数据处理流程优化:Anaconda项目案例研究分析
发布时间: 2024-12-09 15:53:18 阅读量: 25 订阅数: 16 

开发形状模型的框架Matlab代码.rar

# 1. 数据处理流程优化概述
在当今这个数据爆炸的时代,数据处理流程优化已经成为了IT行业中的核心议题。从数据的采集、存储、处理到分析,每一步都潜在着优化的可能性。本章将对数据处理流程进行全面的概述,并探讨在各个环节中实现优化的方法论。
## 1.1 数据处理的重要性与挑战
数据处理流程是任何数据分析和机器学习项目的基石。一个高效而准确的数据处理流程可以显著提升最终模型的性能,并降低生产环境中出现错误的风险。然而,随着数据量的增加和数据复杂性的提高,数据处理面临着数据质量控制、处理速度、可扩展性以及成本效率等挑战。
## 1.2 数据处理流程的定义与组成部分
数据处理流程是指通过一系列的步骤和操作,将原始数据转化为可供分析使用的格式。它通常包括数据收集、清洗、转换、集成、分析和可视化等几个关键环节。理解这些组成部分及其内在关联是优化整个流程的基础。
## 1.3 流程优化的目标与意义
流程优化的目标是提高数据处理的效率、准确性和可靠性,同时降低资源消耗和时间成本。一个优化良好的流程能带来更快速的决策制定、更高的工作满意度以及更大的商业价值。本章将为读者提供一个清晰的数据处理流程优化视角,帮助构建更加高效的数据处理环境。
# 2. Anaconda项目的技术基础
### 2.1 Anaconda环境的搭建与管理
在进行数据分析之前,构建一个稳定且高效的开发环境至关重要。Anaconda是一个强大的包管理和环境管理工具,尤其在数据科学领域广泛使用。它的安装和配置,以及Conda环境和包的管理,都是搭建一个有效工作环境的基石。
#### 2.1.1 安装Anaconda及其配置
Anaconda的安装过程简单直接。通过访问其官方网站下载适合当前操作系统的安装包,然后执行安装程序,并根据指引完成安装。安装完成后,需要进行一些基本配置来确保Anaconda能够正常使用,比如设置环境变量。安装过程中,用户通常需要设置路径以及环境变量,以确保系统能够识别Anaconda及其命令行工具。
在配置完成后,我们可以使用conda命令来管理和操作环境和包。以下是一个简单的Anaconda安装和基本配置流程:
```bash
# 下载Anaconda安装脚本
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
# 给安装脚本添加执行权限
chmod +x Anaconda3-2021.05-Linux-x86_64.sh
# 执行安装脚本
./Anaconda3-2021.05-Linux-x86_64.sh
# 按照提示完成安装,注意选择yes同意许可协议,并在提示处指定安装路径(推荐使用默认路径)
# 配置环境变量,将Anaconda的路径添加到PATH中
export PATH=/path/to/anaconda/bin:$PATH
# 使配置立即生效(根据shell环境不同,可能需要重启终端或者手动source配置文件)
source ~/.bashrc
```
#### 2.1.2 管理Conda环境和包
使用Conda创建和管理独立的环境是避免不同项目间依赖冲突的有效方法。以下是管理Conda环境和包的基本命令和实践:
```bash
# 创建新的环境
conda create -n myenv python=3.8
# 激活环境
conda activate myenv
# 在环境中安装包
conda install numpy pandas
# 列出当前环境下所有包
conda list
# 移除包
conda remove numpy
# 删除环境
conda remove -n myenv --all
```
### 2.2 Python在数据处理中的应用
Python作为一门多用途的编程语言,在数据处理方面有着得天独厚的优势。其强大的标准库和众多第三方库,为数据分析提供了极大的便利。
#### 2.2.1 Python基础与数据结构
Python的基本语法简洁明了,具有易于上手的特点。它支持多种数据结构,如列表(list)、元组(tuple)、字典(dict)和集合(set),这为数据处理提供了灵活的工具。
```python
# 示例:使用列表和字典处理数据
fruits = ['apple', 'banana', 'cherry']
price_dict = {'apple': 2.5, 'banana': 1.2, 'cherry': 3.0}
# 获取列表中的元素
print(fruits[1]) # 输出:banana
# 通过字典的键值对访问数据
print(price_dict['apple']) # 输出:2.5
```
#### 2.2.2 核心库Pandas和NumPy的使用
Pandas库提供了快速、灵活、表达力强的数据结构,专为数据分析而设计。NumPy则是Python中用于科学计算的核心库,提供高性能的多维数组对象和相关工具。以下是使用这两个库处理数据的示例代码:
```python
import pandas as pd
import numpy as np
# 创建Pandas数据框DataFrame
data = {'Fruit': ['apple', 'banana', 'cherry'], 'Price': [2.5, 1.2, 3.0]}
df = pd.DataFrame(data)
# 使用NumPy生成数组
prices = np.array([2.5, 1.2, 3.0])
# 使用Pandas与NumPy结合,进行数据操作
df['Discounted_Price'] = df['Price'] * 0.9
print(df)
# 输出DataFrame结果
```
#### 2.2.3 数据可视化工具Matplotlib和Seaborn
数据可视化是数据分析中不可忽视的一环。Matplotlib和Seaborn是Python中常用的图表库,它们通过简洁的API向用户提供强大的数据可视化能力。下面是一个简单的Matplotlib绘图示例:
```python
import matplotlib.pyplot as plt
# 使用Matplotlib绘制简单的折线图
x = np.arange(1, 4)
y = [2.5, 1.2, 3.0]
plt.plot(x, y, marker='o')
plt.xlabel('Fruit')
plt.ylabel('Price')
plt.title('Fruit Prices')
plt.show()
```
### 2.3 数据处理流程的理论基础
在数据处理流程中,理论基础是至关重要的。掌握数据预处理、清洗、转换和集成的策略能够极大提高数据质量,为后续的数据分析打下坚实的基础。
#### 2.3.1 数据预处理概念与技术
数据预处理是数据分析前必要的步骤,它包括数据清洗、数据整合、数据变换和数据规约等过程。正确地处理缺失值、异常值和噪声数据,可以提升数据的整体质量和后续模型的准确性。
#### 2.3.2 数据清洗、转换和集成策略
数据清洗主要涉及处理缺失值和异常值,数据转换则包括归一化、标准化、数据类型转换等技术。数据集成则涉及合并多个数据源以获得统一的数据视图。
```mermaid
flowchart LR
A[开始] --> B[数据收集]
B --> C[数据清洗]
C --> D[数据转换]
D --> E[数据集成]
E --> F[数据存储]
F --> G[数据使用]
```
#### 2.3.3 数据分析与建模流程
数据分析流程通常包括数据探索、特征工程、模型选择、模型训练、模型评估和参数优化等阶段。其中模型评估和参数优化是保证模型泛化能力的关键步骤。
通过对理论基础的深入理解和应用,数据科学家可以构建出高效、准确的数据处理流程。这不仅提升了分析的效率,也为企业决策提供了更为可靠的依据。
# 3. Anaconda项目实践分析
在数据科学领域,Anaconda项目被广泛应用于实践分析中,这归功于其强大的集成库和简便的环境管理功能。本章节将

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为数据科学家和分析师提供有关 Anaconda 项目管理和协作工具的全面指南。通过深入探讨环境隔离、环境导出导入、Anaconda Notebooks 的集成以及数据处理流程优化,本专栏提供了实用的策略和技巧,以提高数据科学项目的效率和协作性。此外,专栏还通过案例研究分析展示了 Anaconda 在实际项目中的应用,并介绍了使用 Anaconda 有效管理时间线的方法,为数据科学专业人士提供全面的资源,以提升其项目管理和协作能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深度解析:掌握扫描控件原理与应用,提升工作效率的秘诀

# 摘要
扫描控件作为现代信息技术的重要组成部分,在商业、工业及办公自动化领域中扮演着关键角色。本文系统地介绍了扫描控件的基础概念、核心技术,及其在不同应用场景下的实际应用
CPS推广效率提升:转化率优化的10大技巧和工具

# 摘要
本文探讨了CPS(Cost Per Sale,销售成本)推广效率与转化率之间的关系,并对如何优化转化率提供了理论和实践上的深入分析。通过用户行为分析、营销心理学原理的应用以及用户体验和网站性能的提升,本文展示了提升CPS转化率的关键技巧。同时,介绍了多种优化工具与平台,包括分析工具、营销自动化工具和转化率优化工具,并通
MATLAB中QPSK调制解调的关键:根升余弦滤波器设计与应用详解
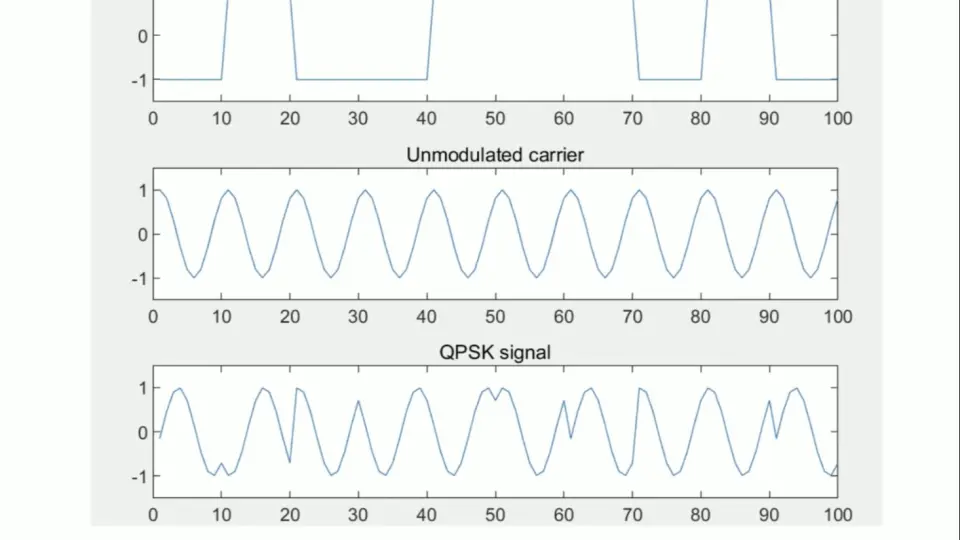
# 摘要
本文详细探讨了QPSK调制解调技术及其关键组成部分:根升余弦滤波器。首先介绍了QPSK调制解调的基本原理,然后深入解析根升余弦滤波器的理论基础,包括其数学模型和在QPSK中的作用。随后,文章阐述了根升余弦滤波器的设计过程,包括设计步骤、使用MATLAB工具以及性能评估方法。接着,针对QPSK系统中根升余弦滤波器的应用进
【ArcGIS数据处理高手速成】:3大技巧助你提升数据处理效率
# 摘要
本文从数据处理的角度深入探讨了ArcGIS的应用,涵盖了从前期数据准备到最终性能优化的完整流程。首先介绍了数据处理的基本概念,重点讲述了数据的导入、格式转换、清洗、预处理以及数据集合并与拆分的技巧。接下来,文章详细解析了空间分析中的高效操作方法,包括空间插值、网络分析和地形分析的实施与优化。第四章转向数据的可视化与制图,讨
伺服性能升级秘籍:SV660F手册里的隐藏技巧大公开

# 摘要
本文深入探讨了SV660F伺服系统的概述、性能指标、基础设置与调整、高级控制技术以及故障排除与维护。首先,文章介绍了SV660F伺服系统的基本概念和性能评估,接着详细描述了伺服驱动器参数配置、伺服电机的启动与运行调整、以及高级参数的应用。第
【图标库实战教程】:打造专业网络通信Visio图标库(一步到位的图库构建法)

# 摘要
图标库作为提升专业网络通信用户体验的重要工具,其设计与构建对于实现有效沟通具有重要作用。本文首先探讨了图标库在专业网络通信中的作用,接着从理论基础和设计原则出发,详细阐述了图标设计的关键点以及设计工具与技术的选择。在实践操作部分,本文提供了图标绘制流程、图标库结构设计、版本控制与维护的具体方法。进一步,本文分析了图标库优化与扩展的重
Ubuntu服务器Python 3.9环境搭建:专家级实战指南
# 摘要
随着技术的进步,Python 3.9的使用在服务器环境中的基础配置和应用实践变得日益重要。本文首先介绍了在Ubuntu服务器上设置Python环境的基础知识,接着详细讲解了Python 3.9的安装、配置以及环境验证过程。此外,本文还深入探讨了Python 3
小米供应链协同效应:整合上下游资源的黄金法则

# 摘要
本文深入分析了小米供应链协同效应的理论基础和实践应用。文章首先介绍了供应链协同的理论基础,随后分析了小米供应链的现状,包括其独特结构与优势、协同机制、信息化建设等方面。进一步地,本文探讨了小米在资源整合、库存管理、物流配送以及风险管理等方面的策略和创新实践。文章最后讨论了在创新驱动下供应链协同面临的挑战,并提出了相应的对策。通过对小米供应链协同效应的深入研究,本文旨在为供应链管理提供理论与实
【inpho DEM软件功能详解】:编辑与分析工具的终极指南

# 摘要
inpho DEM软件为地形数据处理提供了一系列功能强大的编辑和分析工具。本文首先概览了该软件的基本功能和编辑工具,涵盖从地形数据的导入导出到地形特征的编辑修饰,以及地形数据的平滑、优化和特征提取。接着,详细介绍了栅格和向量分析技术的应用,包括数据处理、水文分析、矢量操作以及空间关系网络分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )