揭秘YOLO算法在Windows上的实现:深入解析技术细节,提升算法性能
发布时间: 2024-08-14 11:57:31 阅读量: 31 订阅数: 31 

深入解析YOLO算法:边界框预测与代码实现
# 1. YOLO算法概述**
YOLO(You Only Look Once)算法是一种实时目标检测算法,它将目标检测任务视为一个单一的回归问题,通过一次神经网络前向传播即可直接预测边界框和类概率。与传统的目标检测算法不同,YOLO算法无需生成候选区域,而是直接在输入图像上预测目标的位置和类别。
YOLO算法的优势在于其速度和准确性。它可以在实时(每秒处理多帧图像)下进行目标检测,同时保持较高的准确率。这使得YOLO算法非常适合于需要快速响应的应用,例如自动驾驶、视频监控和机器人视觉。
# 2. YOLO算法在Windows上的实现
### 2.1 Windows平台下的YOLO算法实现架构
YOLO算法在Windows平台上的实现主要基于Darknet框架。Darknet是一个开源的深度学习框架,专为快速和高效的卷积神经网络训练和推理而设计。它提供了对CUDA和OpenCL的支持,从而可以在GPU上加速计算。
Darknet框架包含了YOLO算法的实现,包括训练、推理和评估。YOLO算法在Windows平台上的实现架构如下图所示:
```mermaid
graph LR
subgraph YOLO算法实现架构
A[Darknet框架] --> B[YOLO训练]
A[Darknet框架] --> C[YOLO推理]
A[Darknet框架] --> D[YOLO评估]
end
```
### 2.2 YOLO算法在Windows上的性能优化
为了在Windows平台上优化YOLO算法的性能,可以采取以下措施:
**1. 使用GPU加速**
YOLO算法是一个计算密集型的算法,使用GPU可以显著提高其性能。Darknet框架支持CUDA和OpenCL,可以通过在GPU上运行算法来加速计算。
**2. 优化网络结构**
YOLO算法的网络结构可以根据具体应用场景进行优化。例如,可以减少网络层数或调整卷积核大小,以提高推理速度或准确性。
**3. 使用预训练模型**
使用预训练模型可以节省训练时间并提高模型性能。Darknet框架提供了预训练的YOLO模型,可以根据需要进行微调。
**4. 优化数据预处理**
数据预处理是YOLO算法训练和推理的重要步骤。通过优化数据预处理,例如调整图像大小或使用数据增强技术,可以提高算法性能。
**5. 使用批处理**
批处理可以提高YOLO算法的训练和推理效率。通过将多个图像组合成一个批次,可以减少GPU内存占用并提高计算速度。
**代码块:YOLO算法在Windows上的性能优化**
```python
import darknet as dn
# 创建Darknet网络
net = dn.load_net("yolov3.cfg", "yolov3.weights")
# 使用GPU加速
dn.set_gpu(0)
# 优化网络结构
net.set_batch_size(16)
net.set_max_batches(1000)
# 使用预训练模型
net.load_weights("yolov3.weights")
# 优化数据预处理
dn.set_image_size(416)
dn.set_data_augmentation(True)
# 使用批处理
dn.set_batch_size(16)
# 运行YOLO算法
dn.run(net, "image.jpg")
```
**代码逻辑分析:**
* `dn.load_net()`:加载YOLO网络模型。
* `dn.set_gpu(0)`:设置使用GPU 0 进行加速。
* `net.set_batch_size(16)`:设置批处理大小为 16。
* `net.set_max_batches(1000)`:设置最大批处理次数为 1000。
* `net.load_weights("yolov3.weights")`:加载预训练的 YOLO 权重。
* `dn.set_image_size(416)`:设置图像大小为 416。
* `dn.set_data_augmentation(True)`:启用数据增强。
* `dn.set_batch_size(16)`:设置批处理大小为 16。
* `dn.run(net, "image.jpg")`:运行 YOLO 算法对图像 "image.jpg" 进行目标检测。
**参数说明:**
* `yolov3.cfg`:YOLO 网络配置文件。
* `yolov3.weights`:YOLO 网络权重文件。
* `image.jpg`:需要进行目标检测的图像。
# 3. YOLO算法的理论基础**
### 3.1 卷积神经网络(CNN)基础
卷积神经网络(CNN)是一种深度学习模型,特别适用于处理网格状数据,如图像和视频。CNN由一系列卷积层、池化层和全连接层组成。
**卷积层:**卷积层是CNN的核心,它使用卷积核(也称为滤波器)在输入数据上滑动,提取特征。卷积核的权重和偏置是学习的参数,用于调整输出特征图。
**池化层:**池化层用于减少特征图的大小,同时保留重要的特征。池化操作通常使用最大池化或平均池化,它将一个区域内的最大或平均值作为输出。
**全连接层:**全连接层将卷积层和池化层的输出展平为一维向量,并使用全连接权重和偏置进行分类或回归。
### 3.2 目标检测算法的原理和发展
目标检测算法旨在从图像或视频中定位和识别感兴趣的物体。YOLO算法是目标检测算法中的一种,它采用单次前向传播即可预测图像中的所有物体。
**目标检测算法的原理:**
1. **特征提取:**CNN用于提取图像中的特征,这些特征表示物体的形状、纹理和颜色。
2. **区域建议:**算法生成候选区域,这些区域可能包含物体。
3. **分类和回归:**算法为每个候选区域预测一个类别和一个边界框。
**YOLO算法的发展:**
* **YOLOv1:**第一个YOLO算法,使用一个CNN网络进行特征提取和预测。
* **YOLOv2:**引入了Batch Normalization和Anchor Box机制,提高了准确性和速度。
* **YOLOv3:**进一步优化了网络结构,并加入了残差连接,显著提升了性能。
* **YOLOv4:**采用了CSPDarknet53骨干网络,并集成了Bag of Freebies技术,在准确性和速度方面都取得了突破。
**代码块 3.1:YOLOv3网络结构**
```python
import torch
from torch import nn
class YOLOv3(nn.Module):
def __init__(self):
super(YOLOv3, self).__init__()
# 骨干网络
self.backbone = CSPDarknet53()
# 特征金字塔网络
self.fpn = FPN()
# 检测头
self.detection_head = DetectionHead()
def forward(self, x):
# 特征提取
features = self.backbone(x)
# 特征金字塔网络
features = self.fpn(features)
# 检测头
outputs = self.detection_head(features)
return outputs
```
**逻辑分析:**
* YOLOv3网络由骨干网络、特征金字塔网络和检测头组成。
* 骨干网络负责提取图像特征,FPN负责生成不同尺度的特征图,检测头负责预测物体类别和边界框。
* 前向传播过程包括特征提取、特征融合和检测预测。
**表格 3.1:YOLO算法的性能比较**
| 算法 | mAP | 速度 (FPS) |
|---|---|---|
| YOLOv1 | 63.4% | 45 |
| YOLOv2 | 78.6% | 60 |
| YOLOv3 | 82.1% | 51 |
| YOLOv4 | 89.6% | 65 |
**mermaid流程图 3.1:目标检测算法流程**
```mermaid
graph LR
subgraph 特征提取
A[CNN]
end
subgraph 区域建议
B[Region Proposal Network]
end
subgraph 分类和回归
C[Classifier]
D[Regressor]
end
A --> B
B --> C
B --> D
```
# 4. YOLO算法的实践应用
YOLO算法凭借其实时性和高精度,在图像分类和视频目标检测等实际应用中表现出色。本章节将探讨YOLO算法在这些领域的应用,并提供具体的案例和实现步骤。
### 4.1 YOLO算法在图像分类中的应用
#### 4.1.1 图像分类任务介绍
图像分类是指将图像中的对象归类到预定义的类别中。它在计算机视觉中是一项基础任务,广泛应用于图像搜索、社交媒体和医学影像等领域。
#### 4.1.2 YOLO算法在图像分类中的实现
YOLO算法可以轻松地应用于图像分类任务。其基本思想是将图像分类问题转换为目标检测问题。具体步骤如下:
1. **将图像预处理为固定大小:**YOLO算法要求输入图像具有固定的尺寸,例如416x416。
2. **将图像划分为网格:**将图像划分为一个网格,每个网格单元负责检测该区域内的对象。
3. **预测每个网格单元中的对象:**对于每个网格单元,YOLO算法预测该单元中存在对象的概率、对象的边界框和对象的类别。
4. **非极大值抑制:**对于每个类别,YOLO算法使用非极大值抑制算法去除重叠的边界框,只保留置信度最高的边界框。
#### 4.1.3 代码示例
```python
import cv2
import numpy as np
import darknet
# 加载 YOLO 模型
net = darknet.load_net("yolov3.cfg", "yolov3.weights", 0)
meta = darknet.load_meta("coco.data")
# 加载图像
image = cv2.imread("image.jpg")
# 预处理图像
image = cv2.resize(image, (416, 416))
# 执行 YOLO 检测
results = darknet.detect(net, meta, image)
# 解析结果
for result in results:
print(result[0], result[1], result[2])
```
### 4.2 YOLO算法在视频目标检测中的应用
#### 4.2.1 视频目标检测任务介绍
视频目标检测是指在视频序列中检测和跟踪对象。它在视频监控、体育分析和自动驾驶等领域具有重要应用。
#### 4.2.2 YOLO算法在视频目标检测中的实现
YOLO算法可以应用于视频目标检测,其基本思想是将视频帧视为一系列图像,并逐帧应用YOLO算法进行目标检测。具体步骤如下:
1. **读取视频帧:**从视频文件中读取每一帧。
2. **对每帧应用 YOLO 检测:**使用YOLO算法对每帧进行目标检测,获得对象的位置和类别。
3. **跟踪对象:**使用跟踪算法(例如卡尔曼滤波器)跟踪对象在不同帧之间的运动。
4. **显示结果:**将检测到的对象及其跟踪轨迹显示在视频帧上。
#### 4.2.3 代码示例
```python
import cv2
import darknet
import numpy as np
# 加载 YOLO 模型
net = darknet.load_net("yolov3.cfg", "yolov3.weights", 0)
meta = darknet.load_meta("coco.data")
# 打开视频文件
cap = cv2.VideoCapture("video.mp4")
# 逐帧处理视频
while True:
ret, frame = cap.read()
if not ret:
break
# 预处理图像
frame = cv2.resize(frame, (416, 416))
# 执行 YOLO 检测
results = darknet.detect(net, meta, frame)
# 解析结果
for result in results:
print(result[0], result[1], result[2])
# 显示结果
cv2.imshow("Frame", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
```
# 5. YOLO算法的性能提升
### 5.1 YOLO算法的模型优化
**5.1.1 模型量化**
模型量化是将浮点模型转换为定点模型的技术,可以显著减少模型大小和计算成本。YOLO算法中常用的量化方法包括:
- **8位量化:**将浮点权重和激活值转换为8位整数,从而将模型大小减少约4倍。
- **16位量化:**将浮点权重和激活值转换为16位整数,从而将模型大小减少约2倍。
**代码块:**
```python
import tensorflow as tf
# 创建一个浮点模型
model = tf.keras.models.load_model("yolov3.h5")
# 将模型量化为8位
quantized_model = tf.keras.models.quantize_model(model)
# 保存量化后的模型
quantized_model.save("yolov3_quantized.h5")
```
**逻辑分析:**
这段代码使用TensorFlow的`quantize_model()`函数将浮点模型转换为8位量化模型。量化后的模型保存在`yolov3_quantized.h5`文件中。
**5.1.2 模型剪枝**
模型剪枝是去除冗余权重的技术,可以减少模型大小和计算成本。YOLO算法中常用的剪枝方法包括:
- **L1正则化:**在训练过程中添加L1正则化项,鼓励权重稀疏。
- **权重修剪:**在训练后,将绝对值较小的权重设置为0。
**代码块:**
```python
import tensorflow as tf
from tensorflow.keras import backend as K
# 创建一个浮点模型
model = tf.keras.models.load_model("yolov3.h5")
# 添加L1正则化
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'],
loss_weights=[1.0, 0.001])
# 训练模型
model.fit(x_train, y_train, epochs=10)
# 剪枝权重
pruned_model = tf.keras.models.prune_model(model, prune_low_magnitude=True)
# 保存剪枝后的模型
pruned_model.save("yolov3_pruned.h5")
```
**逻辑分析:**
这段代码使用TensorFlow的`prune_model()`函数将浮点模型剪枝。剪枝后的模型保存在`yolov3_pruned.h5`文件中。
### 5.2 YOLO算法的训练技巧
**5.2.1 数据增强**
数据增强是通过对训练数据进行随机变换(如翻转、旋转、裁剪)来增加训练数据集多样性的技术。数据增强可以防止模型过拟合,提高泛化能力。
**代码块:**
```python
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 创建一个图像数据生成器
data_generator = ImageDataGenerator(rotation_range=30,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
vertical_flip=True)
# 将数据生成器应用于训练数据集
train_generator = data_generator.flow_from_directory(
"train_images",
target_size=(416, 416),
batch_size=32,
class_mode="categorical"
)
```
**逻辑分析:**
这段代码使用TensorFlow的`ImageDataGenerator`类创建了一个图像数据生成器。数据生成器应用于训练数据集,对图像进行随机变换,增加训练数据集的多样性。
**5.2.2 学习率衰减**
学习率衰减是随着训练过程的进行而降低学习率的技术。学习率衰减可以防止模型过拟合,提高收敛速度。
**代码块:**
```python
import tensorflow as tf
# 创建一个学习率衰减器
learning_rate_decay = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.001,
decay_steps=10000,
decay_rate=0.9
)
# 创建一个优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate_decay)
# 编译模型
model.compile(optimizer=optimizer, loss='mse', metrics=['accuracy'])
```
**逻辑分析:**
这段代码使用TensorFlow的`ExponentialDecay`类创建了一个学习率衰减器。学习率衰减器应用于优化器,随着训练过程的进行而降低学习率。
# 6.1 YOLO算法的最新进展
**YOLOv5:** YOLOv5是YOLO算法的最新版本,于2020年发布。它在准确性和速度方面都取得了重大改进。YOLOv5引入了许多新特性,包括:
- **Focus结构:** Focus结构是一种新的卷积层,可以减少计算量,同时保持准确性。
- **CSPDarknet53骨干网络:** CSPDarknet53骨干网络是一种新的神经网络架构,比之前的骨干网络更轻、更有效。
- **Path Aggregation Network (PAN):** PAN是一种新的特征聚合模块,可以提高小目标的检测性能。
- **Deep Supervision:** Deep Supervision是一种新的训练技术,可以提高模型的鲁棒性。
**YOLOv6:** YOLOv6是YOLO算法的最新版本,于2022年发布。它在准确性和速度方面都进一步提高了。YOLOv6引入了许多新特性,包括:
- **Equivariant Adaptive Spatial Sampling (EASS):** EASS是一种新的采样技术,可以提高模型对不同尺度目标的鲁棒性。
- **Mish激活函数:** Mish激活函数是一种新的激活函数,可以提高模型的非线性。
- **Cross-Stage Partial Connections (CSP):** CSP是一种新的连接策略,可以减少计算量,同时保持准确性。
## 6.2 YOLO算法在其他领域的应用前景
YOLO算法不仅在目标检测领域取得了成功,它还被应用于其他领域,包括:
- **图像分割:** YOLO算法可以用于分割图像中的不同对象。
- **视频分析:** YOLO算法可以用于分析视频中的动作和事件。
- **无人驾驶:** YOLO算法可以用于检测和跟踪道路上的行人、车辆和其他物体。
- **医疗成像:** YOLO算法可以用于检测和诊断医疗图像中的疾病。
随着YOLO算法的不断发展,它在其他领域的应用前景也越来越广阔。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“Windows YOLO算法”深入探讨了YOLO(You Only Look Once)算法在Windows系统上的应用。从入门指南到技术细节解析,再到优化技巧和常见问题解决方案,该专栏为读者提供了全面的YOLO算法在Windows平台上的应用知识。通过循序渐进的讲解和丰富的示例,读者可以快速掌握YOLO算法的基本原理和实现方式,并学习如何优化算法性能和准确性,打造高效的目标检测模型。专栏还提供了针对Windows YOLO算法的常见问题的解决方案,帮助读者快速解决问题,提升算法的稳定性和可靠性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
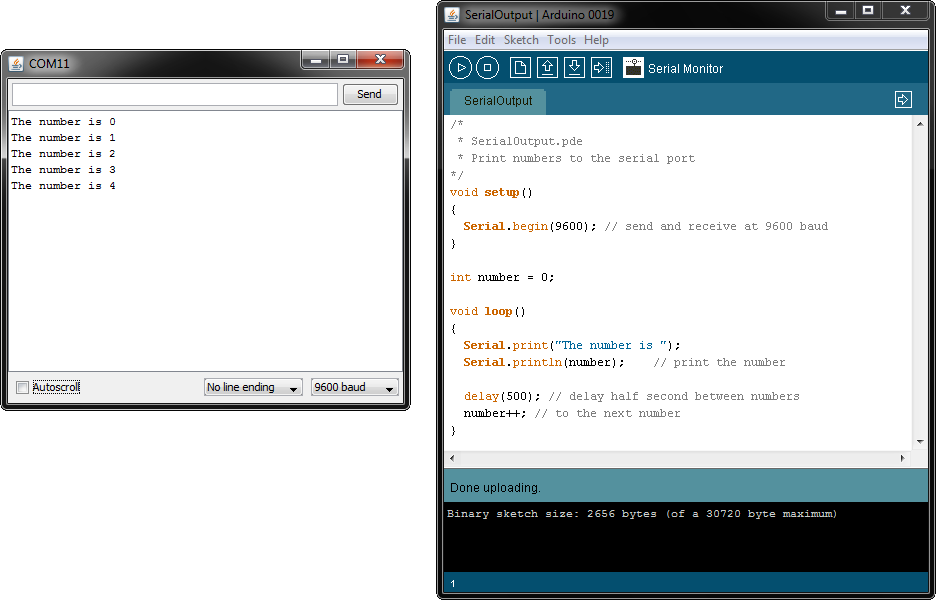
微机接口技术深度解析:串并行通信原理与实战应用
# 摘要
微机接口技术是计算机系统中不可或缺的部分,涵盖了从基础通信理论到实际应用的广泛内容。本文旨在提供微机接口技术的全面概述,并着重分析串行和并行通信的基本原理与应用,包括它们的工作机制、标准协议及接口技术。通过实例介绍微机接口编程的基础知识、项目实践以及在实际应用中的问题解决方法。本文还探讨了接口技术的新兴趋势、安全性和兼容
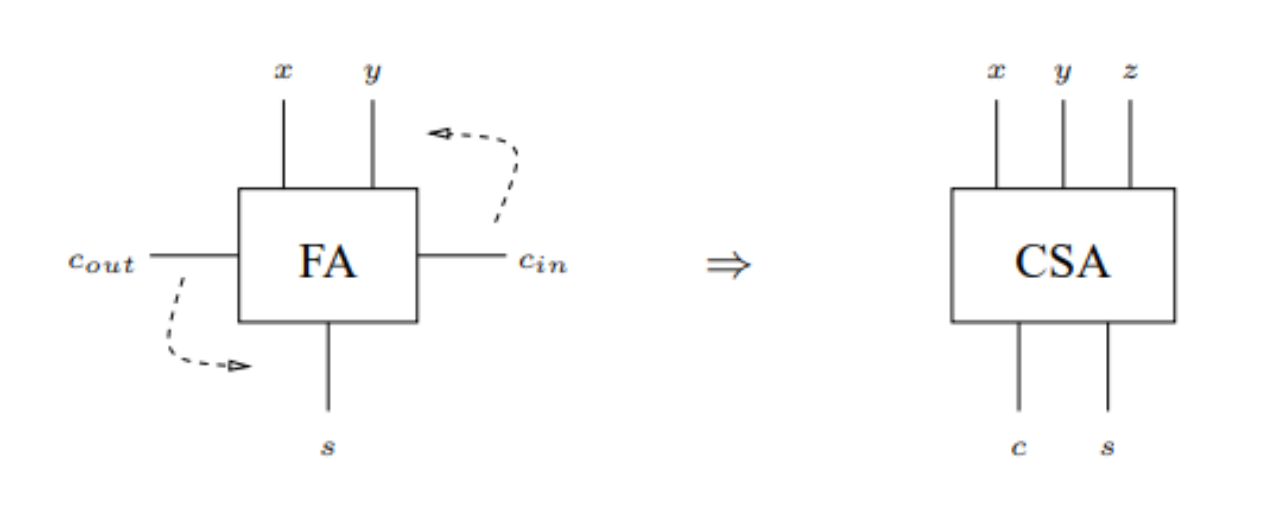
【进位链技术大剖析】:16位加法器进位处理的全面解析
# 摘要
进位链技术是数字电路设计中的基础,尤其在加法器设计中具有重要的作用。本文从进位链技术的基础知识和重要性入手,深入探讨了二进制加法的基本规则以及16位数据表示和加法的实现。文章详细分析了16位加法器的工作原理,包括全加器和半加器的结构,进位链的设计及其对性能的影响,并介绍了进位链优化技术。通过实践案例,本文展示了进位链技术在故障诊断与维护中的应用,并探讨了其在多位加法器设计以及多处理器系统中的高级应用。最后,文章展望了进位链技术的未来,
【均匀线阵方向图秘籍】:20个参数调整最佳实践指南
# 摘要
均匀线阵方向图是无线通信和雷达系统中的核心技术之一,其设计和优化对系统的性能至关重要。本文系统性地介绍了均匀线阵方向图的基础知识,理论基础,实践技巧以及优化工具与方法。通过理论与实际案例的结合,分析了线阵的基本概念、方向图特性、理论参数及其影响因素,并提出了方向图参数调整的多种实践技巧。同时,本文探讨了仿真软件和实验测量在方向图优化中的应用,并介绍了最新的优化算法工具。最后,展望了均匀线阵方向图技术的发展趋势,包括新型材料和技术的应用、智能化自适应方向图的研究,以及面临的技术挑战与潜在解决方案。
# 关键字
均匀线阵;方向图特性;参数调整;仿真软件;优化算法;技术挑战
参考资源链
ISA88.01批量控制:制药行业的实施案例与成功经验

# 摘要
ISA88.01标准为批量控制系统提供了框架和指导原则,尤其是在制药行业中,其应用能够显著提升生产效率和产品质量控制。本文详细解析了ISA88.01标准的概念及其在制药工艺中的重要
实现MVC标准化:肌电信号处理的5大关键步骤与必备工具

# 摘要
本文探讨了MVC标准化在肌电信号处理中的关键作用,涵盖了从基础理论到实践应用的多个方面。首先,文章介绍了
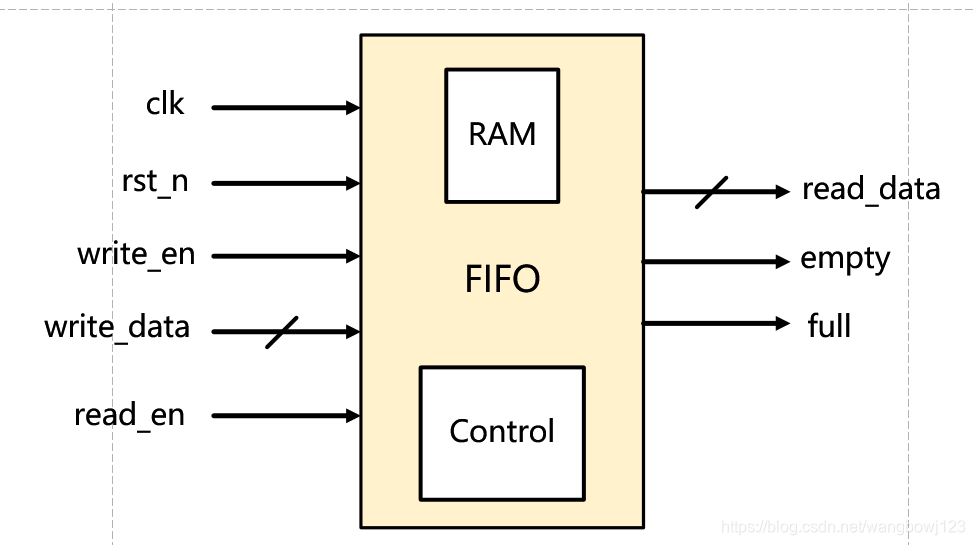
【FPGA性能暴涨秘籍】:数据传输优化的实用技巧
# 摘要
本文全面介绍了FPGA在数据传输领域的应用和优化技巧。首先,对FPGA和数据传输的基本概念进行了介绍,然后深入探讨了FPGA内部数据流的理论基础,包
PCI Express 5.0性能深度揭秘:关键指标解读与实战数据分析

# 摘要
PCI Express(PCIe)技术作为计算机总线标准,不断演进以满足高速数据传输的需求。本文首先概述PCIe技术,随后深入探讨PCI Express 5.0的关键技术指标,如信号传输速度、编码机制、带宽和吞吐量的理论极限以及兼容性问题。通过实战数据分析,评估PCI Express
CMW100 WLAN指令手册深度解析:基础使用指南揭秘
# 摘要
CMW100 WLAN指令是业界广泛使用的无线网络测试和分析工具,为研究者和工程师提供了强大的网络诊断和性能评估能力。本文旨在详细介绍CMW100 WLAN指令的基础理论、操作指南以及在不同领域的应用实例。首先,文章从工作原理和系统架构两个层面探讨了CMW100 WLAN指令的基本理论,并解释了相关网络协议。随后,提供了详细的操作指南,包括配置、调试、优化及故障排除方法。接着,本文探讨了CMW100 WLAN指令在网络安全、网络优化和物联网等领域的实际应用。最后,对CMW100 WLAN指令的进阶应用和未来技术趋势进行了展望,探讨了自动化测试和大数据分析中的潜在应用。本文为读者提供了
三菱FX3U PLC与HMI交互:打造直觉操作界面的秘籍

# 摘要
本论文详细介绍了三菱FX3U PLC与HMI的基本概念、工作原理及高级功能,并深入探讨了HMI操作界面的设计原则和高级交互功能。通过对三菱FX3U PLC的编程基础与高级功能的分析,本文提供了一系列软件集成、硬件配置和系统测试的实践案例,以及相应的故障排除方法。此外,本文还分享了在不同行业应用中的案例研究,并对可能出现的常见问题提出了具体的解决策略。最后,展望了新兴技术对PLC和HMI
【透明度问题不再难】:揭秘Canvas转Base64时透明度保持的关键技术

# 摘要
本文旨在全面介绍Canvas转Base64编码技术,从基础概念到实际应用,再到优化策略和未来趋势。首先,我们探讨了Canvas的基本概念、应用场景及其重要性,紧接着解析了Base64编码原理,并重点讨论了透明度在Canvas转Base64过程中的关键作用。实践方法章节通过标准流程和技术细节的讲解,提供了透明度保持的有效编码技巧和案例分析。高级技术部分则着重于性能优化、浏览器兼容性问题以及Ca
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )