Python Path库实战演练:自动化文件处理的5大秘诀
发布时间: 2024-10-14 03:59:55 阅读量: 26 订阅数: 27 

Python实例-毕业项目设计:自动化文件管理与转换工具

# 1. Python Path库简介与安装
Python的Path库是一个强大的第三方库,主要用于处理文件路径。它提供了一系列简洁、直观的方法,使得路径操作变得更加容易和直观。Path库本质上是对os.path和glob模块的功能封装,让开发者能够以面向对象的方式进行路径操作。
在开始使用Path库之前,首先需要进行安装。可以通过pip命令来安装Path库,具体操作如下:
```bash
pip install path.py
```
安装完成后,我们就可以在Python代码中导入Path库,并开始进行路径操作。接下来的章节将详细介绍Path库的基本操作和应用。
# 2. Path库的基本操作
在本章节中,我们将深入探讨 Python 的 Path 库,它是一个用于路径操作的工具库,可以帮助我们更方便地处理文件系统中的路径问题。Path 库提供了一种面向对象的方式来处理文件和目录路径,它基于 `os`, `os.path` 和 `glob` 模块进行了封装,使得路径操作更加直观和简洁。我们将从路径的解析与构建开始,逐步介绍 Path 库的基本操作。
## 2.1 路径的解析与构建
路径的解析与构建是 Path 库最基础的功能之一,它允许我们将路径字符串解析为路径对象,并对这些对象进行进一步的操作。
### 2.1.1 路径字符串的解析
首先,我们需要了解如何将路径字符串解析为 Path 对象。Path 库提供了 `Path` 类,我们可以通过传入路径字符串来创建 Path 对象。
```python
from pathlib import Path
# 创建一个 Path 对象
path_obj = Path('/path/to/your/file.txt')
# 输出 Path 对象的字符串表示形式
print(path_obj)
```
### 2.1.2 路径对象的创建和构建
Path 对象不仅可以从字符串创建,还可以通过多种方式构建。例如,我们可以使用 `/` 运算符来连接路径,或者使用 `joinpath` 方法。
```python
from pathlib import Path
# 使用 / 运算符连接路径
path_obj = Path('path/to') / 'your/file.txt'
# 使用 joinpath 方法连接路径
path_obj = Path('path/to').joinpath('your/file.txt')
# 输出 Path 对象的字符串表示形式
print(path_obj)
```
Path 对象一旦创建,我们可以调用它的属性和方法来获取关于路径的信息或进行操作。
## 2.2 路径的查询和修改
Path 对象提供了多种方法来查询路径的信息,以及修改路径。
### 2.2.1 基本信息的查询(如文件名、扩展名、目录)
我们可以查询路径的基本信息,例如文件名、扩展名和所在目录。
```python
from pathlib import Path
# 创建 Path 对象
path_obj = Path('/path/to/your/file.txt')
# 查询文件名
print(path_obj.name) # 输出: file.txt
# 查询扩展名
print(path_obj.suffix) # 输出: .txt
# 查询所在目录
print(path_obj.parent) # 输出: Path('/path/to/your')
```
### 2.2.2 路径的修改(如重命名、移动、复制)
Path 对象还支持对路径进行修改,例如重命名、移动和复制。
```python
from pathlib import Path
# 创建 Path 对象
path_obj = Path('your/file.txt')
# 重命名文件
path_obj.rename('new/file.txt')
# 移动文件
path_obj.rename('new/path/to/file.txt')
# 复制文件
path_obj.copy('backup/path/to/file.txt')
```
## 2.3 文件系统的访问
Path 库还可以用来访问文件系统,检查文件和目录的存在性,以及读写权限。
### 2.3.1 文件和目录的存在性检查
我们可以检查文件或目录是否存在。
```python
from pathlib import Path
# 检查文件是否存在
file_path = Path('file.txt')
print(file_path.exists()) # 输出: True or False
# 检查目录是否存在
dir_path = Path('directory')
print(dir_path.exists()) # 输出: True or False
```
### 2.3.2 文件的读写权限检查
我们还可以检查文件的读写权限。
```python
from pathlib import Path
# 检查文件读权限
file_path = Path('file.txt')
print(file_path.read_text()) # 输出文件内容,如果不存在或无权限则抛出异常
# 检查写权限
try:
file_path.touch(exist_ok=True) # 尝试创建文件,如果存在则更新访问和修改时间
except PermissionError:
print('No write permission')
```
在本章节中,我们介绍了 Path 库的基本操作,包括路径的解析与构建、查询和修改以及文件系统的访问。这些操作构成了 Path 库的核心,为更高级的文件操作提供了基础。在下一章中,我们将进一步探讨 Path 库在文件处理中的应用,例如文件遍历与搜索、自动化操作以及文件信息的收集与整理。
# 3. Path库在文件处理中的应用
## 3.1 文件遍历与搜索
### 3.1.1 遍历目录树
在文件系统的日常管理中,遍历目录树是一项基础而重要的任务。通过遍历,我们可以获取目录结构的完整视图,进而执行各种文件操作。Python的Path库提供了一个便捷的方式来遍历目录树,它不仅简洁,而且跨平台。
```python
from pathlib import Path
# 创建Path对象,指向我们要遍历的目录
root_dir = Path('/path/to/your/directory')
# 使用glob方法遍历目录
for path in root_dir.glob('**/*'):
if path.is_file():
print(path)
```
在上述代码中,`Path.glob('**/*')`是一个非常有用的工具,它使用glob模式匹配目录树中的所有文件和子目录。`**`代表任意数量的子目录,`*`代表任意数量的字符。代码中的`if path.is_file()`用于检查当前路径是否为文件,确保只处理文件类型的条目。
### 3.1.2 文件搜索和过滤
文件搜索和过滤是文件处理中的另一个常见任务。我们需要找到符合特定条件的文件,例如特定的文件类型或名称。Path库的`glob`和`rglob`方法可以帮助我们实现这一点。
```python
# 查找所有.jpg文件
jpg_files = [file for file in root_dir.glob('**/*.jpg')]
# 使用正则表达式过滤文件
import re
filtered_files = [file for file in jpg_files if re.search('photo_[0-9]+\.jpg', file.name)]
# 输出过滤后的文件列表
for file in filtered_files:
print(file)
```
在这个例子中,我们首先使用`glob`方法找到了所有的`.jpg`文件。然后,我们使用正则表达式进一步过滤这些文件,只保留那些名称符合特定模式的文件。这种方法在处理大量数据时非常高效。
### 3.1.3 文件搜索的性能优化
当处理大量文件时,文件搜索可能会变得非常耗时。为了提高效率,我们可以使用一些技巧来优化搜索性能。
```python
# 并行处理文件搜索
from concurrent.futures import ThreadPoolExecutor
import os
def search_files(path, pattern):
for file in path.glob(pattern):
if file.is_file():
# 处理文件
print(file)
# 创建一个线程池
with ThreadPoolExecutor(max_workers=10) as executor:
# 并行搜索多个目录
for root, dirs, files in os.walk('/path/to/search'):
executor.submit(search_files, Path(root), '**/*.txt')
```
在这个例子中,我们使用了`ThreadPoolExecutor`来并行执行文件搜索任务。这可以显著提高处理速度,尤其是在有多个CPU核心可用时。每个线程处理一个目录树,从而减少了总体处理时间。
### 3.1.4 文件遍历的可视化展示
有时候,我们需要将文件遍历的结果以图形化的方式展示出来,以便更直观地理解目录结构。我们可以使用`graphviz`库来实现这一点。
```python
from pathlib import Path
from graphviz import Digraph
def visualize_directory_tree(root_dir):
dot = Digraph(comment='Directory Tree')
# 递归遍历目录树并创建节点
def recurse(d, parent=None):
name = d.name
if not d.is_root():
dot.node(name, label=d.relative_to(parent).as_posix())
if parent is not None and parent != d:
dot.edge(parent.name, name)
for sub_d in d.iterdir():
if sub_d.is_dir():
recurse(sub_d, parent=d)
recurse(root_dir)
return dot
# 创建并保存目录树的图形
root_dir = Path('/path/to/your/directory')
dot = visualize_directory_tree(root_dir)
dot.render('directory_tree.gv', view=True)
```
在这个例子中,我们定义了一个`visualize_directory_tree`函数,它使用`graphviz`库来生成目录树的图形表示。我们递归地遍历目录,并为每个目录和文件创建一个节点。然后,我们使用`render`方法保存并显示这个图形。
### 3.1.5 文件遍历的异常处理
在文件遍历过程中,我们可能会遇到各种异常情况,如权限不足、文件系统错误等。正确的异常处理可以确保我们的程序更加健壮。
```python
from pathlib import Path
import logging
def safe_list_dir(path):
try:
return list(path.iterdir())
except Exception as e:
logging.error(f'Error while listing directory {path}: {e}')
return []
# 使用safe_list_dir函数安全地遍历目录
root_dir = Path('/path/to/your/directory')
for file in safe_list_dir(root_dir):
print(file)
```
在这个例子中,我们定义了一个`safe_list_dir`函数,它使用异常处理来捕获`iterdir`方法可能抛出的任何异常。我们记录错误信息,并继续处理其他文件。
### 3.1.6 文件遍历的性能分析
为了进一步了解文件遍历的性能,我们可以使用Python的`time`模块来测量代码执行时间。
```python
import time
start_time = time.time()
# 执行文件遍历代码
for file in root_dir.glob('**/*'):
if file.is_file():
print(file)
end_time = time.time()
print(f'Total time taken: {end_time - start_time} seconds')
```
在这个例子中,我们使用`time.time()`来记录文件遍历开始和结束的时间点,并计算出整个过程的总耗时。这对于性能调优非常有帮助。
## 3.2 文件操作的自动化
### 3.2.1 文件的批量重命名
在许多情况下,我们需要对文件进行批量重命名,例如在数据整理或归档过程中。Path库可以帮助我们自动化这一过程。
```python
import os
import re
# 批量重命名函数
def batch_rename(root_dir, pattern, replacement):
for file in root_dir.glob(pattern):
new_name = re.sub(pattern, replacement, file.name)
file.rename(file.with_name(new_name))
# 使用批量重命名函数
root_dir = Path('/path/to/your/directory')
batch_rename(root_dir, '_old', '_new')
```
在这个例子中,我们定义了一个`batch_rename`函数,它接受三个参数:要遍历的目录、要匹配的模式和要替换的文本。我们使用正则表达式来匹配文件名,并生成新的文件名。然后,我们使用`rename`方法来重命名文件。
### 3.2.2 文件的自动分类和归档
自动分类和归档是文件操作中的另一个常见需求。我们可以使用Path库来帮助我们自动化这一过程。
```python
# 自动分类和归档函数
def auto_archive(root_dir, categories):
for file in root_dir.glob('**/*'):
if file.is_file():
category = file.suffix[1:] # 获取文件扩展名
if category in categories:
archive_dir = root_dir / f'Archive_{category}'
if not archive_dir.exists():
archive_dir.mkdir()
file.rename(archive_dir / file.name)
# 使用自动分类和归档函数
root_dir = Path('/path/to/your/directory')
categories = ['txt', 'jpg', 'pdf']
auto_archive(root_dir, categories)
```
在这个例子中,我们定义了一个`auto_archive`函数,它根据文件的扩展名将文件自动归档到不同的目录中。我们首先创建一个字典`categories`,其中包含我们想要分类的文件类型。然后,我们为每个文件类型创建一个归档目录,并将文件移动到相应的目录中。
### 3.2.3 文件操作的自动化逻辑分析
在本章节中,我们介绍了如何使用Path库进行文件的批量重命名和自动分类归档。这些操作都是通过编写函数来实现的,每个函数都有一组定义明确的参数,这些参数使得函数更加灵活和可重用。
在批量重命名的例子中,我们使用了正则表达式来处理字符串替换,这是文件重命名中常见的需求。在自动分类和归档的例子中,我们根据文件的扩展名将文件移动到不同的目录中,这是文件管理中常用的技术。
通过这两个例子,我们可以看到Path库在文件操作自动化方面的强大功能。Path对象提供了一系列方法,使得文件路径的操作更加直观和方便。同时,Python的其他模块,如`os`和`re`,可以与Path库协同工作,进一步扩展其功能。
## 3.3 文件信息的收集与整理
### 3.3.1 文件大小和修改时间的统计
在文件管理中,我们经常需要获取文件的大小和修改时间等信息。Path库提供了这些信息的直接访问方式。
```python
import pandas as pd
# 收集文件信息的函数
def collect_file_info(root_dir):
file_info_list = []
for file in root_dir.glob('**/*'):
if file.is_file():
file_info = {
'path': file.as_posix(),
'size': file.stat().st_size,
'modified_time': file.stat().st_mtime
}
file_info_list.append(file_info)
return pd.DataFrame(file_info_list)
# 使用收集文件信息的函数
root_dir = Path('/path/to/your/directory')
file_info_df = collect_file_info(root_dir)
print(file_info_df)
```
在这个例子中,我们定义了一个`collect_file_info`函数,它遍历目录树中的所有文件,并收集每个文件的路径、大小和修改时间。我们使用`pandas`库将收集到的信息存储在DataFrame中,这样可以更方便地进行进一步分析和处理。
### 3.3.2 文件系统的健康检查
文件系统的健康检查是确保文件系统稳定性和性能的关键步骤。我们可以使用Path库来检查文件系统中的各种问题。
```python
# 文件系统健康检查的函数
def check_file_system_health(root_dir):
issues = []
for file in root_dir.glob('**/*'):
if file.is_file():
try:
file.stat()
except Exception as e:
issues.append((file, e))
return issues
# 使用文件系统健康检查的函数
root_dir = Path('/path/to/your/directory')
health_issues = check_file_system_health(root_dir)
for file, error in health_issues:
print(f'Issue with file {file}: {error}')
```
在这个例子中,我们定义了一个`check_file_system_health`函数,它遍历目录树中的所有文件,并尝试获取每个文件的状态。如果在获取状态时发生异常,我们将捕获该异常并将文件和错误信息添加到问题列表中。最后,我们打印出所有遇到的问题。
### 3.3.3 文件信息的可视化分析
为了更直观地分析文件信息,我们可以使用`matplotlib`库来创建图表。
```python
import matplotlib.pyplot as plt
# 可视化文件大小分布的函数
def visualize_file_size_distribution(file_info_df):
plt.figure(figsize=(10, 6))
plt.hist(file_info_df['size'], bins=50)
plt.title('File Size Distribution')
plt.xlabel('Size (bytes)')
plt.ylabel('Number of Files')
plt.show()
# 使用可视化文件大小分布的函数
visualize_file_size_distribution(file_info_df)
```
在这个例子中,我们定义了一个`visualize_file_size_distribution`函数,它使用`matplotlib`库来绘制文件大小的直方图。这可以帮助我们了解文件大小的分布情况。
### 3.3.4 文件信息的整理与报告
最后,我们可以使用`pandas`和`matplotlib`库来整理文件信息并生成报告。
```python
# 生成文件信息报告的函数
def generate_file_info_report(file_info_df):
# 生成直方图
visualize_file_size_distribution(file_info_df)
# 生成文件大小的箱线图
plt.figure(figsize=(10, 6))
plt.boxplot(file_info_df['size'])
plt.title('File Size Boxplot')
plt.ylabel('Size (bytes)')
plt.show()
# 保存文件大小信息到CSV文件
file_info_df.to_csv('file_info.csv', index=False)
# 使用生成文件信息报告的函数
generate_file_info_report(file_info_df)
```
在这个例子中,我们定义了一个`generate_file_info_report`函数,它首先调用`visualize_file_size_distribution`函数来生成直方图,然后生成文件大小的箱线图,并将文件大小信息保存到CSV文件中。这样,我们就可以创建一个包含图表和数据的完整报告。
### 3.3.5 文件信息收集的性能优化
当处理大量文件时,收集文件信息可能会变得非常耗时。为了提高效率,我们可以使用一些技巧来优化性能。
```python
# 并行处理文件信息收集
from concurrent.futures import ProcessPoolExecutor
# 并行收集文件信息的函数
def parallel_collect_file_info(root_dir, max_workers=4):
def worker(file_path):
file_info = {
'path': file_path.as_posix(),
'size': file_path.stat().st_size,
'modified_time': file_path.stat().st_mtime
}
return file_info
file_info_list = []
with ProcessPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(worker, file) for file in root_dir.glob('**/*') if file.is_file()]
for future in futures:
file_info_list.append(future.result())
return pd.DataFrame(file_info_list)
# 使用并行收集文件信息的函数
file_info_df = parallel_collect_file_info(root_dir)
print(file_info_df)
```
在这个例子中,我们定义了一个`parallel_collect_file_info`函数,它使用`ProcessPoolExecutor`来并行收集文件信息。这种方法可以显著提高处理速度,尤其是在有多个CPU核心可用时。每个进程处理一部分文件,并将结果返回给主线程。
### 3.3.6 文件信息收集的异常处理
在文件信息收集过程中,我们可能会遇到各种异常情况,如权限不足、文件不存在等。正确的异常处理可以确保我们的程序更加健壮。
```python
# 安全收集文件信息的函数
def safe_collect_file_info(root_dir):
file_info_list = []
for file in root_dir.glob('**/*'):
try:
file_info = {
'path': file.as_posix(),
'size': file.stat().st_size if file.is_file() else None,
'modified_time': file.stat().st_mtime if file.is_file() else None
}
file_info_list.append(file_info)
except Exception as e:
logging.error(f'Error while collecting info for {file}: {e}')
return pd.DataFrame(file_info_list)
# 使用安全收集文件信息的函数
file_info_df = safe_collect_file_info(root_dir)
print(file_info_df)
```
在这个例子中,我们定义了一个`safe_collect_file_info`函数,它使用异常处理来捕获收集文件信息过程中可能抛出的任何异常。我们记录错误信息,并继续处理其他文件。这样可以确保我们的程序即使在遇到错误时也能继续运行。
# 4. Path库高级功能的探索
在前面的章节中,我们已经掌握了Path库的基本操作和在文件处理中的应用。现在,我们将深入探讨Path库的高级功能,这些功能将帮助我们更好地处理复杂的文件系统任务,并优化我们的代码性能。我们将探索路径模板和模式匹配、跨平台的文件路径处理以及异常处理与性能优化。
## 4.1 路径模板和模式匹配
路径模板和模式匹配是Path库提供的强大功能,允许我们以灵活的方式处理文件和目录路径。我们将学习如何使用glob模板和正则表达式进行路径匹配,这对于文件搜索和自动化任务来说非常有用。
### 4.1.1 使用glob模板进行路径匹配
glob模板是一种简化的模式匹配语法,类似于Unix shell的文件名扩展。在Path库中,我们可以使用它来查找与特定模式匹配的所有路径。
```python
from pathlib import Path
# 使用glob模板查找所有的.txt文件
for path in Path('/path/to/directory').glob('*.txt'):
print(path)
```
这段代码将遍历指定目录及其子目录,打印出所有以`.txt`结尾的文件。glob方法返回一个生成器,我们可以使用循环来处理每一个匹配的路径。
### 4.1.2 使用正则表达式进行路径匹配
正则表达式提供了更为强大和灵活的模式匹配能力。Path库的`rglob`方法可以结合正则表达式使用,以查找符合特定模式的文件路径。
```python
from pathlib import Path
import re
# 使用正则表达式查找所有的Markdown文件
for path in Path('/path/to/directory').rglob('*.md'):
if re.search(r'[0-9]{4}-[0-9]{2}-[0-9]{2}', str(path)):
print(path)
```
这段代码使用正则表达式`[0-9]{4}-[0-9]{2}-[0-9]{2}`来查找符合日期格式的Markdown文件。
## 4.2 跨平台的文件路径处理
在处理文件路径时,不同操作系统之间存在的差异是一个常见的问题。Path库提供了跨平台处理路径的方法,确保我们的代码可以在不同的操作系统上无缝运行。
### 4.2.1 不同操作系统路径差异的处理
Windows系统使用反斜杠`\`作为路径分隔符,而Unix系统(包括Linux和macOS)使用正斜杠`/`。Path库自动处理这些差异,让我们无需担心。
```python
from pathlib import Path
# 在Windows系统中
path = Path('C:\\path\\to\\file.txt')
# 在Unix系统中
path = Path('/path/to/file.txt')
# 获取路径的绝对形式
absolute_path = path.absolute()
print(absolute_path)
```
无论在哪个操作系统上运行,Path库都会返回正确的路径形式。
### 4.2.2 路径标准化和规范化
路径标准化(`resolve`)和规范化(`absolute`)是处理文件路径的两种常用方法。标准化是指解析路径中的相对引用,而规范化则是返回绝对路径。
```python
from pathlib import Path
# 创建一个包含相对引用的路径对象
path = Path('folder/../folder2/file.txt')
# 标准化路径
normalized_path = path.resolve()
print(normalized_path)
# 获取绝对路径
absolute_path = path.absolute()
print(absolute_path)
```
`resolve`方法会将路径中的`.`和`..`解析掉,而`absolute`方法会返回路径的绝对形式。
## 4.3 异常处理与性能优化
在文件系统操作中,错误处理和性能优化是两个不可忽视的方面。Path库提供了异常捕获机制,同时,我们也需要了解一些性能优化的最佳实践。
### 4.3.1 错误处理机制和异常捕获
在进行文件操作时,我们可能会遇到权限问题、文件不存在等错误情况。Path库通过异常机制来处理这些情况。
```python
from pathlib import Path
try:
# 尝试创建一个文件
Path('file.txt').write_text('Hello, Pathlib!')
except PermissionError:
print('Permission denied.')
except FileNotFoundError:
print('File does not exist.')
```
这段代码尝试创建并写入一个文件,如果遇到权限问题或文件不存在,将捕获相应的异常并打印错误信息。
### 4.3.2 性能优化技巧和最佳实践
Path库提供了一些方法来提高文件操作的性能,例如使用`touch`方法来创建文件,这样可以避免不必要的错误检查。
```python
from pathlib import Path
# 创建一个文件,如果文件已存在则更新其访问和修改时间
path = Path('file.txt')
path.touch(exist_ok=True)
```
`touch`方法是一种快速创建文件或更新文件状态的方法,`exist_ok=True`参数表示如果文件已存在,不会抛出异常。
通过本章节的介绍,我们了解了Path库的高级功能,包括路径模板和模式匹配、跨平台的文件路径处理以及异常处理与性能优化。这些知识将帮助我们编写出更加健壮、高效的代码,更好地处理复杂的文件系统任务。
# 5. Path库实战案例分析
## 5.1 实战案例一:自动化文件备份系统
### 5.1.1 需求分析与设计思路
在现代IT工作中,数据备份是一个不可或缺的环节。自动化文件备份系统可以有效地帮助我们管理数据的备份过程,减少人为错误,提高效率。在本案例中,我们将使用Python的Path库来实现一个简单的自动化文件备份系统。
需求分析:
- 自动扫描指定目录下的所有文件和子目录。
- 支持定时备份和手动触发备份。
- 备份文件应包含时间戳,以便区分不同版本的备份。
- 能够检测并避免备份重复文件。
设计思路:
- 使用Path库来解析和构建文件路径。
- 使用`shutil`库来处理文件的复制操作。
- 使用`datetime`库来生成时间戳,用于文件命名。
- 使用`hashlib`库来生成文件的哈希值,用于检测重复文件。
### 5.1.2 功能实现与代码演示
以下是自动化文件备份系统的核心代码实现:
```python
import os
import shutil
import hashlib
from datetime import datetime
from pathlib import Path
def generate_hash(file_path):
hasher = hashlib.md5()
with open(file_path, 'rb') as f:
buf = f.read()
hasher.update(buf)
return hasher.hexdigest()
def backup_files(source_path, backup_path):
if not os.path.exists(backup_path):
os.makedirs(backup_path)
for item in Path(source_path).iterdir():
if item.is_file():
file_hash = generate_hash(item)
backup_file_path = Path(backup_path) / f"{item.name}-{file_hash}"
if not backup_file_path.exists():
shutil.copy2(item, backup_file_path)
print(f"Backup completed for file: {item.name}")
# Example usage:
source_directory = '/path/to/source/directory'
backup_directory = '/path/to/backup/directory'
# Backup immediately
backup_files(source_directory, backup_directory)
# Backup with a timestamp
timestamp = datetime.now().strftime('%Y%m%d%H%M%S')
backup_files_with_timestamp = f"{backup_directory}/{timestamp}"
backup_files(source_directory, backup_files_with_timestamp)
```
在这段代码中,我们定义了`generate_hash`函数来生成文件的MD5哈希值,用于检测重复文件。`backup_files`函数接受源目录和备份目录作为参数,遍历源目录中的所有文件,并将它们复制到备份目录中,同时为每个文件生成一个基于哈希值的唯一文件名,以避免重复备份。
通过这个实战案例,我们可以看到Path库在处理文件路径方面的强大功能,以及如何与其他Python库结合使用来实现复杂的文件操作任务。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python Path 库学习专栏,一个从入门到精通的终极指南。本专栏将带您深入了解 Path 库,掌握自动化文件处理、目录树管理、动态路径构建、符号链接处理、文件操作最佳实践和性能优化等关键技巧。通过一系列循序渐进的教程和实战演练,您将掌握 Path 库的强大功能,并能够高效地处理文件和目录。从初学者到高级用户,本专栏将为您提供全面的知识和实践指导,帮助您充分利用 Path 库,提升您的 Python 编程技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【软件技术方案书中的核心要素】:揭示你的竞争优势,赢得市场
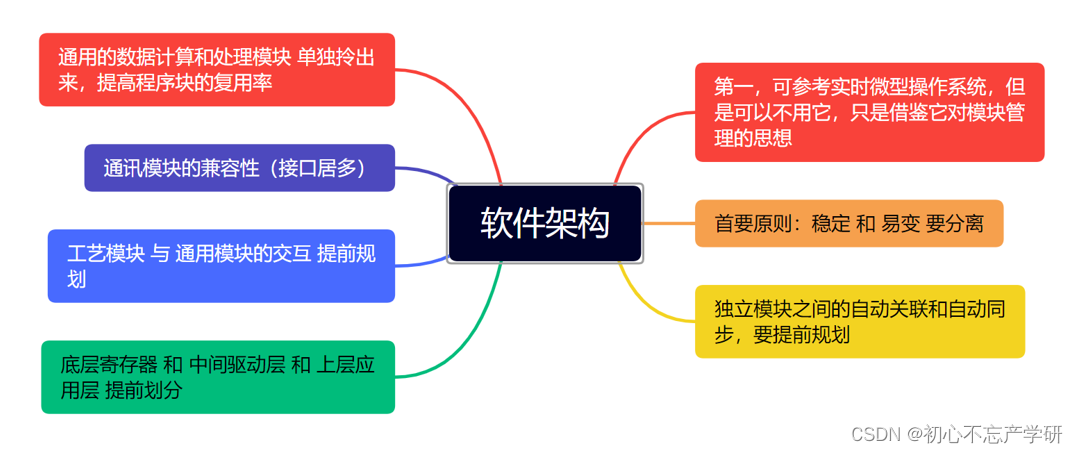
# 摘要
本文旨在全面阐述软件技术方案书的编写与应用,从理论框架到实践指南,再到市场竞争力分析和呈现技巧。首先介绍了软件架构设计原则,如高内聚低耦合和设计模式的应用,然后分析了技术选型的考量因素,包括性能、成熟度、开源与商业软件的选择,以及安全策略和合规性要求。在实践指南部分,探讨了需求分析、技术实施计划、产品开发与迭代等关键步骤。接着,文章对技术方案书的市场竞争力进行了分析,包括竞
【cuDNN安装常见问题及解决方案】:扫清深度学习开发障碍
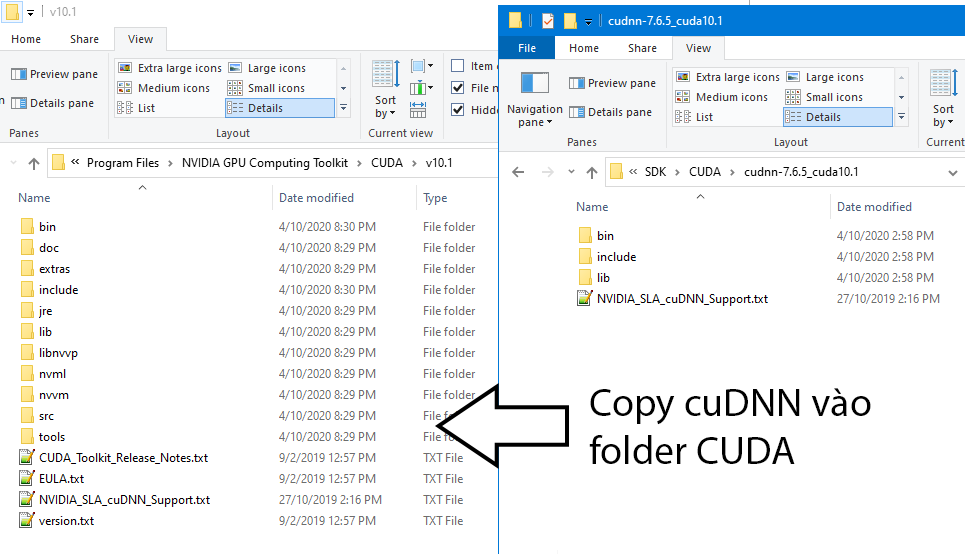
# 摘要
cuDNN作为深度学习库的重要组件,为加速GPU计算提供了基础支持。本文首先介绍了cuDNN的基本概念及其与CUDA的关系,并指导读者完成安装前的准备工作。接着,详细说明了cuDNN的官方安装过程,包括系统兼容性考虑、安装步骤及安装后的验证。针对容器化环境,本文还提供了Docker集成cuDNN的方法。针对安装后可能出现的问题,本文探讨了常见的错误诊断及性能优化策略。进一步地,本
【OpenADR 2.0b 与可再生能源】:挖掘集成潜力,应对挑战
# 摘要
本文系统地介绍了OpenADR 2.0b 标准,并探讨了其在可再生能源和智能电网融合中的关键作用。首先概述了OpenADR 2.0b 标准的基本内容,分析了可再生能源在现代能源结构中的重要性以及需求响应(DR)的基本原理。随后,文章深入探讨了OpenADR 2.0b 如何与智能电网技术相融合,以及在实践中如何促进可再生能源的优化管理。通过具体案例分析,本文揭示了OpenADR 2.0b 应用的成功因素和面临的挑战,并对未来面临的挑战与机遇进行了展望,特别指出了物联网(IoT)和人工智能(AI)技术的应用前景,提出了相应的政策建议。本文的研究为推动可再生能源与需求响应的结合提供了有价值
【UDS故障诊断实战秘籍】:快速定位车辆故障的终极指南

# 摘要
统一诊断服务(UDS)诊断协议是汽车电子领域内标准化的故障诊断和程序更新协议。本文首先介绍了UDS协议的基础知识、核心概念以及诊断消息格式,之后深入探讨了故障诊断的理论知识和实战中常见的UDS命令。文中对不同UDS诊断工具及其使用环境搭建进行了对比和分析,并且提供了实战案例,包括典型故障诊断实例和高级技术应用。此外,本文还
【HMI触摸屏通信指南】:自由口协议的入门与实践

# 摘要
自由口协议作为一种广泛应用于嵌入式系统的串行通信协议,提供了一种灵活的设备间通信方式。本文首先概述了自由口协议的基本概念及其理论基础,包括工作原理、通信模式以及
日志数据质量提升:日志易V2.0清洗与预处理指南
# 摘要
日志数据在系统监控、故障诊断及安全分析中扮演着至关重要的角色,其质量和处理方式直接影响到数据分析的准确性和效率。本文重点探讨了日志数据的重要性及其质量影响,详细阐述了日志数据清洗的基本原理和方法,涵盖不一致性、缺失值、噪声和异常值的处理技术。本文还详细解析了日志预处理技术,包括数据格式化、标准化、转换与集成及其质量评估。通过介绍
案例剖析:ABB机器人项目实施的最佳实践指南

# 摘要
本论文针对ABB机器人技术的应用,提供了一套系统的项目需求分析、硬件选型、软件开发、系统集成到部署和维护的全面解决方案。从项目需求的识别和分析到目标设定和风险管理,再到硬件选型时载荷、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )