我们将带领读者逐步掌握R语言中的数据结构及其应用,深入了解数据导入与清洗技巧,并探索数据分析、机器学习算法在金融领域的应用。此外,我们还会探讨高频数据处理、投资组合优化、股票市场交易策略优化等内容,以及金融资产定价模型、风险因子分析、时间序列数据建模与预测等专题。通过本专栏,读者将全面提升在金融数据分析领域的技术实力,深入了解如何利用R语言处理金融大数据并应用于实际的金融业务中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ZW10I8性能提升秘籍:专家级系统升级指南,让效率飞起来!
# 摘要
ZW10I8系统作为当前信息技术领域的关键组成部分,面临着性能提升与优化的挑战。本文首先对ZW10I8的系统架构进行了全面解析,涵盖硬件和软件层面的性能优化点,以及性能瓶颈的诊断方法。文章深入探讨了系统级优化策略,资源管理,以及应用级性能调优的实践,强调了合理配置资源和使用负载均衡技术的重要性。此外,本文还分析了ZW10I8系统升级与扩展的
【ArcGIS制图新手速成】:7步搞定标准分幅图制作

# 摘要
本文详细介绍了使用ArcGIS软件进行制图的全过程,从基础的ArcGIS环境搭建开始,逐步深入到数据准备、地图编辑、分幅图制作以及高级应用技巧等各个方面。通过对软件安装、界面操作、项目管理、数据处理及地图制作等关键步骤的系统性阐述,本文旨在帮助读者掌握ArcGIS在地理信息制图和空间数据分析中的应用。文章还提供了实践操作中的问题解决方案和成果展示技
QNX Hypervisor故障排查手册:常见问题一网打尽
# 摘要
本文首先介绍了QNX Hypervisor的基础知识,为理解其故障排查奠定理论基础。接着,详细阐述了故障排查的理论与方法论,包括基本原理、常规步骤、有效技巧,以及日志分析的重要性与方法。在QNX Hypervisor故障排查实践中,本文深入探讨了启动、系统性能及安全性方面的故障排查方法,并在高级故障排查技术章节中,着重讨论了内存泄漏、实时性问题和网络故障的分析与应对策略。第五章通过案例研究与实战演练,提供了从具体故障案例中学习的排查策略和模拟练习的方法。最后,第六章提出了故障预防与系统维护的最佳实践,包括常规维护、系统升级和扩展的策略,确保系统的稳定运行和性能优化。
# 关键字
Q
SC-LDPC码构造技术深度解析:揭秘算法与高效实现

# 摘要
本文全面介绍了SC-LDPC码的构造技术、理论基础、编码和解码算法及其在通信系统中的应用前景。首先,概述了纠错码的原理和SC-LDPC码的发展历程。随后,深入探讨了SC-LDPC码的数学模型、性能特点及不同构造算法的原理与优化策略。在编码实现方面,本文分析了编码原理、硬件实现与软件实现的考量。在解码算法与实践中
VisualDSP++与实时系统:掌握准时执行任务的终极技巧
# 摘要
本文系统地介绍了VisualDSP++开发环境及其在实时系统中的应用。首先对VisualDSP++及其在实时系统中的基础概念进行概述。然后,详细探讨了如何构建VisualDSP++开发环境,包括环境安装配置、界面布局和实时任务设计原则。接着,文章深入讨论了VisualDSP++中的实时系
绿色计算关键:高速串行接口功耗管理新技术

# 摘要
随着技术的不断进步,绿色计算的兴起正推动着对能源效率的重视。本文首先介绍了绿色计算的概念及其面临的挑战,然后转向高速串行接口的基础知识,包括串行通信技术的发展和标准,以及高速串行接口的工作原理和对数据完整性的要求。第三章探讨了高速串行接口的功耗问题,包括功耗管理的重要性、功耗测量与分析方法以及功耗优化技术。第四章重点介绍了功耗管理的新技术及其在高速串行接口中
MK9019数据管理策略:打造高效存储与安全备份的最佳实践
# 摘要
随着信息技术的飞速发展,数据管理策略的重要性日益凸显。本文系统地阐述了数据管理的基础知识、高效存储技术、数据安全备份、管理自动化与智能化的策略,并通过MK9019案例深入分析了数据管理策略的具体实施过程和成功经验。文章详细探讨了存储介质与架构、数据压缩与去重、分层存储、智能数据管理以及自动化工具的应用,强调了备份策略制定、数据安全和智能分析技术
【电脑自动关机脚本编写全攻略】:从初学者到高手的进阶之路
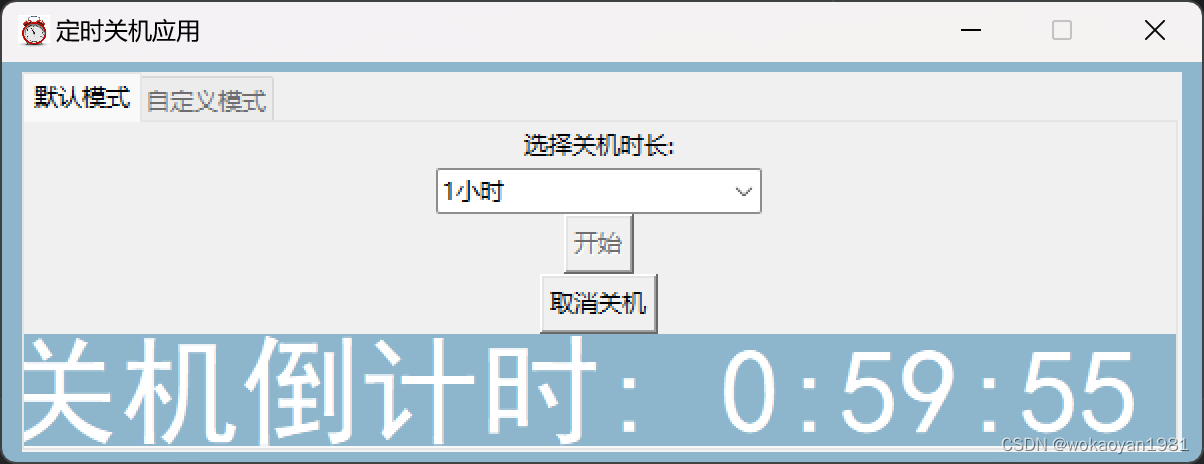
# 摘要
本文系统介绍了电脑自动关机脚本的全面知识,从理论基础到高级应用,再到实际案例的应用实践,深入探讨了自动关机脚本的原理、关键技术及命令、系统兼容性与安全性考量。在实际操作方面,本文详细指导了如何创建基础和高级自动关机脚本,涵盖了脚本编写、调试、维护与优化的各个方面。最后,通过企业级和家庭办公环境中的应用案例,阐述了自动关机脚本的实际部署和用户教育,展望了自动化技术在系统管理中的未来趋势,包
深入CU240BE2硬件特性:进阶调试手册教程

# 摘要
CU240BE2作为一款先进的硬件设备,拥有复杂的配置和管理需求。本文旨在为用户提供全面的CU240BE2硬件概述及基本配置指南,深入解释其参数设置的细节和高级调整技巧,
BRIGMANUAL性能调优实战:监控指标与优化策略,让你领先一步
# 摘要
本文全面介绍了BRIGMANUAL系统的性能监控与优化方法。首先,概览了性能监控的基础知识,包括关键性能指标(KPI)的识别与定义,以及性能监控工具和技术的选择和开发。接着,深入探讨了系统级、应用和网络性能的优化策略,强调了硬件、软件、架构调整及资源管理的重要性。文章进一步阐述了自动化性能调优的流程,包括测试自动化、持续集成和案例研究分析。此外,探讨了在云计算、大
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )