




【处理大规模监测数据】:Python与大数据的协同工作


基于FPGA的四相八拍步进电机控制系统设计:集成交付、正反转、加速减速及调速功能
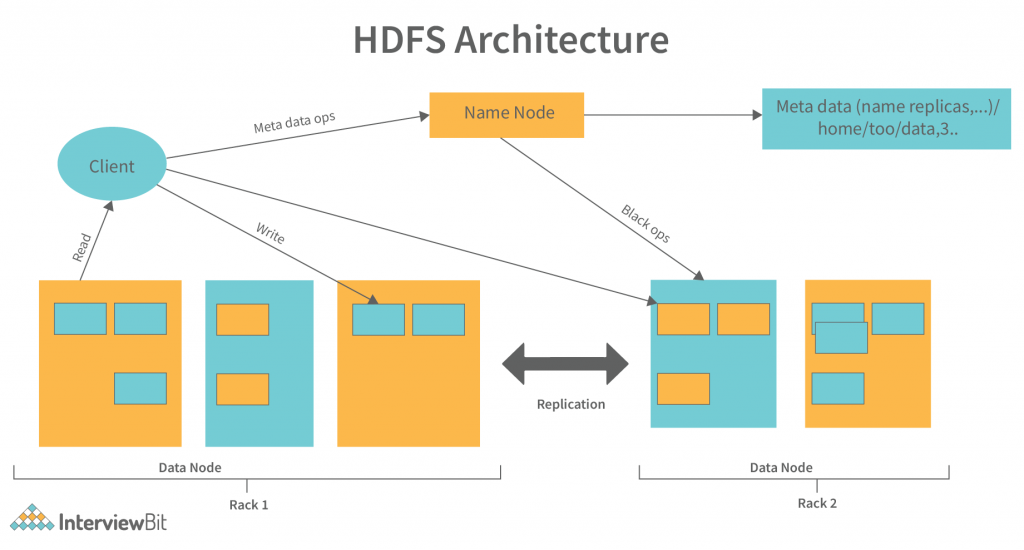
1. Python在大数据处理中的角色
在当今这个数据驱动的时代,大数据处理已经成为了许多IT专业人士的核心关注点。Python作为一种高效、简洁且功能强大的编程语言,在大数据处理领域扮演着越来越重要的角色。它丰富的库、框架和社区支持使其成为分析和处理大量数据的首选工具。从简单的数据操作到复杂的数据挖掘,再到大数据生态系统的集成,Python都能提供行之有效的解决方案。此外,Python还因其易于学习的特性,让更多的数据分析师和技术人员能够迅速掌握大数据处理的技能,进而在工作中取得显著的效率提升。随着大数据技术的不断发展,Python也在持续演进,以适应新的数据挑战,这一点在后续章节中将进一步探讨。
2. Python大数据处理基础
2.1 Python数据处理库概述
Python是一种流行的编程语言,它在数据处理领域占据着举足轻重的地位。其背后的原因是,Python拥有大量用于数据处理、分析和可视化的强大库。接下来我们将讨论这些库中最为关键的两个:NumPy和Pandas,以及数据处理流程的优化技巧。
2.1.1 NumPy和Pandas的基础使用
NumPy 是 Python 中用于科学计算的核心库。它提供了一个强大的 n 维数组对象,称为 ndarray。NumPy 的数组使用起来比 Python 内置的列表类型更高效,因为它们提供了更快的数据处理速度和内存管理优势。NumPy 通常被用来进行数学运算、生成伪随机数、生成矩阵等。
以下是NumPy数组的创建和操作的一个简单示例:
- import numpy as np
- # 创建一个一维数组
- array_1d = np.array([1, 2, 3, 4, 5])
- # 创建一个二维数组
- array_2d = np.array([[1, 2, 3], [4, 5, 6]])
- # 数组的基本操作
- print(array_1d + 1) # 所有元素加一
- print(array_2d * 2) # 所有元素乘二
- # 数组的形状和数据类型
- print(array_2d.shape) # 输出:(2, 3)
- print(array_2d.dtype) # 输出:int64
Pandas 基于 NumPy 构建,提供了高性能、易于使用的数据结构和数据分析工具。Pandas 主要的两个数据结构是 Series 和 DataFrame。Series 是一种一维数组,DataFrame 则是一种表格型数据结构。
下面是一个Pandas Series和DataFrame的创建和操作示例:

2.1.2 数据处理流程的优化技巧
在处理大数据时,通常需要考虑优化数据处理的流程以提高效率。这里有一些常用的优化技巧:
- 使用NumPy数组代替Python列表,进行大规模数值计算。
- 利用Pandas的内置函数来避免不必要的循环,使用向量化操作。
- 对于重复的数据处理任务,考虑使用Pandas的
apply函数或者使用NumPy的广播功能。 - 当数据集非常大而无法放入内存时,利用Pandas的
chunksize参数进行数据的分块读取。 - 使用
memory_profiler等工具监控代码的内存使用情况,并进行适当的优化。
2.2 Python数据清洗和预处理
2.2.1 数据清洗常用方法
数据清洗是数据处理中非常重要的一个环节。在这一部分,我们将探讨数据清洗的常用方法。
- 处理缺失值:在数据集中,缺失值是常见问题。可以使用Pandas的
dropna()或fillna()方法来处理缺失值。 - 去除重复数据:重复数据会影响分析结果的准确性。Pandas的
drop_duplicates()方法可以轻松移除重复的数据行。 - 数据类型转换:确保每个列的数据类型正确无误。例如,使用
astype()方法将列的数据类型转换为适当的格式。 - 数据标准化和归一化:对于需要进行数值比较的场景,对数据进行标准化或归一化是一个好的实践。
- 异常值检测和处理:异常值的处理需要结合业务逻辑进行决策。Pandas的
quantile()方法有助于识别异常值。
- # 示例代码:处理缺失值
- df = pd.DataFrame({'A': [1, 2, None, 4, 5], 'B': [None, 2, 3, None, 6]})
- df.dropna(inplace=True) # 删除包含缺失值的行
- df.fillna(0, inplace=True) # 缺失值填充为0
2.2.2 数据预处理的高级应用
特征工程是数据预处理中的高级应用之一,它涉及到创建新特征、转换现有特征或选择最有信息量的特征,以便提高机器学习模型的性能。
- 特征编码:对于分类变量,通常使用独热编码(One-Hot Encoding)或者标签编码(Label Encoding)。
- 特征转换:一些算法可能对数据的分布或规模敏感,这时可以使用特征转换技术,如对数转换或标准化。
- 多项式特征:通过多项式特征扩展特征空间,提高模型的表达能力。
- 特征选择:通过诸如随机森林重要性评分等方法来选择最有信息量的特征。
- # 示例代码:特征编码
- from sklearn.preprocessing import OneHotEncoder
- encoder = OneHotEncoder()
- encoded = encoder.fit_transform(df[['category_column']]).toarray()
- # 将编码后的特征添加到原数据集中
- encoded_df = pd.DataFrame(encoded, columns=encoder.get_feature_names(['category_column']))
- df = pd.concat([df.reset_index(drop=True), encoded_df], axis=1)
2.3 Python数据可视化技术
2.3.1 常用的数据可视化库
数据可视化是数据分析的重要组成部分,它帮助我们通过图形化的形式理解数据。Python中有多个库可用来创建数据可视化图表:
- Matplotlib 是Python中最著名的可视化库之一,可以用来创建静态、动态和交互式的图表。
- Seaborn 建立在 Matplotlib 之上,提供了更多高级的绘图函数和美观的默认设置。
- Plotly 提供了一个交互式的图形界面,非常适合于展示复杂的数据集。
- Bokeh 专注于将Python可视化图形嵌入网页中,提供了高度交互式的图表。
下面是一个使用Matplotlib绘制简单折线图的示例:
- import matplotlib.pyplot as plt
- # 示例数据
- x = [1, 2, 3, 4, 5]
- y = [1, 4, 9, 16, 25]
- plt.plot(x, y)
- plt.title('Simple Plot')
- plt.xlabel('X axis')
- plt.ylabel('Y axis')
- plt.show()
2.3.2 复杂数据集的可视化策略
对于复杂的数据集,可视化策略需要更细致的考虑,包括:
- 维度选择:选取数据中最有代表性的特征进行可视化。
- 交互式可视化:对于大规模数据集,交互式可视化(例如使用 Plotly 或 Bokeh)有助于深入探索数据。
- 多图表集成:将多个图表结合在一起,形成一个综合性视

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
Cygwin系统监控指南:性能监控与资源管理的7大要点
【精准测试】:确保分层数据流图准确性的完整测试方法
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【T-Box能源管理】:智能化节电解决方案详解


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















