为什么要使用spark集群进行大规模数据处理?
发布时间: 2024-01-03 07:38:26 阅读量: 18 订阅数: 24 
## 1. 简介
### 1.1 什么是Spark集群?
Spark集群是一种用于大规模数据处理和分析的分布式计算框架。它使用内存计算和弹性扩展的方式,实现了高性能的数据处理和计算能力。Spark集群通过将任务分发到多个计算节点并进行并行计算,大大提升了数据处理的效率。
### 1.2 大规模数据处理的需求
随着互联网的普及和技术的不断发展,越来越多的数据被生成和记录下来。这些数据涵盖了各个领域,包括金融、医疗、电商、社交媒体等。传统的数据处理方法已经无法满足大规模数据处理的需求,需要一种高效、可扩展、易于使用的工具来处理数据。Spark集群应运而生,成为了处理大规模数据的首选工具之一。
## 2. Spark集群的优势
在大规模数据处理的背景下,Spark集群成为了一种广泛应用的解决方案。它具备许多优势,使得它在处理大规模数据时表现优秀。下面将详细介绍Spark集群的几个优势。
### 2.1 高性能计算
Spark集群通过将内存中的数据进行计算,相较于传统的磁盘读写方式,大大提高了计算速度。通过使用内存计算,Spark可以在内存中保持数据,并通过相互之间的共享,以及内存数据持久化的方式,实现快速的数据处理和计算。这种高性能计算的特点使得Spark集群在处理大规模数据时非常高效。
### 2.2 分布式数据处理
另一个Spark集群的优势是它的分布式数据处理能力。Spark集群能够将大规模数据分配到集群中的各个节点上进行处理。通过分布式数据处理,Spark能够利用集群的计算能力,实现并行计算,从而加快数据处理速度。这种分布式数据处理的能力使得Spark集群能够应对海量数据的处理需求。
### 2.3 弹性可扩展性
Spark集群具备弹性可扩展性的特点,可以根据实际的计算需求进行灵活的扩展和缩减。当需要处理的数据规模增加时,可以动态地增加集群中的节点,从而提供更多的计算资源。当数据规模减小或处理任务结束时,可以灵活地减少集群的节点数量,节约资源的使用。Spark集群的弹性可扩展性使得它适用于不同规模的数据处理任务。
通过上述几个优势,Spark集群在大规模数据处理的场景下发挥着重要的作用。在下面的章节中,我们将深入探讨Spark集群的组成与架构,以及它的应用实例和成功案例分析。
### 3. Spark集群的组成与架构
在本章中,我们将介绍Spark集群的基本组成和架构,理解这些概念对于使用和管理Spark集群来说是非常重要的。
#### 3.1 Spark的基本概念
在开始了解Spark集群的组成和架构之前,我们先来了解一些Spark的基本概念:
- **Spark应用程序(Application)**: 使用Spark的用户程序,可以基于Spark API编写,支持多种编程语言,如Java、Scala和Python。
- **驱动器程序(Driver program)**: Spark应用程序的入口点,负责定义任务的拓扑结构,设置各种参数,并与集群管理器进行通信。
- **执行器(Executors)**: 运行在集群中的工作节点上,负责执行任务并将结果返回给驱动器程序。每个执行器都有自己的Java虚拟机(JVM)实例,并且可以同时执行多个任务。
- **任务(Task)**: Spark应用程序在集群中执行的最小单位,通常是对数据集的操作,如转换(transformations)和行动(actions)。一个应用程序可以由多个任务组成。
#### 3.2 主要组件和功能
在Spark集群中,有一些核心组件和功能用于实现高效的数据处理和计算:
- **Spark Core**: 是Spark的基础库,提供了分布式任务调度、内存管理和错误恢复等功能。Spark Core也包括RDD(Resilient Distributed Datasets)的概念,它是Spark对分布式数据的抽象表示。
- **Spark SQL**: 提供用于SQL查询和处理结构化数据的功能。Spark SQL支持多种数据源,包括Hive、JSON、Parquet等,还可以将查询结果与Spark中的其他数据进行无缝集成。
- **Spark Streaming**: 提供了实时数据流处理的功能,可以对持续产生的流数据进行处理和分析。Spark Streaming使用微批处理的方式,将连续的数据流切割成小批量,并在每个批次内进行处理。
- **Spark MLlib**: 是Spark的机器学习库,提供了丰富的机器学习算法和工具,支持特征提取、模型训练和预测等任务。
- **Spark GraphX**: 是Spark的图处理库,提供了图计算和图分析的功能。Spark GraphX支持图的构建、图算法的执行和图可视化等操作。
#### 3.3 部署模式和架构设计
Spark集群的部署模式和架构设计取决于具体的使用场景和需求。在大规模数据处理的场景中,常用的部署模式有以下几种:
- **独立部署模式(Standalone Mode)**: Spark集群在独立模式下运行,使用自带的集群管理器进行任务调度和资源管理。
- **Apache Mesos**: 使用Apache Mesos作为资源调度和分配的集群管理器。
- **Hadoop YARN**: 在Hadoop生态系统中,可以将Spark作为MapReduce任务的替代方案,在YARN上进行资源管理和任务调度。
无论采用何种部署模式,Spark集群的架构设计通常包括以下几个关键组件:
- **驱动器(Driver)**: 负责整个应用程序的控制和协调,启动执行器进行任务的分配和执行,并接收来自执行器的计算结果。
- **集群管理器(Cluster Manager)**: 负责在集群上进行资源的分配和调度,以及监控和容错处理。根据不同的部署模式和需求,集群管理器可以是Spark自带的集群管理器、Apache Mesos或Hadoop YARN等。
- **执行器(Executor)**: 运行在工作节点上,负责执行具体的任务,包括数据读写、算法计算等操作。执行器与驱动器通过网络通信,交换任务和结果数据。
这些组件的协作和配合,使得Spark集群能够高效地处理大规模数据和复杂计算任务。
### 4. 大规模数据处理的挑战
在当前大数据时代,处理海量数据所带来的挑战日益显著。Spark集群作为一种强大的大数据处理解决方案,能够有效地解决以下挑战:
#### 4.1 数据规模与处理效率
随着数据量不断增长,传统的数据处理方式面临着处理效率低下的问题。传统的单机处理方案往往无法满足大规模数据处理的需求,而Spark集群通过分布式计算和内存计算技术,能够快速高效地处理PB级甚至EB级规模的数据。
```python
# 示例代码:使用Spark处理大规模数据
from pyspark import SparkContext
# 初始化SparkContext
sc = SparkContext("local", "large_scale_data_processing")
# 读取大规模数据
data = sc.textFile("hdfs://path/to/large_data.txt")
# 数据处理与计算
result = data.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 输出结果
result.collect()
```
通过上述示例代码,我们可以看到Spark集群快速处理大规模数据的能力。
#### 4.2 实时数据处理需求
随着业务场景的复杂化,实时数据处理需求变得日益重要。传统的批处理方式无法满足对实时性要求高的数据处理需求,而Spark集群通过结合流式计算技术,能够实现实时数据流的处理与分析,极大地提升了数据处理的实时性和准确性。
```java
// 示例代码:使用Spark Streaming进行实时数据处理
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));
JavaDStream<String> lines = jssc.socketTextStream("localhost", 9999);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(s -> new Tuple2<>(s, 1))
.reduceByKey((i1, i2) -> i1 + i2);
wordCounts.print();
jssc.start();
jssc.awaitTermination();
```
上述Java代码演示了如何使用Spark Streaming进行实时数据处理,实时统计数据流中的单词频率。
#### 4.3 处理复杂业务逻辑
随着业务场景的发展,需要处理的业务逻辑也变得越来越复杂。传统的数据处理工具往往无法应对复杂的业务逻辑,而Spark集群提供了丰富的API和函数库,能够支持复杂的数据处理和业务逻辑计算,从而满足各种复杂业务场景下的需求。
```scala
// 示例代码:使用Spark SQL处理复杂业务逻辑
val df = spark.read.json("examples/src/main/resources/people.json")
df.createOrReplaceTempView("people")
val result = spark.sql("SELECT * FROM people WHERE age > 20")
result.show()
```
上述Scala代码演示了使用Spark SQL进行复杂业务逻辑的数据处理,通过SQL语句筛选出年龄大于20的数据。
通过以上内容,我们可以清晰地认识到大规模数据处理所面临的挑战,以及Spark集群在解决这些挑战方面的优势和能力。
# 5. 为什么选择Spark集群
在大规模数据处理的领域,选择合适的工具和平台对于实现高效和可靠的数据处理非常重要。下面是选择Spark集群作为数据处理平台的几个主要原因:
## 5.1 快速数据处理和计算
Spark集群采用内存计算的方式,能够快速地处理和计算大规模的数据。相比传统的磁盘计算方式,内存计算具有更高的性能和吞吐量。Spark的RDD(弹性分布式数据集)可以将数据分布到集群中的多个节点上,并通过并行计算来加速数据处理。此外,Spark在底层使用了DAG(有向无环图)调度模型,可以优化计算过程,进一步提高计算效率。
## 5.2 支持多种数据源和格式
Spark集群支持多种数据源和格式的处理,包括文本文件、CSV文件、JSON文件、Parquet文件等。无论数据是存储在HDFS、S3、Hive还是其他存储系统中,Spark都可以通过相应的数据源接口来读取和处理数据。这种灵活性使得Spark集群可以适用于各种数据处理任务,并且可以与已有的数据存储和处理系统集成。
## 5.3 丰富的生态系统和工具支持
Spark集群拥有丰富的生态系统和工具支持,可以满足不同场景下的数据处理需求。除了提供基本的数据处理功能外,Spark还提供了许多扩展库和工具,例如:
- **Spark Streaming**:用于实时数据处理和流式计算;
- **Spark SQL**:用于处理结构化和半结构化数据,并支持SQL查询语言;
- **Spark MLlib**:用于机器学习和数据挖掘的库,提供了丰富的算法和工具;
- **Spark GraphX**:用于图计算和图分析的库,支持复杂的图算法。
此外,Spark还可以与其他工具和平台集成,如Hadoop、Hive、Kafka等。这种集成能力使得Spark集群更加灵活和强大,可以在复杂的数据处理流程中发挥重要作用。
综上所述,选择Spark集群作为数据处理平台具有快速数据处理和计算的能力,支持多种数据源和格式的处理,同时拥有丰富的生态系统和工具支持。这些特点使得Spark集群成为大规模数据处理的首选工具之一。
### 6. 成功案例分析
在这一章节中,我们将探讨一些典型的行业应用案例,以及Spark集群在这些案例中所带来的价值和成果。我们将深入分析这些案例,以便更好地理解Spark集群在实际业务中的应用和作用。
接下来,我们将详细介绍每个案例的背景、解决方案以及使用Spark集群后取得的成果。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入讨论spark集群的安装部署及实际应用,涵盖了从基础概念到高级技术的全面内容。文章包括spark集群的选择原因、硬件配置、操作系统准备、安装步骤、核心组件解析、任务调度与资源管理、高可用性配置、分布式存储系统应用、资源管理工具介绍、容器化部署、数据处理与分析方法、机器学习、图处理分析、边缘计算、性能优化技巧、故障处理及数据安全保护等方面的深入探讨。无论您是初学者还是有经验的技术专家,本专栏将为您呈现spark集群技术的全貌,并为您提供实用的部署指南和解决方案。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】使用Docker与Kubernetes进行容器化管理
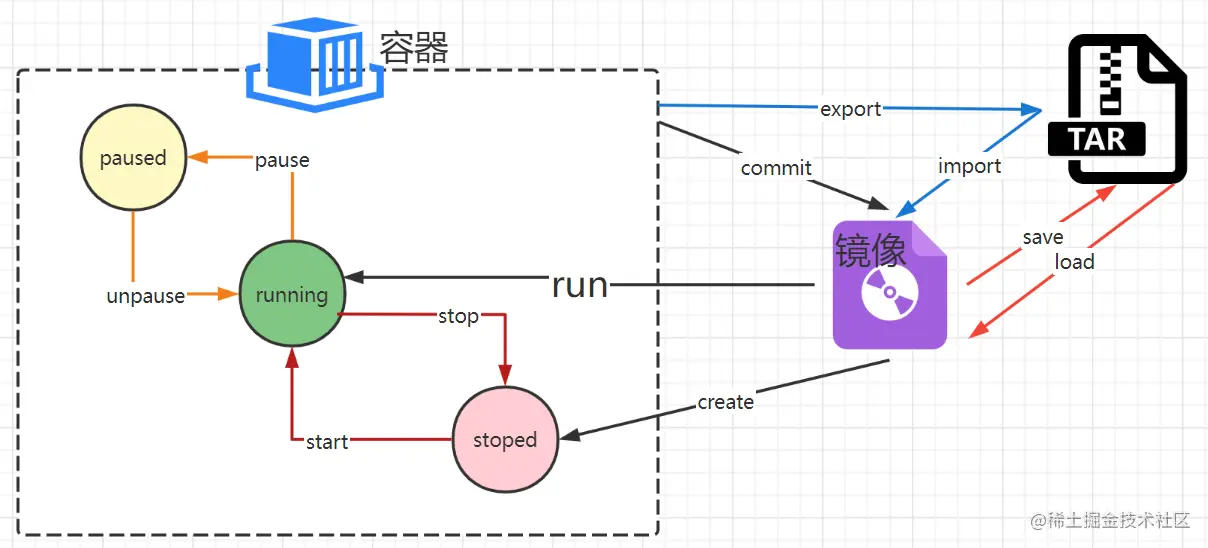
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】通过强化学习优化能源管理系统实战
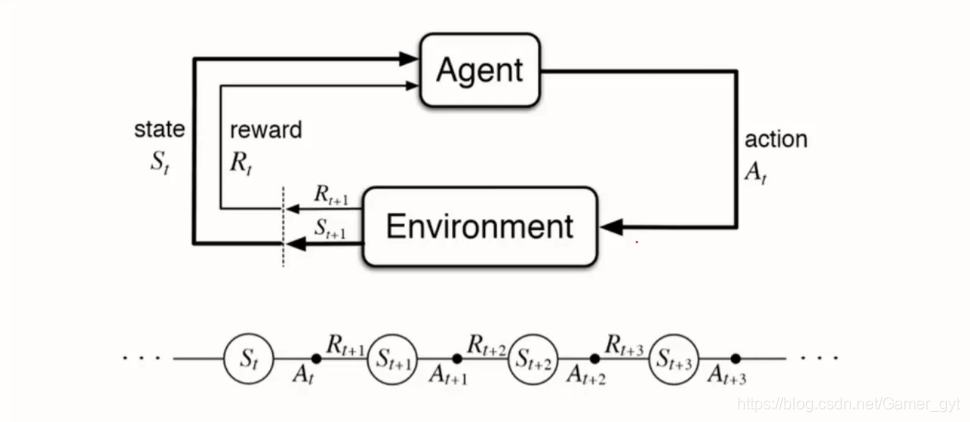
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】python云数据库部署:从选择到实施
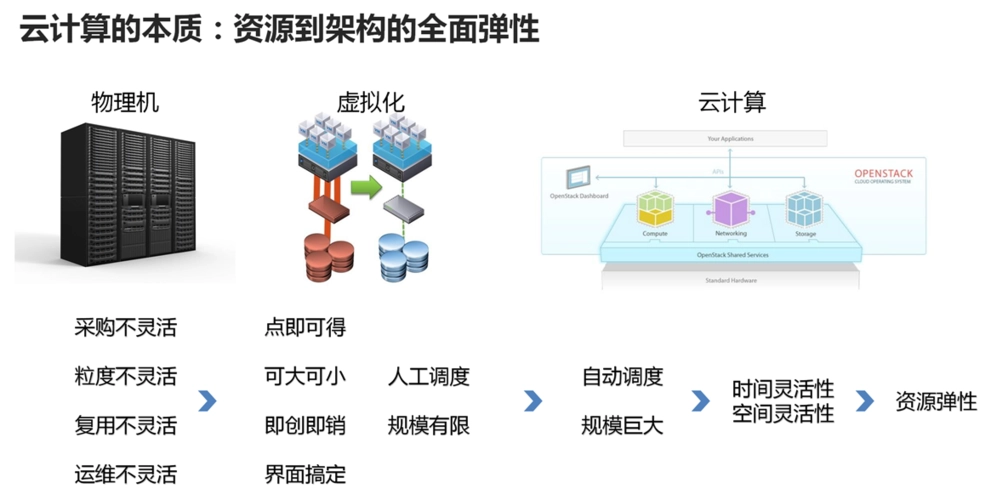
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】渗透测试的方法与流程

# 2.1 信息收集与侦察
信息收集是渗透测试的关键阶段,旨在全面了解目标系统及其环境。通过收集目标信息,渗透测试人员可以识别潜在的攻击向量并制定有效的攻击策略。
###
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )