Lua热更新技术中的数据结构与算法优化
发布时间: 2024-01-03 00:50:53 阅读量: 48 订阅数: 22 
# 1. Introduction
## 1.1 Background
The field of Lua hot update technology has gained significant attention in recent years due to its ability to dynamically update and modify Lua code during runtime. This technology plays a crucial role in various industries, including game development, embedded systems, and server-side applications. With Lua hot update, developers can introduce new features, bug fixes, and performance optimizations without interrupting the running application.
## 1.2 Objectives
The objective of this article is to explore how data structure and algorithm optimizations can enhance the efficiency and performance of Lua hot update technology. By utilizing appropriate data structures and efficient algorithms, developers can achieve faster code execution, reduced memory footprint, and improved overall system performance.
## 1.3 Scope
This article focuses on the optimization techniques related to data structures and algorithms specifically in the context of Lua hot update. It discusses the importance of selecting the right data structures, optimizing data access and manipulation, identifying and improving inefficient algorithms, and demonstrating the significance of testing and benchmarking in evaluating the effectiveness of various optimizations.
Now that we have provided an overview of the article's content and structure, let's delve into the details of Lua hot update technology and its benefits in the next section.
## Lua Hot Update Technology Overview(Lua热更新技术概述)
Lua热更新技术是一种在运行时更新Lua脚本而无需重启应用程序的技术。本章节将介绍Lua热更新的概念、好处以及常见挑战。
三、数据结构优化
### 3.1 Importance of Data Structure(数据结构的重要性)
在软件开发中,选择适当的数据结构是非常重要的,因为数据结构直接影响到程序的性能和效率。一个良好的数据结构可以帮助我们更快地访问和操作数据,从而提升程序的运行速度和效果。
使用高效的数据结构可以减少时间和空间的开销,提高代码的可读性和可维护性,同时还能降低后续功能扩展和优化的难度。因此,优化数据结构是实现高性能和高效率的关键之一。
### 3.2 Choosing the Right Data Structure(选择合适的数据结构)
在选择数据结构时,我们需要根据具体的需求和问题来进行评估和选择。以下是一些常见的数据结构及其适用场景:
- 数组(Array):适用于需要快速随机访问元素的情况,但插入和删除操作的性能较差。
- 链表(Linked List):适用于频繁执行插入和删除操作的情况,但访问元素的性能较差。
- 栈(Stack):用于实现先进后出(LIFO)的数据结构,适用于需要快速插入和删除数据的场景,如函数调用栈。
- 队列(Queue):用于实现先进先出(FIFO)的数据结构,适用于多线程任务分发、消息队列等场景。
- 哈希表(Hash Table):适用于需要快速查找和插入键值对的情况,但内存消耗较大。
- 树(Tree):如二叉树、平衡二叉树、堆等,适用于需要按特定顺序组织和访问数据的情况,如排序、搜索等。
- 图(Graph):用于表达节点之间复杂关系的数据结构,适用于网络、社交网络分析等场景。
根据实际情况选择合适的数据结构对于优化算法的执行效率至关重要。
### 3.3 Optimizing Data Access and Manipulation(优化数据访问与操作)
一旦选择了适当的数据结构,我们还需要优化数据的访问和操作方式,以进一步提高程序的性能。以下是一些用于优化数据访问和操作的常见技巧和方法:
- 避免频繁的内存分配和释放,尽量使用对象池或缓冲区来重用内存。
- 尽量减少不必要的数据复制操作,如使用引用(Reference)而不是拷贝实际数据。
- 使用迭代器(Iterator)来遍历

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏《Lua热更新技术》主要介绍了Lua脚本语言的热更新技术及其在不同领域中的广泛应用。文章涵盖了热更新技术的简介与原理解析,详细解释了实现步骤和游戏开发中的结合应用。此外,还探讨了热更新技术在移动应用开发、服务器端应用开发、嵌入式系统中的实际应用以及对程序性能的影响和优化建议。同时,该专栏还比较了框架级和项目级热更新技术,解决了问题排查与解决方法,讨论了安全性、版本管理和兼容性处理等方面的问题。此外,还介绍了动态调试、测试技巧、面向对象编程、异步编程、多线程并发处理、内存管理、数据结构与算法优化以及大规模系统中的可扩展性探讨等方面。最后,文章还探讨了热更新技术与网络通信协议的相关知识。通过阅读该专栏,读者将了解Lua热更新技术的应用范围和实践经验,并能够应用于自己的项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
西门子V90 PN伺服进阶配置:FB284功能库高级应用技巧

# 摘要
本文全面介绍了西门子V90 PN伺服的基础知识,并深入讲解了FB284功能库的概述、安装、配置、参数设置、优化以及高级应用。通过详细阐述FB284功能库的安装要求、初始配置、参数设置技巧、功能块应用和调试故障诊断,本文旨在提供一个关于如何有效利用该功能库以满足自动化项目需求的实践指南。此外,本文通
【Ensp网络实验新手必读】:7步快速搭建PPPoE实验环境
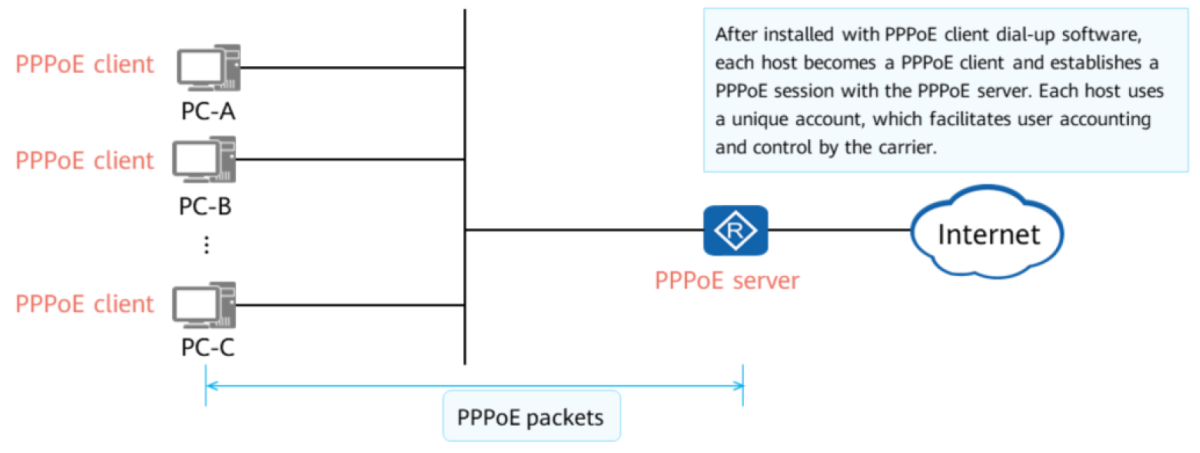
# 摘要
本文系统地介绍了网络基础知识,重点对PPPoE(点对点协议上以太网)技术进行了深入解析,从其工作原理、优势、应用场景以及认证机制等方面进行了全面阐述。同时,介绍了如何利用Ensp(Enterprise Simulation Platform,企业模拟平台)环境搭建和配置PPPoE服务器,并通过实验案例详细演示了PPPoE的
【Excel宏自动化终极指南】:打造你的第一个宏并优化性能
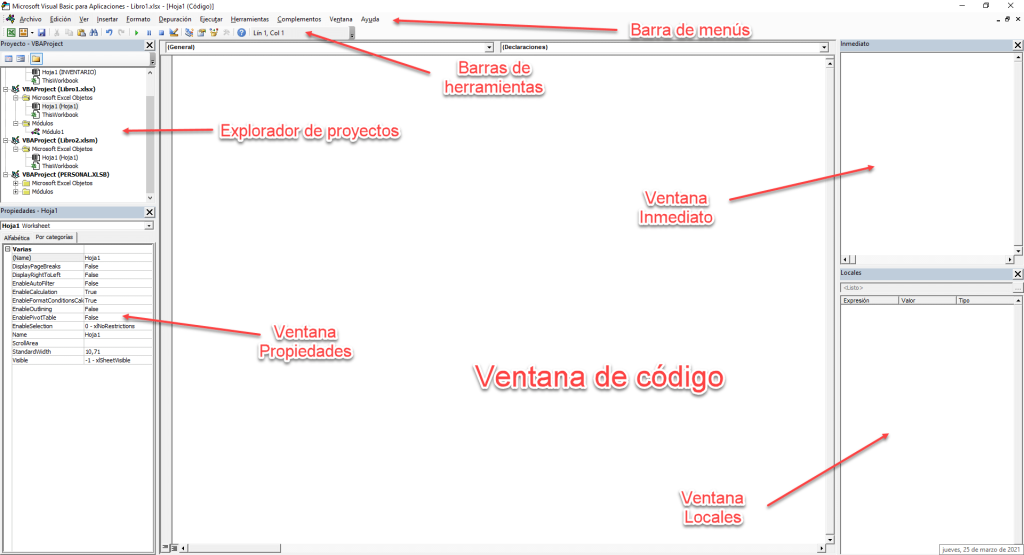
# 摘要
Excel宏自动化作为一种提高工作效率的技术,允许用户通过编写代码来自动化重复性任务和复杂的数据处理。本文全面介绍了Excel宏的基础知识,包括VBA编程基础和Excel对象模型的理解。通过创建和调试宏的实践经验,本文进一步展示了如何编写、优化和维护高效且安全的宏。此外,本文也探讨了宏在实际应用案例中的作用,包括自动化日常任务、数据分析和用户交互等方面
【多尺度可视化方法】:三维标量场数据的精细展现策略
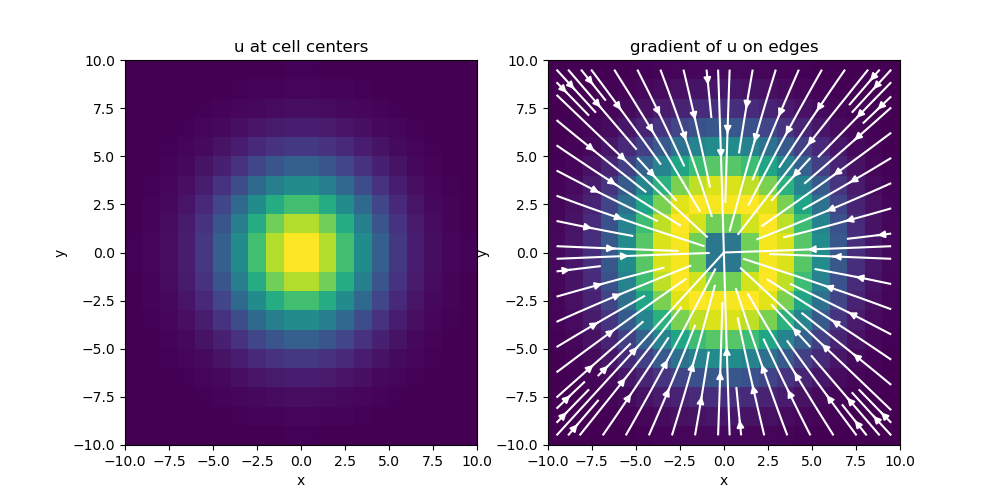
# 摘要
多尺度可视化作为一种复杂数据的表示和分析方法,在三维标量场数据的处理和展示中发挥着重要作用。本文首先概述了多尺度可视化的基本理论与三维标量场数据的特点。随后,深入探讨了多尺度可视化技术的实现方法,包括数据预处理、可视化算法原理及其应用,以及交互式可视化的用户交互设计。接着,通过案例分析,展示了大数据集多尺度可视化和实时三维标量场数据展示的具体应用。最后,本文分析了多尺度
IAR EWARM调试秘籍:代码效率与稳定性提升技巧

# 摘要
IAR Embedded Workbench是嵌入式系统开发者广泛使用的集成开发环境。本文介绍了IAR Embedded Workbench的基本概况及其安装过程,接着深入探讨了代码效率优化的策略,包括高级编译器优化技术的应用、代码剖析与性能分析技巧,以及低功耗编程的实践方法。之后,文章专注于调试技巧,讨论了调试环境的设置
【JFreeChart:定制化图表开发的高级技巧】

# 摘要
JFreeChart是一个功能强大的Java图表库,它允许开发者在各种环境下创建和定制高质量的图表。本文首先介绍JFreeChart库的基础知识,包括基本图表对象的创建、数据源管理、图表元素的样式定制以及轴和坐标系统的定制。然后,深入探讨如何构建复杂的图表表示、交互式元素增强以及图表的性能优化
【Python地震数据分析】:obspy库的深入应用与性能优化

# 摘要
Python已成为地震数据分析领域的首选编程语言,而obspy库作为其核心工具之一,在地震数据采集、处理、分析及可视化方面提供了强大的支持。本文首先概述了Python在地震数据分析中的应用,随后深入探讨了obspy库的理论基础、核
保护数据完整性:电子秤协议安全机制的全面探讨

# 摘要
数据完整性与电子秤协议是确保交易准确性和安全性的重要基础。本文首先探讨了数据完整性的概念及其与数据安全的紧密联系,然后分析了电子秤协议的国际标准化组织规范及安全目标。在理论框架的基础上,进一步阐述了电子秤协议安全技术实现的多种方法,包括认证授权机制、加密技术应用以及传输层保护和数据校验。通过实践案例分析,总结了成功与失败案例中的安全
【TRS WAS 5.0负载均衡进阶教程】:提升系统扩展性的秘诀

# 摘要
本文旨在全面介绍TRS WAS 5.0的基础配置及其在负载均衡方面的应用。首先,我们从TRS WAS 5.0的基本概念和基础配置入手,为读者提供了系统配置的第一手经验。接着,深入探讨了负载均衡的理论基础、主要技术与算法,强调了调度策略、健康检查机制和会话保持的重要性。文章进一步通过实践部署章节,详细说明了在TRS WAS 5.0环境中如何配置集群以及实施负载均衡策略,包
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )