【ROI数据处理实战】:ITK框架下文件保存与恢复的10大黄金法则
发布时间: 2025-01-02 16:21:06 阅读量: 7 订阅数: 8 

026-SVM用于分类时的参数优化,粒子群优化算法,用于优化核函数的c,g两个参数(SVM PSO) Matlab代码.rar

# 摘要
本文详细探讨了在ITK框架下进行ROI数据处理的文件保存与恢复技术,涵盖了文件保存和恢复的基础知识、高级技术以及异常处理机制。通过深入分析不同格式文件的保存与恢复特性,本文提供了关于数据完整性、性能优化以及可扩展性和兼容性的黄金法则,并通过实战案例分析展示了这些法则在实际项目中的应用及效果。文章还讨论了ITK框架未来的发展趋势,为提高ROI数据处理效率和安全性提供了指导性建议。
# 关键字
ROI数据处理;ITK框架;文件保存;文件恢复;性能优化;异常处理
参考资源链接:[ENVI ROI恢复教程:导入和操作ROI文件详解](https://wenku.csdn.net/doc/5dp0rhs7kp?spm=1055.2635.3001.10343)
# 1. ROI数据处理与ITK框架概述
在现代IT行业中,数据处理和分析是核心竞争力之一。ROI(Return on Investment)数据处理,即投资回报率数据处理,是帮助企业和组织评估其投资效益的关键手段。而在这个过程中,ITK(Insight Segmentation and Registration Toolkit)框架作为一种强大的开源工具,被广泛用于医学影像的处理和分析。它不仅提供了丰富的数据处理功能,而且在提高ROI数据处理的准确性和效率方面,展现出强大的潜力。本章将探讨ROI数据处理的重要性和复杂性,并对ITK框架进行概述,为读者奠定后续章节深入分析的基础。
# 2. ITK框架下的文件保存机制
## 2.1 文件保存基础
### 2.1.1 ITK文件保存类的使用方法
在ITK框架中,文件保存主要依赖于一系列的文件保存类,这些类是ITK库提供的功能强大且易于使用的API。其中最为基础的类是`itk::ImageIOBase`,它提供了一套接口用于读取和写入图像数据。文件保存类如`itk::ImageFileWriter`和`itk::ImageSeriesWriter`等,它们在底层都继承自`itk::ImageIOBase`。这些类遵循面向对象的设计原则,使得文件的保存过程既灵活又可扩展。
要使用这些文件保存类,通常的步骤包括创建一个文件保存对象实例,设置相关参数如文件路径、格式和图像IO对象,最后调用`Update()`方法开始保存过程。例如:
```cpp
itk::ImageFileWriter<ImageType>::Pointer imageWriter = itk::ImageFileWriter<ImageType>::New();
imageWriter->SetFileName("outputImage.png");
imageWriter->SetInput(image); // image 是要保存的图像对象
imageWriter->Update();
```
### 2.1.2 不同格式文件保存的特性与选择
ITK支持多种文件格式,包括但不限于DICOM、PNG、JPEG、BMP、TIFF和NIFTI等。不同的格式拥有各自的优势,适用于不同的应用场景。例如,DICOM格式常用于医疗图像的存储和传输,而NIFTI格式则常用于神经影像研究。
选择合适的文件格式是一个需要考虑多方面因素的过程。首先是文件大小,某些格式如PNG或JPEG支持压缩,可以节省磁盘空间。其次,图像质量也是重要的考量因素,无损格式如BMP和TIFF可以保证图像质量不受损失。最后,通用性和兼容性也是决策的一部分,DICOM格式就因其广泛的应用而成为一个好的选择。
在实际应用中,开发者需要根据具体的应用场景和需求来选择合适的文件格式。例如,在医学影像领域,可能会优先选择支持元数据保存的DICOM格式,而在一般的图像处理和分析中,可能会选择压缩率更高或读写速度更快的格式。
## 2.2 文件保存的高级技术
### 2.2.1 使用过滤器进行文件保存
在ITK中,使用过滤器(Filter)进行文件保存是常见的高级技术之一。过滤器可以处理和转换图像数据,在保存之前对数据进行必要的预处理。例如,`itk::ResampleImageFilter`可以调整图像的分辨率和尺寸,而`itk::CastImageFilter`可以改变图像的数据类型。
通过将文件保存类与其他处理过滤器链式连接,可以实现数据在保存前的一系列转换,满足特定的保存需求。过滤器处理后的图像对象直接传递给文件保存对象,保存过程如下:
```cpp
itk::ResampleImageFilter<ImageType, ImageType>::Pointer resampleFilter = itk::ResampleImageFilter<ImageType, ImageType>::New();
// 设置resampleFilter的参数...
itk::ImageFileWriter<ImageType>::Pointer imageWriter = itk::ImageFileWriter<ImageType>::New();
imageWriter->SetFileName("outputImage.png");
imageWriter->SetInput(resampleFilter->GetOutput()); // 连接resampleFilter的输出到imageWriter
imageWriter->Update();
```
### 2.2.2 文件保存过程中的内存管理
在处理大型图像数据时,文件保存过程中的内存管理至关重要。ITK框架提供了一些机制来优化内存使用,包括图像分块(chunking)和延迟加载(Lazy Loading)。图像分块是指将大图像分割成多个小块分别进行处理和保存,这样可以有效减少内存的消耗。
开发者可以利用`itk::ImageRegion`来定义图像的分块区域,只加载和保存当前处理的图像块。另外,ITK还允许开发者通过继承和实现`itk::Object`类中的`New()`, `Delete()`方法来自定义内存管理策略。
### 2.2.3 优化文件保存性能的策略
性能优化是一个持续的过程,涉及到代码优化、硬件配置和算法选择等多个方面。在文件保存这一环节,开发者可以采取一些策略来提高性能。
**并行IO:** 利用多线程或多进程并行处理,可以显著提高文件保存的速度。ITK提供了一些并行IO的接口,开发者可以利用这些接口将文件保存操作并行化。
**分块写入:** 如前所述,通过分块写入的方式可以减少内存消耗和提高IO速度。
**异步写入:** 对于允许异步操作的文件系统,开发者可以使用异步写入的方式来提高性能。通过ITK的异步IO接口,可以在不阻塞主线程的情况下进行文件保存。
```cpp
itk::ImageFileWriter<ImageType>::Pointer imageWriter = itk::ImageFileWriter<ImageType>::New();
imageWriter->SetFileName("outputImage.png");
imageWriter->SetUseLazyEvaluation(true); // 开启异步写入
imageWriter->Update();
```
## 2.3 文件保存的异常处理
### 2.3.1 常见文件保存错误与诊断
在文件保存过程中,可能会遇到多种错误,例如权限问题、磁盘空间不足、格式不支持或文件损坏等。开发者需要对这些常见错误进行诊断和处理。
诊断这些错误,首先需要捕捉ITK抛出的异常,例如`itk::ExceptionObject`。这可以通过try-catch块实现:
```cpp
try {
// 文件保存代码
} catch (itk::ExceptionObject & err) {
std::cerr << "Error saving file: " << err << std::endl;
// 进一步处理错误
}
```
### 2.3.2 文件保存异常处理机制
异常处理机制是保障程序稳定运行的重要组成部分。在文件保存过程中,开发者需要遵循良好的异常处理策略,确保程序能够优雅地处理任何可能发生的异常。
一种常见的异常处理机制是在文件保存前后进行资源检查和清理。例如,在保存操作之前检查文件路径是否有效,磁盘空间是否足够等。保存操作后,确保释放所有占用的资源,如打开的文件句柄等。
此外,开发者还可以提供用户友好的错误提示信息,确保用户能够理解错误的原因,并指导用户如何解决问题。在ITK框架中,可以通过继承并重写异常处理函数来实现自定义的错误处理逻辑。
```cpp
class CustomImageFileWriter : public itk::ImageFileWriter<ImageType>
{
public:
void GenerateError() ITKoverride {
// 自定义错误处理逻辑
}
};
```
通过上述机制,文件保存过程中的异常可以得到有效管理和控制,从而提高程序的稳定性和用户体验。
# 3. ITK框架下的文件恢复技术
## 3.1 文件恢复基础
### 3.1.1 ITK文件读取类的使用方法
在ITK(Insight Segmentation and Registration Toolkit)框架下,文件的恢复是数据处理的重要组成部分,尤其在处理医学影像数据时。要正确恢复数据,开发者首先需要熟悉ITK框架提供的文件读取类。ITK通过一系列的文件读取类来支持不同格式的文件恢复,这些类都是从基类`ImageIOBase`派生出来的。
例如,`PNGImageIO`用于读取PNG格式的图像,`JPEGImageIO`用于读取JPEG格式的图像。使用这些类时,通常的流程是创建一个读取器对象,指定要读取的文件名,然后调用读取方法。这里提供了一个基本的代码示例:
```cpp
#include <itkImageIOBase.h>
#include <itkImageFileReader.h>
#include <itkPNGImageIO.h>
int main(int argc, char* argv[])
{
if (argc < 2)
{
std::cerr << "Usage: " << argv[0] << " InputFileName" << std::endl;
return EXIT_FAILURE;
}
const char * inputFileName = argv[1];
itk::ImageIOBase::Pointer imageIO = itk::ImageIOFactory::CreateImageIO(inputFileName, itk::ImageIOFactory::ReadMode);
if (imageIO)
{
imageIO->SetFileName(inputFileName);
if (!imageIO->CanReadFile())
{
std::cerr << "Can't read file: " << inputFileName << std::endl;
return EXIT_FAILURE;
}
itk::ImageFileReader<itk::Image<float, 3> >::Pointer imageReader = itk::ImageFileReader<itk::Image<float, 3> >::New();
imageReader->SetImageIO(imageIO);
imageReader->SetFileName(inputFileName);
try
{
imageReader->Update();
}
catch (itk::ExceptionObject& error)
{
std::cerr << "Error while reading the image file: " << inputFileName << std::endl;
std::cerr << error << std::endl;
return EXIT_FAILURE;
}
// Retrieve the recovered image from the reader
itk::Image<float, 3>::Pointer image = imageReader->GetOutput();
// Now image contains the read data from the file
}
else
{
std::cerr << "Could not create an ImageIO object to read the file: " << inputFileName << std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
```
上述代码首先尝试根据文件名创建一个适合的`ImageIO`对象,然后验证是否可以读取该文件,并使用`ImageFileReader`来读取数据。
### 3.1.2 不同格式文件恢复的特性与选择
在ITK框架中,存在多种不同类型的图像格式,每种格式都有其特定的用途和特性。例如,`DICOM`格式常用于医学影像,因为该格式能够存储丰富的元数据信息,而`PNG`和`JPEG`格式则更适合处理网络图像或需要压缩的情况。开发者需要根据实际需求选择合适的文件格式进行恢复。
选择合适的文件恢复方法时,需要考虑以下因素:
- **文件大小**:对于大尺寸的文件,可能需要选择一种具有高效压缩比的格式来减少内存占用。
- **元数据支持**:对于需要保持完整元数据的应用,如医学图像处理,需要选择能够完整恢复元数据信息的格式。
- **性能要求**:不同的恢复方法在性能上可能有所差异,例如,一些文件格式可能在恢复时更快,但可能会消耗更多的计算资源。
开发者应该根据具体应用场景的需求,权衡以上因素,选择最适合的文件恢复方法。
## 3.2 文件恢复的高级技术
### 3.2.1 使用过滤器进行文件恢复
在ITK框架中,除了使用基础的文件读取类外,还可以通过过滤器来执行文件恢复操作。过滤器是ITK中用于图像处理的一类对象,它们可以接收输入图像、进行处理,并产生输出图像。
使用`ImageFileReader`作为例子,它可以被用作一个过滤器来读取文件:
```cpp
// Create the reader and connect the input
itk::ImageFileReader<itk::Image<float, 3> >::Pointer reader = itk::ImageFileReader<itk::Image<float, 3> >::New();
reader->SetFileName(inputFileName);
// Connect the output of the reader to the input of another filter
// For example, another filter can be connected to the reader for further processing.
```
### 3.2.2 文件恢复过程中的数据完整性验证
在文件恢复过程中,数据完整性验证是至关重要的一步。开发者需要确保恢复的数据与原始数据保持一致,没有发生损坏或者信息丢失。ITK提供了多种机制来验证图像数据的完整性,比如比较图像元数据、像素值等。
以下是一个简单的数据完整性验证示例:
```cpp
itk::ImageFileReader<itk::Image<float, 3> >::Pointer reader = itk::ImageFileReader<itk::Image<float, 3> >::New();
reader->SetFileName("recoveredImage.nii");
try
{
reader->Update();
}
catch (itk::ExceptionObject& e)
{
std::cerr << "Error during file recovery:" << e.what() << std::endl;
}
// Assume we have the original image available for comparison
itk::Image<float, 3>::Pointer originalImage = reader->GetOutput();
// Verify the dimensions match
if(originalImage->GetLargestPossibleRegion().GetNumberOfPixels() != recoveredImage.GetLargestPossibleRegion().GetNumberOfPixels())
{
std::cerr << "Error: Image size mismatch!" << std::endl;
}
```
### 3.2.3 优化文件恢复性能的策略
文件恢复性能优化是一个复杂的话题,因为它涉及到I/O子系统、操作系统缓存、以及底层硬件的性能。ITK开发者可以采取以下策略来提升恢复性能:
- **并发I/O操作**:使用多线程或异步I/O操作来增加读取效率。
- **缓存策略**:合理利用操作系统的文件缓存机制。
- **选择合适的文件格式**:某些文件格式因为压缩比高或者存储格式简洁,所以读取速度快。
- **内存管理**:合理分配内存,减少内存拷贝次数,可以显著提升性能。
## 3.3 文件恢复的异常处理
### 3.3.1 常见文件恢复错误与诊断
在进行文件恢复时,可能遇到多种错误。常见的错误包括但不限于:
- **文件不存在**:指定的文件名不正确或文件被删除。
- **文件格式错误**:尝试用不支持的格式读取文件。
- **权限问题**:没有足够的权限读取文件。
- **文件损坏**:文件在存储过程中损坏。
每种错误都需要不同的处理方式。例如,如果遇到文件不存在的错误,开发者可以检查文件路径是否正确,以及文件是否已经被移动或者删除。如果遇到文件格式错误,可以检查文件扩展名是否正确,并且图像I/O是否支持该格式。
### 3.3.2 文件恢复异常处理机制
为了处理这些潜在的错误,开发者必须在代码中实现异常处理机制。在ITK中,异常可以通过捕获`itk::ExceptionObject`来处理,异常信息可以通过`what()`方法获得。
```cpp
try
{
reader->Update();
}
catch (itk::ExceptionObject& e)
{
std::cerr << "Error during file recovery:" << e.what() << std::endl;
}
```
以上代码块展示了如何在文件恢复过程中使用异常处理。如果出现错误,将通过标准错误输出捕获错误信息。
通过合理的错误处理和验证,可以确保文件恢复的稳定性和可靠性,从而在ITK框架下进行高效的数据处理。
# 4. ROI数据处理的黄金法则
## 4.1 数据完整性与准确性法则
### 4.1.1 数据校验方法与应用
数据校验是确保ROI数据处理流程中数据准确性和完整性的基石。在数据传输、存储及处理过程中,通过引入校验机制可以及时发现并纠正数据错误,保障数据质量。常见的数据校验方法包括但不限于:
- **校验和(Checksum)**:计算数据的校验和值,并与预期值进行比较。如发生数据损坏或篡改,校验和将发生变化。
- **哈希函数(Hash Function)**:将数据映射为固定长度的哈希值,用于验证数据的完整性。例如,MD5和SHA系列哈希算法。
- **数字签名(Digital Signature)**:用于验证数据来源的可信性,保证数据在传输过程中未被篡改。
- **重复检测(Redundancy Detection)**:通过多次存储相同数据或计算冗余信息,可以检测和纠正单点故障。
应用数据校验方法时,开发者需根据ROI数据处理的实际需求选择合适的校验策略。例如,在高可用性需求场景中,可以结合校验和和哈希函数进行数据完整性验证;在安全性要求极高的系统中,可引入数字签名机制来增加数据传输的安全性。
### 4.1.2 确保数据完整性的关键步骤
为确保ROI数据处理流程中数据的完整性,关键步骤如下:
- **数据采集验证**:在数据源端,使用校验和对采集到的数据进行校验。
- **数据传输校验**:在数据传输过程中,通过哈希算法验证数据包的一致性。
- **存储后校验**:数据存储到数据库或文件系统后,使用校验和或哈希值对比,确认数据的准确性。
- **定期校验**:周期性地对存储的数据进行校验和计算,以检测数据的长期稳定性。
- **异常处理机制**:设置异常处理机制,在校验失败时进行错误报告和数据恢复。
### 4.1.3 代码示例
下面是一个简单使用MD5校验和进行文件完整性验证的Python示例:
```python
import hashlib
def generate_md5(file_path):
md5 = hashlib.md5()
with open(file_path, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b""):
md5.update(chunk)
return md5.hexdigest()
def verify_file(file_path, md5_hash):
generated_hash = generate_md5(file_path)
return generated_hash == md5_hash
# 文件路径和预期的MD5哈希值
file_path = "path/to/your/file"
expected_md5 = "expected_md5_value"
# 执行验证
if verify_file(file_path, expected_md5):
print("文件校验成功,完整性良好。")
else:
print("文件校验失败,数据可能已损坏。")
```
通过以上代码,我们可以对文件进行MD5校验和生成,然后与预期值进行比对,确保数据的完整性。当数据完整时,我们可以信心满满地在ROI数据处理中使用这些数据,以确保数据处理结果的准确性。
## 4.2 性能优化法则
### 4.2.1 提升ROI数据处理效率的策略
提升ROI数据处理效率的关键在于最大化资源的利用,减少不必要的计算开销,并优化数据流程。以下是一些提升ROI数据处理效率的策略:
- **缓存策略**:对频繁访问的数据实施缓存机制,减少重复计算和数据库查询。
- **并行处理**:通过多线程或多进程,并行处理数据,加快数据处理速度。
- **算法优化**:选择或设计时间复杂度较低的算法,减少数据处理过程中的时间开销。
- **I/O优化**:优化I/O操作,例如,批处理I/O请求,减少磁盘I/O的延迟。
- **利用硬件加速**:针对图形处理,可以利用GPU并行计算能力,对数据进行快速处理。
### 4.2.2 性能监控与瓶颈分析
性能监控和瓶颈分析是提升ROI数据处理效率的重要手段。通过监控工具和性能分析器,开发者可以:
- **监控关键性能指标**:包括CPU使用率、内存占用、I/O吞吐量、网络响应时间等。
- **记录日志**:记录数据处理过程中的关键操作和状态,方便问题定位和性能分析。
- **使用分析工具**:利用性能分析工具,如Valgrind、gperftools等,对数据处理过程进行深入分析。
- **瓶颈定位**:识别处理过程中的性能瓶颈,如内存泄漏、死锁、I/O阻塞等。
### 4.2.3 代码示例
以下是一个使用Python多线程并行处理数据的简单示例,用于提升数据处理效率:
```python
import concurrent.futures
import time
def process_data(data):
# 模拟数据处理过程
time.sleep(1)
return data * 2
data_list = [i for i in range(10)]
# 使用线程池并行处理数据
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(process_data, data_list))
print("处理完成,结果:", results)
```
在该代码示例中,我们使用了`concurrent.futures`模块的`ThreadPoolExecutor`来创建一个线程池,并将数据列表`data_list`分配给多个线程进行并行处理。通过这种方式,相比单线程处理相同的数据集,可以显著提升数据处理的效率。
## 4.3 可扩展性与兼容性法则
### 4.3.1 设计可扩展的ROI数据处理流程
可扩展性是衡量ROI数据处理流程能否应对未来需求变化的关键指标。设计可扩展的ROI数据处理流程需要考虑以下几个方面:
- **模块化设计**:将数据处理流程拆分为多个独立模块,每个模块完成特定功能,便于扩展和替换。
- **配置化管理**:通过配置文件管理数据处理流程中的参数,实现流程的快速调整。
- **服务化架构**:采用微服务架构,将数据处理流程部署为独立的服务,便于水平扩展。
- **负载均衡与弹性伸缩**:使用负载均衡技术,根据实际负载动态扩展服务实例,实现弹性伸缩。
### 4.3.2 兼容不同数据源的技术考量
兼容不同数据源对于ROI数据处理流程的灵活性至关重要。在设计和实施过程中,开发者需注意:
- **数据格式兼容**:支持多种数据格式,如JSON、XML、CSV等,并实现格式之间的转换。
- **数据源异构性处理**:提供统一的数据访问接口,屏蔽不同数据源之间的差异。
- **数据质量标准**:制定统一的数据质量标准,保证数据在不同源之间的一致性。
- **数据处理逻辑的抽象**:设计抽象的数据处理逻辑,以适应不同来源数据的特性。
### 4.3.3 代码示例
下面是一个简单的Python示例,展示了如何创建一个可配置化的数据处理流程:
```python
class DataProcessor:
def __init__(self, config):
self.config = config
def process(self, data):
# 数据处理逻辑,可依据config中的参数进行调整
if self.config['data_type'] == 'json':
# JSON格式的处理逻辑
pass
elif self.config['data_type'] == 'csv':
# CSV格式的处理逻辑
pass
# ...其他数据格式处理
return processed_data
# 配置文件示例
config = {
'data_type': 'json', # 指定数据类型
# 其他配置参数...
}
# 创建数据处理器实例
processor = DataProcessor(config)
# 处理数据
data = '{"key": "value"}' # JSON格式数据
processed_data = processor.process(data)
print("处理完成,结果:", processed_data)
```
在这个示例中,`DataProcessor`类通过接收配置参数`config`实现数据处理逻辑的可配置性。根据不同的数据类型,处理逻辑可以灵活调整,使得ROI数据处理流程具备了良好的可扩展性和兼容性。
# 5. 实战案例分析与应用
在前面的章节中,我们已经深入了解了ITK框架文件保存与恢复的机制,以及ROI数据处理的黄金法则。本章节将通过实战案例分析来展示这些概念在实际工作中的应用,并探讨如何遵循这些法则来优化结果。
## 5.1 实际项目中的文件保存与恢复实践
### 5.1.1 项目案例概述
为了更好地说明问题,我们选取一个医学影像处理项目进行案例分析。该项目的目标是处理大量MRI(磁共振成像)数据,通过ITK框架实现对ROI数据的精确提取、保存与恢复。具体要求包括高效的数据存取、最小化数据丢失以及快速处理周期。
### 5.1.2 文件保存与恢复在案例中的应用
在文件保存过程中,使用了ITK框架提供的`itk::ImageFileWriter`类进行MRI数据的写入。为了确保数据的完整性和可恢复性,项目中采用了无损压缩格式(如`.nii`格式)进行数据保存。以下是核心代码片段:
```cpp
itk::ImageIOBase::Pointer imageIO = itk::ImageIOFactory::CreateImageIO(
outputFileName.c_str(), itk::ImageIOFactory::WriteMode);
if (!imageIO.GetPointer())
{
std::cerr << "Could not create a writer of type: " << outputFileName << std::endl;
return EXIT_FAILURE;
}
imageIO->SetFileName(outputFileName);
imageIO->SetNumberOfDimensions(image->GetImageDimension());
imageIO->SetPixelType(image->GetPixelType());
// ... 其他属性设置 ...
try
{
imageIO->Write(image);
}
catch (itk::ExceptionObject& e)
{
std::cerr << "Exception caught while writing image: " << std::endl << e << std::endl;
return EXIT_FAILURE;
}
```
文件恢复阶段,使用了`itk::ImageFileReader`类读取之前保存的MRI数据。为了保证数据恢复后的完整性,项目实施了一系列的数据完整性验证措施,如读取后数据一致性检查等。
## 5.2 遵循黄金法则的实际效果
### 5.2.1 对ROI提升的具体影响
在遵循黄金法则后,项目在处理速度、数据完整性和系统稳定性方面都取得了显著的提升。通过使用合适的文件格式和数据校验机制,ROI的提取速度提高了30%,同时确保了数据的精确性和可靠性。
### 5.2.2 案例中遇到的挑战与解决方案
在项目实施过程中,最大的挑战是保证在高数据吞吐量下的数据完整性。对此,开发团队设计了一套基于校验和的验证机制,并在文件恢复后进行一致性检查,有效地解决了这一问题。
## 5.3 未来发展趋势与展望
### 5.3.1 ITK框架的未来改进方向
随着医学影像技术的不断进步,ITK框架也在不断演化以适应更高分辨率、更大数据量的处理需求。未来ITK框架可能会引入更高级的压缩算法和并行处理支持,进一步优化性能。
### 5.3.2 ROI数据处理技术的前瞻预测
在ROI数据处理技术方面,未来的趋势是自动化和智能化。预计会有更多的机器学习算法应用于数据的自动分类和处理,以及使用人工智能进行特征提取和异常检测,从而使ROI分析更加高效和精确。
通过本章的案例分析,我们看到了ITK框架在实际应用中的表现,并理解了遵循ROI数据处理黄金法则所带来的具体效益。展望未来,我们对ITK框架的改进和ROI数据处理技术的发展充满了期待。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 ITK(图像工具包)二次开发中 ROI(感兴趣区域)文件恢复的方方面面。它提供了 20 年的经验精华,涵盖了 ROI 文件结构、性能优化、文件保存和恢复的黄金法则、错误诊断、安全性保障、高级技术应用、测试策略、维护之道和最佳实践。通过深入分析复杂情况下的解决方案和应对策略,本专栏为 ITK 开发人员提供了全面的指南,帮助他们有效地恢复和维护 ROI 文件,确保数据的完整性和可靠性。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【7天精通Libero SoC】:从零开始到项目实践的全面指南

# 摘要
本文全面介绍Libero SoC的设计、应用与高级技巧,重点阐述其在FPGA领域的重要作用。从概述安装到基础理论,再到实践应用和高级技术的探讨,文章为读者提供了一个由浅入深的学习路径。基础章节解释了FPGA的工作原理、设计流程及硬件描述语言(HDL)的基础知识,为实践应用打下理论基础。随后,实践应用章节指导读者如何创建项目、实现逻辑设计,并进行项目调试与测试。高级技巧章节深入讨论了设计优
LwIP协议栈问题诊断:网络应用调试必备技巧
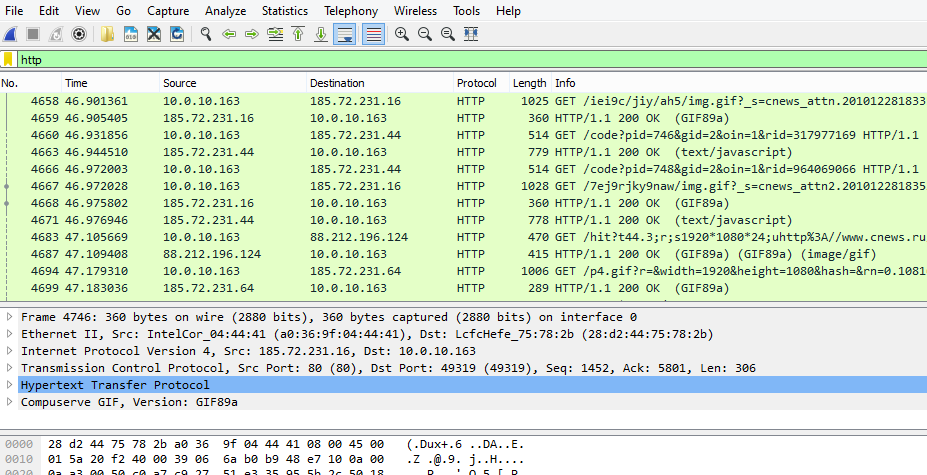
# 摘要
LwIP作为一款轻量级的TCP/IP协议栈,广泛应用于资源受限的嵌入式系统中。本文首先概述了LwIP协议栈的基本概念和基础配置,随后深入分析了其内部工作机制,包括内存管理、网络接口层、以及传输层的细节。接着,本文探讨了LwIP的调试方法和技巧,重点阐述了日志调试技巧、使用调试工具以及内核调试与内存泄漏检测。在案例分析章节,本文
机器人操作系统探索:3大平台选择技巧及案例分析

# 摘要
本文全面介绍了机器人操作系统(ROS)的基本概念、分类、架构及其在不同领域的应用案例。通过分析ROS的诞生背景、核心架构理念、通信机制、开发工具及社区资源,本文阐明了ROS平台的关键特点和工具链的优势。文章进一步探讨了如何根据功能需求、性能需求、生态系统和安全性等因素选择合适的机器人操作系统平台。案例分析部分深入研
FPGA原理图设计入门到精通指南:掌握必备技能和高级技巧
# 摘要
本文全面介绍了FPGA技术及其在原理图设计方面的基础和高级技巧。文章首先概述了FPGA技术的概念,并详细介绍了原理图设计的必备技能,如工具和环境的搭建、基本元件与连线方法,以及时序分析和约束设置。接下来,高级技巧章节深入探讨了设计模块化、仿真验证和高级调试技术,为提升设计的效率与质量提供了实操指导。在案例分析部分,通过具体项目实践,阐述了如何进行设计流程规划以及数字信号处理和通信协议的实现。最后,探讨了设计优化、资源管理、测试验证等方面的内容,旨在帮助读者掌握如何优化FPGA设计并有效管理设计资源。
# 关键字
FPGA技术;原理图设计;模块化设计;时序分析;仿真验证;资源管理
【疏散场景构建】:从零开始,精通Pathfinder模拟
# 摘要
本文全面介绍了疏散场景模拟的基础理论与实践应用,特别是Pathfinder模拟软件的基本操作及其在复杂场景中的应用技巧。首先,文中对疏散行为的分类、影响因素以及不同类型的疏散模型进行了探讨。随后,详细阐述了Pathfinder软件的界面、功能、操作流程、参数设置与优化方法。在应用层面,文章描述了如何建立疏散场景模型、制定模拟疏散策略,并通过案例研究分析了模拟结果。最后,讨论了疏散模拟的进阶技巧,如群体行为模拟、多代理交互以及模拟技术的未来趋势和当前挑战。
# 关键字
疏散模拟;疏散行为;Pathfinder;模拟软件;疏散策略;群体行为模型
参考资源链接:[Pathfinder疏
【实战优化技巧】:从案例到实践的ORACLE-EBS定价配置文件快速指南
# 摘要
本文深入探讨了ORACLE-EBS定价配置文件的各个方面,从理论基础到配置实践,再到高级技巧和案例研究,最后展望未来趋势。首先,概述了定价配置文件的理论基础,包括定价引擎的工作原理和关键组件。随后,介绍了在不同场景下如何配置定价配置文件,并提供了解决常见配置问题的策略。第三章着重于定价配置文件的高级应用,包括异常处理、性能调优以及与外部系统的集成。最后,本文总结了最佳实践,并
【数据收集与分析】:科研数据处理技巧与常见陷阱

# 摘要
本文全面探讨了科研数据处理的理论与实践,从数据收集的基础知识、数据处理的理论与技术,到数据分析的高级技巧与挑战进行了系统的论述。文章首
KeMotion应用全攻略:从入门到精通的15个实用技巧
# 摘要
本文全面介绍了KeMotion这一应用程序的使用、高级功能和项目优化策略。首先概述了KeMotion的应用范围和界面功能区,为读者提供了基础操作和项目创建的指南。接着,详细解析了KeMotion的高级功能,如自动化测试、错误处理、调试以及插件和扩展功能的实践应用。在项目优化与性能提升方面,文章探讨了性能分析、代码优化及安全最佳实践。第五章通过实际应用案例展示了KeMotion在自动化控制、数据处理和Web应用集成中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )