shared_ptr的使用场景与性能对比
发布时间: 2024-03-26 03:41:47 阅读量: 143 订阅数: 24 

基于freeRTOS和STM32F103x的手机远程控制浴室温度系统设计源码
# 1. 引言
在软件开发中,内存管理是一个至关重要的问题。为了避免内存泄漏和悬挂指针等问题,智能指针应运而生。在智能指针中,`shared_ptr`是被广泛应用的一种。本文将重点讨论`shared_ptr`的使用场景、内部实现机制、性能对比实验结果以及优化建议与最佳实践。通过深入探讨`shared_ptr`,帮助开发者更好地理解其工作原理,提高代码的质量和性能。
# 2. shared_ptr的使用场景
在实际的编程过程中,我们经常需要处理动态内存管理的情况,而智能指针便是一种方便且安全地管理内存的工具。其中,`shared_ptr`作为C++标准库中的智能指针之一,具有以下几个主要的使用场景:
1. **资源管理:** `shared_ptr`能够帮助我们自动管理动态内存的分配和释放,避免内存泄漏和野指针的问题。在一个资源需要在多个地方共享使用,且难以确定释放时机的情况下,使用`shared_ptr`能够很好地解决这类问题。
2. **循环引用:** 当对象之间存在循环引用关系时,如果使用裸指针很容易导致内存泄漏。而使用`shared_ptr`可以通过引用计数的方式很好地解决循环引用的问题,在最后一个引用退出作用域后能够自动释放内存。
3. **异常安全:** 在面对代码中存在异常抛出的情况时,使用`shared_ptr`能够帮助我们简化资源管理的复杂性,确保在发生异常时能够正确释放资源,防止资源泄漏。
4. **STL容器中的使用:** `shared_ptr`可被安全地存储在STL容器中,如`std::vector`、`std::map`等,使得在容器中传递和管理对象更加便捷。
总的来说,`shared_ptr`适用于需要在多个地方共享资源、解决循环引用问题、简化异常处理和与STL容器结合使用的场景中,能够提高代码的安全性和可维护性。
在实际编码中使用`shared_ptr`可以大大简化内存管理和加强资源的安全性,提高代码的可读性和可靠性。
# 3. shared_ptr的内部实现机制
在本章中,我们将深入探讨shared_ptr的内部数据结构和工作原理,以及分析shared_ptr如何管理内存和实现引用计数。
#### shared_ptr的内部数据结构
shared_ptr的内部数据结构通常包含两个部分:指向所管理对象的指针和指向引用计数的指针。具体结构可以简单描述如下:
```cpp
template <typename T>
class shared_ptr {
private:
T* ptr; // 指向所管理对象的指针
int* ref_count; // 指向引用计数的指针
};
```
在实际应用中,shared_ptr会通过模板类和动态内存分配来存储所管理的对象和引用计数。当有新的shared_ptr指向同一对象时,引用计数会增加,反之则减少。
#### shared_ptr的工作原理
- **构造函数**:在shared_ptr被创建时,会分配内存来存储指向对象的指针和引用计数。若没有其他shared_ptr指向同一对象,引用计数初始化为1;否则,引用计数递增。
- **拷贝构造函数**:当使用拷贝构造函数创建新的shared_ptr时,只会复制指向对象的指针,而引用计数会递增。
- **赋值运算符**:赋值运算符会递增右侧shared_ptr指向对象的引用计数,并递减左侧shared_ptr原本指向对象的引用计数。若引用计数减至0,则释放对象的内存并销毁引用计数。
- **析构函数**:在shared_ptr对象生命周期结束时,会递减引用计数。若引用计数减至0,则释放对象的内存。
通过合理地管理对象和引用计数,shared_ptr能够确保在没有任何指针指向对象时自动销毁对象,从而避免内存泄漏问题。
在下一章中,我们将设计实验方案对shared_ptr的性能进行对比分析,从而更全面地了解shared_ptr在实际应用中的表现。
# 4. 性能对比实验设计与结果分析
在本章中,我们将设计实验方案,比较shared_ptr与其他指针的性能表现,并进行详细的结果分析,以探讨shared_ptr在性能方面的优劣势。
### 1. 实验设计
#### 实验场景:比较shared_ptr、uniq

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了C++智能指针中的重要一员——shared_ptr。从基本概念入手,逐步剖析shared_ptr与unique_ptr的区别与选择,深入讲解make_shared和make_unique函数,探讨拷贝控制、自定义删除器、循环引用等问题,并探讨强弱指向、自定义内存分配器、STL容器应用等技巧。同时结合RAII编程思想、多维数组实现、继承关系与多态性质等方面展开讨论,还探讨了actived管理模式、lazy检测策略、线程安全使用等内容。此外,还比较了其在性能上的优势,以及move语义和智能指针池技术的实际应用。本专栏旨在帮助读者全面理解shared_ptr,并深入应用于实际项目中,提升代码质量和性能表现。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘STM32:如何用PWM精确控制WS2812LED亮度(专业速成课)

# 摘要
本文系统介绍了STM32微控制器基础,PWM信号与WS2812LED通信机制,以及实现PWM精确控制的技术细节。首先,探讨了PWM信号的理论基础和在微控制器中的实现方法,随后深入分析了WS2812LED的工作原理和与PWM信号的对接技术。文章进一步阐述了实现PWM精确控制的技术要点,包括STM32定时器配置、软件PWM的实现与优化以及硬件PWM的配置和
深入解构MULTIPROG软件架构:掌握软件设计五大核心原则的终极指南
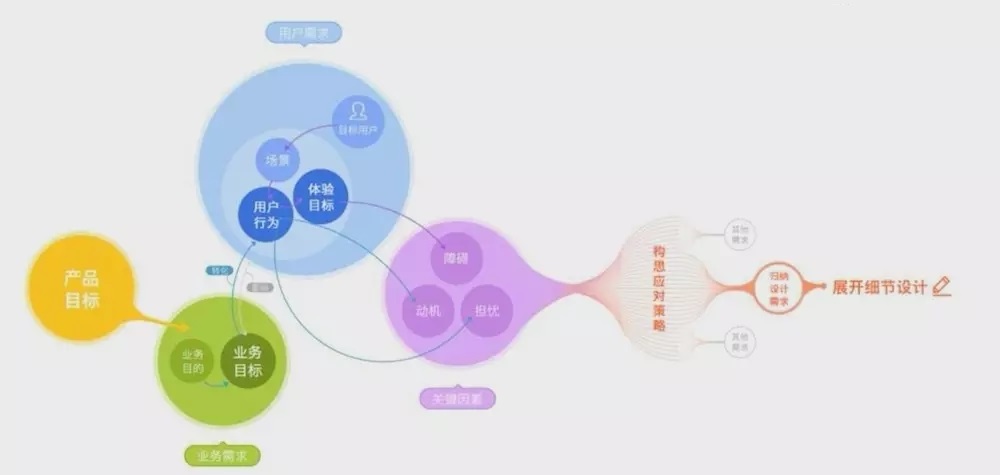
# 摘要
本文旨在探讨MULTIPROG软件架构的设计原则和模式应用,并通过实践案例分析,评估其在实际开发中的表现和优化策略。文章首先介绍了软件设计的五大核心原则——单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、接口隔离原则(ISP)、依赖倒置原则(DIP)——以及它们在MULTIPROG架构中的具体应用。随后,本文深入分析了创建型、结构型和行为型设计模式在
【天清IPS问题快速诊断手册】:一步到位解决配置难题
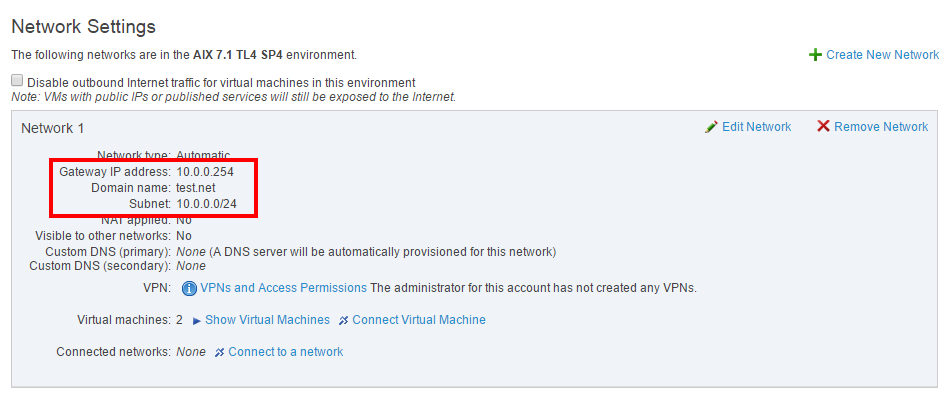
# 摘要
本文全面介绍了天清IPS系统,从基础配置到高级技巧,再到故障排除与维护。首先概述了IPS系统的基本概念和配置基础,重点解析了用户界面布局、网络参数配置、安全策略设置及审计日志配置。之后,深入探讨了高级配置技巧,包括网络环境设置、安全策略定制、性能调优与优化等。此外,本文还提供了详细的故障诊断流程、定期维护措施以及安全性强化方法。最后,通过实际部署案例分析、模拟攻击场景演练及系统升级与迁移实
薪酬增长趋势预测:2024-2025年度人力资源市场深度分析

# 摘要
本论文旨在探讨薪酬增长的市场趋势,通过分析人力资源市场理论、经济因素、劳动力供需关系,并结合传统和现代数据分析方法对薪酬进行预
【Linux文件格式转换秘籍】:只需5步,轻松实现xlsx到txt的高效转换

# 摘要
本文全面探讨了Linux环境下文件格式转换的技术与实践,从理论基础到具体操作,再到高级技巧和最佳维护实践进行了详尽的论述。首先介绍了文件格式转换的概念、分类以及转换工具。随后,重点介绍了xlsx到txt格式转换的具体步骤,包括命令行、脚本语言和图形界面工具的使用。文章还涉及了转换过程中的高级技
QEMU-Q35芯片组存储管理:如何优化虚拟磁盘性能以支撑大规模应用
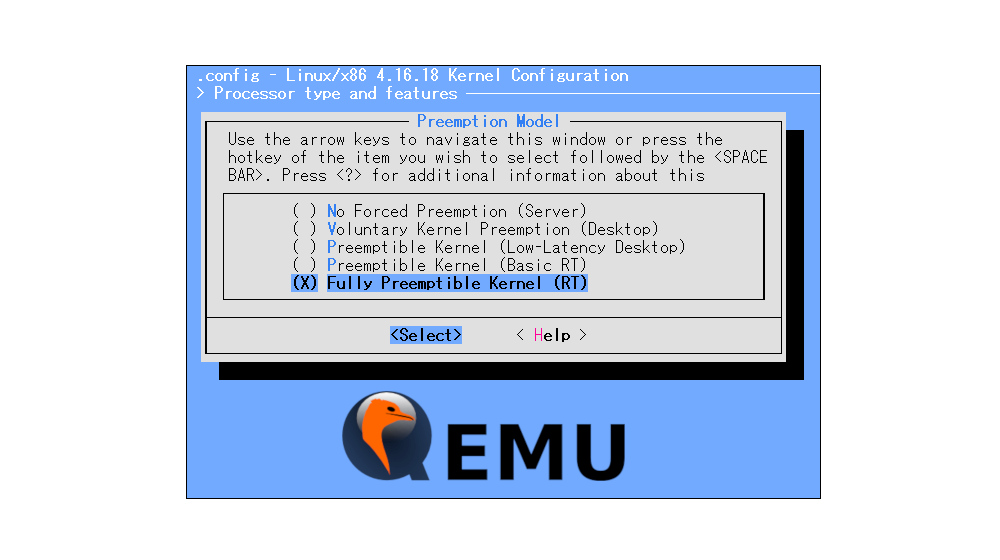
# 摘要
本文详细探讨了QEMU-Q35芯片组在虚拟化环境中的存储管理及性能优化。首先,介绍了QEMU-Q35芯片组的存储架构和虚拟磁盘性能影响因素,深入解析了存储管理机制和性能优化理论。接着,通过实践技巧部分,具体阐述了虚拟磁盘性能优化方法,并提供了配置优化、存储后端优化和QEMU-Q35特性应用的实际案例。案例研究章节分析了大规模应用环境下的虚拟磁盘性能支撑,并展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )