Docker Compose:多容器应用编排与管理
发布时间: 2024-03-05 21:15:38 阅读量: 46 订阅数: 29 

使用docker Compose 服务编排管理容器
# 1. 介绍Docker Compose
## 1.1 什么是Docker Compose
Docker Compose是一个用来定义和运行多容器Docker应用的工具。通过一个单独的Compose文件来配置应用的服务、网络和卷,可以使用`docker-compose up`命令快速启动整个应用。
## 1.2 Docker Compose的优势和应用场景
Docker Compose简化了多容器应用的编排与管理,使得开发、测试和部署变得更加高效。其优势包括:
- 快速启动多容器应用
- 配置简单、易于维护
- 一键部署整个应用
- 支持环境变量替换与扩展
Docker Compose适用于开发人员本地开发、测试团队的自动化测试、快速构建演示环境以及简单的生产部署等场景。
## 1.3 Docker Compose与Docker Swarm的区别
Docker Compose主要用于开发和测试环境下多容器应用的编排与管理,适用于单机或者少量主机的场景。而Docker Swarm是Docker官方的容器编排工具,用于构建生产环境下大规模集群的容器编排与管理。
在功能上,Docker Compose更专注于单机多容器的编排,而Docker Swarm则更适用于多主机、分布式集群管理。因此,开发人员在本地开发和测试时多会选择使用Docker Compose,而在生产环境中则更倾向于使用Docker Swarm。
# 2. 安装与配置Docker Compose
Docker Compose是一种用于定义和运行多容器Docker应用程序的工具。它通过一个单独的文件来配置应用的服务,然后使用简单的命令来启动、停止和管理整个应用。接下来将分为安装Docker Compose、配置Docker Compose文件以及介绍Docker Compose的常用命令这三个部分来详细说明。
### 2.1 安装Docker Compose
在安装Docker Compose之前,请确保已经安装了Docker。Docker Compose的安装过程相对简单,只需在官方GitHub Release页面下载对应版本的二进制文件即可。以下是在Linux系统上安装Docker Compose的示例:
```bash
# 从官方GitHub Release页面下载最新稳定版本的Docker Compose二进制文件
sudo curl -L "https://github.com/docker/compose/releases/download/版本号/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 添加可执行权限
sudo chmod +x /usr/local/bin/docker-compose
# 创建一个软链接
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
# 验证安装
docker-compose --version
```
### 2.2 配置Docker Compose文件(docker-compose.yml)
编写Docker Compose文件是使用Docker Compose的关键。在项目根目录下创建一个名为`docker-compose.yml`的文件,并使用YAML语法定义服务、网络、数据卷等内容。下面是一个简单的示例:
```yaml
version: '3.7'
services:
web:
image: nginx:latest
ports:
- "8080:80"
networks:
- frontend
db:
image: mysql:5.7
environment:
MYSQL_ROOT_PASSWORD: example
networks:
frontend:
volumes:
data:
```
以上示例定义了一个包含一个Nginx Web服务和一个MySQL数据库服务的应用,它们共享一个自定义网络并使用了一个数据卷。
### 2.3 Docker Compose常用命令介绍
Docker Compose提供了一系列命令来简化多容器应用的管理。以下是一些常用的命令:
- `docker-compose up`:启动应用
- `docker-compose down`:停止应用并移除相关容器
- `docker-compose ps`:列出应用中的所有容器
- `docker-compose logs`:查看应用日志
- `docker-compose exec`:在运行中的容器中执行命令
通过上述介绍,现在你应该已经成功安装了Docker Compose并了解了如何配置Docker Compose文件以及常用的命令。接下来,我们将深入学习如何编写多容器应用的Docker Compose文件。
# 3. 编写多容器应用的Docker Compose文件
Docker Compose文件是用来定义和运行多容器Docker应用程序的文件,它使用YAML格式编写,包含了应用的服务、网络、数据卷等配置信息。通过编写Docker Compose文件,我们可以轻松地定义和管理多个容器的编排关系,实现快速部署和管理多容器应用。
#### 3.1 Docker Compose文件结构介绍
一个典型的Docker Compose文件由以下部分组成:
```yaml
version: '3.8' # 版本号,表示采用的Compose文件版本
services: # 定义各个容器化应用的服务
web: # 服务名称
build: . # 指定构建上下文为当前目录
image: web_image # 定义镜像名称
ports: # 暴露端口
- "5000:5000"
networks: # 定义使用的网络
- front-tier
- back-tier
volumes: # 定义挂载的数据卷
- data:/var/www
db:
image: postgres:latest
environment: # 定义环境变量
POSTGRES_PASSWORD: example
volumes:
- data:/var/lib/postgresql/data
networks: # 定义网络
front-tier:
back-tier:
volumes: # 定义数据卷
data:
```
在Docker Compose文件中,`version`指定了Compose文件的版本,`services`定义了各个容器化应用的服务,包括构建信息、镜像、端口映射、网络、数据卷等配置。此外,还可以定义`networks`用于连接各个服务的网络,以及`volumes`用于持久化数据的数据卷。
#### 3.2 编写多容器应用示例:Web服务与数据库服务
让我们来编写一个简单的多容器应用示例,包括一个Web服务和一个数据库服务。假设Web服务使用Python编写的Flask框架,数据库服务使用PostgreSQL。
首先,在一个空目录下创建一个名为`docker-compose.yml`的文件,然后编写以下内容:
```yaml
version: '3.8'
services:
web:
build: ./web
image: web_image
ports:
- "5000:5000"
networks:
- backend
depends_on: # 定义依赖关系
- db
environment: # 定义环境变量
DATABASE_URL: postgres://dbuser:dbpass@db/dbname
db:
image: postgres:latest
environment:
POSTGRES_USER: dbuser
POSTGRES_PASSWORD: dbpass
POSTGRES_DB: dbname
networks:
- backend
networks:
backend:
```
在同级目录下创建一个名为`web`的子目录,在`web`目录中编写Dockerfile用于构建Web服务的镜像,以及Flask应用的代码文件。然后在命令行中切换到包含`docker-compose.yml`的目录,运行以下命令启动应用:
```bash
docker-compose up
```
#### 3.3 使用Docker Compose定义网络与数据卷
除了定义服务之外,Docker Compose还可以帮助我们轻松地定义网络和数据卷。在上面的示例中,我们使用了`networks`来定义连接服务的网络,使用了`volumes`来定义持久化数据的数据卷。这样可以让我们更加方便地管理多容器应用的网络和数据。
通过Docker Compose文件定义网络和数据卷,可以有效地组织和管理多容器应用所需的各种资源,提高了部署和管理的效率。
在本节中,我们介绍了Docker Compose文件的结构,以及通过示例演示了如何编写一个包含多个服务的Compose文件。同时,还介绍了如何使用Docker Compose定义网络和数据卷,使得多容器应用的管理更加便捷。
接下来,我们将在下一节讨论如何运行和管理这样的多容器应用。
# 4. 运行与管理多容器应用
在这一部分,我们将介绍如何使用Docker Compose来运行和管理多容器应用,包括启动应用、扩容缩减、监控和日志管理等方面的内容。
#### 4.1 使用Docker Compose启动多容器应用
首先,确保已经编写好了Docker Compose文件(docker-compose.yml),包括了需要运行的各个服务的配置信息。接下来,通过以下命令来启动多容器应用:
```bash
docker-compose up
```
这个命令会自动读取当前目录下的docker-compose.yml文件,并根据配置启动应用中定义的所有服务。如果希望在后台运行,可以使用`-d`参数:
```bash
docker-compose up -d
```
#### 4.2 Docker Compose的扩容与缩减
通过Docker Compose,我们可以很方便地对应用进行扩容和缩减。比如,如果希望增加某个服务的容器数量,可以使用以下命令:
```bash
docker-compose scale <service_name>=<num_containers>
```
例如,要将web服务的容器数量扩展到3个,可以这样操作:
```bash
docker-compose scale web=3
```
#### 4.3 监控与日志管理
通过Docker Compose,我们可以方便地查看应用的日志信息,只需执行以下命令:
```bash
docker-compose logs
```
如果只想查看某个特定服务的日志,可以指定服务名:
```bash
docker-compose logs <service_name>
```
此外,可以使用第三方监控工具来监控Docker容器的运行情况,比如cAdvisor、Prometheus等,也可以将日志集中存储到ELK等日志管理系统中进行进一步的分析和管理。
# 5. Docker Compose与持续集成
持续集成(Continuous Integration,简称CI)是现代软件开发中的一项重要实践,它可以帮助团队在开发过程中保持代码的持续集成、自动化测试和快速部署。在使用Docker Compose进行多容器应用编排与管理的过程中,结合持续集成可以更好地实现整个开发流程的自动化和优化。
### 5.1 集成Docker Compose到持续集成流程
在持续集成流程中集成Docker Compose,可以使得应用在不同环境中的部署更加一致和可靠。通常,持续集成流程会包括以下几个步骤:
- 代码提交触发自动构建:开发人员将代码提交到版本控制系统(如Git),触发CI工具执行自动构建。
- 单元测试和集成测试:CI工具会在构建过程中运行单元测试和集成测试,确保代码质量。
- 构建Docker镜像:在测试通过后,CI工具会使用Docker Compose构建应用所需的Docker镜像。
- 启动容器:CI工具会利用Docker Compose启动多个容器,将整个应用环境进行编排和管理。
- 自动化测试:运行端到端的自动化测试,确保整个应用的功能正常。
- 部署到测试环境:将构建好的应用部署到测试环境,进行全面的验证。
- 部署到生产环境:通过集成Docker Compose,可以在生产环境中快速部署整个应用。
### 5.2 使用Docker Compose进行本地开发
除了集成到持续集成流程中,Docker Compose也可以用于本地开发。开发人员可以使用Docker Compose快速启动应用所需的多个容器,搭建出与生产环境接近的开发环境,提高开发效率。
在本地开发过程中,可以通过挂载本地文件进行实时代码调试,同时利用Docker Compose定义的服务互相通信,模拟真实的应用部署情况。这有助于开发人员更早地发现和解决潜在的问题。
### 5.3 自动化测试与部署
利用Docker Compose结合持续集成流程,可以实现自动化测试与部署。在CI中通过Docker Compose启动多容器应用,自动运行测试用例;通过定义好的部署脚本,可以在测试通过后实现自动部署到不同环境。
自动化测试与部署可以大大减少人工干预,缩短发布周期,降低人为错误的风险,提高整个团队的工作效率和产品质量。
综上所述,Docker Compose与持续集成的集成为团队的开发流程带来了诸多好处,使得开发、测试和部署更加自动化、高效。
# 6. 最佳实践与常见问题解决
在使用Docker Compose进行多容器应用编排与管理时,有一些最佳实践和常见问题需要注意和解决。下面将介绍一些相关内容。
### 6.1 Docker Compose的最佳实践
#### 6.1.1 确保容器间通信稳定
在编写Docker Compose文件时,需要确保多个容器之间的通信是稳定的,可以通过定义网络并使用容器名称进行通信。
```yaml
version: '3'
services:
web:
image: nginx
ports:
- "80:80"
api:
image: myapi
depends_on:
- database
database:
image: mysql
```
#### 6.1.2 灵活使用环境变量与容器替代
在Docker Compose文件中使用环境变量和容器替代,可以使配置更加灵活,便于不同环境下的部署和管理。
```yaml
version: '3'
services:
web:
image: nginx
environment:
- DEBUG=true
api:
image: myapi
environment:
- DB_HOST=database
database:
image: mysql
```
#### 6.1.3 避免容器过大
尽量避免构建过大的容器镜像,可以通过多阶段构建和精简依赖来减小容器镜像的大小,提高部署效率。
```Dockerfile
FROM node:alpine AS build
WORKDIR /app
COPY . .
RUN npm install
RUN npm run build
FROM nginx:alpine
COPY --from=build /app/dist /usr/share/nginx/html
```
### 6.2 多容器应用部署中的常见问题与解决办法
#### 6.2.1 容器启动顺序问题
在多容器应用中,有些容器可能依赖于其他容器,需要注意容器的启动顺序,可以使用`depends_on`来定义依赖关系。
```yaml
version: '3'
services:
web:
image: nginx
api:
image: myapi
depends_on:
- database
database:
image: mysql
```
#### 6.2.2 网络连接问题
在多容器应用中,容器之间的网络连接需要留意,确保容器可以相互通信,可以定义共享网络或者使用服务发现等方式解决网络连接问题。
```yaml
version: '3'
services:
web:
image: nginx
networks:
- backend
api:
image: myapi
networks:
- backend
database:
image: mysql
networks:
- backend
networks:
backend:
```
### 6.3 Docker Compose在生产环境中的应用注意事项
#### 6.3.1 资源限制与监控
在生产环境中,需要为容器设置合适的资源限制,并进行监控和调优,以确保应用的稳定性和高可用性。
```yaml
version: '3'
services:
web:
image: nginx
deploy:
resources:
limits:
cpus: '0.5'
memory: 512M
```
#### 6.3.2 安全配置
在生产环境中,需要注意容器和应用的安全配置,包括合理设置容器权限、使用安全的镜像源、定期更新等。
```yaml
version: '3'
services:
web:
image: nginx:stable-alpine
security_opt:
- no-new-privileges:true
```
以上是关于Docker Compose的最佳实践、常见问题解决办法以及在生产环境中的应用注意事项,通过遵循这些实践和注意事项,可以更好地利用Docker Compose来编排和管理多容器应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Zkteco智慧多地点管理ZKTime5.0:集中控制与远程监控完全指南

# 摘要
本文对Zkteco智慧多地点管理系统ZKTime5.0进行了全面的介绍和分析。首先概述了ZKTime5.0的基本功能及其在智慧管理中的应用。接着,深入探讨了集中控制系统的理论基础,包括定义、功能、组成架构以及核心技术与优势。文章详细讨论了ZKTime5.0的远程监控功能,着重于其工作原理、用户交互设计及安全隐私保护。实践部署章节提供了部署前准备、系统安装配置
Java代码安全审查规则解析:深入local_policy.jar与US_export_policy.jar的安全策略

# 摘要
本文系统探讨了Java代码安全审查的全面方法与实践。首先介绍了Java安全策略文件的组成及其在不同版本间的差异,对权限声明进行了深入解析。接着,文章详细阐述了进行安全审查的工具和方法,分析了安全漏洞的审查实例,并讨论了审查报告的撰写和管理。文章深入理解Java代码安
数字逻辑深度解析:第五版课后习题的精华解读与应用

# 摘要
数字逻辑作为电子工程和计算机科学的基础,其研究涵盖了从基本概念到复杂电路设计的各个方面。本文首先回顾了数字逻辑的基础知识,然后深入探讨了逻辑门、逻辑表达式及其简化、验证方法。接着,文章详细分析了组合逻辑电路和时序逻辑电路的设计、分析、测试方法及其在电子系统中的应用。最后,文章指出了数字逻辑电路测试与故障诊断的重要性,并探讨了其在现代电子系统设计中的创新应用
【CEQW2监控与报警机制】:构建无懈可击的系统监控体系

# 摘要
监控与报警机制是确保信息系统的稳定运行与安全防护的关键技术。本文系统性地介绍了CEQW2监控与报警机制的理论基础、核心技术和应用实践。首先概述了监控与报警机制的基本概念和框架,接着详细探讨了系统监控的理论基础、常用技术与工具、数据收集与传输方法。随后,文章深入分析了报警机制的理论基础、操作实现和高级应用,探讨了自动化响应流程和系统性能优化。此外,本文还讨论了构建全面监控体系的架构设计、集成测试及维
电子组件应力筛选:IEC 61709推荐的有效方法

# 摘要
电子组件在生产过程中易受各种应力的影响,导致性能不稳定和早期失效。应力筛选作为一种有效的质量控制手段,能够在电子组件进入市场前发现潜在的缺陷。IEC 61709标准为应力筛选提供了理论框架和操作指南,促进了该技术在电子工业中的规范化应用。本文详细解读了IEC 61709标准,并探讨了应力筛选的理论基础和统计学方法。通过分析电子组件的寿命分
ARM处理器工作模式:剖析7种运行模式及其最佳应用场景

# 摘要
ARM处理器因其高性能和低功耗的特性,在移动和嵌入式设备领域得到广泛应用。本文首先介绍了ARM处理器的基本概念和工作模式基础,然后深入探讨了ARM的七种运行模式,包括状态切换、系统与用户模式、特权模式与异常模式的细节,并分析了它们的应用场景和最佳实践。随后,文章通过对中断处理、快速中断模式和异常处理模式的实践应用分析,阐述了在实时系统中的关键作用和设计考量。在高级应用部分,本文讨论了安全模式、信任Z
UX设计黄金法则:打造直觉式移动界面的三大核心策略

# 摘要
随着智能移动设备的普及,直觉式移动界面设计成为提升用户体验的关键。本文首先概述移动界面设计,随后深入探讨直觉式设计的理论基础,包括用户体验设计简史、核心设计原则及心理学应用。接着,本文提出打造直觉式移动界面的实践策略,涉及布局、导航、交互元素以及内容呈现的直觉化设计。通过案例分析,文中进一步探讨了直觉式交互设计的成功与失败案例,为设
海康二次开发进阶篇:高级功能实现与性能优化

# 摘要
随着安防监控技术的发展,海康设备二次开发在智能视频分析、AI应用集成及云功能等方面展现出越来越重要的作用。本文首先介绍了海康设备二次开发的基础知识,详细解析了海康SDK的架构、常用接口及集成示例。随后,本文深入探讨了高级功能的实现,包括实时视频分析技术、AI智能应用集成和云功能的
STM32F030C8T6终极指南:最小系统的构建、调试与高级应用
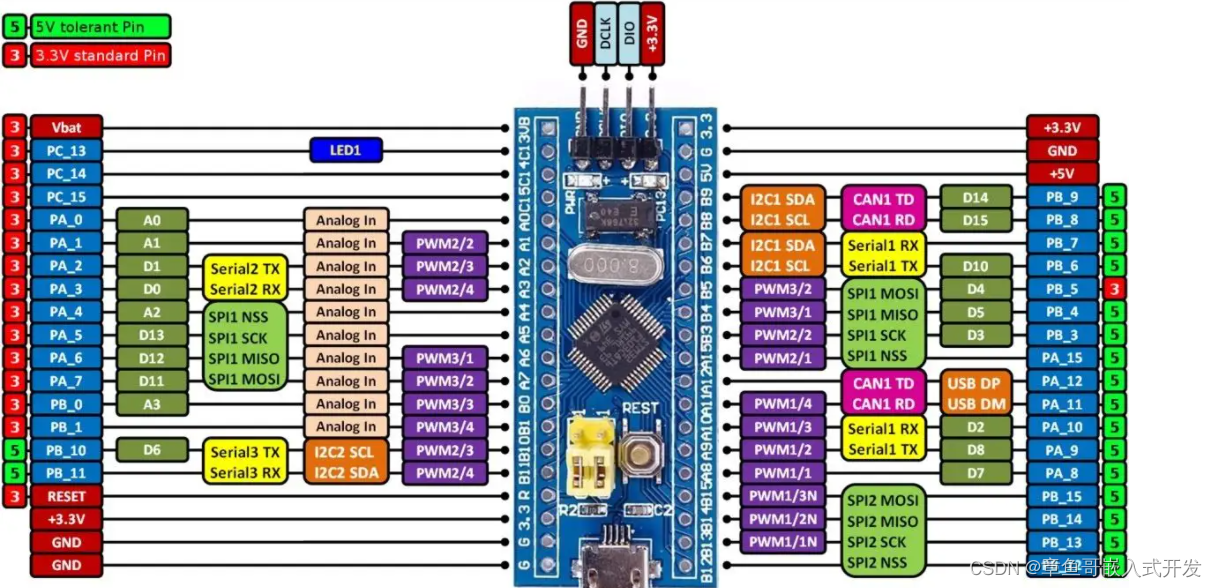
# 摘要
本论文全面介绍了STM32F030C8T6微控制器的关键特性和应用,从最小系统的构建到系统优化与未来展望。首先,文章概述了微控制器的基本概念,并详细讨论了构建最小系统所需的硬件组件选择、电源电路设计、调试接口配置,以及固件准备。随后,论文深入探讨了编程和调试的基础,包括开发环境的搭建、编程语言的选择和调试技巧。文章还深入分析了微控制器的高级特性,如外设接口应用、中断系统优化、能效
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )