Scrapy框架二次开发与定制之道
发布时间: 2024-01-26 10:25:34 阅读量: 63 订阅数: 42 

Scrapy Web爬虫框架 v1.8.4.zip
# 1. Scrapy框架概述与基本功能介绍
## 1.1 什么是Scrapy框架
Scrapy框架是一个基于Python的开源网络爬虫框架,用于快速和高效地抓取网页数据。它提供了一套完整的工具和组件,使开发者可以方便地定义爬取规则、进行页面解析、数据提取和持久化等操作。
## 1.2 Scrapy框架的基本功能及优势
Scrapy框架的基本功能包括网页请求、页面解析、数据提取、持久化存储等。与其他爬虫框架相比,Scrapy具有以下优势:
- 异步请求:Scrapy框架采用异步请求,可以高效地并发爬取多个网页,提高爬取速度。
- 定制能力强:Scrapy框架提供了丰富的配置选项和扩展机制,可以根据需求定制爬虫的行为。
- 自动化处理:Scrapy框架自动处理请求的发送和响应的接收,开发者只需要关注数据的提取和处理。
- 丰富的中间件支持:Scrapy框架支持自定义的中间件,可以在请求和响应的各个阶段进行处理和修改。
- 分布式支持:Scrapy框架可以与分布式存储系统和任务调度系统结合使用,实现分布式爬取和任务调度。
## 1.3 Scrapy框架的基本组件介绍
Scrapy框架由以下几个基本组件组成:
- **引擎(Engine)**:作为框架的核心,负责控制整个爬虫的流程和调度各个组件的工作。
- **调度器(Scheduler)**:负责接收引擎发送的请求,并根据某种策略进行调度,将请求发送给下载器进行下载。
- **下载器(Downloader)**:负责下载网页内容,并将下载得到的响应返回给引擎。
- **解析器(Parser)**:负责解析下载得到的网页内容,并提取数据。
- **项目管道(Item Pipeline)**:负责对从网页中提取的数据进行处理和持久化存储。
- **中间件(Middleware)**:负责处理请求和响应的中间环节,可以进行请求的修改、修改响应,甚至拦截请求和响应进行处理。
以上是Scrapy框架概述与基本功能介绍的内容。在接下来的章节中,我们将深入讨论Scrapy框架的二次开发和定制相关内容。
# 2. Scrapy框架二次开发入门
在本章中,我们将介绍如何进行Scrapy框架的二次开发,包括定制中间件、编写自定义的Pipeline以及定制下载器组件。
#### 2.1 定制Scrapy框架的中间件
在这一节中,我们将学习如何通过编写自定义的中间件,来对Scrapy框架的请求和响应进行预处理和后处理。我们将通过实际的案例来演示如何编写和配置自定义中间件,并且讲解中间件的应用场景和原理。
```python
# 示例代码:自定义中间件示例
class CustomMiddleware(object):
def process_request(self, request, spider):
# 在发出请求前的预处理操作
if condition:
# 对请求进行定制化处理
pass
return None
def process_response(self, request, response, spider):
# 在收到响应后的后处理操作
if condition:
# 对响应进行定制化处理
pass
return response
```
**代码总结:**
- 自定义中间件需要实现`process_request`和`process_response`方法。
- 可以在`process_request`中对请求进行预处理,比如添加特定的请求头信息。
- 在`process_response`中可以对响应进行后处理,比如验证响应的有效性。
**结果说明:**
通过编写自定义中间件,我们可以灵活地对Scrapy框架的请求和响应进行定制化处理,从而满足不同的需求场景。
#### 2.2 编写自定义的Pipeline
本节中,我们将介绍如何编写自定义的Pipeline,在Scrapy框架中进行数据的处理和持久化操作。我们将通过实际的案例来演示如何编写自定义Pipeline,并且讲解Pipeline在数据处理和持久化中的应用。
```python
# 示例代码:自定义Pipeline示例
class CustomPipeline(object):
def process_item(self, item, spider):
# 对Item进行处理和持久化操作
if condition:
# 执行特定的处理逻辑
pass
return item
```
**代码总结:**
- 自定义Pipeline需要实现`process_item`方法,对Item进行处理和持久化操作。
- 可以根据实际需求,自定义处理逻辑,包括数据清洗、数据存储等操作。
**结果说明:**
通过编写自定义Pipeline,我们可以对爬取到的数据进行灵活的处理和持久化操作,满足不同数据处理需求。
#### 2.3 定制Scrapy的下载器组件
在本节中,我们将学习如何对Scrapy框架的下载器组件进行定制,包括设置代理、处理超时等。我们将通过实际的示例来演示如何编写自定义的下载器组件,并讲解下载器组件的应用场景和原理。
```python
# 示例代码:定制下载器组件示例
class CustomDownloaderMiddleware(object):
def process_request(self, request, spider):
# 在发出请求前的预处理操作
if condition:
# 添加代理信息等定制操作
pass
return None
def process_response(self, request, response, spider):
# 在收到响应后的后处理操作
if condition:
# 对响应进行定制化处理
pass
return response
```
**代码总结:**
- 定制下载器组件需要编写自定义的Downloader Middleware,并实现`process_request`和`process_response`方法。
- 可以在`process_request`中进行请求的定制化处理,比如添加代理信息。
- 在`process_response`中可以对响应进行后处理,比如处理特定的响应内容。
**结果说明:**
通过定制下载器组件,我们可以在发出请求前和收到响应后对请求和响应进行定制化处理,满足不同的下载需求场景。
希望以上内容能够帮助你深入理解Scrapy框架的二次开发及定制化功能。
# 3. 使用Scrapy框架进行页面解析与数据提取
在本章中,我们将深入探讨如何使用Scrapy框架进行页面解析与数据提取。这是爬虫工作中非常关键的一环,也是Scrapy框架的核心功能之一。
#### 3.1 页面解析器的选择与配置
在使用Scrapy框架进行页面解析时,我们通常会面对多种页面结构和数据格式。因此,在选择页面解析器时,需要根据具体的情况进行选择。
**场景**
假设我们需要爬取一个网站上的商品信息,该网站的页面使用了HTML和JavaScript进行渲染,我们需要解析这些页面获取所需的商品数据。
**代码**
```python
import scrapy
class ProductSpider(scrapy.Spider):
name = 'product_spider'
start_urls = ['http://www.example.com/products']
def parse(self, response):
products = response.css('div.product')
for product in products:
title = product.css('h2.title::text').get()
price = product.css('span.price::text').get()
yield {
'title': title,
'price': price
}
```
**代码总结**
- 通过`response.css`方法选择页面中的特定元素
- 使用`yield`关键字生成需要提取的数据
**结果说明**
通过以上代码,我们可以解析商品页面,提取出商品的标题和价格数据。
#### 3.2 数据提取规则的编写
除了选择页面解析器外,编写数据提取规则也是爬虫工作中不可或缺的一部分。Scrapy框架提供了强大的数据提取功能,可以根据需要编写灵活的数据提取规则。
**场景**
我们需要从网页中提取出符合特定规则的数据,例如所有的链接地址。
**代码**
```python
import scrapy
class LinkSpider(scrapy.Spider):
name = 'link_spider'
start
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Scrapy框架核心原理实战与源码分析》是一门旨在帮助初学者掌握Scrapy框架核心原理和实战技巧的专栏。专栏从Scrapy框架的简介与基本原理入手,详细解析了Scrapy框架的安装与环境配置方法,并通过实例演示了如何编写第一个爬虫。此外,专栏还深入探讨了Scrapy框架的数据存储与管道技术,并介绍了性能优化和并发爬取的关键技巧。随后,专栏还介绍了Scrapy框架的部署与监控实践指南,帮助读者将爬虫应用于实际项目中。最后,专栏还涉及了Scrapy框架的二次开发与定制技巧,以及异步IO技术的应用。通过学习本专栏,读者将全面掌握Scrapy框架的核心原理和实战技巧,为实际项目开发提供强大支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据链路层深度剖析:帧、错误检测与校正机制,一次学懂

# 摘要
数据链路层是计算机网络架构中的关键组成部分,负责在相邻节点间可靠地传输数据。本文首先概述了数据链路层的基本概念和帧结构,包括帧的定义、类型和封装过程。随后,文章详细探讨了数据链路层的错误检测机制,包括检错原理、循环冗余检验(CRC)、奇偶校验和校验和,以及它们在错误检测中的具体应用。接着,本文介绍了数据链路层的错误校正技术,如自动重传请求(ARQ
【数据完整性管理】:重庆邮电大学实验报告中的关键约束技巧
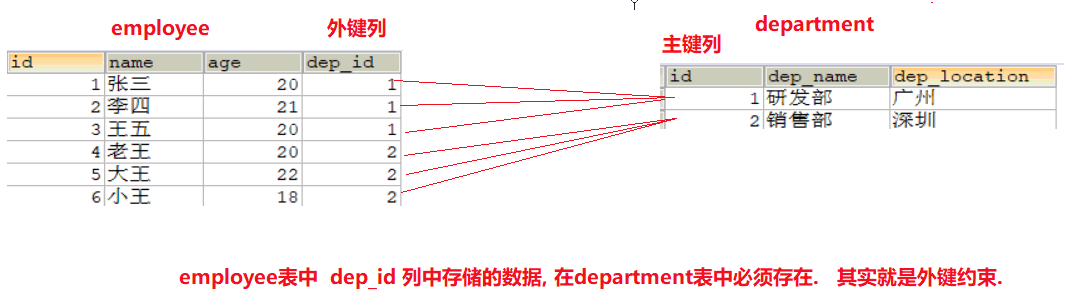
# 摘要
数据完整性是数据库管理系统中至关重要的概念,它确保数据的质量和一致性。本文首先介绍了数据完整性的概念、分类以及数据库约束的基本原理和类型。随后,文章深入探讨了数据完整性约束在实践中的具体应用,包括主键和外键约束的设置、域约束的管理和高级技巧如触发器和存储过程的运用。接着,本文分析了约束带来的性能影响,并提出了约束优化与维护的策略。最后,文章通过案例分析,对数据完整性管理进行了深度探讨,总结了实际操作中的
深入解析USB协议:VC++开发者必备的8个关键点
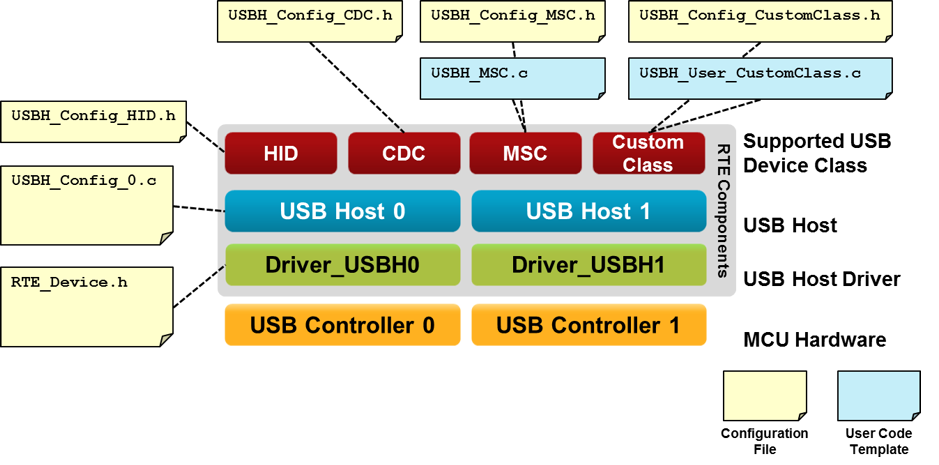
# 摘要
本文系统地介绍了USB协议的基础知识、硬件基础、数据传输机制、在VC++中的实现以及高级特性与编程技巧。首先概述USB协议的基础,然后详细探讨了USB硬件的物理接口、连接规范、电源管理和数据传输的机制。文章接着阐述了在VC++环境下USB驱动程序的开发和与USB设备通信的编程接口。此外,还涉及了USB设备的热插拔与枚举过程、性能优化,以及USB协议高级特性和编程技巧。最后,本文提供了USB设备的调试工具和方法,以
【科东纵密性能调优手册】:监控系统到极致优化的秘笈

# 摘要
性能调优是提高软件系统效率和响应速度的关键环节。本文首先介绍了性能调优的目的与意义,概述了其基本原则。随后,深入探讨了系统性能评估的方法论,包括基准测试、响应时间与吞吐量分析,以及性能监控工具的使用和系统资源的监控。在硬件优化策略方面,详细分析了CPU、内存和存储的优化方法。软件与服务优化章节涵盖了数据库、应用程序和网络性能调
【FPGA引脚规划】:ug475_7Series_Pkg_Pinout.pdf中的引脚分配最佳实践

# 摘要
本文全面探讨了FPGA引脚规划的关键理论与实践方法,旨在为工程师提供高效且可靠的引脚配置策略。首先介绍了FPGA引脚的基本物理特性及其对设计的影响,接着分析了设计时需考虑的关键因素,如信号完整性、热管理和功率分布。文章还详细解读了ug475_7S
BY8301-16P语音模块全面剖析:从硬件设计到应用场景的深度解读
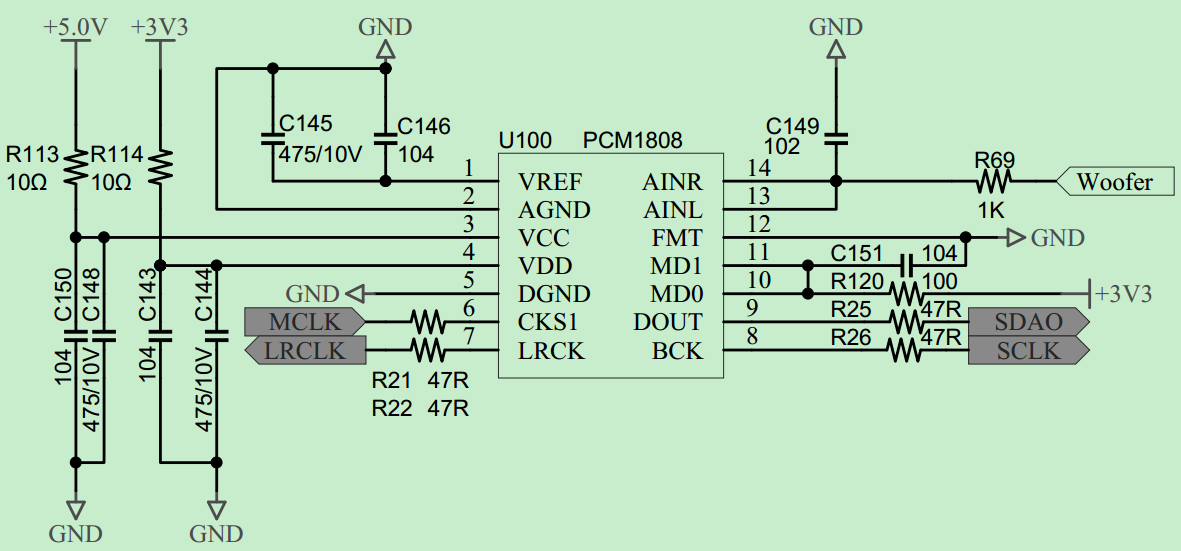
# 摘要
本文详细介绍了BY8301-16P语音模块的技术细节、硬件设计、软件架构及其应用场景。首先概述了该模块的基本功能和特点,然后深入解析其硬件设计,包括主控芯片、音频处理单元、硬件接口和电路设计的优化。接着,本文探讨了软件架构、编程接口以及高级编程技术,为开发者提供了编程环境搭建和
【Ansys命令流深度剖析】:从脚本到高级应用的无缝进阶
# 摘要
本文深入探讨了Ansys命令流的基础知识、结构和语法、实践应用、高级技巧以及案例分析与拓展应用。首先,介绍了Ansys命令流的基本构成,包括命令、参数、操作符和分隔符的使用。接着,分析了命令流的参数化、数组操作、嵌套命令流和循环控制,强调了它们在提高命令流灵活性和效率方面的作用。第三章探讨了命令流在材料属性定义、网格划分和结果后处理中的应用,展示了其在提高仿真精度和效率上的实际价值。第四章介绍了命令流的高级技巧,包括宏定义、用户自定义函数、错误处理与调试以及并行处理与性能优化。最后,第五章通过案例分析和扩展应用,展示了命令流在复杂结构模拟和多物理场耦合中的强大功能,并展望了其未来趋势
【Ubuntu USB转串口驱动安装】:新手到专家的10个实用技巧

# 摘要
本文详细介绍了在Ubuntu系统下安装和使用USB转串口驱动的方法。从基础介绍到高级应用,本文系统地探讨了USB转串口设备的种类、Ubuntu系统的兼容性检查、驱动的安装步骤及其验证、故障排查、性能优化、以及在嵌入式开发和远程管理中的实际应用场景。通过本指南,用户可以掌握USB转串口驱动的安装与管理,确保与各种USB转串口设备的顺畅连接和高效使用。同时,本文还提
RH850_U2A CAN Gateway高级应用速成:多协议转换与兼容性轻松掌握

# 摘要
本文全面概述了RH850_U2A CAN Gateway的技术特点,重点分析了其多协议转换功能的基础原理及其在实际操作中的应用。通过详细介绍协议转换机制、数据封装与解析技术,文章展示了如何在不同通信协议间高效转换数据包。同时,本文还探讨了RH850_U2A CAN Gateway在实际操作过程中的设备初始化、协议转换功能实现以及兼容性测试等关键环节。此外,文章还介
【FPGA温度监测:Xilinx XADC实际应用案例】

# 摘要
本文探讨了FPGA在温度监测中的应用,特别是Xilinx XADC(Xilinx Analog-to-Digital Converter)的核心
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )