掌握MySQL JSON数据查询利器:全方位解析JSON查询方法
发布时间: 2024-07-29 02:31:10 阅读量: 38 订阅数: 31 

java+sql server项目之科帮网计算机配件报价系统源代码.zip

# 1. MySQL JSON数据查询简介
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,广泛用于存储和传输数据。MySQL数据库支持对JSON数据的查询和操作,为数据分析和处理提供了强大的功能。本章将介绍MySQL JSON数据查询的基础知识,包括JSON数据结构、查询操作符以及基本查询实践。
# 2. JSON查询基础
### 2.1 JSON数据结构和语法
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它采用文本形式来表示对象和数组。JSON数据结构由以下元素组成:
- **对象:**由键值对组成的无序集合,用大括号`{}`表示。
- **数组:**由元素组成的有序集合,用方括号`[]`表示。
- **字符串:**用双引号`"`或单引号`'`括起来的文本。
- **数字:**整数或浮点数。
- **布尔值:**`true`或`false`。
- **null:**表示空值。
### 2.2 JSON查询操作符
MySQL提供了以下JSON查询操作符:
- **`.`(点运算符):**用于访问对象的键。
- **`->`(箭头运算符):**用于访问嵌套对象的键。
- **`$`(美元符号):**用于访问数组元素。
- **`[]`(方括号):**用于访问数组元素或对象键。
- **`@`(at符号):**用于获取JSON文档的类型。
#### 代码块示例:
```sql
-- 创建一个JSON文档
CREATE TABLE json_data (id INT, data JSON);
INSERT INTO json_data (id, data) VALUES (1, '{"name": "John Doe", "age": 30}');
-- 使用`.`运算符访问对象键
SELECT data->'$.name' FROM json_data WHERE id = 1;
-- 使用`$`运算符访问数组元素
SELECT data->'$.hobbies[0]' FROM json_data WHERE id = 1;
```
#### 逻辑分析:
- 第一行创建了一个名为`json_data`的表,其中`data`列存储JSON文档。
- 第二行使用`.`运算符访问对象的`name`键。
- 第三行使用`$`运算符访问数组`hobbies`的第一个元素。
#### 参数说明:
- `data->'$.name'`: 使用`.`运算符访问对象的`name`键。
- `data->'$.hobbies[0]'`: 使用`$`运算符访问数组`hobbies`的第一个元素。
# 3. JSON查询实践
### 3.1 JSON路径表达式
JSON路径表达式用于从JSON文档中提取特定值。它类似于XPath,但针对JSON数据进行了优化。JSON路径表达式由以下部分组成:
- **根对象:**JSON文档的根对象。
- **路径分隔符:**`.`,用于分隔路径中的不同部分。
- **键或索引:**用于指定对象中的键或数组中的索引。
#### 3.1.1 基本路径表达式
基本路径表达式用于提取单个值。它由以下语法组成:
```
$.<key>
```
其中:
- `$` 表示根对象。
- `<key>` 是要提取的值的键。
**示例:**
```sql
SELECT JSON_EXTRACT('{"name": "John", "age": 30}', '$.name');
```
输出:
```
John
```
#### 3.1.2 数组和对象路径表达式
JSON路径表达式还支持提取数组和对象中的值。
**数组路径表达式:**
```
$.<array>[<index>]
```
其中:
- `<array>` 是数组的键。
- `<index>` 是数组中要提取的值的索引。
**示例:**
```sql
SELECT JSON_EXTRACT('{"names": ["John", "Mary", "Bob"]}', '$.names[1]');
```
输出:
```
Mary
```
**对象路径表达式:**
```
$.<object>.<key>
```
其中:
- `<object>` 是对象的键。
- `<key>` 是要提取的值的键。
**示例:**
```sql
SELECT JSON_EXTRACT('{"address": {"city": "New York", "state": "NY"}', '$.address.city');
```
输出:
```
New York
```
### 3.2 JSON函数
MySQL提供了两个用于操作JSON数据的函数:JSON_EXTRACT()和JSON_SET()。
#### 3.2.1 JSON_EXTRACT()函数
JSON_EXTRACT()函数用于从JSON文档中提取值。它的语法如下:
```
JSON_EXTRACT(<json_document>, <json_path>)
```
其中:
- `<json_document>` 是要从中提取值的JSON文档。
- `<json_path>` 是要提取值的JSON路径表达式。
**示例:**
```sql
SELECT JSON_EXTRACT('{"name": "John", "age": 30}', '$.name');
```
输出:
```
John
```
#### 3.2.2 JSON_SET()函数
JSON_SET()函数用于在JSON文档中设置或更新值。它的语法如下:
```
JSON_SET(<json_document>, <json_path>, <new_value>)
```
其中:
- `<json_document>` 是要设置或更新值的JSON文档。
- `<json_path>` 是要设置或更新值的JSON路径表达式。
- `<new_value>` 是要设置或更新的新值。
**示例:**
```sql
SELECT JSON_SET('{"name": "John", "age": 30}', '$.age', 31);
```
输出:
```
{"name": "John", "age": 31}
```
# 4. JSON查询进阶
### 4.1 JSON嵌套查询
嵌套查询是指在JSON查询中使用另一个JSON查询作为查询条件。它允许我们从复杂嵌套的JSON文档中提取特定数据。
#### 嵌套查询语法
嵌套查询的语法如下:
```
SELECT ...
FROM ...
WHERE JSON_QUERY(JSON_COLUMN, '$.path_to_nested_object') JSON_QUERY_CONDITION
```
其中:
* `JSON_COLUMN` 是包含JSON数据的列
* `path_to_nested_object` 是指向嵌套对象的JSON路径
* `JSON_QUERY_CONDITION` 是应用于嵌套对象的JSON查询条件
#### 示例
假设我们有一个包含以下JSON数据的表:
```
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_data JSON
);
INSERT INTO products (product_id, product_data) VALUES
(1, '{"name": "Product 1", "category": {"id": 1, "name": "Category 1"}, "tags": ["tag1", "tag2"]}');
(2, '{"name": "Product 2", "category": {"id": 2, "name": "Category 2"}, "tags": ["tag3", "tag4"]}');
```
要查找所有属于特定类别的产品,我们可以使用嵌套查询:
```
SELECT product_id, product_data->'$.name' AS product_name
FROM products
WHERE JSON_QUERY(product_data, '$.category.id') = 1;
```
### 4.2 JSON联合查询
联合查询允许我们从多个JSON文档中提取数据并将其组合到一个结果集中。这对于从不同的JSON源中提取相关数据非常有用。
#### 联合查询语法
联合查询的语法如下:
```
SELECT ...
FROM (
SELECT ... FROM JSON_TABLE1
UNION ALL
SELECT ... FROM JSON_TABLE2
...
) AS JSON_UNION_TABLE
```
其中:
* `JSON_TABLE1`, `JSON_TABLE2`, ... 是包含JSON数据的表或子查询
* `UNION ALL` 操作符将结果集组合在一起
#### 示例
假设我们有两个包含以下JSON数据的表:
```
CREATE TABLE orders (
order_id INT PRIMARY KEY,
order_data JSON
);
INSERT INTO orders (order_id, order_data) VALUES
(1, '{"product_id": 1, "quantity": 2}');
(2, '{"product_id": 2, "quantity": 1}');
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_data JSON
);
INSERT INTO products (product_id, product_data) VALUES
(1, '{"name": "Product 1", "price": 10}');
(2, '{"name": "Product 2", "price": 15}');
```
要查找所有订单及其对应的产品信息,我们可以使用联合查询:
```
SELECT *
FROM (
SELECT order_id, product_id, quantity
FROM orders
UNION ALL
SELECT product_id, NULL, NULL
FROM products
) AS JSON_UNION_TABLE;
```
# 5. JSON查询优化
### 5.1 索引优化
索引是提高查询性能的关键技术,对于JSON查询也不例外。MySQL提供了两种类型的JSON索引:
- **单值索引:**为JSON文档中的单个键值对创建索引。
- **多值索引:**为JSON文档中数组或对象的多个键值对创建索引。
创建JSON索引的语法如下:
```sql
CREATE INDEX index_name ON table_name (JSON_COLUMN) USING JSON_INDEX(path)
```
其中:
- `index_name` 是索引的名称。
- `table_name` 是要创建索引的表的名称。
- `JSON_COLUMN` 是要创建索引的JSON列的名称。
- `path` 是要创建索引的JSON路径。
例如,以下语句为 `products` 表中的 `json_data` 列创建单值索引:
```sql
CREATE INDEX idx_product_name ON products (json_data) USING JSON_INDEX("$.name")
```
### 5.2 数据结构优化
除了索引优化之外,数据结构的优化也可以提高JSON查询的性能。以下是一些优化数据结构的建议:
- **将JSON数据存储在单独的列中:**不要将JSON数据存储在文本或BLOB列中,因为这会降低查询性能。
- **使用适当的数据类型:**为JSON文档中的不同键值对使用适当的数据类型,例如:
- 数字:使用 `INT` 或 `FLOAT`
- 布尔值:使用 `BOOLEAN`
- 日期:使用 `DATE` 或 `DATETIME`
- **避免嵌套JSON数据:**嵌套JSON数据会降低查询性能,因此应尽量避免。
- **使用JSON规范化:**将JSON数据规范化到多个表中可以提高查询性能。
### 5.3 查询优化技巧
除了索引和数据结构优化之外,还可以使用以下查询优化技巧来提高JSON查询的性能:
- **使用适当的查询操作符:**选择最适合查询的JSON查询操作符,例如:
- `$` 操作符:用于选择根文档中的键值对。
- `.` 操作符:用于选择嵌套文档中的键值对。
- `[]` 操作符:用于选择数组中的元素。
- **避免使用通配符:**通配符(如 `*`)会降低查询性能,因此应尽量避免使用。
- **使用子查询:**将复杂查询分解为多个子查询可以提高性能。
- **使用临时表:**将中间结果存储在临时表中可以提高性能。
### 5.4 性能监控和分析
为了确保JSON查询的最佳性能,定期监控和分析查询性能非常重要。以下是一些监控和分析工具:
- **EXPLAIN:**使用 `EXPLAIN` 语句分析查询执行计划。
- **慢查询日志:**启用慢查询日志以记录执行时间较长的查询。
- **性能模式:**使用性能模式收集有关查询性能的详细统计信息。
通过监控和分析查询性能,可以识别性能瓶颈并实施适当的优化措施。
# 6. JSON查询案例
### 6.1 电子商务数据分析
**场景:**分析电子商务网站的订单数据,找出购买特定商品的用户数量。
**查询:**
```sql
SELECT COUNT(DISTINCT user_id)
FROM orders
WHERE JSON_CONTAINS(order_details, '{"product_id": "P001"}');
```
**解释:**
* `JSON_CONTAINS()` 函数检查 `order_details` 列中的 JSON 数据是否包含指定的子文档。
* `{"product_id": "P001"}` 指定要查找的子文档,其中 `product_id` 为 `P001`。
* `COUNT(DISTINCT user_id)` 统计满足条件的订单中不同的用户数量。
### 6.2 日志数据解析
**场景:**解析日志数据,找出特定错误代码出现的次数。
**查询:**
```sql
SELECT error_code, COUNT(*) AS count
FROM logs
WHERE JSON_VALUE(log_data, '$.error.code') = '404'
GROUP BY error_code;
```
**解释:**
* `JSON_VALUE()` 函数从 `log_data` 列中的 JSON 数据中提取指定路径的值。
* `$.error.code` 指定要提取的路径,其中 `error` 是 JSON 对象,`code` 是其属性。
* `COUNT(*)` 统计满足条件的日志记录数量。
* `GROUP BY error_code` 根据错误代码对结果进行分组,并统计每个错误代码出现的次数。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL JSON 数据处理的方方面面,提供了一系列实用的指南和技巧,帮助您充分利用 JSON 数据的强大功能。从存储和查询到更新和优化,您将掌握各种技术,以高效管理和处理 JSON 数据。此外,专栏还涵盖了 JSON 数据的索引优化、性能调优、存储设计、迁移、备份、恢复、安全防护以及在云计算、移动开发、物联网、金融科技、医疗保健、电子商务和教育等领域的应用。通过阅读本专栏,您将成为 MySQL JSON 数据处理方面的专家,能够充分发挥其潜力,为您的应用程序带来显著的优势。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
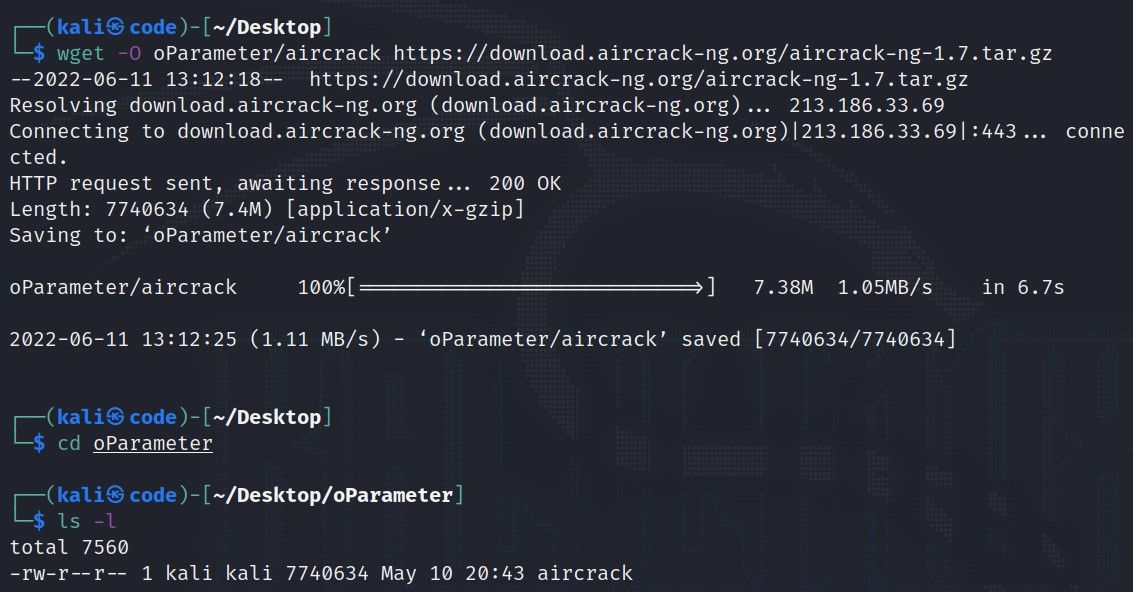
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )