Scala中基本数据类型详解与应用场景分析
发布时间: 2024-04-04 03:02:03 阅读量: 81 订阅数: 22 

Scala 数据类型 图表VISIO格式
# 1. 引言
在现代软件开发中,选择合适的数据类型是非常重要的。Scala作为一种静态类型的编程语言,具有丰富的数据类型系统,能够帮助开发者更好地管理数据和代码。本章将介绍Scala中基本数据类型的详细内容,并探讨它们在实际应用中的意义和场景。让我们一起深入了解Scala中的整型、浮点型、布尔型、字符型等数据类型,以及它们的应用原则和使用技巧。【这里是简要说明,具体内容请查看文章后续内容】
# 2. Scala中的整型数据类型
在Scala中,整型数据类型是非常常用的数据类型之一。Scala提供了几种整型数据类型,包括Int、Long、Short等,每种类型在内存中所占的空间大小和取值范围都有所不同。在实际编程中,我们需要根据数据的大小和精度需求来选择合适的整型数据类型,以提高程序性能和节约内存空间。
### 2.1 Int类型
Int类型是Scala中最常用的整型数据类型之一,它表示32位有符号整数。Int类型的取值范围为-2147483648到2147483647,适合大多数整数运算场景。
```scala
val num1: Int = 100
val num2: Int = 200
val sum: Int = num1 + num2
println(s"The sum of $num1 and $num2 is $sum")
```
**代码说明:**
- 定义了两个Int类型的变量`num1`和`num2`,并计算它们的和赋值给变量`sum`。
- 最后通过println函数输出了两个整数的和。
**代码执行结果:**
```
The sum of 100 and 200 is 300
```
### 2.2 Long类型
Long类型是表示64位有符号整数的数据类型,在需要处理更大整数值的场景下非常有用。Long类型的取值范围为-9223372036854775808到9223372036854775807。
```scala
val bigNum1: Long = 1234567890123456789L
val bigNum2: Long = 9876543210987654321L
val product: Long = bigNum1 * bigNum2
println(s"The product of $bigNum1 and $bigNum2 is $product")
```
**代码说明:**
- 定义了两个Long类型的变量`bigNum1`和`bigNum2`,并计算它们的乘积赋值给变量`product`。
- 最后通过println函数输出了两个大整数的乘积。
**代码执行结果:**
```
The product of 1234567890123456789 and 9876543210987654321 is -8424397003403217027
```
### 2.3 Short类型
Short类型表示16位有符号整数,适用于对内存消耗有严格要求的场景。Short类型的取值范围为-32768到32767。
```scala
val smallNum1: Short = 1000
val smallNum2: Short = 2000
val difference: Short = (smallNum1 - smallNum2).toShort
println(s"The difference between $smallNum1 and $smallNum2 is $difference")
```
**代码说明:**
- 定义了两个Short类型的变量`smallNum1`和`smallNum2`,计算它们的差值并强制转换为Short类型赋值给变量`difference`。
- 最后通过println函数输出了两个短整数的差值。
**代码执行结果:**
```
The difference between 1000 and 2000 is -1000
```
通过以上示例,我们可以看到Scala中整型数据类型的使用方法和场景。在选择整型数据类型时,要根据实际需求合理选择,以确保程序运行的效率和准确性。
# 3. Scala中的浮点型数据类型
在Scala中,浮点型数据类型包括Float和Double两种,用于表示带有小数点的数值。下面我们来详细探讨这两种数据类型的特点和应用场景。
#### 1. Float类型
Float类型在Scala中用于表示单精度浮点数,占据32位(4个字节)内存空间。它可以表示大约6到7位有效数字,并且范围相对有限。在实际编程中,通常使用Float类型来表示需要节省内存空间或者对精度要求不高的浮点数。
下面是一个示例代码,演示了Float类型的声明和初始化:
```scala
val floatValue: Float = 3.14159f
```
#### 2. Double类型
Double类型在Scala中用于表示双精度浮点数,占据64位(8个字节)内存空间。它可以表示大约15位有效数字,范围更广,精度更高。在实际编程中,通常使用Double类型来表示需要更高精度的浮点数。
下面是一个示例代码,演示了Double类型的声明和初始化:
```scala
val doubleValue: Double = 3.14159
```
#### 3. 浮点数的注意事项
在处理浮点数时,我们需要注意浮点数的精度问题。由于计算机内部表示浮点数时采用二进制,所以在某些情况下会出现精度丢失的问题。因此,在比较浮点数是否相等时,不建议直接使用等号进行比较,而是考虑使用一个误差范围来判断。
总的来说,通过本章内容的学习,我们深入了解了Scala中的浮点型数据类型及其应用场景,同时也了解了在处理浮点数时需要注意的问题。在实际编程中,根据需求选择合适的浮点型数据类型是非常重要的。
# 4. Scala中的布尔型数据类型
在Scala中,布尔型数据类型Boolean用于表示逻辑值,即True(真)或False(假)。布尔型数据类型在逻辑运算和条件判断中发挥着重要作用,常常用于控制程序的流程和逻辑。
#### 1. 布尔型数据类型的定义和赋值
在Scala中,可以使用关键字`true`和`false`来定义布尔型变量,例如:
```scala
val isScalaFun: Boolean = true
val isJavaFun: Boolean = false
```
#### 2. 布尔型数据类型的逻辑运算
布尔型数据类型可以进行逻辑运算,包括与(&&)、或(||)和非(!)操作,例如:
```scala
val x: Boolean = true
val y: Boolean = false
val andResult: Boolean = x && y // 逻辑与运算,结果为false
val orResult: Boolean = x || y // 逻辑或运算,结果为true
val notResult: Boolean = !x // 逻辑非运算,结果为false
```
#### 3. 布尔型数据类型在条件判断中的应用
在Scala的条件语句中经常使用布尔型数据类型进行条件判断,例如:
```scala
val age: Int = 18
val isAdult: Boolean = age >= 18
if (isAdult) {
println("成年人")
} else {
println("未成年人")
}
```
#### 4. 实际案例展示
下面通过一个简单的实际案例展示布尔型数据类型的使用方法,在这个示例中,我们判断一个人的年龄是否为偶数:
```scala
val age: Int = 20
val isEven: Boolean = age % 2 == 0
if (isEven) {
println("年龄是偶数")
} else {
println("年龄是奇数")
}
```
通过以上内容,读者可以更深入地了解Scala中布尔型数据类型的定义、运算和应用场景。在实陃编程中,合理地应用布尔型数据类型可以提高程序的逻辑性和可读性。
# 5. Scala中的字符型数据类型
在Scala中,字符型数据类型Char代表了单个字符,使用单引号来表示,如`'a'`、`'b'`等。和Java不同的是,Scala中的Char类型是统一采用Unicode编码的,故支持更多字符。
### Unicode编码
Unicode编码是一种为世界上所有文字和符号统一编码的方案,通过使用不同的编码点来表示字符。在Scala中,Char类型可以表示Unicode范围内的字符,包括英文字母、汉字、表情符号等。例如:
```scala
val chineseChar: Char = '好'
val smileyFace: Char = '\uD83D\uDE00'
```
### 字符型数据类型的应用
在实际编程中,字符型数据类型Char常用于处理用户输入和字符串操作中。例如,可以使用Char类型进行字符匹配,判断用户输入是否合法等操作。下面是一个简单的示例:
```scala
val inputChar: Char = readChar() // 从用户输入获取一个字符
if(inputChar.isDigit) {
println("输入的是数字")
} else if(inputChar.isLetter) {
println("输入的是字母")
} else {
println("输入的是特殊字符")
}
```
### 总结
字符型数据类型Char在Scala中具有广泛的应用场景,可以用于表示各种字符并进行相关操作。通过Unicode编码的支持,Char类型可以处理各种国际文字和符号,为字符串处理提供了更大的灵活性。在编程过程中,合理利用字符型数据类型能够让代码更具表现力和实用性。
# 6. Scala中的特殊数据类型
在Scala中除了常见的整型、浮点型、布尔型和字符型数据类型外,还存在一些特殊的数据类型,它们在编程中起着特殊的作用。让我们一起来了解这些特殊数据类型:
1. **Unit类型:** 在Scala中,Unit类型对应Java中的void类型,表示不返回任何有用的值。它通常用于函数没有返回值的情况。
```scala
// 示例代码
def printHello(): Unit = {
println("Hello, Scala!")
}
val result = printHello()
println(result) // 输出:()
```
2. **Null类型:** Null类型是AnyRef的子类型,它只有一个实例值null。在Scala中,任何引用类型都可以赋值为null。
```scala
// 示例代码
val str: String = null
println(str) // 输出:null
```
3. **Nothing类型:** Nothing类型是所有类型的子类型,但没有任何实例对象。通常在抛出异常或表示永远不会返回结果的函数中使用。
```scala
// 示例代码
def throwError(message: String): Nothing = {
throw new Exception(message)
}
val result = throwError("An error occurred.")
println(result) // 该行代码不会执行
```
特殊数据类型在Scala编程中具有独特的意义和用途,合理运用它们可以使代码更加简洁和灵活。通过以上示例,希望读者能够更好地理解Scala中特殊数据类型的用法和实际应用场景。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在通过一系列文章,全面介绍 Scala 语言在数据处理领域的应用。文章涵盖 Scala 编程基础、数据类型、集合类型、函数式编程、面向对象编程、异常处理、并发编程、ETL 数据抽取、数据库连接、数据增量抽取、JSON 数据处理、Hive 数据仓库集成、模式匹配、Spark 框架、Spark 作业优化、Hive 数据读写、数据质量处理、闭包和高阶函数、时间窗口事件数据处理等各个方面。通过深入浅出的讲解和丰富的示例,本专栏将帮助读者掌握 Scala 在数据处理领域的强大功能,并将其应用于实际项目中,提升数据处理效率和数据分析能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FANUC机器人:系统恢复完整攻略】

# 摘要
本文全面介绍了FANUC机器人系统的备份与恢复流程。首先概述了FANUC机器人系统的基本概念和备份的重要性。随后,深入探讨了系统恢复的理论基础,包括定义、目的、类型、策略和必要条件。第三章详细阐述了系统恢复的实践操作,包括恢复步骤、问题排除和验证恢复后的系统功能。第四章则提出了高级技巧,如安全性考虑、自定义恢复方案和优化维护策略。最后,第五章通过案例分析,展示了系统恢复的成
深入解析Linux版JDK的内存管理:提升Java应用性能的关键步骤
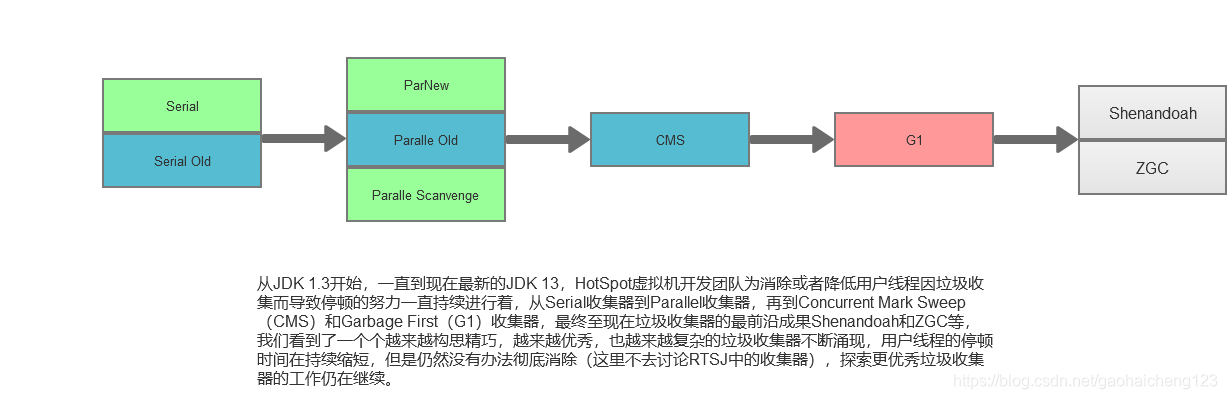
# 摘要
本文全面探讨了Java内存管理的基础知识、JDK内存模型、Linux环境下的内存监控与分析、以及内存调优实践。详细阐述了
AutoCAD中VLISP编程的进阶之旅:面向对象与过程的区别

# 摘要
本文全面概述了VLISP编程语言的基础知识,并深入探讨了面向对象编程(OOP)在VLISP中的应用及其与过程式编程的对比。文中详细介绍了类、对象、继承、封装、多态性等面向对象编程的核心概念,并通过AutoCAD中的VLISP类实例展示如何实现对象的创建与使用。此外,文章还涵盖了过程式编程技巧,如函数定义、代码组织、错误处理以及高级过程式技术。在实践面向对象编程方面,探讨了高级特性如抽象类和接
【FABMASTER高级建模技巧】:提升3D设计质量,让你的设计更加完美

# 摘要
本文旨在介绍FABMASTER软件中高级建模技巧和实践应用,涵盖了从基础界面使用到复杂模型管理的各个方面。文中详细阐述了FABMASTER的建模基础,包括界面布局、工具栏定制、几何体操作、材质与纹理应用等。进一步深入探讨了高级建模技术,如曲面建模、动态与程序化建模、模型管理和优化。通过3D设计实践应用的案例,展示
汽车市场与销售专业术语:中英双语版,销售大师的秘密武器!

# 摘要
本文综述了汽车市场营销的核心概念与实务操作,涵盖了汽车销售术语、汽车金融与保险、售后服务与维护以及行业未来趋势等多个方面。通过对汽车销售策略、沟通技巧、性能指标的详尽解读,提供了全面的销售和金融服务知识。文章还探讨了新能源汽车市场与自动驾驶技术的发展,以及汽车行业的未来挑战。此外,作者分享了汽车销售大师的实战技巧,包括策略制定、技术工具
【Infoworks ICM权限守护】:数据安全策略与实战技巧!
# 摘要
本文对Infoworks ICM权限守护进行深入探讨,涵盖了从理论基础到实践应用的各个方面。首先概述了权限守护的概念,随后详细介绍了数据安全理论基础,强调了数据保护的法律合规性和权限管理的基本原则。本文还深入分析了权限守护的实现机制,探讨了如何配置和管理权限、执行权限审核与监控,以及进行应急响应和合规性报告。文章的高级应用部分讨论了多租户权
多租户架构模式:大学生就业平台系统设计与实现的深入探讨

# 摘要
本文首先介绍了多租户架构模式的概念及其优势,随后深入探讨了其理论基础,包括定义、分类和数据隔离策略。接着,文章转向大学生就业平台系统的需求分析,明确了功能、性能、可用性和安全性等方面的需求。在此基础上,详细阐述了系统架构设计与实现过程中的关键技术和实现方法,以及系统测试与评估结果。最后,针对大学生就业平台
FreeRTOS死锁:预防与解决的艺术

# 摘要
FreeRTOS作为一款流行的实时操作系统,其死锁问题对于嵌入式系统的稳定性和可靠性至关重要。本文首先概述了死锁的概念、产生条件及其理论基础,并探讨了预防死锁的传统理论方法,如资源请求策略、资源分配图和银行家算法。接下来,本文深入研究了FreeRTOS资源管理机制,包括
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )