XML数据解析:揭秘DOM、SAX和XPath,提升解析效率
发布时间: 2024-07-28 15:46:41 阅读量: 58 订阅数: 44 

Dom,Sax,Xpath解析XML实例
# 1. XML数据解析简介
XML(可扩展标记语言)是一种用于表示和传输结构化数据的标准化标记语言。它广泛用于各种应用程序中,包括数据交换、配置管理和文档存储。
XML数据解析是将XML文档转换为应用程序可用的数据结构的过程。有两种主要的方法来解析XML数据:DOM(文档对象模型)和SAX(简单API for XML)。
DOM解析将XML文档加载到内存中,并创建其完整的树状表示。这使得可以轻松地访问和操作XML文档中的任何元素或属性。然而,DOM解析的缺点是内存消耗大,并且对于大型XML文档来说可能很慢。
# 2. DOM解析技术
### 2.1 DOM树结构和操作
#### 2.1.1 DOM树的结构和层次
DOM(Document Object Model)树是一种层次结构,它将XML文档表示为一个对象树。每个节点都代表XML文档中的一个元素、属性或文本。DOM树的根节点是`<document>`元素,它包含了整个XML文档。
**DOM树的层次结构:**
- **根节点:**`<document>`元素
- **元素节点:**表示XML文档中的元素
- **属性节点:**表示元素的属性
- **文本节点:**表示元素中的文本内容
- **注释节点:**表示XML文档中的注释
#### 2.1.2 DOM节点的操作和遍历
DOM API提供了各种方法来操作和遍历DOM树中的节点。
**操作DOM节点:**
- `createElement()`:创建新的元素节点
- `appendChild()`:将子节点添加到父节点
- `insertBefore()`:在现有子节点之前插入新子节点
- `removeChild()`:从父节点中删除子节点
- `setAttribute()`:设置元素的属性
- `getAttribute()`:获取元素的属性
**遍历DOM节点:**
- `firstChild`:获取节点的第一个子节点
- `lastChild`:获取节点的最后一个子节点
- `nextSibling`:获取节点的下一个同级节点
- `previousSibling`:获取节点的上一个同级节点
- `parentNode`:获取节点的父节点
### 2.2 DOM解析的优缺点
#### 2.2.1 DOM解析的优势
- **完整性:**DOM解析器将整个XML文档加载到内存中,因此可以访问文档中的所有数据。
- **灵活性:**DOM API提供了丰富的操作和遍历方法,允许对XML文档进行灵活的处理。
- **支持性:**DOM解析器得到广泛的支持,并且在各种编程语言中都有实现。
#### 2.2.2 DOM解析的劣势
- **内存消耗:**DOM解析器将整个XML文档加载到内存中,因此可能会消耗大量的内存,尤其是对于大型XML文档。
- **性能:**DOM解析通常比SAX解析慢,因为需要构建整个DOM树。
- **复杂性:**DOM API相对复杂,学习和使用可能需要时间。
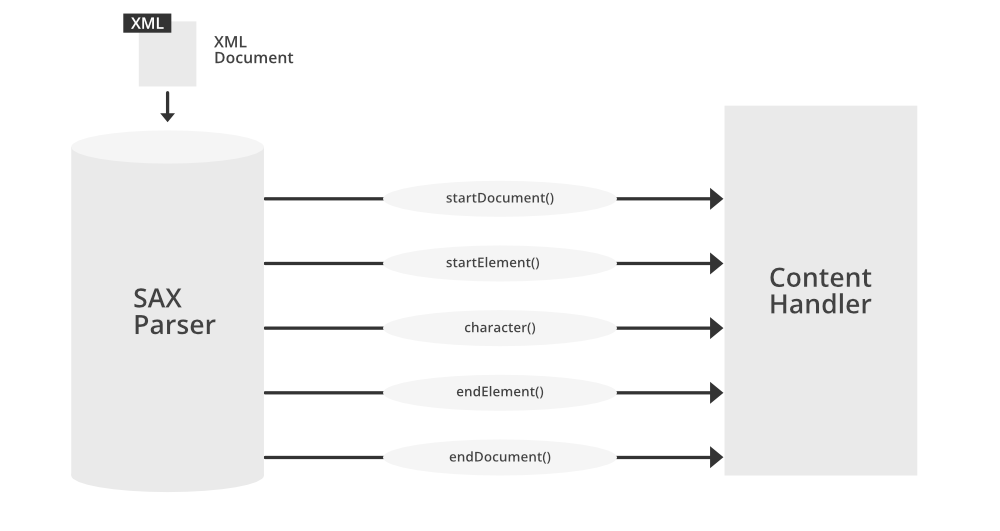
# 3. SAX解析技术
SAX(Simple API for XML)是一种事件驱动的XML解析技术,它以流的方式解析XML文档,逐个事件处理XML元素。与DOM解析不同,SAX解析不会构建整个DOM树,而是通过事件处理机制逐个处理XML元素。
### 3.1 SAX事件处理机制
SAX解析器提供了一系列事件类型,当解析器遇到特定XML元素时,它会触发相应的事件。这些事件类型包括:
- **startElement():**当解析器遇到一个开始标签时触发。
- **endElement():**当解析器遇到一个结束标签时触发。
- **characters():**当解析器遇到元素的内容时触发。
- **startDocument():**当解析器开始解析XML文档时触发。
- **endDocument():**当解析器完成解析XML文档时触发。
### 3.1.1 SAX解析器的事件处理
为了使用SAX解析器,开发人员需要实现一个事件处理类,该类继承自`DefaultHandler`类并重写相应的事件处理方法。当解析器触发特定事件时,它会调用相应的事件处理方法。
```java
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXEventHandler extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 处理开始标签事件
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// 处理结束标签事件
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// 处理元素内容事件
}
@Override
public void startDocument() throws SAXException {
// 处理文档开始事件
}
@Override
public void endDocument() throws SAXException {
// 处理文档结束事件
}
}
```
### 3.1.2 SAX解析器的事件处理
SAX解析器使用一个SAXParser对象来解析XML文档。SAXParser对象通过`parse()`方法解析XML文档,并触发相应的事件。
```java
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
public class SAXParserExample {
public static void main(String[] args) throws SAXException {
// 创建SAX解析器
XMLReader reader = XMLReaderFactory.createXMLReader();
// 设置事件处理类
reader.setContentHandler(new SAXEventHandler());
// 解析XML文档
reader.parse("example.xml");
}
}
```
### 3.2 SAX解析的优缺点
**3.2.1 SAX解析的优势**
- **低内存消耗:**SAX解析不会构建整个DOM树,因此它消耗的内存较少。
- **快速解析:**SAX解析以流的方式解析XML文档,逐个事件处理元素,因此解析速度较快。
- **可扩展性:**SAX解析器允许开发人员自定义事件处理类,以便根据需要处理特定的XML元素。
**3.2.2 SAX解析的劣势**
- **难以导航:**SAX解析器不构建DOM树,因此开发人员无法使用DOM API来导航XML文档。
- **不支持随机访问:**SAX解析器以流的方式解析XML文档,因此开发人员无法随机访问XML元素。
- **难以处理复杂文档:**对于包含大量嵌套元素的复杂XML文档,SAX解析可能难以处理。
# 4. XPath技术
### 4.1 XPath语法和表达式
#### 4.1.1 XPath语法概述
XPath(XML Path Language)是一种用于在XML文档中导航和查询数据的语言。它基于XPath表达式,采用路径表达式语法,类似于文件系统中的路径。XPath表达式由以下部分组成:
- **轴:**指定从当前节点开始导航的方向,如`child::`(子节点)、`parent::`(父节点)、`descendant::`(后代节点)
- **节点测试:**指定要匹配的节点类型,如`element()`(元素节点)、`text()`(文本节点)、`attribute()`(属性节点)
- **谓词:**用于过滤匹配的节点,指定附加条件,如`[@id='1']`(具有id属性值为1的节点)
#### 4.1.2 XPath表达式类型和用法
XPath表达式有两种主要类型:
- **位置路径表达式:**用于导航和选择XML文档中的节点,如`/root/child1/child2`(从根节点开始,选择child1的child2节点)
- **谓词表达式:**用于对位置路径表达式选择的结果进行过滤,如`//element[@id='1']`(选择所有具有id属性值为1的element节点)
### 4.2 XPath在XML解析中的应用
#### 4.2.1 XPath查询XML元素
XPath可用于查询XML文档中的元素。例如,以下XPath表达式将选择`book`元素的所有子元素:
```xml
/book/*
```
#### 4.2.2 XPath提取XML数据
XPath也可用于从XML文档中提取数据。例如,以下XPath表达式将提取`book`元素中`title`元素的文本内容:
```xml
/book/title/text()
```
**代码块:**
```python
import xml.etree.ElementTree as ET
# 解析XML文件
tree = ET.parse('books.xml')
# 使用XPath查询XML元素
books = tree.findall('/book')
# 遍历查询结果
for book in books:
print(book.tag, book.attrib)
```
**逻辑分析:**
该代码使用ElementTree库解析XML文件,然后使用XPath表达式查询所有`book`元素。查询结果是一个列表,其中包含所有匹配的`book`元素。代码遍历列表并打印每个元素的标签和属性。
**表格:XPath表达式类型和用法**
| 表达式类型 | 用途 |
|---|---|
| 位置路径表达式 | 导航和选择XML文档中的节点 |
| 谓词表达式 | 对位置路径表达式选择的结果进行过滤 |
**Mermaid流程图:XPath解析流程**
```mermaid
sequenceDiagram
participant User
participant XPath Parser
User->XPath Parser: Send XPath expression
XPath Parser->User: Return matching nodes
```
# 5. XML数据解析实践
### 5.1 DOM解析示例
#### 5.1.1 使用DOM解析XML文件
DOM解析XML文件的基本步骤如下:
1. 创建一个DOM解析器:使用`DocumentBuilderFactory`创建`DocumentBuilder`,再使用`DocumentBuilder`创建`Document`对象。
2. 加载XML文件:使用`Document`对象的`parse()`方法加载XML文件。
3. 获取根元素:使用`Document`对象的`getDocumentElement()`方法获取根元素。
4. 遍历和操作XML数据:使用DOM节点的各种方法(如`getChildNodes()`、`getAttributes()`)遍历和操作XML数据。
#### 5.1.2 DOM解析的代码实现
```java
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class DOMParserDemo {
public static void main(String[] args) throws Exception {
// 创建DOM解析器
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
// 加载XML文件
Document document = builder.parse("example.xml");
// 获取根元素
Element root = document.getDocumentElement();
// 遍历和操作XML数据
NodeList nodes = root.getChildNodes();
for (int i = 0; i < nodes.getLength(); i++) {
Node node = nodes.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
System.out.println("元素名称:" + element.getNodeName());
System.out.println("元素值:" + element.getTextContent());
}
}
}
}
```
**代码逻辑逐行解读:**
1. `DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();`:创建DOM解析器工厂。
2. `DocumentBuilder builder = factory.newDocumentBuilder();`:使用工厂创建DOM解析器。
3. `Document document = builder.parse("example.xml");`:加载XML文件并解析为DOM对象。
4. `Element root = document.getDocumentElement();`:获取根元素。
5. `NodeList nodes = root.getChildNodes();`:获取根元素的所有子节点。
6. `for (int i = 0; i < nodes.getLength(); i++)`:遍历子节点。
7. `Node node = nodes.item(i);`:获取当前子节点。
8. `if (node.getNodeType() == Node.ELEMENT_NODE)`:判断当前节点是否为元素节点。
9. `Element element = (Element) node;`:将当前节点转换为元素节点。
10. `System.out.println("元素名称:" + element.getNodeName());`:输出元素名称。
11. `System.out.println("元素值:" + element.getTextContent());`:输出元素值。
### 5.2 SAX解析示例
#### 5.2.1 使用SAX解析XML文件
SAX解析XML文件的基本步骤如下:
1. 创建一个SAX解析器:使用`SAXParserFactory`创建`SAXParser`,再使用`SAXParser`创建`XMLReader`对象。
2. 注册事件处理器:为`XMLReader`对象注册事件处理器,用于处理SAX事件。
3. 解析XML文件:使用`XMLReader`对象的`parse()`方法解析XML文件。
#### 5.2.2 SAX解析的代码实现
```java
import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class SAXParserDemo {
public static void main(String[] args) throws Exception {
// 创建SAX解析器
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
// 注册事件处理器
DefaultHandler handler = new DefaultHandler() {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) {
System.out.println("开始元素:" + qName);
}
@Override
public void endElement(String uri, String localName, String qName) {
System.out.println("结束元素:" + qName);
}
@Override
public void characters(char[] ch, int start, int length) {
System.out.println("字符数据:" + new String(ch, start, length));
}
};
// 解析XML文件
parser.parse("example.xml", handler);
}
}
```
**代码逻辑逐行解读:**
1. `SAXParserFactory factory = SAXParserFactory.newInstance();`:创建SAX解析器工厂。
2. `SAXParser parser = factory.newSAXParser();`:使用工厂创建SAX解析器。
3. `DefaultHandler handler = new DefaultHandler() { ... };`:创建事件处理器。
4. `parser.parse("example.xml", handler);`:解析XML文件并处理SAX事件。
# 6. XML数据解析性能优化
### 6.1 DOM解析优化技巧
**6.1.1 减少DOM树的创建和遍历**
- 避免频繁创建DOM树,在需要时才创建。
- 避免对整个DOM树进行遍历,只遍历需要的部分。
- 使用XPath或其他查询语言来快速定位特定节点。
**6.1.2 优化DOM节点的操作**
- 避免频繁获取或设置节点值,使用一次性操作。
- 避免频繁添加或删除节点,使用批量操作。
- 使用DOM Level 3的DOM Mutation Events来监听节点变化,避免不必要的遍历。
### 6.2 SAX解析优化技巧
**6.2.1 减少事件处理器的数量**
- 合并多个事件处理器,减少解析器调用的次数。
- 使用SAX2的DefaultHandler类作为基类,只覆盖需要的事件。
**6.2.2 优化事件处理器的代码**
- 避免在事件处理器中进行复杂的操作,将其移到其他方法中。
- 使用缓存来存储经常使用的值,避免重复计算。
- 使用高效的数据结构,例如HashMap或ArrayList。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 XML 和 JSON 数据格式,重点关注数据交换、解析、转换、存储和管理。它涵盖了 XML 和 JSON 在 Web 服务、数据库设计和数据分析中的应用。通过揭秘 DOM、SAX、XPath 和 JSON 解析技术,专栏提供了提升数据处理效率的秘籍。它还探讨了 XML 和 JSON 数据验证、查询、更新、删除、索引、安全、压缩和性能优化方面的最佳实践。此外,专栏还强调了 XML 和 JSON 数据可视化的重要性,以增强数据分析和决策制定。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODU flex故障排查:G.7044标准下的终极诊断技巧

# 摘要
本文综述了ODU flex技术在故障排查方面的应用,重点介绍了G.7044标准的基础知识及其在ODU flex故障检测中的重要性。通过对G.7044协议理论基础的探讨,本论文阐述了该协议在故障诊断中的核心作用。同时,本文还探讨了故障检测的基本方法和高级技术,并结合实践案例分析,展示了如何综合应用各种故障检测技术解决实际问题。最后,本论文展望了故障排查技术的未来发展,强调了终
环形菜单案例分析

# 摘要
环形菜单作为用户界面设计的一种创新形式,提供了不同于传统线性菜单的交互体验。本文从理论基础出发,详细介绍了环形菜单的类型、特性和交互逻辑。在实现技术章节,文章探讨了基于Web技术、原生移动应用以及跨平台框架的不同实现方法。设计实践章节则聚焦于设计流程、工具选择和案例分析,以及设计优化对用户体验的影响。测试与评估章节覆盖了测试方法、性能安全评估和用户反馈的分析。最后,本文展望
【性能优化关键】:掌握PID参数调整技巧,控制系统性能飞跃
# 摘要
本文深入探讨了PID控制理论及其在工业控制系统中的应用。首先,本文回顾了PID控制的基础理论,阐明了比例(P)、积分(I)和微分(D)三个参数的作用及重要性。接着,详细分析了PID参数调整的方法,包括传统经验和计算机辅助优化算法,并探讨了自适应PID控制策略。针对PID控制系统的性能分析,本文讨论了系统稳定性、响应性能及鲁棒性,并提出相应的提升策略。在
系统稳定性提升秘籍:中控BS架构考勤系统负载均衡策略

# 摘要
本文旨在探讨中控BS架构考勤系统中负载均衡的应用与实践。首先,介绍了负载均衡的理论基础,包括定义、分类、技术以及算法原理,强调其在系统稳定性中的重要性。接着,深入分析了负载均衡策略的选取、实施与优化,并提供了基于Nginx和HAProxy的实际
【Delphi实践攻略】:百分比进度条数据绑定与同步的终极指南

# 摘要
本文针对百分比进度条的设计原理及其在Delphi环境中的数据绑定技术进行了深入研究。首先介绍了百分比进度条的基本设计原理和应用,接着详细探讨了Delphi中数据绑定的概念、实现方法及高级应用。文章还分析了进度条同步机制的理论基础,讨论了实现进度条与数据源同步的方法以及同步更新的优化策略。此外,本文提供了关于百分比进度条样式自定义与功能扩展的指导,并
【TongWeb7集群部署实战】:打造高可用性解决方案的五大关键步骤

# 摘要
本文深入探讨了高可用性解决方案的实施细节,首先对环境准备与配置进行了详细描述,涵盖硬件与网络配置、软件安装和集群节点配置。接着,重点介绍了TongWeb7集群核心组件的部署,包括集群服务配置、高可用性机制及监控与报警设置。在实际部署实践部分,本文提供了应用程序部署与测试、灾难恢复演练及持续集成与自动化部署
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
先锋SC-LX59:多房间音频同步设置与优化

# 摘要
本文旨在介绍先锋SC-LX59音频系统的特点、多房间音频同步的理论基础及其在实际应用中的设置和优化。首先,文章概述了音频同步技术的重要性及工作原理,并分析了影响音频同步的网络、格式和设备性能因素。随后,针对先锋SC-LX59音频系统,详细介绍了初始配置、同步调整步骤和高级同步选项。文章进一步探讨了音频系统性能监测和质量提升策略,包括音频格式优化和环境噪音处理。最后,通过案例分析和实战演练,展示了同步技术在多品牌兼容性和创新应用
【S参数实用手册】:理论到实践的完整转换指南
# 摘要
本文系统阐述了S参数的基础理论、测量技术、在射频电路中的应用、计算机辅助设计以及高级应用和未来发展趋势。第一章介绍了S参数的基本概念及其在射频工程中的重要性。第二章详细探讨了S参数测量的原理、实践操作以及数据处理方法。第三章分析了S参数在射频电路、滤波器和放大器设计中的具体应用。第四章进一步探讨了S参数在CAD软件中的集成应用、仿真优化以及数据管理。第五章介绍了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )