xhammer数据库数据建模技巧:设计高效且可扩展的数据模型:5种数据建模方法
发布时间: 2024-07-04 15:56:34 阅读量: 92 订阅数: 28 

数据仓库维度建模实践-模型设计-网易03.pdf
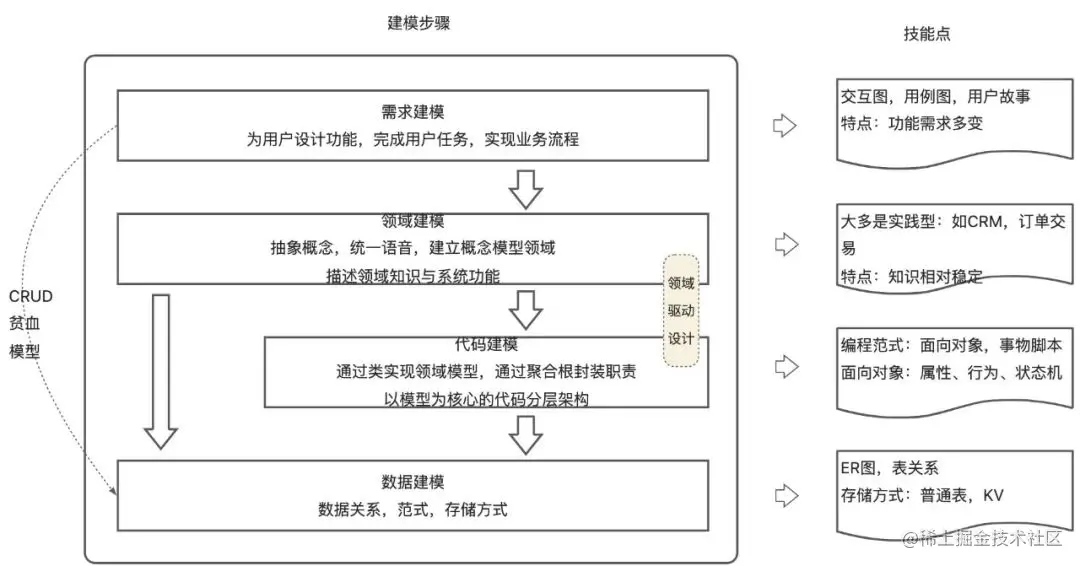
# 1. 数据建模概述**
数据建模是将现实世界中的业务实体、属性和关系抽象成数据结构的过程。它为数据管理和分析提供了一个蓝图,确保数据的一致性、完整性和可用性。
数据建模涉及识别业务需求、分析数据源、定义数据实体和关系,并创建逻辑和物理数据模型。通过建立一个准确且可扩展的数据模型,组织可以有效地存储、管理和利用数据,以支持业务决策和运营。
# 2.1 实体关系模型(ERM)
### 2.1.1 ERM的基本概念和符号
实体关系模型(ERM)是一种数据建模方法,用于表示现实世界中的实体、属性和关系。它使用图形符号来表示这些概念,从而创建易于理解和可视化的数据模型。
**基本概念:**
* **实体:**现实世界中可独立存在的对象,例如客户、产品或订单。
* **属性:**描述实体特征的特性,例如客户的姓名、产品的价格或订单的日期。
* **关系:**实体之间建立的关联,例如客户与订单之间的关系。
**符号:**
* **矩形:**表示实体。
* **椭圆形:**表示属性。
* **菱形:**表示关系。
* **连线:**连接实体和关系,表示实体之间的关系。
### 2.1.2 ERM的建模步骤
ERM的建模步骤包括:
1. **识别实体:**确定需要在模型中表示的现实世界对象。
2. **定义属性:**为每个实体识别和定义其特征。
3. **建立关系:**确定实体之间的关联并创建相应的菱形。
4. **指定基数:**指定每个关系中实体之间的数量限制(例如,一对一、一对多或多对多)。
5. **添加约束:**指定对属性和关系的附加规则,例如主键、外键和参照完整性。
**示例:**
以下是一个简单的 ERM,表示客户、订单和产品之间的关系:
```mermaid
erDiagram
CUSTOMER ||--o{ ORDER }
ORDER ||--o{ PRODUCT }
```
在这个模型中:
* **CUSTOMER**和**PRODUCT**是实体。
* **NAME**、**ADDRESS**和**PHONE**是**CUSTOMER**的属性。
* **PRODUCT_ID**、**NAME**和**PRICE**是**PRODUCT**的属性。
* **ORDER_ID**、**CUSTOMER_ID**和**PRODUCT_ID**是**ORDER**的属性。
* **CUSTOMER**和**ORDER**之间是一对多的关系。
* **ORDER**和**PRODUCT**之间是一对多的关系。
# 3.1 数据收集和分析
**3.1.1 需求收集和业务分析**
数据建模的起点是需求收集和业务分析。通过与业务人员和利益相关者沟通,了解业务目标、数据需求和数据使用场景。需求收集可以采用访谈、问卷调查或研讨会等方式进行。
业务分析是将业务需求转化为数据模型需求的过程。分析师需要识别业务实体、属性和关系,并确定数据模型的范围和粒度。业务分析可以采用用例分析、流程图或业务规则建模等方法。
**3.1.2 数据源的整理和清洗**
数据收集后,需要对数据源进行整理和清洗。整理包括将数据从不同来源整合到统一的格式,并去除重复和不一致的数据。清洗包括识别和纠正数据中的错误、缺失值和异常值。
数据整理和清洗可以使用数据集成工具或手工处理。数据集成工具可以自动化数据提取、转换和加载(ETL)过程,提高效率和准确性。手工处理适合于数据量较小或数据结构简单的场景。
**代码块 1:数据清洗示例**
```python
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 去除重复行
df = df.drop_duplicates()
# 填充缺失值
df['age'].fillna(df['age'].mean(), inplace=True)
# 纠正数据类型
df['gender'] = df['gender'].astype('category')
```
**逻辑分析:**
代码块 1 展示了使用 Pandas 库进行数据清洗的示例。首先读取数据到 DataFrame,然后去除重复行、填充缺失值并纠正数据类型。这些操作可以确保数据的一致性和完整性。
**参数说明:**
* `df.drop_duplicates()`:去除重复行,返回一个新的 DataFrame。
* `df['age'].fillna(df['age'].mean(), inplace=True)`:用平均值填充缺失值,并直接修改 DataFrame。
* `df['gender'] = df['gender'].astype('category')`:将性别列转换为类别类型。
# 4. 数据关系建模**
**4.1 关系类型和约束**
数据关系建模是数据建模的核心,它定义了数据实体之间的联系和约束。常见的数据库关系类型包括:
- **一对一(1:1)关系:**两个实体之间存在一对一的对应关系,例如,每个学生对应一个唯一的学生证号。
- **一对多(1:N)关系:**一个实体与多个实体相关联,例如,一个部门可以有多个员工。
- **多对多(N:M)关系:**多个实体与多个实体相关联,例如,多个学生可以参加多个课程。
为了确保数据的一致性和完整性,数据模型中需要定义约束:
- **主键:**唯一标识实体的属性,例如,学生证号。
- **外键:**引用另一个实体主键的属性,例如,员工表的部门ID。
- **参照完整性:**确保外键值始终引用有效的主键值,防止数据不一致。
**4.1.1 代码示例:一对多关系**
```sql
CREATE TABLE Department (
DeptID INT PRIMARY KEY,
DeptName VARCHAR(50) NOT NULL
);
CREATE TABLE Employee (
EmpID INT PRIMARY KEY,
EmpName VARCHAR(50) NOT NULL,
DeptID INT REFERENCES Department(DeptID)
);
```
**逻辑分析:**
- `Department`表包含部门信息,`DeptID`为主键。
- `Employee`表包含员工信息,`EmpID`为主键,`DeptID`为外键,引用`Department`表的`DeptID`。
- 参照完整性约束确保每个员工的`DeptID`都对应于一个有效的部门。
**4.2 数据归一化和反规范化**
数据归一化是一种将数据分解成多个表的过程,以消除冗余和确保数据一致性。归一化的程度分为以下几个级别:
- **第一范式(1NF):**每个属性都不可再分。
- **第二范式(2NF):**所有非主键属性都完全依赖于主键。
- **第三范式(3NF):**所有非主键属性都不依赖于其他非主键属性。
反规范化是将数据重新组合到一个表中的过程,以提高查询性能。它通常用于数据仓库和联机分析处理(OLAP)系统中。
**4.2.1 代码示例:数据归一化**
**未归一化表:**
```sql
CREATE TABLE Student (
StudentID INT PRIMARY KEY,
StudentName VARCHAR(50) NOT NULL,
Address VARCHAR(100) NOT NULL,
Phone VARCHAR(20) NOT NULL,
Email VARCHAR(50) NOT NULL
);
```
**归一化表:**
```sql
CREATE TABLE Student (
StudentID INT PRIMARY KEY,
StudentName VARCHAR(50) NOT NULL
);
CREATE TABLE Contact (
ContactID INT PRIMARY KEY,
StudentID INT REFERENCES Student(StudentID),
Address VARCHAR(100) NOT NULL,
Phone VARCHAR(20) NOT NULL,
Email VARCHAR(50) NOT NULL
);
```
**逻辑分析:**
- 未归一化表中,`Address`、`Phone`和`Email`属性都依赖于主键`StudentID`。
- 归一化后,将这些属性移到`Contact`表中,以消除冗余并提高数据一致性。
**4.2.2 反规范化示例:星型模式**
星型模式是一种维度建模技术,它将事实表与多个维度表连接起来。事实表包含度量值,而维度表包含维度属性。反规范化可以将维度属性复制到事实表中,以提高查询性能。
**Mermaid流程图:星型模式**
```mermaid
graph LR
subgraph 事实表
A[事实表]
end
subgraph 维度表
B[维度1]
C[维度2]
D[维度3]
end
A --> B
A --> C
A --> D
```
# 5. 数据模型优化
### 5.1 性能优化
#### 5.1.1 索引和分区的使用
**索引**
索引是数据库中一种特殊的数据结构,用于快速查找数据。通过在数据表中创建索引,可以大大提高查询效率。
**分区**
分区是一种将大型数据表划分为更小部分的技术。通过对数据表进行分区,可以提高查询效率,因为数据库只需要扫描相关分区即可。
**代码块:**
```sql
-- 创建索引
CREATE INDEX idx_name ON table_name (column_name);
-- 创建分区
CREATE TABLE table_name (
column_name1,
column_name2,
column_name3
)
PARTITION BY RANGE (column_name1) (
PARTITION p1 VALUES LESS THAN (100),
PARTITION p2 VALUES LESS THAN (200),
PARTITION p3 VALUES LESS THAN (300)
);
```
**逻辑分析:**
* 创建索引时,指定了索引名称、表名和索引列。
* 创建分区时,指定了分区表名、分区列,以及每个分区的值范围。
#### 5.1.2 查询优化技巧
**避免全表扫描**
全表扫描是数据库中最慢的操作之一。通过使用索引或分区,可以避免全表扫描,从而提高查询效率。
**使用适当的连接类型**
不同的连接类型(例如,INNER JOIN、LEFT JOIN、RIGHT JOIN)会产生不同的结果。选择适当的连接类型可以优化查询性能。
**代码块:**
```sql
-- 使用索引避免全表扫描
SELECT * FROM table_name
WHERE column_name = 'value'
INDEX (column_name);
-- 使用适当的连接类型
SELECT *
FROM table1
INNER JOIN table2
ON table1.id = table2.id;
```
**逻辑分析:**
* 在第一个查询中,使用了索引避免全表扫描。
* 在第二个查询中,使用了INNER JOIN连接类型,只返回两个表中具有匹配行的结果。
### 5.2 可扩展性优化
#### 5.2.1 数据模型的模块化设计
模块化设计将数据模型分解为多个独立的模块。每个模块代表一个特定的业务领域或功能。这种设计提高了数据模型的可扩展性,因为可以轻松添加或删除模块。
**代码块:**
```sql
-- 创建模块化数据模型
CREATE SCHEMA module1;
CREATE TABLE module1.table1 (
column_name1,
column_name2
);
CREATE SCHEMA module2;
CREATE TABLE module2.table2 (
column_name1,
column_name2
);
```
**逻辑分析:**
* 创建了两个模式,module1和module2,用于将数据模型模块化。
* 每个模式包含一个表,用于存储特定业务领域或功能的数据。
#### 5.2.2 数据模型的版本控制
数据模型版本控制允许跟踪数据模型的更改,并轻松回滚到以前的版本。这对于确保数据模型的可扩展性和可靠性至关重要。
**代码块:**
```sql
-- 使用版本控制系统管理数据模型
CREATE TABLE table_name (
column_name1,
column_name2
)
VERSION AS OF TIMESTAMP '2023-01-01 00:00:00';
```
**逻辑分析:**
* 使用VERSION子句指定数据模型的版本。
* 可以使用TIMESTAMP子句指定特定的版本时间戳。
# 6. 数据模型文档和维护
### 6.1 数据模型文档
数据模型文档是记录和传达数据模型信息的正式文件。它对于确保数据模型的理解、维护和使用至关重要。数据模型文档通常包括以下内容:
- **数据模型图和说明:**使用ERD或其他建模符号来可视化表示数据模型。
- **数据字典和元数据管理:**提供有关数据模型中实体、属性和关系的详细元数据信息。
### 6.2 数据模型维护
数据模型是一个不断发展的实体,随着业务需求和技术的变化而需要维护。数据模型维护涉及以下活动:
- **数据模型的变更管理:**记录和管理对数据模型的更改,包括更改的理由、影响和实施步骤。
- **数据模型的版本更新:**定期更新数据模型以反映更改,并确保所有用户使用最新的版本。
**代码块示例:**
```sql
-- 创建数据字典表
CREATE TABLE data_dictionary (
entity_name VARCHAR(255) NOT NULL,
attribute_name VARCHAR(255) NOT NULL,
data_type VARCHAR(50) NOT NULL,
description VARCHAR(255)
);
-- 插入数据字典记录
INSERT INTO data_dictionary (entity_name, attribute_name, data_type, description)
VALUES
('customer', 'customer_id', 'INT', '客户唯一标识符'),
('customer', 'name', 'VARCHAR(255)', '客户姓名'),
('order', 'order_id', 'INT', '订单唯一标识符'),
('order', 'customer_id', 'INT', '客户标识符'),
('order', 'product_id', 'INT', '产品标识符'),
('order', 'quantity', 'INT', '订单数量'),
('product', 'product_id', 'INT', '产品唯一标识符'),
('product', 'name', 'VARCHAR(255)', '产品名称'),
('product', 'price', 'DECIMAL(10, 2)', '产品价格');
```
**表格示例:**
| **实体** | **属性** | **数据类型** | **描述** |
|---|---|---|---|
| Customer | customer_id | INT | 客户唯一标识符 |
| Customer | name | VARCHAR(255) | 客户姓名 |
| Order | order_id | INT | 订单唯一标识符 |
| Order | customer_id | INT | 客户标识符 |
| Order | product_id | INT | 产品标识符 |
| Order | quantity | INT | 订单数量 |
| Product | product_id | INT | 产品唯一标识符 |
| Product | name | VARCHAR(255) | 产品名称 |
| Product | price | DECIMAL(10, 2) | 产品价格 |
**mermaid流程图示例:**
```mermaid
graph LR
subgraph 数据模型维护流程
A[变更请求] --> B[变更评估]
B --> C[变更批准]
C --> D[变更实施]
D --> E[变更验证]
E --> F[变更发布]
end
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**xhammer 数据库专栏**
xhammer 数据库专栏汇集了数据库性能优化、死锁分析、索引失效、表锁问题、事务隔离级别、备份与恢复、高可用架构、分库分表、监控与告警、性能调优、查询优化、事务管理、并发控制、日志分析、安全最佳实践、迁移实战、数据建模、性能测试和运维最佳实践等方面的内容。
本专栏旨在帮助数据库管理员和开发人员深入了解 xhammer 数据库的特性、原理和最佳实践,从而提升数据库性能、解决常见问题并确保数据库的稳定可靠运行。通过阅读本专栏的文章,读者可以掌握各种数据库优化技术,提高数据库效率,并为构建高性能、高可用和可扩展的数据库系统奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
IT8390下载板固件升级秘籍:升级理由与步骤全解析

# 摘要
固件升级是确保设备稳定运行和性能提升的关键步骤。本文首先阐述了固件升级的必要性和优势,然后介绍了固件的定义、作用以及升级原理,并探讨了升级过程中的风险和防范措施。在此基础上,详细介绍了IT8390下载板固件升级的具体步骤,包括准备工作、升级流程和升级后的验证。通过案例分析与经验分享,本文展示了固件升级成功的策略和解决困难的技巧。最后,本文探讨了固件升级后的性能优化
【双输入单输出模糊控制器案例研究】:揭秘工业控制中的智能应用

# 摘要
双输入单输出(SISO)模糊控制器是工业控制领域中广泛应用的一种智能控制策略。本文首先概述了SISO模糊控制器的基本概念和设计原理,详细介绍了其理论基础、控制系统设计以及
【APK资源优化】:图片、音频与视频文件的优化最佳实践
# 摘要
随着移动应用的普及,APK资源优化成为提升用户体验和应用性能的关键。本文概述了APK资源优化的重要性,并深入探讨了图片、音频和视频文件的优化技术。文章分析了不同媒体格式的特点,提出了尺寸和分辨率管理的最佳实践,以及压缩和加载策略。此外,本文介绍了高效资源优
【51单片机数字时钟设计】:从零基础到精通,打造个性化时钟

# 摘要
本文介绍了51单片机在数字时钟项目中的应用,从基础概念出发,详细阐述了单片机的硬件结构、开发环境搭建、程序设计基础以及数字时钟的理论与设计。在实践操作方面,作者重点介绍了显示模块的编程实现、时间设置与调整功能以及额外功能的集成与优化。进一步,文章探讨了数字时钟的高级应用,包括远程时间同步技术、多功能集成与用户定制化,以及项目总结与未来展望。通过本文,读者能够理解51单片机在数字
EMC CX存储硬盘故障速查手册:快速定位与解决之道

# 摘要
本文针对EMC CX存储硬盘故障进行了全面的概述,涵盖了故障诊断理论基础、故障快速定位方法、故障解决策略以及预防措施与最佳实践。通过对存储系统架构和硬盘在其中的作用进行深入分析,本文详细介绍了故障诊断流程和常见硬盘故障原因,并
ISAPI性能革命:5个实用技巧,让你的应用跑得飞快!
# 摘要
随着网络服务的日益普及,ISAPI作为服务器端应用程序接口技术,在Web开发中扮演着重要角色。本文首先介绍了ISAPI的基础知识和面临的性能挑战,然后详细探讨了ISAPI设计优化的技巧,包括请求处理、缓存策略和并发管理等方面。在ISAPI开发实践部分,本文提供了代码优化、SQL语句优化和异常处理与日志记录的实用技巧。随后,文章深入分析了通过模块化设计、网络优化技术和异步处理来实现高级性能提
报表自动化:DirectExcel的角色与实践策略

# 摘要
报表自动化是提升工作效率和数据管理质量的关键,DirectExcel作为一种先进的报表工具,提供了从基础数据处理到高级功能集成的全方位解决方案。本文系统阐述了DirectExcel的核心功能与配置,包括其定位、优势、数据处理机制、与传统报表工具的对比分析以及安全性与权限控制。通
网络编程高手教程:彻底解决W5200_W5500 TCP连接中断之谜

# 摘要
本文系统地介绍了网络编程与TCP/IP协议的基础知识,并对W5200和W5500网络控制芯片进行了深入的技术分析和驱动安装指导。通过对TCP连接管理的详细讨论,包括连接的建立、维护和中断分析,本文提供了针对W5200/W5500在网络中断问题上的实战演练和解决方案。最后,本文探讨了进阶网络编程技巧,
【驱动管理优化指南】:3大步骤确保打印设备兼容性和性能最大化
# 摘要
本文全面探讨了驱动管理优化的基础知识、实践操作和未来趋势。第一章介绍了驱动管理优化的基础知识,第二章和第三章分别详述了打印设备驱动的识别、安装、更新、兼容性测试以及性能评估。第四章讨论了驱动性能调优的理论与技巧,第五章则提供了故障排除和维护策略。最后,第六章展望了驱动管理优化的未来趋势,包括与云服务的结合、人工智能的应用以及可持续发展策略。通过理论与实践相结合的方式,本文旨在为提升打印设备驱动管理效率和性能提供指导。
# 关键字
DSP28335数字信号处理:优化算法,性能提升的3大技巧
# 摘要
本文系统地探讨了基于DSP28335处理器的性能优化方法,涵盖了从理解处理器架构到系统级性能提升策略的各个方面。文章首先介绍了DSP28335的架构和性能潜力,随后深入讨论了算法优化基础,包括CPU与外设交互、内存管理、算法复杂度评估和效率提升。接着,文章在代码级性能优化部分详细阐述了汇编语言及C语言在DSP上的使用技巧和编译器优化选项。第四章着眼于系统级性能提升策略,包括实时操作系统的任务调度、多核并行处理以及外设管理。文章还介绍了性能测试与评估的方法,并通过具体案例分析展示了优化策略在实际应用中的效果。最终,文章对未来的优化方向和新技术的融合进行了展望。
# 关键字
DSP28
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )