【高效PSpice模型库管理】:揭秘模型库维护和更新的4大策略
发布时间: 2024-12-15 06:03:17 阅读量: 4 订阅数: 4 

2.建PSPICE仿真模型库(二).pdf

参考资源链接:[PSpice添加SPICE模型:转换MOD/TXT/CIR到.lib、.olb](https://wenku.csdn.net/doc/649318a99aecc961cb2bdd38?spm=1055.2635.3001.10343)
# 1. PSpice模型库管理概述
## 1.1 PSpice模型库的重要性
PSpice模型库是电子电路仿真中不可或缺的组成部分,它包含了各种电子元件和器件的详细参数和行为特性。一个良好的模型库不仅能够提供精确的仿真结果,还能够大大减少设计者的调试时间,提高设计效率。
## 1.2 模型库管理的目标和挑战
模型库管理的主要目标是确保模型库的准确性和一致性,同时提高模型库的可访问性和易用性。挑战则包括如何高效地管理大量模型,如何在保持模型库质量的同时进行更新和扩展,以及如何确保模型库的兼容性和通用性。
## 1.3 模型库管理的必要性
随着电子设计复杂性的增加,模型库管理变得越来越重要。良好的模型库管理可以帮助设计师更快地找到正确的模型,降低设计风险,并为产品开发周期的其他环节提供坚实的基础。
# 2. 模型库的理论基础和数据结构
## 2.1 PSpice模型库的组成
### 2.1.1 模型库的定义与目的
PSpice模型库是电子设计自动化(EDA)工具PSpice中用于存储和管理各种电子元件参数的数据库。它为工程师提供了一个标准的平台,可以在模拟电路设计过程中调用所需的元件模型,以提高电路设计的准确性和效率。
模型库的目的包括但不限于以下几点:
- 提供一个标准化的元件描述方法,确保模拟结果的一致性。
- 便于管理和检索模型数据,减少设计重复工作。
- 支持模型的版本控制,以跟踪和维护历史版本。
### 2.1.2 模型库中的数据类型和层次结构
PSpice模型库中的数据类型多种多样,涵盖从简单的无源元件到复杂的半导体器件模型。其层次结构可以被粗略划分为三大类:
- **基础元件模型(Basic Components):** 包括电阻、电容、电感、二极管、晶体管等基础电子元件的模型。
- **半导体模型(Semiconductor Models):** 包括双极型晶体管(BJT)、金属-氧化物半导体场效应晶体管(MOSFET)、等效模型等。
- **高级模型(Advanced Models):** 包括温度依赖模型、非线性模型、封装模型等更为复杂的模型。
## 2.2 数据管理理论
### 2.2.1 数据库管理的重要性
数据库管理是维护PSpice模型库的核心,其重要性体现在:
- 确保数据的一致性:避免数据冗余和不一致,保证模拟的准确性。
- 提高数据的可靠性:通过备份和恢复机制保护模型库不受损失。
- 促进数据的可用性:通过合理的数据结构设计,提高数据检索的速度。
### 2.2.2 数据一致性与完整性原则
在模型库中维护数据的一致性与完整性是至关重要的:
- **一致性(Consistency)**:在更新、删除或添加操作后,确保数据仍然保持原有规则约束。
- **完整性(Integrity)**:包括实体完整性、参照完整性以及用户定义的完整性,它们确保数据在逻辑上是正确的。
### 2.2.3 数据结构设计
数据结构设计是数据库设计的关键组成部分,针对PSpice模型库的设计,通常包含以下结构:
- **表结构(Tables):** 存储元件描述、参数和关系。
- **视图结构(Views):** 提供针对特定需求的数据子集。
- **索引(Indexes):** 提高查询效率,通常为关键字段设置索引。
### 2.2.4 案例分析:半导体模型的数据结构设计
以一个半导体模型数据结构设计为例,表结构可能包含以下字段:
- **模型名称(Model Name)**:唯一标识一个模型。
- **模型类型(Model Type)**:例如BJT、MOSFET等。
- **参数集(Parameter Set)**:包含模型的所有参数。
- **温度系数(Temperature Coefficients)**:描述模型在不同温度下的行为。
- **仿真数据(Simulation Data)**:包含模型在特定条件下的仿真结果。
```
CREATE TABLE semiconductor_models (
model_name VARCHAR(255) PRIMARY KEY,
model_type VARCHAR(50),
parameter_set TEXT,
temperature_coefficients TEXT,
simulation_data TEXT
);
```
## 2.3 模型库的逻辑架构
### 2.3.1 逻辑架构的设计原则
逻辑架构的设计原则包括:
- **模块化(Modularity):** 将复杂的系统分解为易管理的模块。
- **可扩展性(Scalability):** 允许逻辑架构随需求增长而扩展。
- **灵活性(Flexibility):** 逻辑架构能够适应变化,例如增加新的模型类型。
### 2.3.2 逻辑架构对维护更新的影响
逻辑架构设计直接影响模型库的维护更新流程:
- **变更管理(Change Management):** 一个良好的逻辑架构可以简化模型更新的流程。
- **数据迁移(Data Migration):** 在逻辑架构升级时,能够保证数据平滑迁移。
### 2.3.3 逻辑架构中的数据迁移流程
在更新逻辑架构时,数据迁移流程通常包括以下步骤:
1. **评估现有数据:** 分析现有数据是否满足新架构的需求。
2. **数据转换计划:** 制定详细的迁移计划,包括备份策略。
3. **执行迁移:** 在确保数据安全的情况下进行数据转换。
4. **验证迁移结果:** 对迁移后的数据进行测试,确保其准确性和完整性。
5. **恢复服务:** 确认数据迁移成功后,恢复模型库服务。
通过上述流程,能够有效地将模型库从旧逻辑架构迁移到新的逻辑架构中,同时保障数据的完整性和服务的连续性。
下一章将深入探讨如何维护PSpice模型库,并提供具体的策略与实践指导。
# 3. 维护PSpice模型库的策略与实践
## 3.1 常规维护流程
### 3.1.1 定期检查与验证
在维护PSpice模型库的过程中,定期检查与验证是确保模型库准确性和完整性的关键步骤。这些检查应当包括但不限于模型参数的准确性、模型库结构的完整性和文档的同步更新。具体来说:
1. **模型参数的准确性**:定期运行自动化脚本或者手动检查各个模型的参数值,确保它们与最新的数据手册和工程标准保持一致。
2. **模型库结构的完整性**:验证目录结构、文件命名规则、引用关系等是否按照设计规范进行维护,确保没有缺失或错误。
3. **文档同步更新**:当模型库发生变化时,相关文档的更新往往容易被忽视。维护过程中应制定严格的流程,确保相关文档与模型库同步更新。
代码块示例:
```bash
#!/bin/bash
# 检查PSpice模型参数脚本示例
MODEL_LIBRARY_PATH="/path/to/model/library"
# 使用grep命令查找特定参数,如Rds(on)
grep -r "Rds(on)" $MODEL_LIBRARY_PATH | awk -F ":" '{print $1}' | sort -u > Rds检查列表.txt
# 进行参数验证...
# 这里省略了验证逻辑,需要根据具体的参数和验证标准填充
echo "完成参数检查。"
```
### 3.1.2 版本控制与变更管理
变更管理是维护PSpice模型库的另一个重要方面,特别是在设计团队成员众多时,良好的版本控制和变更管理流程可以极大减少错误和冲突。
1. **版本控制工具选择**:选择合适的版本控制系统(如Git)来追踪模型库的变更历史,以便在出现问题时可以回溯到之前的版本。
2. **变更管理流程**:建立严格的变更管理流程,包括变更请求的审批、实施和验证。每一次变更都应记录变更日志,并进行适当的测试。
变更管理流程图示例:
```mermaid
graph LR
A[开始变更管理流程] --> B[提交变更请求]
B --> C{审批变更请求}
C --> |批准| D[实施变更]
C --> |拒绝| E[结束流程]
D --> F[测试变更]
F --> |通过| G[合并变更到主分支]
F --> |失败| H[回退变更并通知请求者]
G --> I[更新变更日志]
```
## 3.2 故障排除与问题解决
### 3.2.1 常见模型库故障案例分析
在实际的维护工作中,模型库可能会遇到各种问题,这些问题通常源于模型参数错误、模型损坏或者环境配置不当等。通过分析案例,可以发现多数问题都有一定的模式,下面通过一个常见的故障案例进行分析:
1. **案例描述**:在模型库中发现某一型号的晶体管模型参数不符合预期,导致仿真结果与实际电路表现不一致。
2. **问题定位**:通过版本控制系统追踪到变更历史,发现最近的一次更新将该晶体管的某个关键参数做了错误的修改。
3. **解决方案**:将参数修改回正确的值,并进行全面的仿真验证确保修改有效。
### 3.2.2 故障诊断与修复流程
故障诊断和修复流程应当系统化以确保效率和准确性。以下是一个标准的流程:
1. **记录故障现象**:详细记录故障发生时的情况和故障表现,这是后续分析的基础。
2. **初步判断可能原因**:根据故障现象,初步判定可能的原因,如参数错误、模型损坏、软件故障等。
3. **深入分析问题**:深入探究问题的根源,可能需要检查日志文件、对比参数、甚至重建模型环境。
4. **制定修复计划**:确定修复方案后,制定详细的实施步骤,包括修改参数、重新建立模型、重新仿真验证等。
5. **实施修复计划**:按照计划实施修复,修复过程中要确保有适当的方法记录每一步骤,以便出现问题时可以追溯。
6. **验证修复结果**:修复后,需要进行充分的验证,确保修复后的模型库运行稳定且结果正确。
代码块示例:
```bash
#!/bin/bash
# 修复模型参数脚本示例
MODEL_TO_FIX="/path/to/problematic/model"
# 使用sed命令替换错误的模型参数
sed -i 's/erroneous_param/accurate_param/g' $MODEL_TO_FIX
# 重新验证模型
echo "正在验证修复后的模型..."
# 这里省略了验证命令和逻辑,需要根据具体的参数和验证标准填充
echo "模型验证完成,结果正确。"
```
## 3.3 模型库的自动化管理
### 3.3.1 自动化工具的选择与配置
在维护一个大型PSpice模型库时,自动化工具是提高效率的关键。工具的选择应基于模型库的规模、团队的技能水平和维护流程的需求。以下是一些常见的自动化工具及其配置方法:
1. **版本控制系统**:选择合适的版本控制系统(如Git或SVN)并进行配置,以实现模型库的版本跟踪和变更管理。
2. **持续集成工具**:如Jenkins或GitLab CI,可以用于自动化测试模型库的变更,确保每次更新都不会破坏现有的模型功能。
3. **备份工具**:选择适合的备份工具或服务,如rsync、Bacula或云存储服务,定期备份整个模型库,以防止数据丢失。
### 3.3.2 自动化更新与备份流程
自动化更新和备份流程的建立可以大幅减少手动操作的错误和遗漏。流程通常包括:
1. **触发更新**:设置触发器来监控模型库的变更,例如当版本控制系统中的模型文件发生变化时。
2. **更新执行**:自动化脚本执行模型库更新,包括复制新的或修改的模型文件到目标位置,运行必要的测试。
3. **更新验证**:更新后,自动化执行测试脚本来验证模型库的完整性。
4. **备份实施**:设置自动化备份任务,按照既定的计划备份模型库到安全的位置。
5. **日志记录**:记录自动化任务的详细日志,以便发生问题时可以进行故障排除。
代码块示例:
```bash
#!/bin/bash
# 自动化备份PSpice模型库脚本示例
MODEL_LIBRARY_PATH="/path/to/model/library"
BACKUP_PATH="/path/to/backup/library"
# 备份模型库
rsync -avz $MODEL_LIBRARY_PATH $BACKUP_PATH
# 执行后检查备份是否成功
echo "备份完成,检查备份结果..."
# 这里省略了检查备份完整性的命令和逻辑
echo "备份成功。"
```
通过实施上述策略与实践,可以有效地维护PSpice模型库的稳定性和准确性,同时降低维护工作中的风险和错误。这为模型库的持续优化和扩展打下了坚实的基础。
# 4. 模型库更新的关键步骤
## 4.1 更新流程设计
### 4.1.1 更新流程的规划和文档化
在实施模型库更新之前,关键步骤之一是制定一个详尽的更新流程,并将其规划和文档化。这一步骤是为了确保更新过程中的每一步都有明确的指导和记录,从而减少人为错误并提供一个回溯的依据。规划更新流程应该从以下几点入手:
- **需求分析**:明确更新的目标和需求,包括新增的模型、改进的参数、以及任何用户反馈的特定问题。
- **资源分配**:评估更新所需的资源,包括人员、时间和软硬件工具。
- **详细步骤**:将整个更新流程分解为可操作的步骤,每个步骤应当有明确的负责人和完成时间。
- **风险管理**:识别更新过程中可能出现的风险,并制定相应的缓解策略。
- **流程图绘制**:使用流程图来直观展示更新步骤的逻辑关系和顺序,mermaid流程图是一个很好的选择。
```mermaid
graph LR
A[开始] --> B[需求分析]
B --> C[资源分配]
C --> D[详细步骤制定]
D --> E[风险管理]
E --> F[更新实施]
F --> G[验证与测试]
G --> H[文档更新]
H --> I[结束]
```
在文档化过程中,可以使用表格记录每个步骤的详细信息,如下所示:
| 步骤编号 | 步骤名称 | 负责人 | 预期完成日期 | 备注 |
|----------|----------|---------|---------------|------|
| 1 | 需求分析 | 张三 | 2023-04-10 | - |
| 2 | 资源分配 | 李四 | 2023-04-12 | - |
| ... | ... | ... | ... | ... |
### 4.1.2 更新流程中的关键控制点
在模型库更新流程中,有些步骤是关键控制点,它们对于确保更新的质量和可靠性至关重要。关键控制点通常包括:
- **代码审查**:更新后的代码需经过同行或专业人员的审查,确保没有逻辑错误。
- **参数校验**:对新增或修改的模型参数进行校验,确保它们符合预期的性能。
- **版本控制**:在更新过程中使用版本控制系统跟踪更改,以便在出现问题时能够快速回滚。
- **用户测试**:在更新完成后,让部分用户进行测试,以发现可能未被提前发现的问题。
代码审查可以采取同行评审的方式,提高代码质量和减少缺陷。参数校验则通常涉及模拟测试,以确保参数调整后的模型库仍然保持应有的性能。
```mermaid
graph LR
A[开始更新] --> B[代码审查]
B --> C[参数校验]
C --> D[版本控制]
D --> E[用户测试]
E --> F[更新流程结束]
```
## 4.2 数据迁移与兼容性
### 4.2.1 数据迁移策略
在模型库更新时,数据迁移是不可避免的环节。数据迁移策略必须考虑数据的一致性和完整性。数据迁移策略的制定应包括以下几个方面:
- **数据备份**:在进行任何迁移前,必须对现有数据进行备份,以防数据丢失。
- **迁移工具选择**:选择适合的数据迁移工具,并确保其兼容性。
- **测试迁移**:在正式迁移前,先在测试环境中进行迁移,检查数据的完整性和系统的表现。
- **逐步迁移**:分阶段进行数据迁移,每完成一个阶段进行验证和检查。
代码块可以提供一个简单的迁移脚本示例,比如使用SQL语句进行数据库迁移:
```sql
-- 备份现有模型库数据
BACKUP DATABASE ModelLib TO DISK = 'ModelLib_backup.bak';
-- 迁移数据
USE ModelLib;
GO
-- 示例插入语句,假设添加了一个新的模型参数
INSERT INTO ModelParameters (ModelID, ParameterName, ParameterValue)
VALUES ('001', 'NewParameter', 'NewValue');
```
### 4.2.2 兼容性测试与处理
更新模型库时,兼容性测试保证了新旧版本之间的平滑过渡。兼容性问题可能导致模型失效或性能下降。测试工作应包括:
- **功能测试**:确保所有模型在新版本中仍能正常工作。
- **性能测试**:比较更新前后的模型性能,保证没有退化。
- **回归测试**:确保更新没有引入新的问题,特别是对已有功能的影响。
兼容性测试通常需要创建详细的测试用例,并记录测试结果。下面是一个简化的测试用例表格示例:
| 测试用例编号 | 模型名称 | 预期输出 | 实际输出 | 测试结果 | 备注 |
|---------------|-----------|-----------|-----------|-----------|------|
| TC-01 | ModelA | ... | ... | 通过/失败 | - |
| TC-02 | ModelB | ... | ... | 通过/失败 | - |
| ... | ... | ... | ... | ... | ... |
## 4.3 更新后的验证与测试
### 4.3.1 更新后模型库的验证方法
更新模型库后,验证工作是确认更新是否成功的必要环节。验证方法应该包括:
- **模拟测试**:使用模拟器运行更新后的模型库,查看是否满足性能要求。
- **一致性检查**:检查模型库中模型的一致性,确保它们符合预期的规范。
- **用户体验测试**:让用户进行实际操作,评价更新后的模型库是否提供了更好的体验。
模拟测试可以通过编写自动化脚本来运行,确保测试的客观性和重复性。下面是一个简化的自动化测试脚本示例:
```python
import model_library
# 初始化模型库
model_lib = model_library.initialize()
# 运行测试模型
results = model_lib.run('ModelA', input_data)
# 输出结果和预期结果进行比较
if results == expected_results:
print("测试通过")
else:
print("测试失败")
```
### 4.3.2 回归测试策略和案例分析
回归测试是指在软件或模型库更新后,重新运行之前所有的测试用例,确保之前的代码更改没有对现有功能造成负面影响。回归测试策略可以包括:
- **全回归测试**:在每次更新后执行所有测试用例。
- **选择性回归测试**:根据变更的范围选择相关的测试用例执行。
- **基于风险的回归测试**:优先执行那些可能受到影响的风险较高的测试用例。
一个案例分析可以展示如何根据实际更新实施回归测试:
假设有一个模型库更新了温度传感器模型,那么回归测试应该包括:
- **原有温度模型测试**:验证更新后的温度模型与更新前的表现是否一致。
- **温度模型新功能测试**:如果新版本引入了新功能,需要针对该功能进行测试。
这些测试步骤不仅确保模型库的质量,而且提高用户对更新模型库的信心。
# 5. 模型库管理的高级技巧
在之前的章节中,我们已经深入了解了PSpice模型库的基础知识、数据结构、维护策略以及更新流程。在这一章中,我们将进入更高级的领域,探讨如何通过优化、安全性和知识管理来提升模型库的整体质量和使用效率。
## 5.1 模型库优化技巧
模型库优化的目的是为了提升模型库的性能和用户的使用体验。这不仅包括性能上的优化,比如查询速度的加快,也包括改善用户界面和使用流程,从而提高用户的整体满意度。
### 5.1.1 性能优化的策略与方法
为了优化PSpice模型库的性能,我们可以采用一系列策略和方法,例如:
- **索引优化**:合理地为模型库中的字段创建索引可以显著加快查询速度。对于经常用于搜索和比较的字段,如模型名称、类型或参数,应该考虑创建索引。
- **查询优化**:优化数据库查询语句,减少不必要的表连接操作,使用更有效的查询条件,可以减少查询时间。
- **缓存机制**:对于频繁访问的数据,可以采用缓存机制来减少数据库的直接访问,从而加快数据的读取速度。
- **存储优化**:使用高效的存储解决方案,比如固态硬盘(SSD),可以提高数据读写速度。
### 5.1.2 用户体验的优化
优化用户体验主要涉及以下几个方面:
- **界面改进**:提供直观、简洁、易于操作的用户界面。界面设计应考虑到用户的操作习惯,减少用户的操作步骤。
- **搜索功能**:增强搜索功能,使其支持更多种类的搜索条件,如模糊搜索、高级搜索等,并提供搜索建议。
- **反馈机制**:建立有效的用户反馈机制,及时收集用户的意见和建议,持续改进模型库。
#### 示例代码块和分析
下面的示例代码展示了如何为一个模型库表添加索引,以优化查询性能。
```sql
-- 创建索引前的查询性能分析
EXPLAIN SELECT * FROM model_library WHERE model_name LIKE '%transistor%';
-- 添加索引
CREATE INDEX idx_model_name ON model_library(model_name);
-- 创建索引后的查询性能分析
EXPLAIN SELECT * FROM model_library WHERE model_name LIKE '%transistor%';
```
**逻辑分析和参数说明:**
- `EXPLAIN` 用于分析SQL查询语句的执行计划。
- `CREATE INDEX` 是用来在数据库中创建索引的语句,`idx_model_name` 是索引名称,`model_library(model_name)` 指定了索引应用于`model_library` 表的`model_name`字段。
- 通过比较添加索引前后的查询性能分析,可以看到查询所使用的操作(如扫描的行数和返回的行数)、使用的资源(如总成本)等性能指标。
## 5.2 安全性管理
安全性是模型库管理中不可忽视的重要方面。随着对模型库的依赖增加,数据泄露或损坏的风险也随之增加。因此,实施有效的安全性管理措施是非常重要的。
### 5.2.1 数据安全的威胁分析
数据安全威胁可以分为几种类型:
- **未授权访问**:未经授权的个人访问敏感数据。
- **数据篡改**:数据在存储或传输过程中被非法修改。
- **数据泄露**:数据被泄露给未经授权的第三方。
- **服务中断**:模型库服务因攻击或故障而中断。
### 5.2.2 安全防护措施与实践
为了应对上述威胁,可以采取以下措施:
- **访问控制**:实施基于角色的访问控制(RBAC),确保只有经过授权的用户才能访问特定的数据和功能。
- **数据加密**:使用强加密算法对存储和传输的数据进行加密。
- **备份策略**:定期备份数据,并确保备份的安全存储。
- **入侵检测系统**:部署入侵检测系统(IDS)监控潜在的安全威胁。
#### 示例代码块和分析
以下是一个示例代码,用于设置数据库的访问权限。
```sql
-- 创建用户
CREATE USER 'model_user'@'localhost' IDENTIFIED BY 'password123';
-- 授予权限
GRANT SELECT, INSERT, UPDATE, DELETE ON model_library.* TO 'model_user'@'localhost';
-- 刷新权限
FLUSH PRIVILEGES;
```
**逻辑分析和参数说明:**
- `CREATE USER` 语句用于创建一个新的数据库用户。
- `'model_user'@'localhost'` 定义了用户的名称和来源地址。
- `IDENTIFIED BY 'password123'` 设置了用户的密码。
- `GRANT` 语句用于授权用户对`model_library`数据库的特定操作权限。
- `FLUSH PRIVILEGES` 命令用于立即应用权限更改。
## 5.3 文档与知识管理
模型库不仅是模型数据的存储地,也应该是一个知识共享的平台。良好的文档和知识管理可以提升团队协作效率,加速问题的解决。
### 5.3.1 模型库文档化的重要性
文档化有助于:
- **信息共享**:文档是共享知识和信息的重要方式。
- **知识保留**:在员工离职或团队变更时,文档能保留关键知识。
- **流程优化**:通过文档记录最佳实践和操作流程,便于团队成员遵循和改进。
### 5.3.2 知识共享与团队协作
为了促进知识共享和团队协作,可以采取以下措施:
- **建立知识库**:在模型库中集成一个知识库,记录模型的使用方法、案例、故障处理等。
- **协作工具**:使用版本控制系统和项目管理工具来增强团队协作。
- **定期会议**:定期组织会议,分享项目进展和经验教训。
## 表格示例
下面的表格为模型库文档化的一个简单示例,用于记录模型的基本信息、使用指南和常见问题。
| 模型名称 | 使用指南 | 常见问题与解决方案 |
|-----------|----------|---------------------|
| BJT NPN | [链接到使用指南文档] | [链接到常见问题解答文档] |
| MOSFET | [链接到使用指南文档] | [链接到常见问题解答文档] |
## Mermaid 流程图示例
流程图可以用于描述模型库的知识共享工作流:
```mermaid
graph TD
A[开始] --> B[创建模型文档]
B --> C[审阅文档]
C --> D[发布到知识库]
D --> E[定期更新]
E --> F[结束]
```
以上内容为第五章:模型库管理的高级技巧的核心部分,下接第六章,我们将展望模型库管理的未来趋势与挑战。
# 6. 未来模型库管理的趋势与挑战
在当今技术迅速发展的时代,模型库管理面临着前所未有的机遇和挑战。新的技术趋势正在重塑未来模型库的管理方式,同时,行业内外部的变化也对模型库管理者提出了更高的要求。本章节将深入探讨未来模型库管理的新兴技术应用,以及在应对行业挑战时所采取的战略规划和持续改进路径。
## 6.1 模型库管理的新兴技术
### 6.1.1 人工智能在模型库管理中的应用
人工智能(AI)正在逐步渗透到各个技术领域,PSpice模型库管理也不例外。AI技术可以用于自动化模型参数校验、预测性维护和故障诊断,提高模型库的准确性和效率。
**实现AI技术应用的步骤:**
1. **数据采集:** 首先要从模型库中收集历史数据,包括模型参数、使用频率、变更记录等。
2. **模型训练:** 使用机器学习算法对收集到的数据进行训练,创建预测模型。
3. **集成与部署:** 将训练好的AI模型集成到PSpice模型库管理系统中,并进行部署和测试。
AI在模型库管理中的一个典型应用是对模型参数进行智能校验。例如,通过对比历史数据中的参数分布,AI可以自动识别出异常参数值,并给出修改建议,从而减少人为错误。
### 6.1.2 云服务与分布式模型库管理
随着云计算技术的发展,云服务在模型库管理中的应用变得越来越普遍。将模型库部署在云端可以带来诸多好处,比如弹性扩展、随时随地访问以及降低本地硬件成本。
**云服务模型库管理的关键实施步骤:**
1. **评估需求:** 对模型库的规模、访问频率和安全性需求进行评估。
2. **选择服务提供商:** 根据评估结果选择适合的云服务提供商和相应的服务方案。
3. **数据迁移:** 将现有模型库数据安全地迁移到云平台,并确保数据完整性。
4. **配置与测试:** 在云平台上配置必要的模型库管理工具,并进行全面测试确保功能正常。
云服务可以帮助团队实现分布式模型库管理,允许来自不同地理位置的团队成员协同工作,提高工作效率。
## 6.2 面临的挑战与应对策略
### 6.2.1 面临的行业挑战与发展趋势
模型库管理领域正面临着包括技术变革、法规合规和市场竞争在内的多方面挑战。随着技术的快速迭代,管理者需要不断提升自己的技能以适应新技术。此外,数据隐私和安全法规的更新也对模型库管理提出了更高的要求。
**行业发展的趋势:**
- **数字化转型:** 随着数字化转型的不断深入,模型库将变得更加智能化、自动化。
- **全球化协同:** 模型库管理将更加注重全球化协同,需要构建支持多语言和文化的管理平台。
- **数据驱动决策:** 数据驱动决策将成为模型库管理中的重要趋势,数据的准确性、及时性和全面性变得尤为重要。
### 6.2.2 战略规划与持续改进路径
为了应对上述挑战,模型库管理者需要制定清晰的战略规划,并不断进行持续改进。
**战略规划的关键点:**
1. **长期目标设定:** 明确模型库长期发展的目标和里程碑,以适应未来的变化。
2. **技术升级计划:** 定期评估新兴技术,并制定相应的升级计划。
3. **人员培训与发展:** 定期为团队成员提供技术培训,鼓励技能提升和职业发展。
4. **流程优化:** 定期审查和优化管理流程,确保流程的高效率和灵活性。
**持续改进的实施方法:**
- **收集反馈:** 积极收集内部和外部用户对模型库管理的反馈。
- **定期评审:** 定期进行项目评审会议,讨论问题和改进措施。
- **质量保证:** 引入质量保证流程,确保每次改进都能带来实质性的效益。
未来模型库管理不仅需要技术和工具的创新,还需要对管理和运营模式进行持续的优化和改进,以满足不断变化的业务需求和技术发展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入解读NIST随机数测试标准:掌握随机性质量的关键与操作步骤

参考资源链接:[NIST随机数测试标准中文详解及16种检测方法](https://wenku.csdn.net/doc/1cxw8fybe9?spm=1055.2635.3001.10343)
# 1. 随机数生成器的重要性与应用
随机数生成
ATS2825实践指南:5个步骤教会你如何有效阅读技术数据手册

参考资源链接:[ATS2825:高集成蓝牙音频SoC解决方案](https://wenku.csdn.net/doc/6412b5cdbe7fbd1778d4471c?spm=1055.2635.3001.10343)
# 1. 理解技术数据手册的重要性
在技术行业,数据手册是连接工程师与产品之间的桥梁。技术数据手册详细记录了产品规格、性能参数及应用指南,是开发、维护
【图论与组合之美】:如何在复杂网络中运用组合数学(IT精英专属)
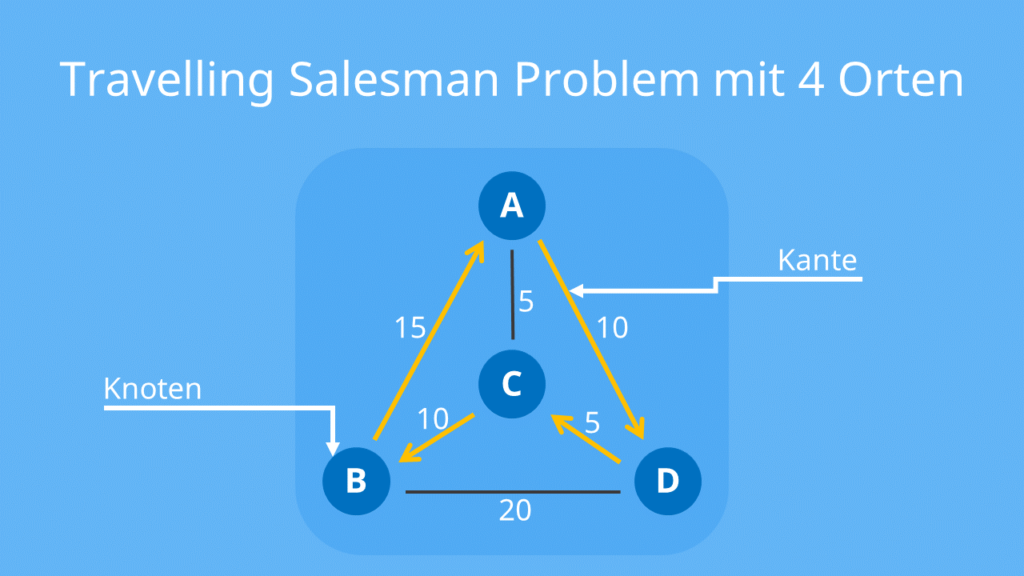
参考资源链接:[组合理论及其应用 李凡长 课后习题 答案](https://wenku.csdn.net/doc/646b0b685928463033e5bca7?spm=1055.2635.3001.10343)
# 1. 图论与组合数学基础
图论和组合数学是研究离散结构的数学分
立即掌握:HK4100F继电器驱动电路设计与优化技巧
参考资源链接:[hk4100f继电器引脚图及工作原理详解](https://wenku.csdn.net/doc/6401ad19cce7214c316ee482?spm=1055.2635.3001.10343)
# 1. HK4100F继电器驱动电路简介
继电器驱动电路是电子系统中重要的组件,负责控制继电器的动作,以实现电路的开关、转换、控制等功能。HK4100F是一种广泛应用于工业控制、家用电器、汽车电子等领域的高性能继电器。本文将首先对HK4100F继电器驱动电路进行简要介绍,阐述其基本功能和应用场景,为后续章节深入探讨其设计理论基础、电路设计实践、性能优化、自动化测试及创新应用奠定
【仿真分析新手上路】:电路设计仿真工具的必备技巧全攻略

参考资源链接:[大电容LDO中的Miller补偿:误区与深度解析](https://wenku.csdn.net/doc/1t74pjtw6m?spm=1055.2635.3001.10343)
# 1. 电路设计仿真工具概述
## 简介
在现代电子设计工程中,电路设计仿真工具扮演着至关重要的角色。它们不仅能够模拟实际电路在不同工作条件下的行为,而且能够帮助工程师在物理原型
【ISO 11898-1标准深度解析】:精通CAN通信协议的5大关键

参考资源链接:[ISO 11898-1 中文](https://wenku.csdn.net/doc/6412b72bbe7fbd1778d49563?spm=1055.2635.3001.10343)
# 1. CAN通信协议概述
## 1.1 CAN通信协议的诞生与应用领域
控制器局域网络(CAN)通信协议由德国Bosch公司于1980年代初期开发,最初用于汽车内部的微控制器和设备之间的通信
【高级故障排除】:Tc3卡壳卸载?专家级别的解决策略

参考资源链接:[TwinCAT 3软件卸载完全指南](https://wenku.csdn.net/doc/1qen88ydgt?spm=1055.2635.3001.10343)
# 1. Tc3卡故障排除概述
## 1.1 Tc3卡故障排除的重要性
在当今高度依赖技术的商业环境中,Tc3卡作为关键硬件组件,其稳定性和效率对整个系统的性能至关重要。当Tc3卡发生故障
【VPX硬件设计与实现秘籍】:遵循VITA 46-2007,打造高效嵌入式系统
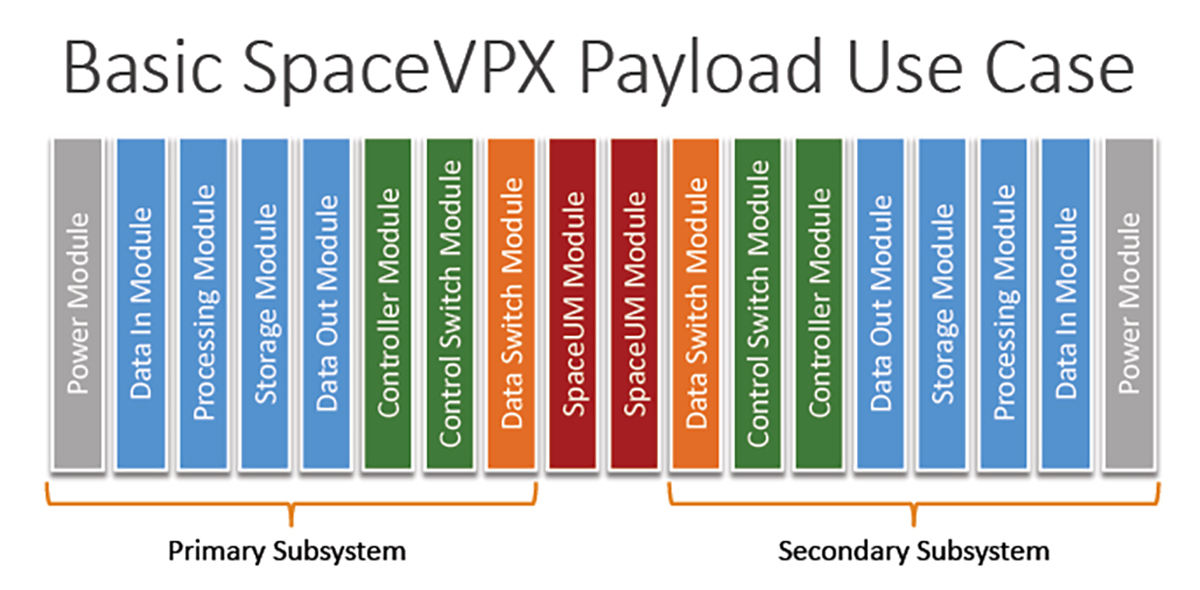
参考资源链接:[VPX基础规范(VITA 46-2007):VPX技术详解与标准入门](https://wenku.csdn.net/doc/6412b7abbe7fbd1778d4b1da?spm=1055.2635.3001.10343)
# 1. VPX技术标准概览
VPX,或VITA
PL_0编译器优化秘籍:技术细节与实践应用全面解读

参考资源链接:[PL/0编译程序研究与改进:深入理解编译原理和技术](https://wenku.csdn.net/doc/20is1b3xn1?spm=1055.2635.3001.10343)
# 1. PL_0编译器优化概述
## 1.1 什么是PL_0编译器优化
PL_0编译
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )