VMware性能监控告警机制:构建自动化响应系统的实战攻略
发布时间: 2024-12-09 23:13:32 阅读量: 13 订阅数: 17 

VMware vSphere:vSphere自动化与脚本编写
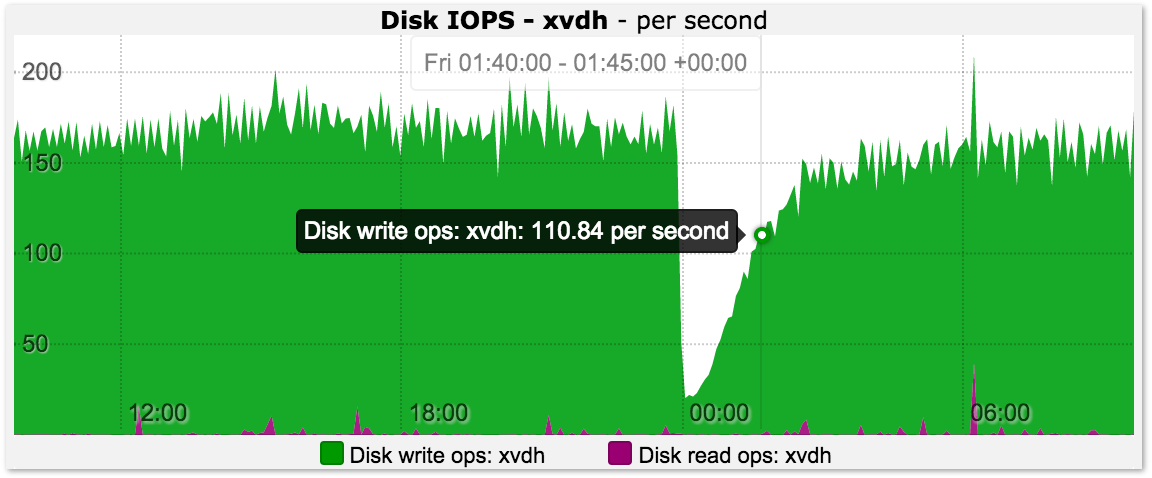
# 1. VMware性能监控告警机制概述
## 简介
在现代IT基础设施中,VMware作为虚拟化技术的领头羊,其性能监控与告警机制对于保障业务连续性和系统稳定性至关重要。监控告警机制能够实时反映虚拟环境的健康状况,并在问题发生时及时发出告警,从而最大限度地减少停机时间和服务中断。
## 性能监控与告警的重要性
在动态且复杂的虚拟化环境中,性能监控确保了系统资源的合理分配和高效利用。通过连续的性能数据分析,管理员能够识别潜在的性能瓶颈和异常行为,实现主动管理和故障预防。告警机制是性能监控的延伸,它在预设的性能阈值被触发时,通过多种通知方式提醒管理员,确保快速响应和问题解决。
## 告警机制的组成
告警机制通常包括告警规则的设定、告警消息的传递以及最终的响应处理。规则设定决定了什么情况下会触发告警,消息传递则涉及通知的方式,例如电子邮件、短信、即时通讯工具等。响应处理则包括手动和自动两种,自动响应通常依赖于预先定义的脚本和流程,以快速修正问题或减轻影响。在后续章节中,我们将详细探讨如何构建和优化VMware环境中的监控告警系统。
# 2. 性能监控的基础理论与方法
### 2.1 VMware性能监控概念解析
#### 2.1.1 性能监控的目的和重要性
在虚拟化环境下,性能监控是确保数据中心稳定运行的关键。通过对物理资源和虚拟资源的性能监控,管理员可以及时了解系统运行状态,预测潜在问题,避免或减少系统故障对业务的影响。性能监控的目的是实现资源的高效使用、保障服务质量和满足合规要求。
具体来说,性能监控可以帮助管理员执行以下任务:
- **资源分配**:合理分配资源,确保高优先级应用获得必要的资源。
- **性能瓶颈识别**:快速定位性能瓶颈,及时采取措施解决。
- **容量规划**:通过历史性能数据进行分析,为未来的资源需求做规划。
- **成本控制**:避免资源浪费,优化成本效率。
- **合规性报告**:提供必要的性能数据,以满足外部审计和合规要求。
性能监控的重要性体现在其对数据中心运营的全面影响上。它不仅影响到单个系统的稳定性,还直接关联到企业业务的连续性和竞争力。
#### 2.1.2 VMware性能计数器和监控指标
VMware vSphere提供了一套丰富的性能计数器,用于衡量虚拟化环境中的各项指标。这些指标包括但不限于CPU、内存、磁盘和网络的性能数据。性能计数器是监控系统的核心组件,它们帮助管理员了解虚拟机和主机的运行状态。
下面是一些关键的VMware性能计数器示例:
- **CPU使用率**:衡量CPU的繁忙程度。
- **内存使用率**:监控物理和虚拟内存的使用情况。
- **存储I/O**:监控虚拟机和主机存储I/O操作的性能。
- **网络吞吐量**:衡量通过网络传输的数据量。
### 2.2 性能数据收集技术
#### 2.2.1 使用vSphere API进行数据收集
vSphere API为开发者提供了一种访问和管理vSphere环境的方法。通过vSphere API,可以编写脚本来自动化性能数据的收集过程。以下是使用vSphere API收集性能数据的基本步骤:
1. **认证与连接**:使用vSphere API与vCenter或ESXi主机建立连接。
2. **查询性能计数器**:获取系统支持的性能计数器列表。
3. **配置数据收集**:设置数据收集的起止时间和频率。
4. **数据读取**:按需读取和处理性能数据。
5. **数据存储与报告**:将收集的数据存储到数据库,并生成报告。
一个简单的vSphere API调用示例代码块如下:
```python
from pyVim.connect import SmartConnect, Disconnect
from pyVmomi import vim
server = 'vcenter_server_address'
user = 'username'
password = 'password'
vim_type = 'vcenter_server' # Or 'esxi_host'
# Connect and log in to the server
si = SmartConnect(host=server, user=user, pwd=password, vimtype=vim_type)
# Get the content
content = si.RetrieveContent()
# List all virtual machines on the server
vmMorList = content.virtualMachine
for vmMor in vmMorList:
print(vmMor.name)
# Disconnect from server
Disconnect(si)
```
#### 2.2.2 集成第三方监控工具
除了使用vSphere API手动编写脚本外,许多第三方监控工具(如vRealize Operations Manager)提供了强大的数据收集和分析功能,可以自动化性能监控的过程。这些工具通常带有易于使用的图形界面,并且已经内置了许多性能监控和分析的逻辑,极大地简化了管理员的工作。
第三方监控工具的集成步骤通常包括:
1. **安装和配置**:在监控系统上安装第三方监控工具,并配置其与vCenter或ESXi主机的连接。
2. **设置监控模板**:定义监控参数、阈值和告警策略。
3. **性能数据收集**:监控工具开始收集性能数据,并将结果存储在内置数据库中。
4. **数据展示和分析**:通过图形界面展示性能数据,进行趋势分析和预测。
5. **告警和通知**:当检测到阈值违规时,自动触发告警和通知。
### 2.3 性能分析与瓶颈诊断
#### 2.3.1 性能数据的解读和分析方法
性能数据解读是性能监控中一项重要的技能。分析性能数据时,需要关注以下几点:
- **趋势分析**:对历史数据进行比较,观察资源使用量的变化趋势。
- **基线比较**:与性能基线对比,确定是否超出正常范围。
- **相关性分析**:关联不同资源的使用情况,理解它们之间的相互影响。
- **根因分析**:深入挖掘问题的根源,而不是仅仅解决表面现象。
为实现这些分析,可以使用统计和分析工具,如图表、热图和数据可视化等方法。
下面是一个使用Python的pandas库进行性能数据趋势分析的示例代码块:
```python
import pandas as pd
# 假设有一个性能数据的CSV文件
data = pd.read_csv('performance_data.csv')
# 对数据按时间序列进行排序
data.sort_values('timestamp', inplace=True)
# 计算CPU使用率的移动平均值来平滑短期波动
data['cpu_moving_avg'] = data['cpu_usage'].rolling(window=3).mean()
# 绘制图表展示趋势
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 5))
plt.plot(data['timestamp'], data['cpu_moving_avg'], label='CPU Usage Trend')
plt.title('CPU Usage Trend Over Time')
plt.xlabel('Time')
plt.ylabel('CPU Usage (%)')
plt.legend()
plt.show()
```
#### 2.3.2 常见性能瓶颈案例分析
在虚拟化环境中,性能瓶颈可以出现在多个层面,包括CPU、内存、存储和网络。以下是一些常见的性能瓶颈案例分析:
- **CPU资源竞争**:当多个虚拟机争夺有限的CPU资源时,可能导致所有虚拟机的性能下降。通过合理配置资源分配策略和优先级,可以缓解这一问题。
- **内存不足**:虚拟机内存不足可能导致大量的磁盘交换,影响虚拟机性能。通过配置内存预留、增加主机内存或调整虚拟机内存分配策略,可以解决内存瓶颈。
- **存储I/O延迟**:存储系统的响应时间直接影响到虚拟机的性能。针对存储性能问题,可能需要优化存储配置、升级存储设备或优化存储网络。
- **网络拥塞**:网络带宽不足或配置问题可能导致数据传输延迟。通过网络优化和流量管理,可以减少网络瓶颈。
通过案例分析,管理员可以积累经验,快速定位并解决实际问题。
# 3. 告警机制的构建与实践
告警机制是性能监控中的关键组成部分,它能够在系统性能下降或出现问题时及时通知管理员进行干预,是维护系统稳定运行的重要保障。构建有效的告警机制需要考虑多个方面,包括告警规则的设定、通知方

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 VMware 监控和性能分析工具,为用户提供了全面的指南,帮助他们建立高效的监控体系,优化云环境性能,解决虚拟机资源问题,并构建自动化响应系统。专栏还涵盖了高级监控技巧、I/O 性能监控和调优、自定义报告和数据分析,以及故障排除技术。通过深入的案例分析和实战攻略,用户可以掌握 VMware 监控工具的专业应用,提升虚拟化环境的性能和稳定性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【USB2.0数据传输加速】:从原理到应用的深度剖析

参考资源链接:[USB2.0协议中文详解:结构、数据流与电气规范](https://wenku.csdn.net/doc/2mpprnjccu?spm=1055.2635.3001.10343)
# 1. USB2.0技术概述
USB2.0作为一项广泛应
【短信服务用户行为分析】:用数据驱动的策略优化营销
参考资源链接:[SMS网格生成实战教程:岸线处理与ADCIRC边界调整](https://wenku.csdn.net/doc/566peujjyr?spm=1055.2635.3001.10343)
# 1. 短信服务用户行为分析概述
在当今信息爆炸的时代,短信作为快速直达的通信方式,在营销中占据着举足轻重的地位。**用户行为分析**对于
HyperMesh网格质量优化:从入门到进阶的实用技巧
参考资源链接:[Hypermesh网格划分教程:从几何建模到3D网格生成](https://wenku.csdn.net/doc/1feyo6tkwb?spm=1055.2635.3001.10343)
# 1. HyperMesh网格质量优化概述
在本章中,我们将对HyperMesh的网格质量优化进行初步的介绍。HyperMesh是一款强大的有限元
零停机迁移:VMware虚拟机迁移的高级技术与实践

参考资源链接:[VMware产品详解:Workstation、Server、GSX、ESX和Player对比](https://wenku.csdn.net/doc/6493fbba9aecc961cb34d21f?spm=1055.2635.3001.10343)
# 1. 虚拟化技术概述与零停机迁移的重要性
在当今IT行业,随着业务的快速发展和技术的不断演进,企业的数据中心面临着前所未有的
Marc基础操作教程:一步一个脚印
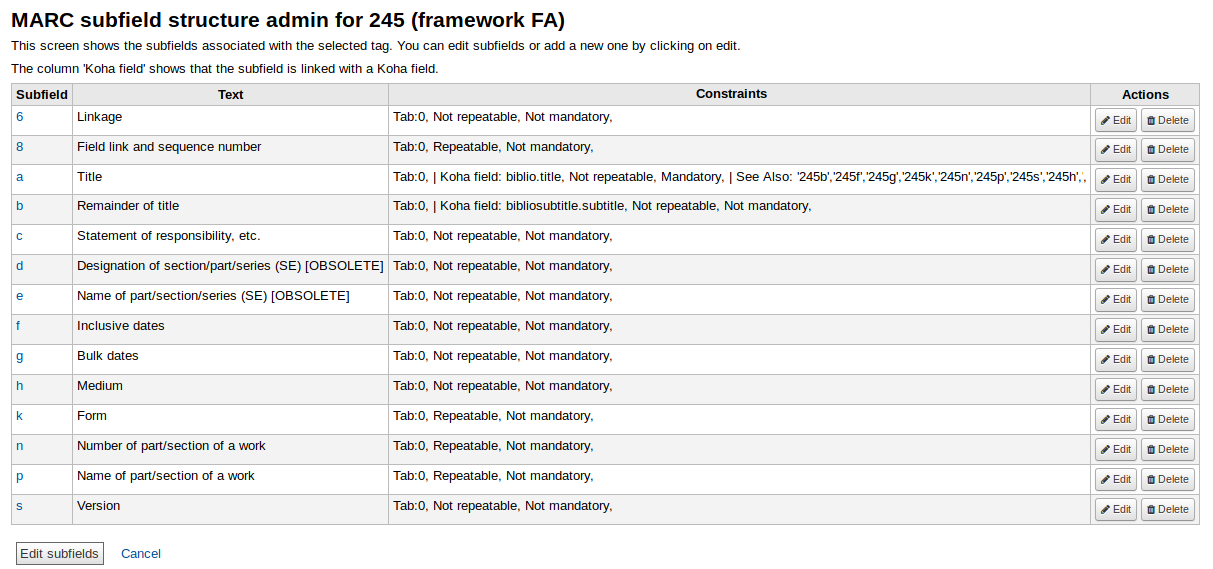
参考资源链接:[Marc中文版使用手册:强大的结构分析工具详解](https://wenku.csdn.net/doc/6401ad03cce7214c316edf98?spm=1055.2635.3001.10343)
# 1. Marc语言入门指南
## Marc语言简介
Marc语言是一种面向文本处理和数据操作的编程语言,它具有简洁的语法和强大的数据处理能力。入门Marc语言,首先需要了解它的基本特性和适用场景,这
量子化学基础与实践:从头算到密度泛函理论的Gaussian 16 B.01应用

参考资源链接:[Gaussian 16 B.01 用户指南:量子化学计算详解](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a187?spm=1055.2635.3001.10343)
# 1. 量子化学的理论基础与历史发展
## 理论基础
量子化学作为化学与量子力学交叉的学科,提供了分子和原子尺度物质特性的理解。它的发展始于20世纪初,主要借助薛
【Excel转PDF终极秘籍】:一步实现文档格式转换的秘诀
参考资源链接:[使用C#将Excel转换为PDF的方法](https://wenku.csdn.net/doc/2h17089otk?spm=1055.2635.3001.10343)
# 1. Excel转PDF概述
在数据报告和业务文档的处理中,Excel到PDF的转换是一个常见的需求。Excel,作为广泛使用的电子表
Vofa+ 1.3.10 x64 调试速查手册:快速定位安装问题的技巧
参考资源链接:[vofa+1.3.10_x64_安装包下载及介绍](https://wenku.csdn.net/doc/2pf2n715h7?spm=1055.2635.3001.10343)
# 1. Vofa+ 1.3.10 x64简介与安装问题概述
## 简介
Vofa+ 1.3.10 x64是一种先进的企
PSAT-2.0.0-ref故障排查与问题解决:遇到问题时的应对策略

参考资源链接:[PSAT 2.0.0 中文使用指南:从入门到精通](https://wenku.csdn.net/doc/6412b6c4be7fbd1778d47e5a?spm=1055.2635.3001.10343)
# 1. PSAT-2.0.0-ref概述及安装配置
## 1.1 PSAT-2.0.0-ref简介
PSA
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )