SQLAlchemy元数据操作秘籍:表定义与数据库结构管理
发布时间: 2024-10-14 17:10:16 阅读量: 32 订阅数: 35 

使用SQLAlchemy操作数据库表过程解析

# 1. SQLAlchemy基础介绍
SQLAlchemy是一个强大的Python SQL工具包和对象关系映射(ORM)库。它为用户提供了一种高级、可扩展且易于使用的方式来处理SQL数据库。SQLAlchemy允许开发者用Python语言直接与数据库进行交互,而无需深入底层的SQL语法。这种抽象化的方法不仅简化了数据库操作,还增加了代码的可读性和可维护性。
## 1.1 ORM的概念和作用
对象关系映射(ORM)是一种编程技术,用于将不兼容的对象模型转换为关系模型。在使用SQLAlchemy时,开发者可以通过定义Python类来映射数据库中的表,并通过实例化这些类来操作数据库中的记录。这种映射使得开发者能够以面向对象的方式思考和工作,而不需要编写原始的SQL代码。
## 1.2 SQLAlchemy的安装和配置
在开始使用SQLAlchemy之前,您需要确保已经安装了这个库。可以通过Python的包管理器pip来安装:
```bash
pip install sqlalchemy
```
安装完成后,您就可以开始配置您的数据库引擎和会话,这是与数据库交互的第一步。接下来的章节将详细介绍这些内容。
# 2. 元数据操作的核心概念
在本章节中,我们将深入探讨SQLAlchemy的核心概念,特别是元数据操作的各个方面。这包括ORM映射基础、数据库引擎的创建与配置、元数据对象的作用和声明式基类的使用。这些概念是构建复杂数据库结构和进行高效数据操作的基石。
## 2.1 SQLAlchemy的ORM映射基础
ORM(Object-Relational Mapping)技术使得开发者能够使用面向对象的方式来操作数据库。通过将数据库表映射为Python对象,ORM抽象了底层的SQL操作,简化了数据访问逻辑。
### 2.1.1 ORM与关系型数据库的关系
ORM框架的主要目的是将对象模型映射到关系型数据库的表结构。这一映射过程涉及到对象的创建、读取、更新和删除操作(CRUD)与SQL语句的转换。在SQLAlchemy中,这种映射是通过定义模型类和它们之间的关系来实现的。
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
```
在上面的代码示例中,我们定义了一个`User`类,它映射到数据库中的`users`表。每个类的属性对应表中的一列,而类本身则代表了表的结构。
### 2.1.2 SQLAlchemy中的模型定义
在SQLAlchemy中,模型定义是通过声明式基类完成的。这个基类提供了一种方式来定义模型类,并自动处理映射过程中的元数据。
```python
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine('sqlite:///example.db')
Session = sessionmaker(bind=engine)
session = Session()
Base.metadata.create_all(engine)
```
在这个例子中,我们创建了一个SQLite数据库引擎,并定义了一个会话类`Session`。通过调用`Base.metadata.create_all(engine)`,SQLAlchemy会自动创建对应的表结构。
## 2.2 SQLAlchemy的引擎和连接
引擎和连接是SQLAlchemy进行数据库操作的核心组件。引擎代表了数据库的连接池,而连接则是与数据库进行交互的会话。
### 2.2.1 数据库引擎的创建和配置
数据库引擎是SQLAlchemy中抽象数据库连接的核心接口。它可以配置为支持不同的数据库连接字符串,例如SQLite、MySQL、PostgreSQL等。
```python
from sqlalchemy import create_engine
engine = create_engine('sqlite:///example.db')
```
在这个例子中,我们创建了一个SQLite数据库引擎。引擎对象可以用来创建连接和会话,并且可以配置数据库连接参数,如URL、用户名、密码等。
### 2.2.2 数据库连接与会话管理
会话对象代表了与数据库的当前会话。它负责管理事务,并提供了操作数据库的方法。
```python
Session = sessionmaker(bind=engine)
session = Session()
```
在这个例子中,我们使用`sessionmaker`创建了一个会话工厂`Session`。通过调用`Session()`,我们得到了一个会话实例`session`,它可以用来执行数据库操作。
## 2.3 元数据对象和声明式基类
元数据对象和声明式基类是SQLAlchemy构建模型和管理数据库结构的重要组成部分。
### 2.3.1 元数据对象的作用和创建
元数据对象包含了关于数据库表和列的描述信息。这些信息用于在ORM映射过程中自动生成表结构。
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
```
在这个例子中,`declarative_base()`创建了一个声明式基类`Base`,它包含了关于表结构的元数据。
### 2.3.2 声明式基类的使用和优势
声明式基类提供了一种声明式的方式来定义模型。它简化了ORM映射的复杂性,并提供了代码组织的便利。
```python
Base.metadata.create_all(engine)
```
通过调用`Base.metadata.create_all(engine)`,SQLAlchemy会自动创建所有通过声明式基类定义的表结构。这使得数据库迁移和版本控制变得更加容易。
通过本章节的介绍,我们了解了SQLAlchemy的ORM映射基础、数据库引擎和连接的创建与配置、以及元数据对象和声明式基类的作用。这些是使用SQLAlchemy进行数据库操作的基础,也是构建复杂数据库结构的前提。在接下来的章节中,我们将深入探讨表定义、数据库结构的动态创建与修改、表关系、会话管理等高级主题。
# 3. 表定义与数据类型映射
在本章节中,我们将深入探讨SQLAlchemy中表定义和数据类型映射的相关知识,这是构建数据库结构的基础。我们将从数据类型和字段的映射开始,然后讨论表的继承和关联关系,最后介绍约束和索引的定义及其在数据库设计中的应用。通过本章节的介绍,你将能够掌握如何在SQLAlchemy中定义表结构,并对数据库表进行优化,以提高数据完整性和查询效率。
## 3.1 SQLAlchemy的数据类型和字段
### 3.1.1 标准SQL数据类型映射
在SQLAlchemy中,数据类型映射是将Python数据类型转换为SQL数据类型的桥梁。SQLAlchemy提供了与SQL标准数据类型相对应的Python表示,同时也支持许多数据库特定的数据类型。例如,我们可以使用`Integer`代表整型,`String`代表字符串类型,`DateTime`代表日期时间类型等。
```python
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
created_at = Column(DateTime)
```
在上述代码中,我们定义了一个简单的`User`模型,其中包含了三个字段:`id`(整型,主键),`name`(字符串),和`created_at`(日期时间类型)。
### 3.1.2 字段定义与选项设置
SQLAlchemy允许我们在字段定义时设置各种选项,以满足不同的需求。例如,我们可以为字段设置默认值、非空约束、唯一约束等。这些选项可以通过字段构造器中的参数来设置。
```python
from sqlalchemy import create_engine, Column, Integer, String, UniqueConstraint
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50), unique=True, nullable=False)
email = Column(String(120), unique=True)
age = Column(Integer)
__table_args__ = (
UniqueConstraint('email'),
)
```
在上述代码中,我们为`name`字段设置了最大长度为50的字符串类型,并且添加了唯一约束和非空约束。同时,我们还为`email`字段添加了唯一约束,通过`__table_args__`属性在表级别添加了额外的约束。
## 3.2 表的继承和关联关系
### 3.2.1 单表继承的实现
在SQLAlchemy中,我们可以通过声明式基类来实现单表继承。单表继承是一种设计模式,它允许多个子类共享同一张表的大部分字段。我们可以在基类中定义共享字段,然后在子类中定义额外的字段。
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship
Base = declarative_base()
class Person(Base):
__tablename__ = 'persons'
id = Column(Integer, primary_key=True)
name = Column(String)
class Employee(Person):
__tablename__ = 'employees'
id = Column(Integer, ForeignKey('persons.id'), primary_key=True)
department_id = Column(Integer)
class Customer(Person):
__tablename__ = 'customers'
id = Column(Integer, ForeignKey('persons.id'), primary_key=True)
customer_level = Column(String)
```
在上述代码中,我们定义了一个`Person`基类,其中包含了`id`和`name`字段。然后我们定义了`Employee`和`Customer`两个子类,它们都继承了`Person`类的字段,并且添加了各自特有的字段。
### 3.2.2 多表之间的关联映射
多表之间的关联映射是数据库设计中的常见需求,它允许我们将数据分散到不同的表中,同时还能维护表之间的关系。SQLAlchemy提供了多种关联映射的方式,包括一对多、多对多等。
```python
from sqlalchemy import create_engine, Column, Integer, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Department(Base):
__tablename__ = 'departments'
id = Column(Integer, primary_key=True)
name = Column(String)
class Employee(Base):
__tablename__ = 'employees'
id = Column(Integer, primary_key=True)
name = Column(String)
department_id = Column(Integer, ForeignKey('departments.id'))
department = relationship("Department")
class Manager(Employee):
__tablename__ = 'managers'
id = Column(Integer, ForeignKey('employees.id'), primary_key=True)
```
在上述代码中,我们定义了`Department`和`Employee`两个类,它们通过`department_id`字段建立了外键关系。同时,我们还定义了一个`Manager`类,它继承自`Employee`类,并且通过`ForeignKey`关联回`Employee`表。
## 3.3 约束和索引的定义
### 3.3.1 各种约束的声明与应用
约束是数据库设计中保证数据完整性的关键机制。SQLAlchemy支持多种约束,包括主键约束、唯一约束、外键约束等。我们可以使用字段构造器中的参数或者`__table_args__`属性来声明这些约束。
### 3.3.2 索引的创建与优化
索引是提高数据库查询性能的重要工具。SQLAlchemy允许我们为模型定义索引,以优化特定字段的查询性能。我们可以使用`Index`类或者在字段构造器中使用`index`参数来创建索引。
```python
from sqlalchemy import Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String, index=True)
email = Column(String, unique=True)
Index('idx_user_name', User.name)
```
在上述代码中,我们为`User`模型的`name`字段创建了一个索引。此外,我们还通过`__table_args__`属性为`email`字段添加了唯一约束。
### 本章节介绍
在本章节中,我们介绍了SQLAlchemy中表定义和数据类型映射的基本概念和使用方法。我们讨论了数据类型的映射、字段的定义与选项设置、单表继承的实现、多表之间的关联映射、约束和索引的定义等内容。通过本章节的介绍,你应该能够理解并应用SQLAlchemy中的表定义和数据类型映射,以及如何优化数据库结构设计,以提高数据完整性和查询性能。
## 3.3.1 各种约束的声明与应用
在本节中,我们将深入探讨SQLAlchemy中的各种约束,这些约束包括主键约束、唯一约束、外键约束以及检查约束。这些约束是保证数据完整性和一致性的重要机制,它们确保数据库中的数据满足特定的业务规则。
### 主键约束(Primary Key)
主键约束是最常见的约束之一,它用于唯一标识表中的每一行记录。在

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析 SQLAlchemy 库,涵盖其核心概念、会话管理、映射技术、查询构建、关系映射、异常处理、JOIN 操作、高级特性、性能优化、数据库迁移、单元测试、高级配置、Django 集成、元数据操作、事务处理、ORM 事件处理、ORM 高级特性和安全性。通过一系列文章,本专栏旨在帮助开发者掌握 SQLAlchemy 的精髓,提升数据库操作效率,打造健壮可靠的应用程序。从基础概念到高级技巧,本专栏提供全面的指南,助力开发者充分利用 SQLAlchemy 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【16位加法器设计秘籍】:全面揭秘高性能计算单元的构建与优化

# 摘要
本文对16位加法器进行了全面的研究和分析。首先回顾了加法器的基础知识,然后深入探讨了16位加法器的设计原理,包括二进制加法基础、组成部分及其高性能设计考量。接着,文章详细阐述
三菱FX3U PLC编程:从入门到高级应用的17个关键技巧

# 摘要
三菱FX3U PLC是工业自动化领域常用的控制器之一,本文全面介绍了其编程技巧和实践应用。文章首先概述了FX3U PLC的基本概念、功能和硬件结构,随后深入探讨了
【Xilinx 7系列FPGA深入剖析】:掌握架构精髓与应用秘诀
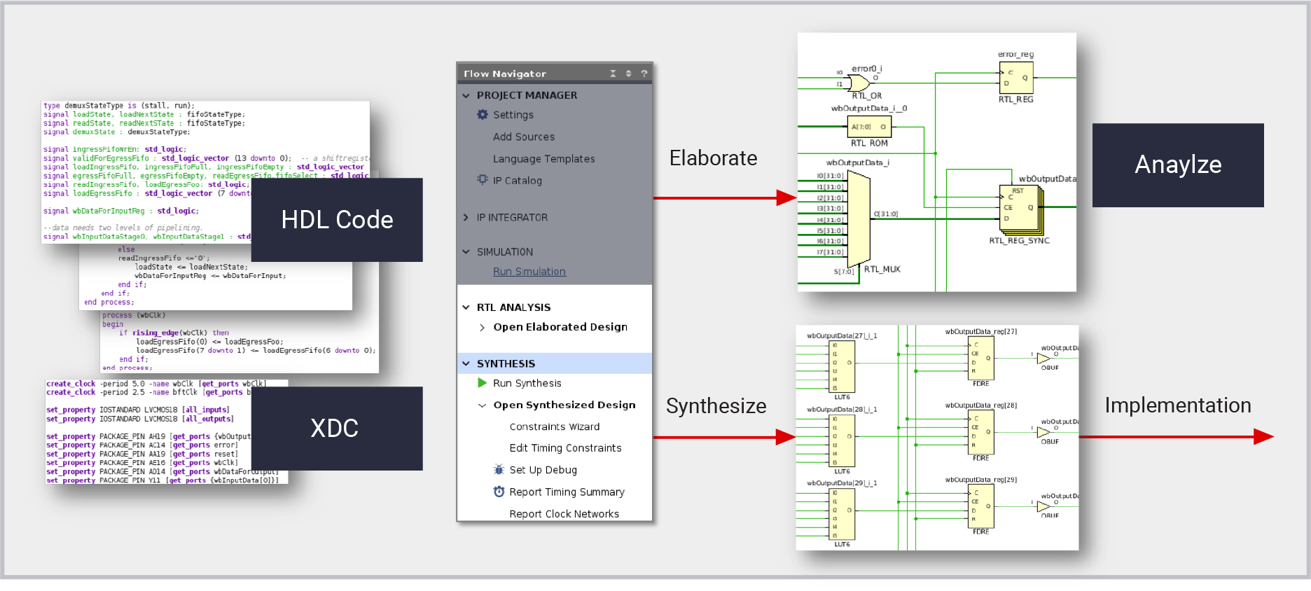
# 摘要
本文详细介绍了Xilinx 7系列FPGA的关键特性及其在工业应用中的广泛应用。首先概述了7系列FPGA的基本架构,包括其核心的可编程逻辑单元(PL)、集成的块存储器(BRAM)和数字信号处理(DSP)单元。接着,本文探讨了使用Xilinx工具链进行FPGA编程与配置的流程,强调了设计优化和设备配置的重要性。文章进一步分析了7系列FPGA在
【图像技术的深度解析】:Canvas转JPEG透明度保护的终极策略

# 摘要
随着Web技术的不断发展,图像技术在前端开发中扮演着越来越重要的角色。本文首先介绍了图像技术的基础和Canvas绘
【MVC标准化:肌电信号处理的终极指南】:提升数据质量的10大关键步骤与工具
# 摘要
MVC标准化是肌电信号处理中确保数据质量的重要步骤,它对于提高测量结果的准确性和可重复性至关重要。本文首先介绍肌电信号的生理学原理和MVC标准化理论,阐述了数据质量的重要性及影响因素。随后,文章深入探讨了肌电信号预处理的各个环节,包括噪声识别与消除、信号放大与滤波技术、以及基线漂移的校正方法。在提升数据质量的关键步骤部分,本文详细描述了信号特征提取、MVC标准化的实施与评估,并讨论了数据质量评估与优化工具。最后,本文通过实验设计和案例分析,展示了MVC标准化在实践应用中的具
ISA88.01批量控制:电子制造流程优化的5大策略

# 摘要
本文首先概述了ISA88.01批量控制标准,接着深入探讨了电子制造流程的理论基础,包括原材料处理、制造单元和工作站的组成部分,以及流程控制的理论框架和优化的核心原则。进一步地,本文实
【Flutter验证码动画效果】:如何设计提升用户体验的交互

# 摘要
随着移动应用的普及和安全需求的提升,验证码动画作为提高用户体验和安全性的关键技术,正受到越来越多的关注。本文首先介绍Flutter框架下验证码动画的重要性和基本实现原理,涵盖了动画的类型、应用场景、设计原则以及开发工具和库。接着,文章通过实践篇深入探讨了在Flutter环境下如何具体实现验证码动画,包括基础动画的制作、进阶技巧和自定义组件的开发。优化篇
ENVI波谱分类算法:从理论到实践的完整指南
# 摘要
ENVI软件作为遥感数据处理的主流工具之一,提供了多种波谱分类算法用于遥感图像分析。本文首先概述了波谱分类的基本概念及其在遥感领域的重要性,然后介绍了ENVI软件界面和波谱数据预处理的流程。接着,详细探讨了ENVI软件中波谱分类算法的实现方法,通过实践案例演示了像元级和对象级波谱分类算法的操作。最后,文章针对波谱分类的高级应用、挑战及未来发展进行了讨论,重点分析了高光谱数据分类和深度学习在波谱分类中的应用情况,以及波谱分类在土地覆盖制图和农业监测中的实际应用。
# 关键字
ENVI软件;波谱分类;遥感图像;数据预处理;分类算法;高光谱数据
参考资源链接:[使用ENVI进行高光谱分
【天线性能提升密籍】:深入探究均匀线阵方向图设计原则及案例分析
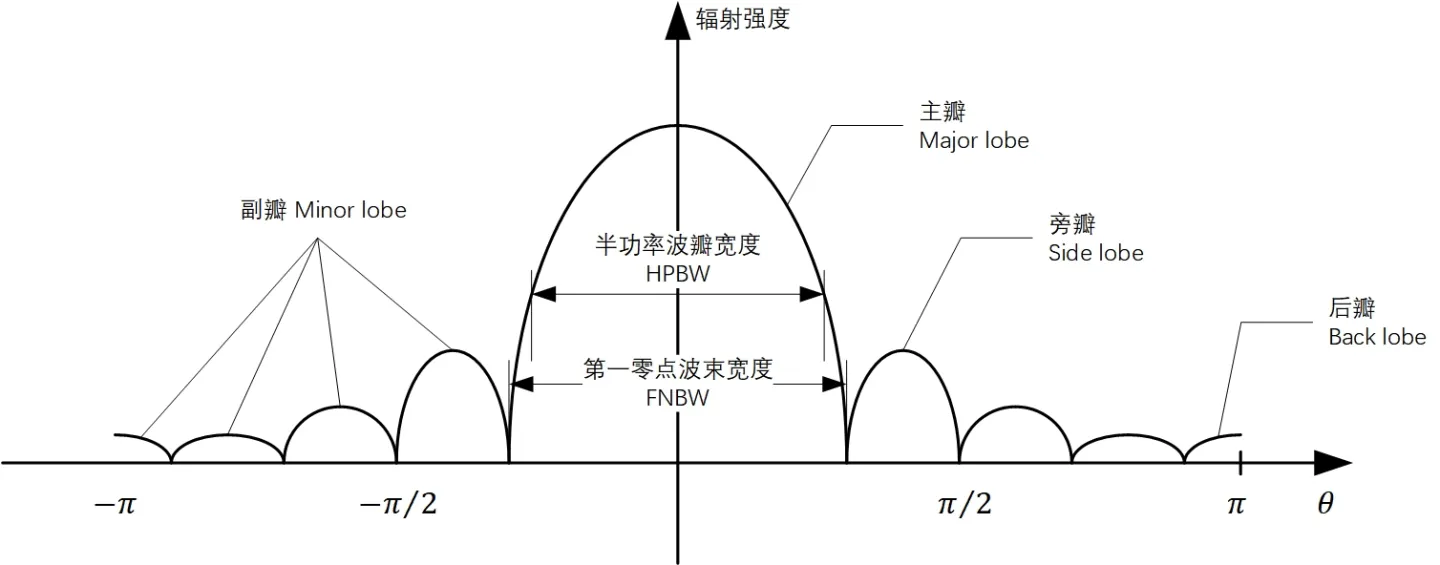
# 摘要
本文深入探讨了均匀线阵天线的基础理论及其方向图设计,旨在提升天线系统的性能和应用效能。文章首先介绍了均匀线阵及方向图的基本概念,并阐述了方向图设计的理论基础,包括波束形成与主瓣及副瓣特性的控制。随后,论文通过设计软件工具的应用和实际天线系统调试方法,展示了方向图设计的实践技巧。文中还包含了一系列案例分析,以实证研究验证理论,并探讨了均匀线阵性能
【兼容性问题】快解决:专家教你确保光盘在各设备流畅读取
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/L/w/I3DfXKTAmrqNi0rGtG5A/2014-06-24-cd-dvd-bluray.png)
# 摘要
光盘作为一种传统的数据存储介质,其兼容性问题长
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )