AWS Redshift数据仓库的建立与优化
发布时间: 2024-02-25 16:34:14 阅读量: 46 订阅数: 46 

数据仓库构建
# 1. AWS Redshift数据仓库概述
## 1.1 什么是AWS Redshift数据仓库
AWS Redshift是亚马逊提供的一种高性能、可扩展的数据仓库解决方案,基于列存储技术,并且完全托管在云端。它能够处理大规模的数据,并支持高并发的复杂查询。Redshift还提供了易于使用的管理工具,方便用户进行数据加载、备份和扩展。
## 1.2 AWS Redshift的特点和优势
- **高性能**:Redshift利用列存储技术和并行处理能力,能够快速执行复杂的查询,适用于大规模数据分析和报告生成。
- **扩展性**:Redshift支持根据业务需求灵活地扩展数据仓库的规模,无需担心硬件或软件的限制。
- **易用性**:提供用户友好的管理控制台和工具,使得数据加载、备份、扩展等任务变得简单。
- **成本效益**:基于亚马逊云服务的模式,用户只需按照所使用的资源付费,无需关注基础设施的管理和维护。
- **兼容性**:Redshift兼容性强,支持大部分的SQL查询语法,并能够与众多BI工具和ETL工具集成。
## 1.3 Redshift与传统数据仓库的区别
相对于传统数据仓库,AWS Redshift在性能、扩展性和成本上有明显的优势。传统数据仓库往往需要大量的硬件投入以支持大规模的数据处理,而Redshift通过云端托管,极大地简化了硬件管理和维护工作。此外,Redshift的列存储和并行处理技术,使得它能够更快地处理复杂查询,并支持更大规模的数据。
# 2. AWS Redshift数据仓库的建立
在AWS Redshift数据仓库的建立过程中,我们需要依次完成以下几个步骤:创建AWS Redshift数据仓库、设置数据仓库基本配置以及数据加载与管理。
### 2.1 创建AWS Redshift数据仓库
首先,我们需要登录AWS管理控制台,选择Redshift服务,点击“创建数据仓库”按钮,填写相关配置信息,如数据仓库名称、节点类型、节点数量、VPC等。下面是一个示例代码片段,演示如何使用Boto3库创建一个AWS Redshift数据仓库:
```python
import boto3
redshift = boto3.client('redshift')
response = redshift.create_cluster(
ClusterIdentifier='my-redshift-cluster',
NodeType='dc2.large',
MasterUsername='admin',
MasterUserPassword='MyPassword',
ClusterSubnetGroupName='my-subnet-group',
VpcSecurityGroupIds=['sg-12345678'],
ClusterParameterGroupName='default',
Port=5439,
NumberOfNodes=2
)
print(response)
```
**代码说明:**
- 使用Boto3库创建一个AWS Redshift数据仓库。
- 设置数据仓库的基本配置,如集群标识符、节点类型、主用户名和密码、子网组、VPC安全组等。
- 打印创建数据仓库的响应信息。
### 2.2 设置数据仓库基本配置
在数据仓库创建完成后,我们需要设置数据仓库的基本配置,包括IAM角色授权、启用密钥访问、分配资源权限等。以下是一个示例代码片段,演示如何使用IAM角色授权Redshift访问S3:
```python
response = redshift.associate_data_share_consumer(
ClusterIdentifier='my-redshift-cluster',
DataShareArn='arn:aws:redshift:us-east-1:123456789012:datashare/my-datashare',
ConsumerIdentifier='arn:aws:redshift:us-east-1:123456789012:iamrole/my-redshift-role'
)
print(response)
```
**代码说明:**
- 使用Boto3库将IAM角色授权给Redshift集群。
- 指定数据共享ARN和消费者标识符。
- 打印关联数据分享的响应信息。
### 2

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在全面介绍AWS认证及相关考试准备知识,涵盖了搭建EC2实例、使用S3存储服务、介绍RDS与Aurora数据库、IAM身份与访问管理、CloudFormation模板编写、Route 53域名服务、CloudWatch监控系统配置、EKS容器服务部署、Kinesis流式数据处理、SNS消息通知服务以及KMS加密服务等多个主题。通过对这些关键内容的深入讲解,读者能够全面了解AWS各项服务的概述和基本用法,为取得AWS认证做好充分准备。无论是新手入门还是有经验者进阶,本专栏都能为读者提供实用指导和实战技巧,帮助他们更好地应对AWS考试及实际工作挑战。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
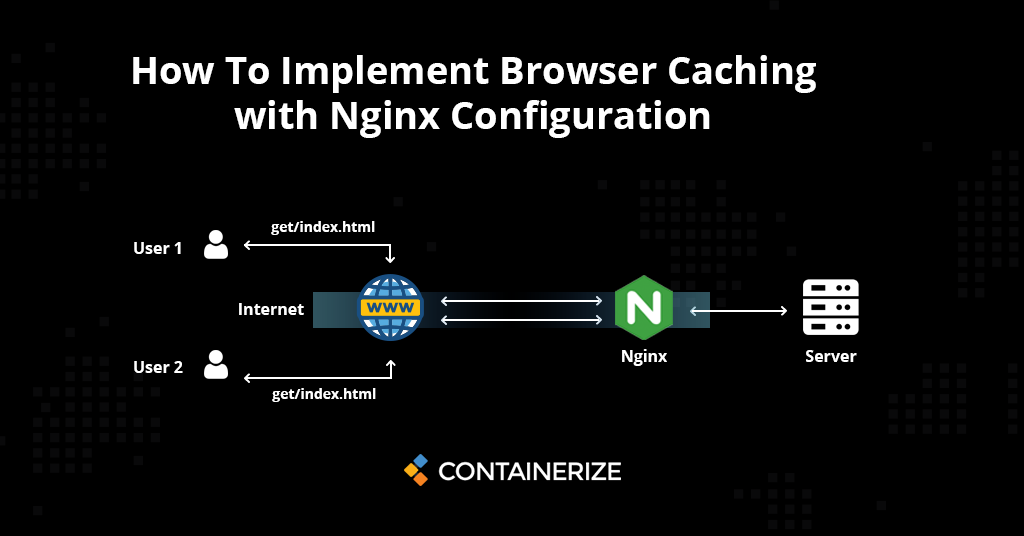
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )