微服务Eureka注册与发现机制详细解析
发布时间: 2024-02-19 04:44:32 阅读量: 41 订阅数: 22 

基于net的超市管理系统源代码(完整前后端+sqlserver+说明文档+LW).zip
# 1. 微服务架构概述
## 1.1 微服务架构概念
在传统的单体应用架构中,所有功能模块都集中在一个应用中,这导致了开发、部署、扩展等方面的困难。微服务架构是一种以服务为中心的架构风格,通过将应用拆分成一组小型、独立的服务来解决传统架构的问题。每个微服务可独立开发、部署和扩展,各个服务之间通过轻量级通信机制相互配合。
## 1.2 微服务架构优势
- **灵活性**:各个微服务可以使用不同的技术栈,独立开发、部署和扩展,更易于应对不同需求。
- **可伸缩性**:针对具体服务进行横向或纵向扩展,无需整体扩展整个应用。
- **可维护性**:每个微服务都是独立实现的,故障定位和排除更为简单。
- **快速交付**:各个微服务独立部署,可以快速迭代发布新功能。
## 1.3 微服务架构挑战与解决方案
- **复杂性管理**:微服务架构会导致服务间的复杂交互,需要良好的设计和管理,可以使用API网关、服务注册与发现等解决方案。
- **数据一致性**:跨服务操作可能导致数据一致性问题,可以采用分布式事务、最终一致性等方式解决。
- **性能监控**:微服务众多,难以进行整体性能监控,需借助监控系统进行性能分析。
接下来,我们将介绍Eureka服务注册与发现,作为微服务架构中常用的服务注册中心。
# 2. Eureka服务注册与发现介绍
在本章中,我们将深入介绍Eureka服务注册与发现的相关内容,包括Eureka的概述、服务注册原理以及服务发现原理。
### 2.1 Eureka概述
Eureka是Netflix开源的基于REST的服务治理框架,用于实现中间层服务器的负载均衡和故障转移。它包含两个组件:Eureka Server和Eureka Client。Eureka Server用作服务注册中心,而Eureka Client用于与Eureka Server进行通信并注册服务。
### 2.2 Eureka服务注册原理
当微服务启动时,Eureka Client会向Eureka Server发送服务注册请求,将自己注册到服务中。在Eureka Server上,会存储所有注册的服务信息,包括服务名、IP地址、端口等。Eureka Server会定期从Eureka Client接收心跳和健康检查信息,以维持服务的可用性。
```java
// 伪代码示例:微服务注册到Eureka
@RestController
public class EurekaRegistrationController {
@Autowired
private EurekaClient eurekaClient;
@RequestMapping("/register")
public String registerService(@RequestParam String serviceName, @RequestParam String ipAddress, @RequestParam int port) {
InstanceInfo instanceInfo = InstanceInfo.Builder.newBuilder()
.setAppName(serviceName)
.setInstanceIp(ipAddress)
.setInstancePort(port)
.build();
eurekaClient.register(instanceInfo);
return "Service registered successfully!";
}
}
```
**代码总结:** 上述代码演示了如何将微服务注册到Eureka Server,通过EurekaClient向注册中心发送服务注册请求,将服务信息注册到Eureka Server中。
**结果说明:** 当服务成功注册到Eureka Server后,其他微服务可以通过Eureka Client从注册中心获取该服务的信息,实现了服务的动态发现和调用。
### 2.3 Eureka服务发现原理
微服务在启动时,会向Eureka Server发送服务注册请求,将自己注册到Eureka注册中心。而在服务调用时,其他微服务通过Eureka Client向Eureka Server发送服务发现请求,获取目标服务的IP地址和端口信息,实现了服务间的通讯。
```java
// 伪代码示例:微服务从Eureka发现服务
@RestController
public class EurekaDiscoveryController {
@Autowired
private EurekaClient eurekaClient;
@RequestMapping("/discover")
public String discoverService(@RequestParam String serviceName) {
Application application = eurekaClient.getApplication(serviceName);
List<InstanceInfo> instances = application.getInstances();
InstanceInfo instance = instances.get(0);
return instance.getHostName() + ":" + instance.getPort();
}
}
```
**代码总结:** 上述代码展示了微服务如何通过Eureka Client从Eureka Server中发现指定服务的信息,并获取该服务的IP地址和端口,实现服务调用。
**结果说明:** 通过Eureka服务发现,微服务可以简单、快捷地获取其他服务的信息,实现了微服务之间的通讯与调用。
# 3. 微服务与Eureka集成
微服务架构中,服务的注册与发现是一个重要的组成部分。Eureka作为Netflix开源的服务注册与发现组件,为微服务架构提供了便捷的解决方案。本章将介绍微服务如何与Eureka进行集成,包括服务的注册到Eureka、从Eureka发现服务以及Eureka集群部署与配置等内容。
#### 3.1 微服务注册到Eureka
在微服务架构中,服务需要注册到Eureka以便其他服务能够发现和调用它。下面以Java语言为例,演示一个简单的微服务注册到Eureka的代码示例。
```java
// 使用Spring Cloud的注解@EnableEurekaClient,标识该服务需要注册到Eureka
@SpringBootApplication
@EnableEurekaClient
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class, args);
}
}
```
通过在服务的启动类上加上`@EnableEurekaClient`注解,就可以实现将该服务注册到Eureka Server中。在application.properties或application.yml中配置Eureka Server的地址:
```yaml
eureka:
client:
service-url:
defaultZone: http://eureka-server:8761/eureka/
```
这样就完成了微服务注册到Eureka Server的配置。
#### 3.2 微服务从Eureka发现服务
在微服务架构中,一个服务通常需要调用其他服务提供的接口。Eureka提供了服务发现的能力,使得服务能够动态地发现其他服务的实例地址。下面演示一个简单的微服务从Eureka发现服务的代码示例。
```java
@RestController
public class UserController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/user/{id}")
public User getUserById(@PathVariable Long id) {
// 通过Eureka Server的服务名调用远程服务
return restTemplate.getForObject("http://user-service/user/" + id, User.class);
}
}
```
在上面的示例中,通过使用RestTemplate和Eureka Server的服务名来调用远程服务,无需硬编码具体的服务实例地址,从而实现了服务发现的功能。
#### 3.3 Eureka集群部署与配置
为了确保Eureka Server的高可用性和扩展性,通常会进行集群部署。下面简要介绍一下Eureka集群的部署与配置。
在Eureka Server的配置文件中,需要配置多个Eureka Server的地址:
```yaml
eureka:
client:
service-url:
defaultZone: http://eureka-server1:8761/eureka/,http://eureka-server2:8762/eureka/
instance:
prefer-ip-address: true # 设置为true,以IP方式注册服务实例
```
通过上述配置,可以将多个Eureka Server组成一个集群,并确保各个Eureka Server之间能够相互注册和相互发现,从而实现高可用的Eureka集群部署。
以上是微服务与Eureka集成的基本内容,包括服务注册、服务发现以及集群部署与配置等方面。通过Eureka的支持,微服务架构得以更好地运作和发展。
# 4. Eureka的工作原理分析
在本章中,我们将深入探讨Eureka的工作原理,包括其对CAP理论的支持、注册表的维护和更新,以及健康检查机制。
### 4.1 Eureka的CAP理论支持
Eureka通过CAP(一致性、可用性、分区容忍性)理论来保证系统的可靠性和稳定性。在CAP理论中,Eureka主要侧重于实现分区容忍性(Partition Tolerance)和可用性(Availability),而在一定情况下牺牲了一致性(Consistency)。这意味着,即使在网络出现故障或分区的情况下,Eureka仍然能够保持基本的可用性,确保系统的正常运行。
### 4.2 Eureka注册表的维护和更新
Eureka服务注册表是Eureka体系结构的核心组件,负责存储所有可用服务实例的信息,并且能够快速、准确地更新这些信息。当一个微服务实例启动时,它会向Eureka服务器注册自己的信息(例如IP地址、端口号、服务名称等)。同时,每隔30秒,该微服务实例会发送一次心跳以确认自己仍然处于活跃状态。如果Eureka在一定时间内没有收到该微服务实例的心跳,则会将该实例从注册表中剔除,确保注册表的信息是最新的、准确的。
### 4.3 Eureka健康检查机制
Eureka通过定期发送心跳来检查服务的健康状态。当某个服务连续几次未能按时发送心跳,Eureka会将该服务实例标记为不健康,停止将其提供给客户端。这一机制确保了客户端只能获取到健康的服务实例,提高了系统的可靠性和稳定性。
通过深入了解Eureka的工作原理,我们能够更好地理解其在微服务架构中的作用,并且能够更好地应用和优化Eureka相关的功能。
希望本章内容能够帮助您更深入地理解Eureka的工作原理。
# 5. Eureka的高可用与扩展
在本章中,我们将深入探讨Eureka的高可用性和扩展性,以及如何构建具有弹性和可伸缩性的Eureka集群。
### 5.1 Eureka高可用解决方案
#### 5.1.1 单点故障与高可用性
在传统的单机Eureka部署中,一旦Eureka Server出现故障,将导致所有服务注册和发现功能不可用,从而带来严重的影响。因此,构建高可用的Eureka集群至关重要。
#### 5.1.2 Eureka高可用架构
为了实现高可用性,我们可以通过在多台服务器上部署多个Eureka实例,并通过负载均衡器将客户端请求分发到这些实例上。当某一实例发生故障时,其他实例仍然可以继续提供服务,确保整个系统的可用性。
#### 5.1.3 Eureka的自我保护模式
Eureka具有自我保护机制,当Eureka Server在一定时间内没有收到心跳时,它将进入自我保护模式,不会立即剔除健康检查失败的服务实例,从而避免由于网络抖动或短暂故障导致大规模服务实例的剔除,保证系统的稳定性。
### 5.2 Eureka集群的搭建与负载均衡
#### 5.2.1 Eureka集群部署
通过在不同的服务器上部署多个Eureka实例,然后通过配置彼此的地址信息,构建一个Eureka集群。通过集群部署,我们可以确保即使部分Eureka实例发生故障,整个系统仍然能够保持高可用性。
#### 5.2.2 负载均衡策略
在Eureka集群中,通常会使用负载均衡器(如Nginx、HAProxy等)来实现客户端请求的分发,以达到均衡各个Eureka实例的负载,从而提高系统的并发处理能力和整体性能。
### 5.3 Eureka扩展功能介绍
#### 5.3.1 Eureka数据持久化
Eureka Server 默认使用内存来存储注册表信息,但在生产环境中,为了避免单点故障,通常会考虑将注册表信息持久化到数据库中,如MySQL、MongoDB等,以确保系统数据的安全性和可靠性。
#### 5.3.2 Eureka安全机制
Eureka提供了基于安全组件的扩展,可以实现对服务注册和发现的安全控制,包括认证、授权、HTTPS等机制,以确保系统的安全通信和数据保护。
#### 5.3.3 Eureka监控和告警
通过整合监控系统(如Spring Boot Actuator、Micrometer等)和告警系统(如Prometheus、Grafana等),可以实现对Eureka集群的监控和异常告警,及时发现和解决潜在的问题,提高系统的稳定性和可靠性。
以上就是关于Eureka的高可用与扩展的内容,希望对你有所帮助!
# 6. 微服务Eureka最佳实践
微服务的架构设计离不开Eureka这样的服务注册与发现工具,但是如何最好地利用Eureka来实现微服务架构的优化与提升,是每个开发者都需要思考和实践的问题。在本章节中,我们将介绍一些微服务Eureka的最佳实践,包括部署、性能优化以及故障处理与排查等方面。
#### 6.1 微服务Eureka部署最佳实践
在部署微服务与Eureka时,有几个关键的最佳实践需要注意:
1. **Eureka集群部署**:为了保证高可用性,建议至少将Eureka注册中心部署为3个节点以上的集群,这样即使某个节点宕机,其他节点仍然可以提供服务。
2. **分布式部署**:将微服务实例部署在不同的节点上,避免单点故障对整个系统产生影响。
3. **监控与告警**:建议使用监控系统对Eureka集群的状态进行监控,并设置告警机制,及时发现和处理异常情况。
#### 6.2 微服务Eureka性能优化
为了提升微服务与Eureka的性能,在实践中可以进行以下优化:
1. **减少注册信息大小**:尽量减少每个微服务实例注册到Eureka上的额外信息,只保留必要的元数据,可以减少网络传输开销。
2. **合理设置心跳间隔**:合理设置Eureka客户端发送心跳的间隔时间,可以通过调整配置参数来达到最佳效果。
3. **缓存注册信息**:对Eureka注册信息进行本地缓存,减少对Eureka服务器的访问,提升性能。
#### 6.3 微服务Eureka故障处理与排查
在使用微服务与Eureka过程中,难免会遇到各种故障,为了提高系统的稳定性和可靠性,需要做好故障处理与排查工作:
1. **日志监控**:及时监控系统日志,发现异常情况并定位问题所在。
2. **灰度发布**:采用灰度发布策略,逐步将新版本微服务注册到Eureka上,降低发布过程中的风险。
3. **故障演练**:定期进行故障演练,模拟各种故障情况,验证系统的容错能力。
通过以上最佳实践,可以帮助开发者更好地搭建和维护微服务与Eureka集成的架构,提升系统性能和可靠性,实现更好的应用体验。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨微服务Eureka的原理与应用,首先从源码角度对微服务Eureka进行详细解析,深度分析其注册与发现机制,以及与Feign的无缝集成方式。随后,结合实战经验,分享微服务Eureka集群搭建方法与服务治理、负载均衡技巧,探索其动态路由策略及与Hystrix熔断降级机制结合的实现原理。同时还分享微服务Eureka与Spring Boot集成的优化技巧以及与Kubernetes集成与实践探索。此外,还会深入研究Eureka服务网关与安全机制,展望Eureka的新特性与未来发展方向,并根据大型项目中的应用案例进行解析,旨在帮助读者全面了解Eureka并在实际项目中运用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
功能安全完整性级别(SIL):从理解到精通应用

# 摘要
功能安全完整性级别(SIL)是衡量系统功能安全性能的关键指标,对于提高系统可靠性、降低风险具有至关重要的作用。本文系统介绍了SIL的基础知识、理论框架及其在不同领域的应用案例,分析了SIL的系统化管理和认证流程,并探讨了技术创新与SIL认证的关系。文章还展望了SIL的创新应用和未来发展趋势,强调了在可持续发展和安全文化推广中SIL的重要性。通过对SIL深入的探讨和分析,本文旨在为相关行业提供参考,促进功
ZTW622在复杂系统中的应用案例与整合策略

# 摘要
ZTW622技术作为一种先进的解决方案,在现代复杂系统中扮演着重要角色。本文全面概述了ZTW622技术及其在ERP、CRM系统以及物联网领域的应用案例,强调了技术整合过程中的挑战和实际操作指南。文章深入探讨了ZTW622的整合策略,包括数据同步、系统安全、性能优化及可扩展性,并提供了实践操作指南。此外,本文还分享了成功案例,分析了整合过程中的挑战和解决方案,最后对ZT
【Python并发编程完全指南】:精通线程与进程的区别及高效应用
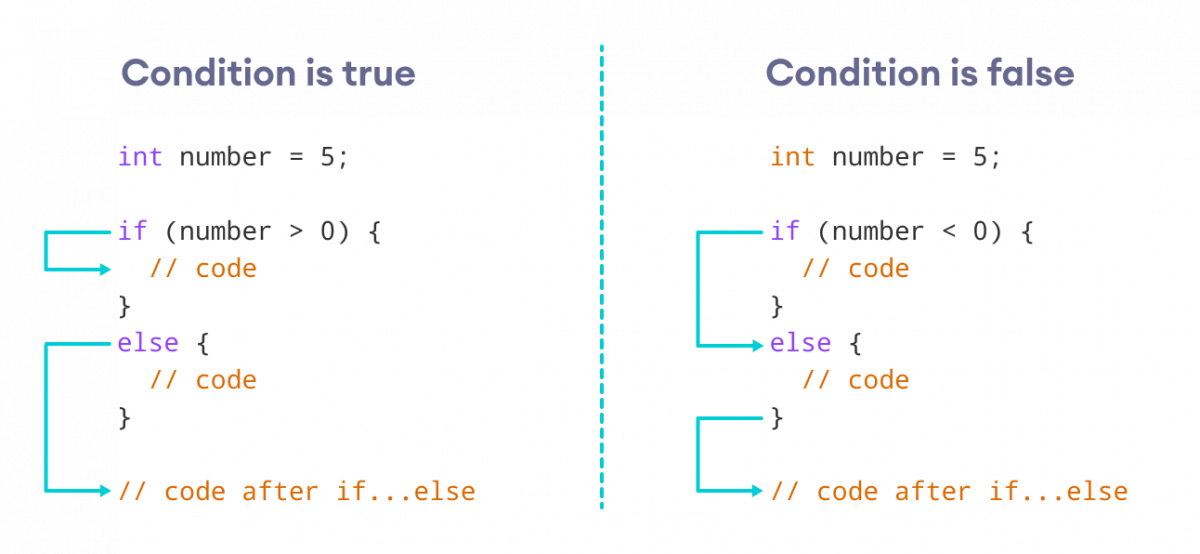
# 摘要
本文详细探讨了Python中的并发编程模型,包括线程和进程的基础知识、高级特性和性能优化。文章首先介绍了并发编程的基础概念和Python并发模型,然后深入讲解了线程编程的各个方面,如线程的创建、同步机制、局部存储、线程池的应用以及线程安全和性能调优。之后,转向进程编程,涵盖了进程的基本使用、进程间通信、多进程架构设计和性能监控。此外,还介绍了Python并发框架,如concurrent.futures、as
RS232_RS422_RS485总线规格及应用解析:基础知识介绍

# 摘要
本文详细探讨了RS232、RS422和RS485三种常见的串行通信总线技术,分析了各自的技术规格、应用场景以及优缺点。通过对RS232的电气特性、连接方式和局限性,RS422的信号传输能力与差分特性,以及RS485的多点通信和网络拓扑的详细解析,本文揭示了各总线技术在工业自动化、楼宇自动化和智能设备中的实际应用案例。最后,文章对三种总线技术进行了比较分析,并探讨了总线技术在5G通信和智能技术中的创新
【C-Minus词法分析器构建秘籍】:5步实现前端工程
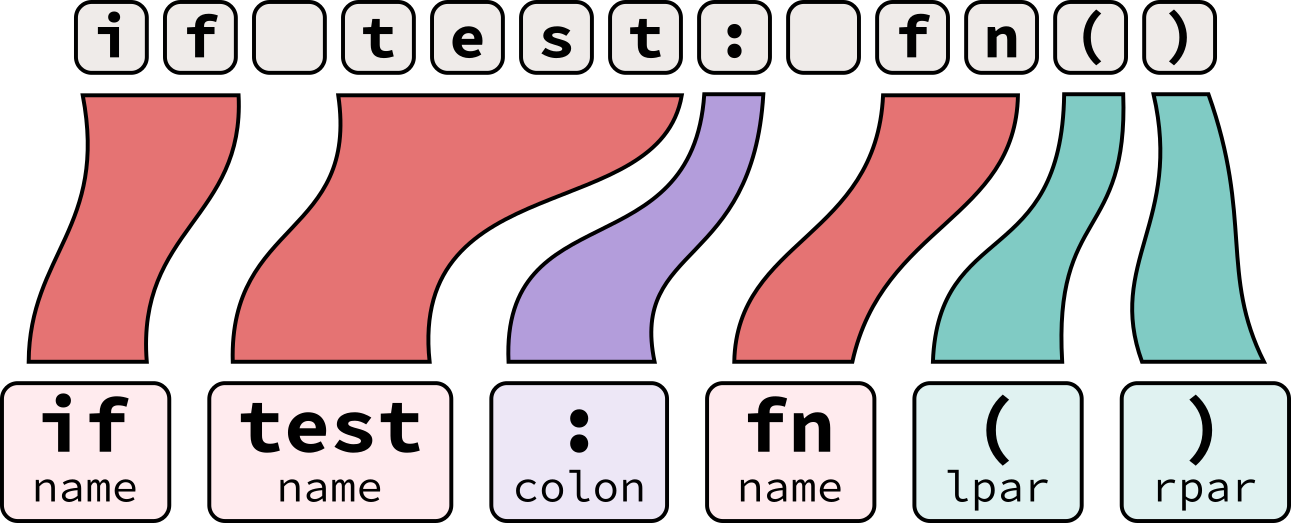
# 摘要
C-Minus词法分析器是编译器前端的关键组成部分,它将源代码文本转换成一系列的词法单元,为后续的语法分析奠定基础。本文从理论到实践,详细阐述了C-Minus词法分析器的概念、作用和工作原理,并对构建过程中的技术细节和挑战进行了深入探讨。我们分析了C-Minus语言的词法规则、利用正则表达式进行词法分析,并提供了实现C-Minus词法分析
【IBM X3850 X5故障排查宝典】:快速诊断与解决,保障系统稳定运行
# 摘要
本文全面介绍了IBM X3850 X5服务器的硬件构成、故障排查理论、硬件故障诊断技巧、软件与系统级故障排查、故障修复实战案例分析以及系统稳定性保障与维护策略。通过对关键硬件组件和性能指标的了解,阐述了服务器故障排查的理论框架和监控预防方法。此外,文章还提供了硬件故障诊断的具体技巧,包括电源、存储系统、内存和处理器问题处理方法,并对操作系统故障、网络通信故障以及应用层面问题进行了系统性的分析和故障追踪。通过实战案例的复盘,本文总结了故障排查的有效方法,并强调了系统优化、定期维护、持续监控以及故障预防的重要性,为确保企业级服务器的稳定运行提供了详细的技术指导和实用策略。
# 关键字
【TM1668芯片编程艺术】:从新手到高手的进阶之路
# 摘要
本文全面介绍了TM1668芯片的基础知识、编程理论、实践技巧、高级应用案例和编程进阶知识。首先概述了TM1668芯片的应用领域,随后深入探讨了其硬件接口、功能特性以及基础编程指令集。第二章详细论述了编程语言和开发环境的选择,为读者提供了实用的入门和进阶编程实践技巧。第三章通过多个应用项目,展示了如何将TM1668芯片应用于工业控制、智能家居和教育培训等领域。最后一章分析了芯片的高级编程技巧,讨论了性能扩展及未来的技术创新方向,同时指出编程资源与社区支持的重要性。
# 关键字
TM1668芯片;编程理论;实践技巧;应用案例;性能优化;社区支持
参考资源链接:[TM1668:全能LE
【Minitab案例研究】:解决实际数据集问题的专家策略
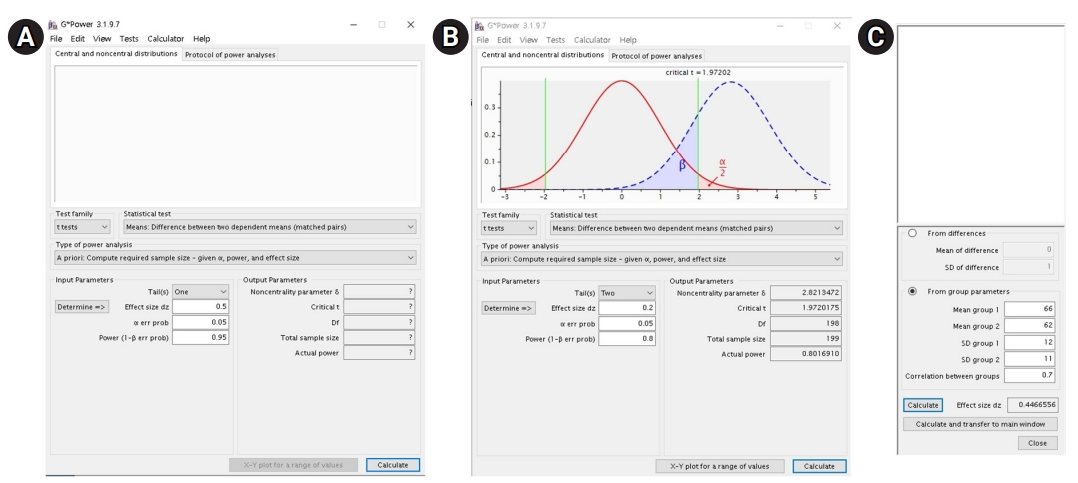
# 摘要
本文全面介绍了Minitab统计软件在数据分析中的应用,包括数据集基础、数据预处理、统计分析方法、高级数据分析技术、实验设计与优化策略,以及数据可视化工具的深入应用。文章首先概述了Minitab的基本功能和数据集的基础知识,接着详细阐述了数据清洗技巧、探索性数据分析、常用统计分析方法以及在Minitab中的具体实现。在高级数据分析技术部分,探讨了多元回归分析和时间序列分析,以及实际案例应用研究。此外,文章还涉及
跨平台开发新境界:MinGW-64与Unix工具的融合秘笈

# 摘要
本文全面探讨了MinGW-64与Unix工具的融合,以及如何利用这一技术进行高效的跨平台开发。文章首先概述了MinGW-64的基础知识和跨平台开发的概念,接着深入介绍了Unix工具在MinGW-64环境下的实践应用,包括移植常用Unix工具、编写跨平台脚本和进行跨平台编译与构建。文章还讨论了高级跨平台工具链配置、性能优化策略以及跨平台问题的诊断与解决方法。通过案例研究,
【单片机编程宝典】:手势识别代码优化的艺术
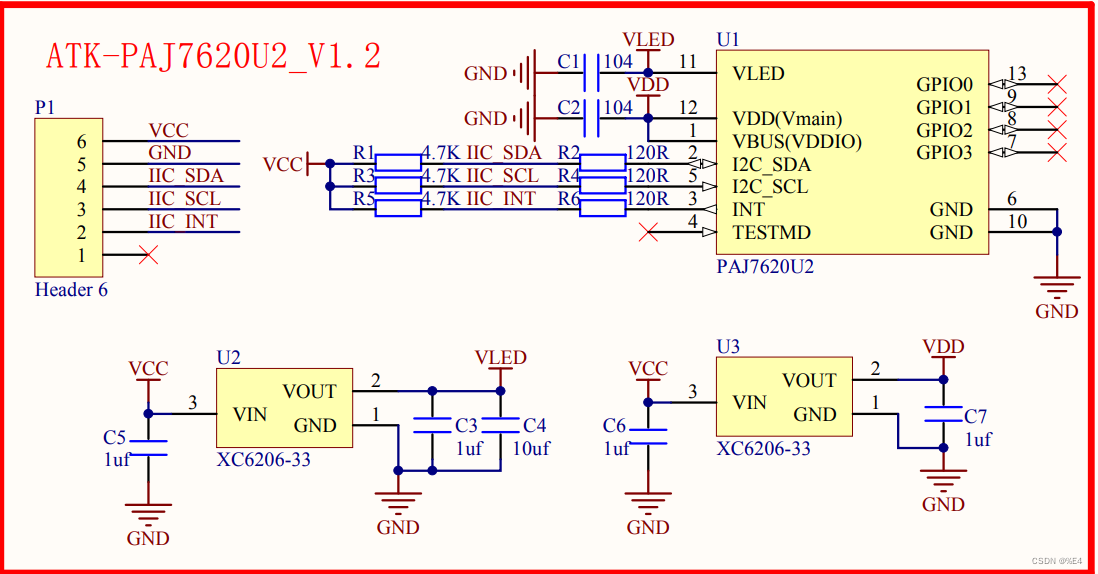
# 摘要
本文首先概述了手势识别技术的基本概念和应用,接着深入探讨了在单片机平台上的环境搭建和关键算法的实现。文中详细介绍了单片机的选择、开发环境的配置、硬件接口标准、手势信号的采集预处理、特征提取、模式识别技术以及实时性能优化策略。此外,本文还包含了手势识别系统的实践应用案例分析,并对成功案例进行了回顾和问题解决方案的讨论。最后,文章展望了未来手势识别技术的发展趋势,特别是机器学习的应用、多传感器数据融合技术以及新兴技术的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )