文本相似度计算方法概述与应用场景解析
发布时间: 2024-04-06 21:41:41 阅读量: 100 订阅数: 41 

基于微信小程序的社区门诊管理系统php.zip
# 1. 引言
在本章中,将介绍文本相似度计算方法的课题背景和意义,概念及作用,以及研究现状概述。首先,我们将深入探讨文本相似度计算在当今信息技术领域中的重要性和应用场景。
# 2. 文本相似度计算方法分类
文本相似度计算方法可以根据其计算原理和特点进行分类,主要包括以下几种类型:
### 2.1 基于词汇的文本相似度计算方法
基于词汇的文本相似度计算方法主要通过比较文本中的词汇信息来判断文本之间的相似程度。常见的方法包括词袋模型(Bag of Words,简称BoW)、词频-逆文档频率(Term Frequency-Inverse Document Frequency,简称TF-IDF)等。这些方法通常通过构建文本特征向量,利用向量之间的相似度度量来实现文本相似度计算。
### 2.2 基于语法结构的文本相似度计算方法
基于语法结构的文本相似度计算方法则关注文本之间的句法结构和组织方式,通过比较句子结构、语法树或者依存关系来判断文本的相似度。这种方法通常需要进行句法分析和结构化处理,常见的应用包括基于句法树的相似度计算和基于依存关系的相似度计算等。
### 2.3 基于语义的文本相似度计算方法
基于语义的文本相似度计算方法致力于理解文本的语义含义,通过比较文本的语义信息来衡量文本之间的相似度。常见的方法包括词向量化(Word Embedding)技术,如Word2Vec、GloVe等,以及语义匹配模型,如Siamese神经网络等。这些方法能够捕捉词语之间的语义关系,有助于提高文本相似度计算的准确度。
### 2.4 深度学习在文本相似度计算中的应用
近年来,随着深度学习技术的快速发展,深度学习在文本相似度计算领域也得到了广泛应用。诸如卷积神经网络(CNN)、循环神经网络(RNN)、注意力机制(Attention)等深度学习模型被应用于文本相似度计算任务中,取得了许多成功的应用案例。这些模型能够从大规模文本数据中学习语义表示,提高文本相似度计算的效果和效率。
通过以上分类,我们可以更好地了解不同类型的文本相似度计算方法及其在实际应用中的优缺点,为选择合适的方法提供参考。
# 3. 常见文本相似度计算算法解析
在文本相似度计算中,常用的算法包括余弦相似度算法、Jaccard相似度算法、编辑距离算法和Word Mover's Distance算法。下面将对这些算法进行详细解析。
#### 3.1 余弦相似度算法
余弦相似度是通过计算两个向量之间的夹角余弦值来衡量它们的相似度。在文本相似度计算中,可以将文本表示为向量,常用的表示方法包括词袋模型、TF-IDF等。通过计算文本向量之间的余弦相似度,可以评估它们之间的相似程度。
```python
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 两个文本
text1 = "This is a sample text for calculating cosine similarity"
text2 = "This is another sample text for calculating similarity"
# 构建词袋模型
vectorizer = CountVectorizer().fit_transform([text1, text2])
# 计算余弦相似度
cosine_sim = cosine_similarity(vectorizer)
print("Cosine Similarity between text1 and text2:", cosine_sim[0][1])
```
通过余弦相似度算法,可以得到text1和text2之间的相似度值。
#### 3.2 Jaccard相似度算法
Jaccard相似度是通过计算两个集合的交集与并集的比值来衡量它们的相似度。在文本相似度计算中,可以将文本转换为词语的集合,然后计算这些词语集合之间的Jaccard相似度。
```python
# 两个文本
text1 = set("apple banana mango".split())
text2 = set("banana orange mango".split())
# 计算Jaccard相似度
jaccard_sim = len(text1.intersection(text2)) / len(text1.union(text2))
print("Jaccard Similarity between text1 and text2:", jaccard_sim)
```
通过Jaccard相似度算法,可以得到text1和text2之间的相似度值。
#### 3.3 编辑距离算法
编辑距离是衡量两个字符串之间相似程度的方法,通过插入、删除和替换等操作将一个字符串转换为另一个字符串所需的最小操作次数来计算相似度。编辑距离算法常用于拼写纠错、信息检索等领域。
```python
def edit_distance(str1, str2):
m, n = len(str1), len(str2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 初始化边界
for i in range(m + 1):
dp[i][0] = i
for j in range(n + 1):
dp[0][j] = j
for i in range(1, m + 1):
for j in range(1, n + 1):
if str1[i - 1] == str2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1]) + 1
return dp[m][n]
str1 = "kitten"
str2 = "sitting"
distance = edit_distance(str1, str2)
print("Edit Distance between 'kitten' and 'sitting':", distance)
```
编辑距离算法可以计算出两个字符串之间的编辑距离,从而评估它们的相似度。
#### 3.4 Word Mover's Distance算法
Word Mover's Distance是一种基于词向量的文本相似度计算方法,通过衡量两个文本之间每个词向量之间的距离来计算它们之间的相似度。Word Mover's Distance算法通常用于处理长文本之间的相似度计算。
```python
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import euclidean_distances
# 两个文本
text1 = "king is a strong man"
text2 = "queen is a wise woman"
# 构建词袋模型
vectorizer = CountVectorizer().fit_transform([text1, text2])
# 计算词语间的欧氏距离
euclidean_dist = euclidean_distances(vectorizer)
# 计算Word Mover's Distance
word_mover_dist = euclidean_dist[0][1]
print("Word Mover's Distance between text1 and text2:", word_mover_dist)
```
通过Word Mover's Distance算法,可以得到text1和text2之间的相似度值。
# 4. 文本相似度计算的应用场景
在文本相似度计算中,有许多广泛的应用场景,这些场景涵盖了多个领域,如搜索引擎、情感分析、推荐系统和自然语言处理,下面将对这些应用场景进行详细解析。
### 4.1 文本相似度搜索引擎
文本相似度搜索引擎是应用文本相似度计算的一种典型场景。它可以通过分析用户输入的文本内容,与数据库中的文本数据进行相似度比对,从而返回最相关的文本信息。这种搜索引擎在信息检索、问答系统等领域有着重要的应用,能够帮助用户快速准确地获取所需信息。
```python
# 示例代码:文本相似度搜索引擎
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 假设存在一个文本数据库 texts
texts = ['Python is a popular programming language',
'Java is widely used for enterprise applications',
'Machine learning is a branch of artificial intelligence']
# 用户输入的查询文本
query = 'Python programming language'
# 计算TF-IDF向量
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(texts + [query])
# 计算余弦相似度
similarity = cosine_similarity(tfidf)[-1][:-1]
# 返回与查询文本最相似的文本
most_similar_idx = similarity.argmax()
most_similar_text = texts[most_similar_idx]
print(f'Most similar text to the query: {most_similar_text}')
```
上述代码演示了如何使用TF-IDF向量和余弦相似度进行文本相似度搜索,找到与用户查询文本最相似的文本数据。
### 4.2 情感分析与情感相似度计算
情感分析是通过对文本内容进行分析,判断其中蕴含的情感倾向,如积极、消极或中性。情感相似度计算则可以用来比较文本之间的情感倾向程度,帮助企业或研究人员了解用户对特定主题或产品的情感态度。
```java
// 示例代码:情感分析与情感相似度计算
import org.apache.commons.text.similarity.CosineSimilarity;
String text1 = "I love this product, it's amazing!";
String text2 = "This product is great, I really like it.";
CosineSimilarity cosineSimilarity = new CosineSimilarity();
double similarityScore = cosineSimilarity.cosineSimilarity(text1, text2);
System.out.println("Similarity score between the two texts: " + similarityScore);
```
以上Java示例展示了如何使用余弦相似度计算文本之间的情感相似度,可以根据相似度分数来判断两个文本内容的情感倾向程度。
### 4.3 文本推荐系统中的应用
文本推荐系统利用文本相似度计算来为用户推荐与其兴趣相似的文章、新闻或产品。通过分析用户历史浏览或点击的文本内容,系统可以找到与之相似的文本并进行推荐,提升用户体验和内容推广效果。
```javascript
// 示例代码:文本推荐系统中的文本相似度计算
const articles = ['How to learn Python programming effectively',
'Top 10 JavaScript frameworks for web development',
'The benefits of using ReactJS for front-end development'];
const userInterests = ['Python programming', 'web development'];
// 找到与用户兴趣最相关的文章
const recommendedArticle = articles.reduce((prev, curr) => {
// 计算文章标题与用户兴趣的相似度,这里采用简单的包含匹配
const similarityScore = userInterests.filter(interest => curr.includes(interest)).length;
return similarityScore > prev.similarity ? {article: curr, similarity: similarityScore} : prev;
}, {article: '', similarity: 0});
console.log(`Recommended article based on user interests: ${recommendedArticle.article}`);
```
上述JavaScript代码展示了如何基于用户兴趣与文章内容进行相似度匹配,从而为用户推荐最相关的文章内容。
### 4.4 文本相似度在自然语言处理中的应用
文本相似度计算在自然语言处理中有着广泛的应用,如语义匹配、信息抽取、对话系统等。通过衡量不同文本之间的相似度,可以帮助机器理解自然语言文本,实现自然语言处理任务中的文本匹配和推理。
以上是文本相似度计算在不同场景下的应用,从搜索引擎到情感分析再到推荐系统,文本相似度计算方法在各个领域都发挥着重要作用,为文本数据的处理和应用提供了有效的解决方案。
# 5. 文本相似度计算方法的评估
在文本相似度计算中,评估方法对于验证算法的准确性和效果至关重要。本章将介绍文本相似度计算方法的评估指标及方法,并进行实验设计与结果分析。
### 5.1 评估指标及方法
在文本相似度计算中,常用的评估指标包括但不限于:
- 精确率 (Precision):精确率是指检索出的相关文档数与所有检索出的文档数的比值。
- 召回率 (Recall):召回率是指检索出的相关文档数与文档库中所有的相关文档数的比值。
- F1值 (F1-score):综合考虑精确率和召回率,F1值是精确率和召回率的调和平均数。
- ROC曲线 (Receiver Operating Characteristic curve):ROC曲线是以假正例率为纵轴,真正例率为横轴的曲线,评价分类器的性能。
- AUC值 (Area Under Curve):AUC值是ROC曲线下方的面积,用于表示分类器的性能。
评估方法通常包括构建测试集和训练集,通过对测试集进行文本相似度计算,并与标准结果进行比对来评估算法的准确性和效果。
### 5.2 实验设计与结果分析
在评估文本相似度计算方法时,需要设计合理的实验方案和评估指标,以确保评估结果准确可靠。
实验设计应考虑以下几个方面:
1. 数据集的选择:应选择包含各种文本类型和长度的数据集,以确保算法对不同文本情况的适用性。
2. 对比算法的选择:需要选择与所研究算法相关的对比算法进行比较,以验证算法的优越性。
3. 参数设置:对于需要调参的算法,应进行合理的参数设置和调优。
实验结果分析包括对比实验结果与对比算法的性能表现,评估算法的优劣以及可能存在的改进空间,为进一步优化文本相似度计算方法提供依据。
通过科学严谨的实验设计和结果分析,可以全面评估文本相似度计算方法的有效性和可靠性,为后续研究和应用提供参考。
# 6. 未来发展趋势与展望
在文本相似度计算领域,随着人工智能和自然语言处理技术的不断发展,未来有许多令人振奋的发展趋势和展望。以下是一些可能的发展方向和展望:
### 6.1 文本相似度计算方法的发展方向
- **增强深度学习在文本相似度计算中的应用**:随着深度学习技术的不断成熟,未来有望进一步提升文本相似度计算的准确性和效率。
- **结合多模态信息进行文本相似度计算**:将文本、图像、视频等多模态信息进行融合,能够更准确地捕捉文本之间的相似度。
- **探索基于知识图谱的文本相似度计算方法**:利用知识图谱的丰富语义信息,可以提升文本相似度计算的语义理解能力。
### 6.2 可能的技术突破与挑战
- **解决文本长度不一致带来的挑战**:针对长短文本混合的情况,如何更好地进行文本相似度计算是一个挑战。
- **提高对文本语义的理解能力**:如何更好地捕捉文本之间的语义信息,是文本相似度计算的技术突破点之一。
- **处理领域特定语境下的文本相似度计算**:不同领域的文本相似度计算可能需要考虑不同的语境信息,如何有效处理这一问题也是一个挑战。
### 6.3 文本相似度计算在人工智能领域的应用前景
- **智能搜索与推荐系统**:借助文本相似度计算,可以为用户提供更加智能化的搜索和推荐体验。
- **智能对话系统**:文本相似度计算在智能对话系统中具有重要作用,未来将有望实现更加自然、智能的对话交互。
- **个性化学习与知识图谱构建**:文本相似度计算有助于构建个性化学习模型和知识图谱,为用户提供更加个性化的学习和知识服务。
综合以上展望和挑战,文本相似度计算领域在未来将有望取得更加显著的成果,为人工智能领域的发展带来新的动力和机遇。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析了文本相似度计算的三种常用方法:Cosine、Jaccard和Edit Distance。它深入探讨了每种方法的原理、算法实现和应用场景。专栏还提供了详细的示例和代码演示,帮助读者理解和应用这些方法。此外,它还涵盖了优化文本相似度计算的技巧,例如数据预处理、降维和算法优化。本专栏适合数据科学家、工程师和任何需要评估文本相似度的人员,提供了对这一重要领域的全面理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#网络编程揭秘】:TCP_IP与UDP通信机制全解析
# 摘要
本文全面探讨了C#网络编程的基础知识,深入解析了TCP/IP架构下的TCP和UDP协议,以及高级网络通信技术。首先介绍了C#中网络编程的基础,包括TCP协议的工作原理、编程模型和异常处理。其次,对UDP协议的应用与实践进行了讨论,包括其特点、编程模型和安全性分析。然后,详细阐述了异步与同步通信模型、线程管理,以及TLS/SSL和NAT穿透技术在C#中的应用。最后,通过实战项目展示了网络编程的综合应用,并讨论了性能优化、故障排除和安全性考量。本文旨在为网络编程人员提供详尽的指导和实用的技术支持,以应对在实际开发中可能遇到的各种挑战。
# 关键字
C#网络编程;TCP/IP架构;TCP
深入金融数学:揭秘随机过程在金融市场中的关键作用

# 摘要
随机过程理论是分析金融市场复杂动态的基础工具,它在期权定价、风险管理以及资产配置等方面发挥着重要作用。本文首先介绍了随机过程的定义、分类以及数学模型,并探讨了模拟这些过程的常用方法。接着,文章深入分析了随机过程在金融市场中的具体应用,包括Black-Scholes模型、随机波动率模型、Value at Risk (VaR)和随机控制理论在资产配置中的应
CoDeSys 2.3中文教程高级篇:自动化项目中面向对象编程的5大应用案例
# 摘要
本文全面探讨了面向对象编程(OOP)的基础理论及其在CoDeSys 2.3平台的应用实践。首先介绍面向对象编程的基本概念与理论框架,随后深入阐释了OOP的三大特征:封装、继承和多态,以及设计原则,如开闭原则和依赖倒置原则。接着,本文通过CoDeSys 2.3平台的实战应用案例,展示了面向对象编程在工业自动化项目中
【PHP性能提升】:专家解读JSON字符串中的反斜杠处理,提升数据清洗效率
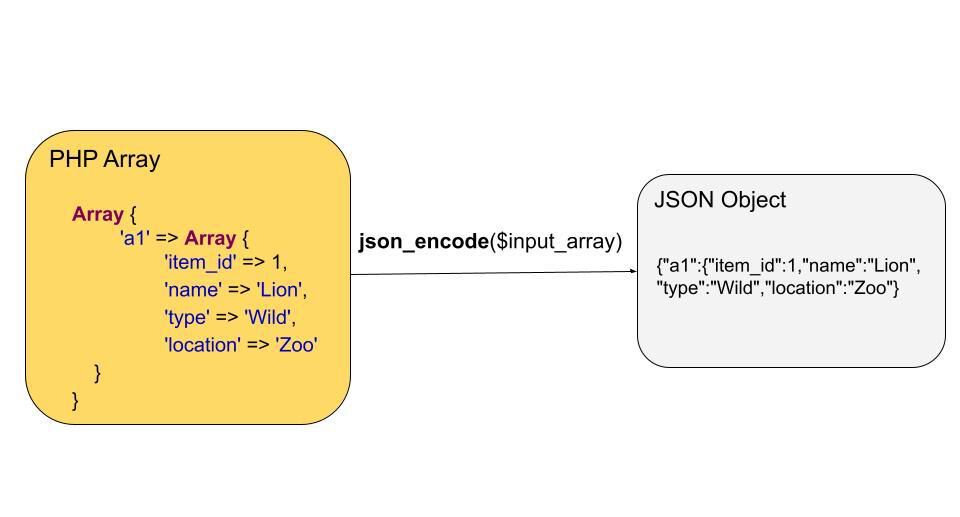
# 摘要
本文深入探讨了在PHP环境中处理JSON字符串的重要性和面临的挑战,涵盖了JSON基础知识、反斜杠处理、数据清洗效率提升及进阶优化等关键领域。通过分析JSON数据结构和格式规范,本文揭示了PHP中json_encode()和json_decode()函数使用的效率和性能考量。同时,本文着重讨论了反斜杠在JSON字符串中的角色,以及如何高效处理以避免常见的数据清洗性能
成为行业认可的ISO 20653专家:全面培训课程详解

# 摘要
ISO 20653标准作为铁路行业的关键安全规范,详细规定了安全管理和风险评估流程、技术要求以及专家认证路径。本文对ISO 20653标准进行了全面概述,深入分析了标准的关键要素,包括其历史背景、框架结构、安全管理系统要求以及铁路车辆安全技术要求。同时,本文探讨了如何在企业中实施ISO 20653标准,并分析了在此过程中可能遇到的挑战和解决方案。此外,文章还强调了持续专业发展的重要性
Arm Compiler 5.06 Update 7实战指南:专家带你玩转LIN32平台性能调优

# 摘要
本文详细介绍了Arm Compiler 5.06 Update 7的特点及其在不同平台上的性能优化实践。文章首先概述了Arm架构与编译原理,并针对新版本编译器的新特性进行了深入分析。接着,介绍了如何搭建编译环境,并通过编译实践演示了基础用法。此外,文章还
【62056-21协议深度解析】:构建智能电表通信系统的秘诀
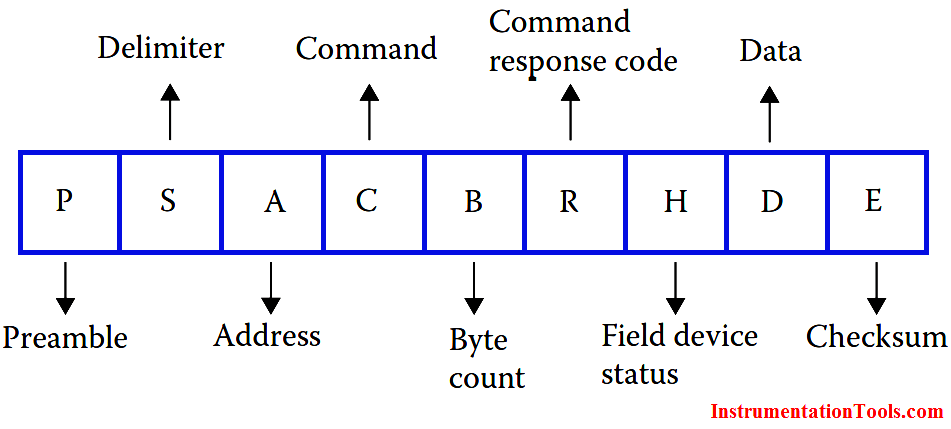
# 摘要
本文对62056-21通信协议进行了全面概述,分析了其理论基础,包括帧结构、数据封装、传输机制、错误检测与纠正技术。在智能电表通信系统的实现部分,探讨了系统硬件构成、软件协议栈设计以及系统集成与测试的重要性。此外,本文深入研究了62056-21协议在实践应用中的案例分析、系统优化策略和安全性增强措
5G NR同步技术新进展:探索5G时代同步机制的创新与挑战

# 摘要
本文全面概述了5G NR(新无线电)同步技术的关键要素及其理论基础,探讨了物理层同步信号设计原理、同步过程中的关键技术,并实践探索了同步算法与
【天龙八部动画系统】:骨骼动画与精灵动画实现指南(动画大师分享)
# 摘要
本文系统地探讨了骨骼动画与精灵动画的基本概念、技术剖析、制作技巧以及融合应用。文章从理论基础出发,详细阐述了骨骼动画的定义、原理、软件实现和优化策略,同时对精灵动画的分类、工作流程、制作技巧和高级应用进行了全面分析。此外,本文还探讨了骨骼动画与精灵动画的融合点、构建跨平台动画系统的策略,并通过案例分
【Linux二进制文件执行权限问题快速诊断与解决】:一分钟搞定执行障碍
# 摘要
本文针对Linux环境下二进制文件执行权限进行了全面的分析,概述了权限的基本概念、构成和意义,并探讨了执行权限的必要性及其常见问题。通过介绍常用的权限检查工具和方法,如使用`ls`和`stat`命令,文章提供了快速诊断执行障碍的步骤和技巧,包括文件所有者和权限设置的确认以及脚本自动化检查。此外,本文还深入讨论了特殊权限位、文件系统特性、非标准权限问题以及安全审计的重要性。通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )