Spark SQL简介与基本概念
发布时间: 2024-01-23 15:26:39 阅读量: 47 订阅数: 36 
# 1. 简介
## 1.1 Spark SQL的背景
在大数据处理领域,Spark SQL是一个重要的组件,它提供了类似于SQL的语法来操作分布式数据集。Spark SQL的出现,使得开发人员可以使用熟悉的SQL语言来进行大数据处理,极大地简化了数据处理的复杂性。
## 1.2 Spark SQL的定义
Spark SQL是Apache Spark生态系统中的一个组件,它提供了用于结构化数据处理的接口。通过Spark SQL,用户可以使用SQL语言进行数据查询、数据分析和数据处理。
## 1.3 Spark SQL的优势
Spark SQL具有以下优势:
- **统一的数据访问**:Spark SQL可以同时处理结构化数据和半结构化数据,而且可以通过统一的编程模型进行处理。
- **性能优化**:Spark SQL内置了Catalyst优化器和Tungsten引擎,可以对查询进行优化,提高查询性能。
- **与Hive集成**:Spark SQL可以与Hive集成,可以直接访问Hive中的数据,并且支持Hive的元数据操作。
- **动态分区与分桶**:Spark SQL支持动态分区和分桶表,可以提高数据查询的效率。
# 2. 基本概念
Spark SQL是Apache Spark生态系统中的一个重要组件,可以提供结构化数据处理和关系型查询功能。在使用Spark SQL之前,我们需要了解一些基本概念,包括数据源、数据集和DataFrame。
### 2.1 数据源
数据源是指存储数据的位置,可以是本地文件系统、Hadoop分布式文件系统(HDFS)、关系型数据库(如MySQL、PostgreSQL)、NoSQL数据库(如Cassandra、MongoDB)等。Spark SQL支持多种数据源,可以通过简单的接口进行数据的读取和保存操作。
### 2.2 数据集(Dataset)
数据集(Dataset)是Spark SQL中最基本的概念之一,它是由一组分布式的数据对象组成的,每个数据对象包含多个命名的列,列的类型可以是原始类型(如整数、字符串等)或复杂类型(如数组、结构体等)。数据集提供了一种高效的数据操作接口,可以进行转换、过滤、排序等操作。
### 2.3 DataFrame
DataFrame是Spark SQL中非常重要的一个概念,它是由一组以命名列为基础的分布式数据集组成的,可以以表格的形式表示数据,类似于关系型数据库中的表。DataFrame可以从不同的数据源中读取数据,并进行类似于SQL的操作,例如查询、过滤、排序、聚合等。
在Spark SQL中,数据集和DataFrame的关系比较密切,DataFrame实际上是对数据集的一个高级封装,提供了更多的操作方式和优化能力。可以说,DataFrame是Spark SQL中最常用和最重要的概念之一。
```python
# 示例代码:创建DataFrame
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder \
.appName("DataFrameExample") \
.getOrCreate()
# 从JSON文件中加载数据,创建DataFrame
df = spark.read.json("data/people.json")
# 显示DataFrame的内容
df.show()
```
上述示例代码中,首先创建了一个SparkSession对象,然后使用`read.json()`方法从JSON文件中加载数据,最后使用`show()`方法显示DataFrame的内容。通过这种方式,我们可以轻松地将外部数据加载为DataFrame,后续可以对DataFrame进行各种查询和操作。
总结:在第二章节中,我们介绍了Spark SQL中的基本概念,包括数据源、数据集和DataFrame。数据源是存储数据的位置,可以是本地文件系统、HDFS、数据库等;数据集是由一组分布式的数据对象组成的,提供了高效的数据操作接口;DataFrame是由一组以命名列为基础的分布式数据集组成的,可以以表格的形式表示数据,并提供了类似于SQL的操作方式。在实际应用中,我们可以通过代码加载外部数据,并将其转换为DataFrame,方便后续进行各种查询和操作。
# 3. 数据加载与保存
在使用Spark SQL进行数据分析时,通常需要先将数据加载进来进行处理。Spark SQL支持多种格式的数据加载和保存方式,包括CSV、JSON、Parquet、JDBC等。
#### 3.1 读取数据
```python
# 读取CSV文件
df_csv = spark.read.csv("data.csv", header=True, inferSchema=True)
# 读取JSON文件
df_json = spark.read.json("data.json")
# 读取Parquet文件
df_parquet = spark.read.format("parquet").load("data.parquet")
# 读取JDBC数据
df_jdbc = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/test") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("dbtable", "table_name") \
.option("user", "username") \
.option("password", "password") \
.load()
```
#### 3.2 数据加载的方法
Spark SQL支持以下几种数据加载方法:
- `read.csv(path, options...)`:读取CSV格式的数据。
- `read.json(path, options...)`:读取JSON格式的数据。
- `read.parquet(path, options...)`:读取Parquet格式的数据。
- `read.format(source).load(path, options...)`:读取自定义格式的数据。
- `read.jdbc(url, table, options...)`:读取JDBC数据。
#### 3.3 数据保存的方法
```python
# 保存数据为CSV文件
df_csv.write.csv("data.csv")
# 保存数据为JSON文件
df_json.write.json("data.json")
# 保存数据为Parquet文件
df_parquet.write.parquet("data.parquet")
# 保存数据到JDBC数据库
df_jdbc.write.format("jdbc").option("url", "jdbc:mysql://localhost:3306/test") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("dbtable", "table_name") \
.option("user", "username") \
.option("password", "password") \
.save()
```
Spark SQL支持以下几种数据保存方法:
- `write.csv(path, options...)`:保存数据为CSV格式。
- `write.json(path, options...)`:保存数据为JSON格式。
- `write.parquet(path, options...)`:保存数据为Parquet格式。
- `write.format(source).save(path, options...)`:保存数据为自定义格式。
- `write.jdbc(url, table, options...)`:保存数据到JDBC数据库。
# 4. 数据查询与操作
Spark SQL提供了强大的数据查询和操作功能,包括基本查询语句、数据过滤与排序、聚合与分组等操作。
### 4.1 基本查询语句
在Spark SQL中,我们可以使用类似SQL的语法进行数据查询。下面是一个简单的示例,演示如何使用Spark SQL进行数据查询:
```python
# 创建一个DataFrame
data = [("Alice", 25), ("Bob", 30), ("Tom", 20)]
df = spark.createDataFrame(data, ["name", "age"])
# 注册为临时表
df.createOrReplaceTempView("people")
# 使用SQL查询语句
result = spark.sql("SELECT * FROM people WHERE age > 25")
# 显示结果
result.show()
```
代码解析:
- 首先,我们创建了一个DataFrame,包含了姓名和年龄两列。
- 然后,我们通过`createOrReplaceTempView`方法将DataFrame注册为了一个临时表,表名为"people"。
- 接着,我们使用`spark.sql`方法执行了一条SQL查询语句,查询符合年龄大于25的人。
- 最后,我们调用`show`方法显示查询结果。
### 4.2 数据过滤与排序
除了基本的查询语句,Spark SQL还提供了丰富的数据过滤与排序功能。下面是一些常用的示例:
#### 数据过滤
```python
# 过滤年龄大于25的人
result = df.filter(df.age > 25)
# 过滤姓名以'A'开头的人
result = df.filter(df.name.startswith("A"))
# 过滤年龄大于25并且姓名以'A'开头的人
result = df.filter((df.age > 25) & df.name.startswith("A"))
```
#### 数据排序
```python
# 按照年龄升序排序
result = df.sort(df.age.asc())
# 按照年龄降序排序
result = df.sort(df.age.desc())
# 按照年龄和姓名升序排序
result = df.sort(df.age.asc(), df.name.asc())
```
### 4.3 聚合与分组
Spark SQL支持丰富的聚合与分组操作,可以对数据进行统计计算。下面是一些常用的示例:
#### 聚合操作
```python
# 计算年龄的平均值
result = df.agg({"age": "avg"})
# 计算年龄的最大值和最小值
result = df.agg({"age": "max", "age": "min"})
# 计算每个姓名对应的年龄平均值
result = df.groupBy("name").agg({"age": "avg"})
```
#### 分组操作
```python
# 按照姓名进行分组,并计算每个分组的平均年龄
result = df.groupBy("name").avg("age")
# 按照姓名和年龄进行分组,并计算每个分组的平均年龄和最大年龄
result = df.groupBy("name", "age").agg({"age": "avg", "age": "max"})
```
代码解析:
- 聚合操作通过`agg`函数来实现,可以对指定的列进行统计计算。
- 分组操作通过`groupBy`函数来实现,可以按照指定的列进行分组。
以上就是Spark SQL中数据查询与操作的一些常用功能示例。根据实际需求,我们可以灵活运用这些功能来处理和分析数据。
# 5. 高级功能
在本章中,我们将探讨Spark SQL的一些高级功能,包括UDF和UDAF的使用、与Hive的集成、以及动态分区与分桶的应用。
### 5.1 UDF和UDAF
Spark SQL提供了用户定义函数(UDF)和用户定义聚合函数(UDAF)的功能,可以方便地扩展SQL的功能。
**UDF(User Defined Function)**
UDF允许用户自定义函数,在SQL查询中使用这些函数来处理数据。下面是一个使用Python编写的UDF的示例,计算给定字符串的长度:
```python
from pyspark.sql.functions import udf
# 定义一个UDF
def calculate_length(s):
return len(str(s))
# 注册UDF
calculate_length_udf = udf(calculate_length)
# 使用UDF进行查询
df.select("name", calculate_length_udf("name").alias("name_length")).show()
```
上述代码中,我们定义了一个名为`calculate_length`的函数,通过`udf`函数将其转换为UDF,并通过`alias`为结果列指定一个名称。
**UDAF(User Defined Aggregation Function)**
UDAF允许用户自定义聚合函数,在SQL查询中使用这些函数对数据进行聚合操作。下面是一个使用Java编写的UDAF的示例,计算给定列的平均值:
```java
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
public class AverageUDAF extends UserDefinedAggregateFunction {
// 定义输入数据类型
public StructType inputSchema() {
return new StructType()
.add("value", DataTypes.DoubleType);
}
// 定义中间缓存数据类型
public StructType bufferSchema() {
return new StructType()
.add("sum", DataTypes.DoubleType)
.add("count", DataTypes.LongType);
}
// 定义输出结果类型
public DataType dataType() {
return DataTypes.DoubleType;
}
// 定义是否是固定输出类型
public boolean deterministic() {
return true;
}
// 定义初始缓存数据
public void initialize(MutableAggregationBuffer buffer) {
buffer.update(0, 0.0);
buffer.update(1, 0L);
}
// 定义每次输入数据的聚合操作
public void update(MutableAggregationBuffer buffer, Row input) {
if (!input.isNullAt(0)) {
double value = input.getDouble(0);
double sum = buffer.getDouble(0);
long count = buffer.getLong(1);
buffer.update(0, sum + value);
buffer.update(1, count + 1);
}
}
// 定义多个分区结果的聚合操作
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
double sum1 = buffer1.getDouble(0);
long count1 = buffer1.getLong(1);
double sum2 = buffer2.getDouble(0);
long count2 = buffer2.getLong(1);
buffer1.update(0, sum1 + sum2);
buffer1.update(1, count1 + count2);
}
// 定义最终结果的计算操作
public Double evaluate(Row buffer) {
double sum = buffer.getDouble(0);
long count = buffer.getLong(1);
return sum / count;
}
}
// 注册UDAF
spark.udf().register("average", new AverageUDAF());
```
上述代码中,我们定义了一个名为`AverageUDAF`的类,继承自`UserDefinedAggregateFunction`,并实现了相应的方法来定义聚合函数的行为。最后通过`spark.udf().register`方法将UDAF注册到Spark中。
### 5.2 Hive集成
Spark SQL可以与Hive进行集成,通过使用Hive的元数据和查询语法来操作数据。在使用Spark SQL之前,需先启用Hive支持,然后可以使用`spark.sql`来执行Hive的查询语句。
下面是一个使用Hive集成进行数据查询的示例:
```java
// 启用Hive支持
spark = SparkSession.builder()
.appName("HiveIntegration")
.enableHiveSupport()
.getOrCreate();
// 使用Hive查询
spark.sql("SELECT * FROM table").show();
```
在上述代码中,我们通过`enableHiveSupport`方法启用Hive支持,并使用`spark.sql`方法执行Hive的查询语句。
### 5.3 动态分区与分桶
Spark SQL提供了动态分区和分桶功能,可以在数据加载和保存时,自动进行数据分区和桶ing,以提高查询性能。
**动态分区**
动态分区是指根据数据的列值动态创建分区,从而将数据按照指定的列值进行分组。下面是一个示例:
```java
spark.sql("SET hive.exec.dynamic.partition.mode=nonstrict");
// 加载数据并动态分区
df.write().partitionBy("date").format("parquet").save(path);
```
在上述代码中,我们通过设置`hive.exec.dynamic.partition.mode`参数来启用动态分区模式,然后使用`partitionBy`方法指定按照哪个列进行分区。
**分桶**
分桶是指将数据根据某个列的哈希值分成多个桶,可以使用分桶来提高数据的查询效率。下面是一个示例:
```java
spark.sql("SET hive.enforce.bucketing=true");
// 加载数据并设置分桶
df.write().bucketBy(10, "name").format("parquet").save(path);
```
在上述代码中,我们通过设置`hive.enforce.bucketing`参数来启用分桶功能,然后使用`bucketBy`方法指定分桶的数量和列。
以上是关于Spark SQL的高级功能的介绍,包括UDF和UDAF的使用、与Hive的集成,以及动态分区和分桶的应用。这些功能可以帮助开发者更加灵活地处理数据和优化查询性能。
# 6. 性能优化
在使用Spark SQL进行大规模数据处理时,性能优化是非常重要的。优化可以提升查询速度和整体效率,减少资源消耗。本章将介绍一些Spark SQL的性能优化技巧。
## 6.1 Catalyst优化器
Catalyst是Spark SQL的查询优化引擎,它采用了一系列优化策略来提升查询性能。Catalyst会在解析SQL语句后构建逻辑执行计划,并进行一系列的优化操作,包括谓词下推、列裁剪、表达式合并等。
Spark SQL默认开启了Catalyst优化器,但也可以通过配置参数`spark.sql.optimizer.enabled`进行关闭。通常情况下,我们无需手动干预Catalyst的优化过程,它会自动根据查询语句进行优化。
## 6.2 Tungsten引擎
Tungsten是Spark SQL的内存管理和代码生成引擎。它通过使用可序列化的数据结构和二进制格式进行存储和交换,以及通过JIT(Just-in-Time)编译来生成高度优化的Java字节码。
Tungsten引擎可以大大提高Spark SQL的查询性能。在使用Spark SQL时,可以通过配置参数`spark.sql.tungsten.enabled`开启Tungsten引擎。
## 6.3 数据倾斜处理
在大规模数据处理中,数据倾斜是一个常见的问题。如果数据倾斜严重,会导致一部分任务运行时间过长,从而降低整体性能。
针对数据倾斜问题,Spark SQL提供了一些解决方案。可以使用`repartition`或`coalesce`方法对数据进行重分区,使得数据均匀分布。另外,还可以对倾斜的键进行拆分,将数据划分到多个分区中,从而减轻单个分区的负担。
## 6.4 硬件与配置优化
除了Spark SQL自身的优化措施,还可以通过硬件和配置的优化来提升性能。
首先,可以增加集群的计算和存储资源,如增加节点数、扩大内存容量等。
其次,可以适当调整Spark SQL的配置参数。例如,可以通过增大`spark.sql.shuffle.partitions`参数的值来增加shuffle操作的并行度,从而提高性能。
另外,还可以通过使用数据压缩、使用Off-Heap内存、合理设置序列化方式等方式来优化性能。
总之,性能优化是Spark SQL使用过程中需要关注的重要问题。通过合理使用优化器、开启Tungsten引擎、处理数据倾斜问题和进行硬件及配置优化,可以有效提升Spark SQL的查询速度和整体性能。
以上便是关于Spark SQL的性能优化的介绍。
# 总结
本章介绍了Spark SQL的性能优化相关内容,包括Catalyst优化器、Tungsten引擎、数据倾斜处理和硬件与配置优化。这些优化技巧可以提高Spark SQL的查询性能和整体效率,减少资源消耗。在使用Spark SQL进行大规模数据处理时,我们可以根据实际情况选择适合的优化策略来提升性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Spark SQL原理与应用》专栏深入探讨了Spark SQL的核心原理和丰富应用。从《Spark SQL简介与基本概念》到《Spark SQL的数据安全与权限控制》,每篇文章都深入浅出地介绍了Spark SQL的重要概念和实际操作技巧。专栏内容包括了数据的加载、保存、过滤、转换、聚合、统计,以及与DataFrame和SQL语法相关的操作,同时也涵盖了内置函数、UDF、数据缓存、优化、分区、分桶、连接、合并等内容。此外,专栏还涉及了对流式数据处理和与分布式文件系统、数据存储相关的知识。无论是对初学者还是有一定经验的工程师而言,本专栏都将为您提供深入、系统的Spark SQL学习体验,使您能够更加灵活地应用Spark SQL解决实际问题。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Java代码审计核心教程】:零基础快速入门与进阶策略
-Concept-in-Java.webp)
# 摘要
Java代码审计是保障软件安全性的重要手段。本文系统性地介绍了Java代码审计的基础概念、实践技巧、实战案例分析、进阶技能提升以及相关工具与资源。文中详细阐述了代码审计的各个阶段,包括准备、执行和报告撰写,并强调了审计工具的选择、环境搭建和结果整理的重要性。结合具体实战案例,文章
【Windows系统网络管理】:IT专家如何有效控制IP地址,3个实用技巧

# 摘要
本文主要探讨了Windows系统网络管理的关键组成部分,特别是IP地址管理的基础知识与高级策略。首先概述了Windows系统网络管理的基本概念,然后深入分析了IP地址的结构、分类、子网划分和地址分配机制。在实用技巧章节中,我们讨论了如何预防和解决IP地址冲突,以及IP地址池的管理方法和网络监控工具的使用。之后,文章转向了高级
【技术演进对比】:智能ODF架与传统ODF架性能大比拼

# 摘要
随着信息技术的快速发展,智能ODF架作为一种新型的光分配架,与传统ODF架相比,展现出诸多优势。本文首先概述了智能ODF架与传统ODF架的基本概念和技术架构,随后对比了两者在性能指标、实际应用案例、成本与效益以及市场趋势等方面的不同。智能ODF架通过集成智能管理系统,提高了数据传输的高效性和系统的可靠性,同时在安全性方面也有显著增强。通过对智能ODF架在不同部署场景中的优势展示和传统ODF架局限性的分析,本文还探讨
化工生产优化策略:工业催化原理的深入分析
# 摘要
本文综述了化工生产优化的关键要素,从工业催化的基本原理到优化策略,再到环境挑战的应对,以及未来发展趋势。首先,介绍了化工生产优化的基本概念和工业催化理论,包括催化剂的设计、选择、活性调控及其在工业应用中的重要性。其次,探讨了生产过程的模拟、流程调整控制、产品质量提升的策略和监控技术。接着,分析了环境法规对化工生产的影响,提出了能源管理和废物处理的环境友好型生产方法。通过案例分析,展示了优化策略在多相催化反应和精细化工产品生产中的实际应用。最后,本文展望了新型催化剂的开发、工业4.0与智能化技术的应用,以及可持续发展的未来方向,为化工生产优化提供了全面的视角和深入的见解。
# 关键字
MIPI D-PHY标准深度解析:掌握规范与应用的终极指南
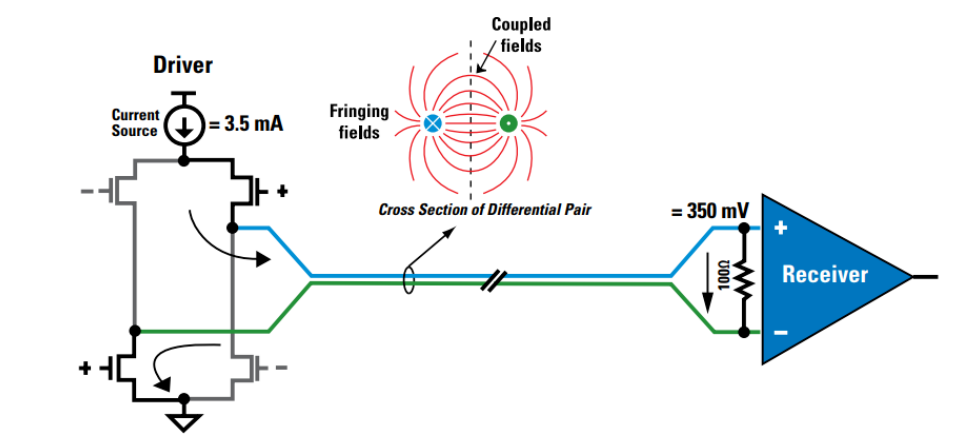
# 摘要
MIPI D-PHY作为一种高速、低功耗的物理层通信接口标准,广泛应用于移动和嵌入式系统。本文首先概述了MIPI D-PHY标准,并深入探讨了其物理层特性和协议基础,包括数据传输的速率、通道配置、差分信号设计以及传输模式和协议规范。接着,文章详细介绍了MIPI D-PHY在嵌入式系统中的硬件集成、软件驱动设计及实际应用案例,同时提出了性能测试与验
【SAP BASIS全面指南】:掌握基础知识与高级技能

# 摘要
SAP BASIS是企业资源规划(ERP)解决方案中重要的技术基础,涵盖了系统安装、配置、监控、备份、性能优化、安全管理以及自动化集成等多个方面。本文对SAP BASIS的基础配置进行了详细介绍,包括系统安装、用户管理、系统监控及备份策略。进一步探讨了高级管理技
【Talend新手必读】:5大组件深度解析,一步到位掌握数据集成
# 摘要
Talend是一款强大的数据集成工具,本文首先介绍了Talend的基本概念和安装配置方法。随后,详细解读了Talend的基础组件,包括Data Integration、Big Data和Cloud组件,并探讨了各自的核心功能和应用场景。进阶章节分析了Talend在实时数据集成、数据质量和合规性管理以及与其他工
网络安全新策略:Wireshark在抓包实践中的应用技巧

# 摘要
Wireshark作为一款强大的网络协议分析工具,广泛应用于网络安全、故障排除、网络性能优化等多个领域。本文首先介绍了Wireshark的基本概念和基础使用方法,然后深入探讨了其数据包捕获和分析技术,包括数据包结构解析和高级设置优化。文章重点分析了Wireshark在网络安全中的应用,包括网络协议分析、入侵检测与响应、网络取证与合规等。通过实
三角形问题边界测试用例的测试执行与监控:精确控制每一步

# 摘要
本文针对三角形问题的边界测试用例进行了深入研究,旨在提升测试用例的精确性和有效性。文章首先概述了三角形问题边界测试用例的基础理论,包括测试用例设计原则、边界值分析法及其应用和实践技巧。随后,文章详细探讨了三角形问题的定义、分类以及测试用例的创建、管理和执行过程。特别地,文章深入分析了如何控制测试环境与用例的精确性,并探讨了持续集成与边界测试整合的可能性。在测试结果分析与优化方面,本文提出了一系列故障分析方法和测试流程改进策略。最后,文章展望了边界
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )