Linux下的数据库管理与应用
发布时间: 2024-02-01 10:55:59 阅读量: 52 订阅数: 36 

linux下神通数据库安装包
# 1. 简介
## 1.1 什么是Linux下的数据库管理与应用
在Linux系统下进行数据库管理与应用,是指在Linux操作系统环境下使用数据库管理系统(如MySQL、PostgreSQL、MongoDB等)来创建、管理、存储和检索数据,并将数据库应用于开发和生产环境中。
## 1.2 Linux下的数据库管理的优势和适用场景
Linux作为一种开源、稳定、安全的操作系统,在进行数据库管理时具有以下优势:
- 强大的性能和稳定性,适合对大规模数据进行处理和管理
- 开源免费,无需额外的数据库管理系统的授权费用
- 丰富的工具和资源支持,便于开发者进行数据库管理与应用开发
Linux下的数据库管理适用于各种场景,包括Web应用、大数据处理、云计算平台等,特别是对于需要高性能和高可靠性的业务场景,Linux下的数据库管理是一个理想的选择。
# 2. 常用的Linux下数据库管理系统
### 2.1 MySQL
MySQL是最流行的开源关系型数据库管理系统之一,它被广泛应用于Web应用程序的开发和数据存储。MySQL具有简单易用、高性能和可靠稳定等特点,适用于小型到大型企业的各种应用场景。
#### MySQL的安装与配置
##### 1. 安装MySQL
```shell
sudo apt-get install mysql-server # 使用Ubuntu系统的apt-get命令安装MySQL
```
##### 2. 配置MySQL
安装完成后,需要进行一些基本配置,如设置root用户的密码等。运行以下命令来进行配置:
```shell
sudo mysql_secure_installation
```
##### 3. 连接MySQL
安装和配置完成后,可以使用以下命令连接到MySQL数据库:
```shell
mysql -u root -p
```
### 2.2 PostgreSQL
PostgreSQL是一种强大的开源对象关系型数据库管理系统,具有高度可靠性、一致性和可扩展性。PostgreSQL支持复杂的查询、事务和并发处理,并提供多种编程接口和工具。
#### PostgreSQL的安装与配置
##### 1. 安装PostgreSQL
```shell
sudo apt-get install postgresql # 使用Ubuntu系统的apt-get命令安装PostgreSQL
```
##### 2. 配置PostgreSQL
安装完成后,可以使用以下命令连接到PostgreSQL数据库:
```shell
sudo -u postgres psql
```
### 2.3 MongoDB
MongoDB是一个高性能、开源、无模式的文档数据库管理系统。它支持JSON风格的文档存储结构,具有灵活的数据模型和强大的查询能力,适用于大规模数据存储和实时分析等场景。
#### MongoDB的安装与配置
##### 1. 安装MongoDB
```shell
sudo apt-get install mongodb # 使用Ubuntu系统的apt-get命令安装MongoDB
```
##### 2. 配置MongoDB
安装完成后,可以使用以下命令连接到MongoDB数据库:
```shell
mongo
```
以上是常用的Linux下数据库管理系统的介绍以及安装与配置的步骤。通过上述安装和配置,可以在Linux系统中使用MySQL、PostgreSQL和MongoDB等数据库管理系统来满足不同的需求。接下来将介绍如何进行数据库的管理与维护。
# 3. 数据库的安装与配置
在Linux系统中,安装和配置数据库管理系统是非常重要的一步。不同的数据库管理系统有不同的安装和配置方法,接下来将分别介绍MySQL、PostgreSQL和MongoDB的安装与配置方法。
#### 3.1 安装与配置MySQL
MySQL是一个常用的开源关系型数据库管理系统,在Linux环境下有多种安装方式,包括使用包管理器、直接下载安装包等。以使用包管理器的方式为例,以下是在Ubuntu系统上安装MySQL的示例代码:
```bash
# 使用APT包管理器安装MySQL
sudo apt update
sudo apt install mysql-server
# 配置MySQL
sudo mysql_secure_installation
```
代码说明:
- `sudo apt update`:更新APT包管理器的软件列表。
- `sudo apt install mysql-server`:安装MySQL服务器。
- `sudo mysql_secure_installation`:运行安全配置脚本,设置MySQL root 用户的密码等安全选项。
#### 3.2 安装与配置PostgreSQL
PostgreSQL是一款强大的开源对象关系数据库管理系统,同样可以通过包管理器进行安装。以下是在CentOS系统上安装PostgreSQL的示例代码:
```bash
# 使用YUM包管理器安装PostgreSQL
sudo yum install postgresql-server
# 初始化数据库
sudo postgresql-setup initdb
# 启动并设置开机自启动
sudo systemctl start postgresql
sudo systemctl enable postgresql
```
代码说明:
- `sudo yum install postgresql-server`:安装PostgreSQL服务器。
- `sudo postgresql-setup initdb`:初始化数据库。
- `sudo systemctl start postgresql`:启动PostgreSQL服务。
- `sudo systemctl enable postgresql`:设置PostgreSQL开机自启动。
#### 3.3 安装与配置MongoDB
MongoDB是一个NoSQL数据库管理系统,安装也可以通过包管理器或者直接下载安装包的方式进行。以下是在Fedora系统上安装MongoDB的示例代码:
```bash
# 使用DNF包管理器安装MongoDB
sudo dnf install mongodb-server
# 启动并设置开机自启动
sudo systemctl start mongod
sudo systemctl enable mongod
```
代码说明:
- `sudo dnf install mongodb-server`:安装MongoDB服务器。
- `sudo systemctl start mongod`:启动MongoDB服务。
- `sudo systemctl enable mongod`:设置MongoDB开机自启动。
通过以上示例代码,可以安装和配置MySQL、PostgreSQL和MongoDB,使其在Linux系统中正常运行。
# 4. 数据库的管理与维护
在Linux环境下,数据库的管理与维护是非常重要的,包括创建和管理数据库和表,数据备份和恢复,数据库性能优化与监控,以及用户权限管理。下面将对这些内容进行详细说明。
#### 4.1 创建和管理数据库和表
数据库的创建和管理可以通过SQL命令或数据库管理工具来实现。以MySQL为例,使用SQL语句创建数据库和表的示例如下:
```sql
-- 创建数据库
CREATE DATABASE IF NOT EXISTS mydb;
USE mydb;
-- 创建表
CREATE TABLE IF NOT EXISTS users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL
);
```
上述代码中,首先创建了名为`mydb`的数据库,然后在该数据库中创建了名为`users`的表,表中包含`id`、`username`和`email`等字段。
#### 4.2 数据备份和恢复
数据库的备份和恢复是保障数据安全的重要手段,可以通过数据库自带的备份工具或者第三方工具来实现。以PostgreSQL为例,使用`pg_dump`和`pg_restore`命令进行备份和恢复:
```bash
# 备份数据库
pg_dump -U username -d dbname -h hostname -f backup.sql
# 恢复数据库
psql -U username -d dbname -h hostname -f backup.sql
```
#### 4.3 数据库性能优化与监控
为了提高数据库性能,需要进行性能优化和监控。可以通过调整数据库参数、使用索引、分析慢查询日志等方式来优化数据库性能,并借助工具如`top`、`htop`、`mytop`、`pt-query-digest`等来监控数据库性能。
#### 4.4 用户权限管理
在数据库管理中,用户权限管理是非常重要的一环,可以使用SQL语句为用户赋予不同的权限,以控制其对数据库的访问和操作。以MongoDB为例,使用`db.grantRolesToUser`命令为用户授权:
```javascript
// 授予用户读写权限
db.grantRolesToUser(
"myUser",
[
{ role: "readWrite", db: "mydb" }
]
)
```
以上就是数据库的管理与维护的基本内容,在实际应用中,需要根据具体情况进行灵活运用,以确保数据库的安全、稳定和高效运行。
# 5. Linux下数据库的应用开发
在Linux下,开发人员可以使用各种编程语言和工具连接和操作数据库。本章将介绍一些常用的连接数据库的编程语言与工具,数据库操作的基本语法与示例,数据库的事务管理以及数据库的索引与查询优化。
### 5.1 连接数据库的编程语言与工具
在Linux环境下,开发人员可以使用多种编程语言和工具来连接数据库,进行数据的增删改查操作。以下是一些常用的连接数据库的编程语言和工具:
- Python:Python是一种简单易学、功能强大的编程语言,有着丰富的数据库操作库,如pymysql、psycopg2等,可以方便地连接MySQL、PostgreSQL等数据库进行数据操作。
- Java:Java是一种广泛应用于企业级开发的编程语言,通过JDBC可以连接各种数据库,如使用JDBC连接MySQL、PostgreSQL等数据库进行数据操作。
- Go:Go语言是一种快速、简洁、安全的编程语言,通过官方提供的数据库驱动包,如go-sql-driver/mysql、lib/pq等,可以连接MySQL、PostgreSQL等数据库进行数据操作。
- JavaScript:JavaScript作为一种广泛应用于网页开发的编程语言,可以利用其提供的库,如Node.js中的mysql、pg等模块,连接MySQL、PostgreSQL等数据库进行数据操作。
### 5.2 数据库操作的基本语法与示例
无论是使用哪种编程语言,进行数据库操作都需要掌握一些基本的语法和API。下面以Python为例,展示数据库操作的基本语法与示例。
#### 5.2.1 连接数据库
```python
import pymysql
# 连接数据库
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='test')
# 获取游标
cursor = conn.cursor()
# 执行SQL语句
cursor.execute('SELECT * FROM users')
# 获取查询结果
results = cursor.fetchall()
# 关闭游标和连接
cursor.close()
conn.close()
```
#### 5.2.2 插入数据
```python
import pymysql
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='test')
cursor = conn.cursor()
# 插入单条记录
sql = "INSERT INTO users (name, age) VALUES (%s, %s)"
values = ('John', 28)
cursor.execute(sql, values)
# 插入多条记录
sql = "INSERT INTO users (name, age) VALUES (%s, %s)"
values = [('Alice', 25), ('Bob', 30), ('Cindy', 33)]
cursor.executemany(sql, values)
# 提交事务
conn.commit()
cursor.close()
conn.close()
```
#### 5.2.3 更新数据
```python
import pymysql
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='test')
cursor = conn.cursor()
# 更新单条记录
sql = "UPDATE users SET age = %s WHERE id = %s"
values = (30, 1)
cursor.execute(sql, values)
# 更新多条记录
sql = "UPDATE users SET age = %s WHERE name = %s"
values = [(28, 'Alice'), (32, 'Bob')]
cursor.executemany(sql, values)
# 提交事务
conn.commit()
cursor.close()
conn.close()
```
#### 5.2.4 删除数据
```python
import pymysql
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='test')
cursor = conn.cursor()
# 删除单条记录
sql = "DELETE FROM users WHERE id = %s"
values = (1,)
cursor.execute(sql, values)
# 删除多条记录
sql = "DELETE FROM users WHERE name = %s"
values = [('Alice',), ('Bob',)]
cursor.executemany(sql, values)
# 提交事务
conn.commit()
cursor.close()
conn.close()
```
### 5.3 数据库的事务管理
在数据库操作中,事务是一系列操作的逻辑单元,要么全部成功执行,要么全部失败回滚。事务可以确保数据的一致性和完整性。下面以Python为例,介绍数据库事务的基本操作。
```python
import pymysql
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='test')
cursor = conn.cursor()
# 开启事务
conn.begin()
try:
# 执行SQL语句1
sql1 = "UPDATE users SET age = age + 1 WHERE id = %s"
values1 = (1,)
cursor.execute(sql1, values1)
# 执行SQL语句2
sql2 = "INSERT INTO logs (user_id, operation) VALUES (%s, %s)"
values2 = (1, 'update age')
cursor.execute(sql2, values2)
# 提交事务
conn.commit()
print("事务执行成功")
except:
# 发生异常,回滚事务
conn.rollback()
print("事务执行失败")
cursor.close()
conn.close()
```
使用`conn.begin()`开启事务,然后在一系列SQL语句执行后,通过`conn.commit()`提交事务,如果事务执行过程中发生异常,则通过`conn.rollback()`回滚事务。
### 5.4 数据库的索引与查询优化
在数据库中,索引是一种特殊的数据结构,可以加快数据的查找速度。优化查询可以提高数据库的查询性能。下面以MySQL为例,介绍数据库的索引与查询优化的示例。
#### 5.4.1 创建索引
```python
import pymysql
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='test')
cursor = conn.cursor()
# 创建索引
sql = "CREATE INDEX idx_age ON users (age)"
cursor.execute(sql)
cursor.close()
conn.close()
```
#### 5.4.2 查询优化
```python
import pymysql
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', database='test')
cursor = conn.cursor()
# 优化查询
sql = "SELECT name, age FROM users WHERE age > %s"
values = (30,)
cursor.execute(sql, values)
results = cursor.fetchall()
cursor.close()
conn.close()
```
通过创建适当的索引,可以大大提高查询性能。在查询语句中,使用合适的条件和参数绑定,可以进一步优化查询。
这里只是简单介绍了一些常用的数据库操作和优化技巧,实际应用中还需要根据具体情况进行进一步调整和优化。
请注意,以上示例仅为演示用途,实际应用中需要做好安全性和错误处理。
# 6. 第六章 最佳实践与案例分享
### 6.1 Linux下数据库管理的最佳实践
在Linux下进行数据库管理时,我们可以遵循以下最佳实践来提高数据库的性能和稳定性:
1. 使用合适的硬件配置:选择性能优异、可靠性高的硬件设备,如快速的磁盘驱动器、大内存容量、多核处理器等。
2. 优化数据库的存储结构:根据实际需求,合理设计数据库的表结构,使用适当的数据类型和索引,避免冗余和重复数据。
3. 定期备份和恢复数据:建立合理的备份策略,并定期执行数据库备份操作,以保证数据的安全性和可用性。
4. 监控与优化数据库性能:使用性能监控工具对数据库进行持续监控,发现潜在问题并进行性能优化,如调整数据库参数、优化查询语句等。
5. 定期执行数据库维护任务:包括数据清理、索引优化、表碎片整理等,以保持数据库的良好状态。
6. 管理用户权限:根据需要分配合适的用户权限,限制对数据库的访问和操作,保护数据的安全性。
### 6.2 某公司在Linux下数据库应用的成功案例分享
某互联网公司在Linux环境下成功应用了数据库管理系统,并取得了显著的业务成果。以下是该公司的成功经验分享:
该公司使用的是MySQL数据库,并且在Linux服务器上搭建了一套高可用的数据库集群,以应对高并发访问和大规模数据存储的需求。
与常规的数据库架构相比,该公司采用了分布式的架构,使用了主从复制和读写分离技术,提高了数据库的性能和可扩展性。
此外,该公司还对数据库进行了合理的索引设计和查询优化,有效提升了系统的响应速度和吞吐量。
通过持续的性能监控和优化工作,该公司成功解决了数据库性能问题,并保持了系统的稳定性和可靠性。
总结起来,该公司通过合理的数据库设计、具体的运维策略和持续的性能优化,成功应用了Linux下的数据库管理系统,为业务的快速发展提供了坚实的数据支撑。
以上是某公司在Linux下数据库应用的成功案例分享,这一实例证明了Linux下数据库管理的重要性和价值,在实践中我们可以借鉴他们的经验,以优化我们自己的数据库管理工作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Linux系统开发基础与应用》专栏深入探讨了Linux系统开发的各个方面,涵盖了从基础概念到实际应用的广泛内容。通过系列文章,读者将了解Linux系统的基本介绍与基础命令使用,深入剖析Linux的文件系统与目录结构,探讨Linux文件权限与用户管理,学习Linux网络配置与管理的技巧,掌握Linux软件包管理与更新的方法。同时,专栏还关注Linux系统性能优化与调校,介绍在Linux下的编译与构建工具的使用,以及Linux内核与设备驱动开发的实践方法。此外,专栏还涵盖了Linux中的多线程编程与并发控制、网络编程与套接字通信,以及数据库管理与应用的技术要点。最后,读者还将深入了解Linux下的虚拟化与容器技术,为进一步探索Linux系统开发打下坚实基础。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Madagascar程序安装详解:手把手教你解决安装难题

# 摘要
Madagascar是一套用于地球物理数据处理与分析的软件程序。本文首先概述了Madagascar程序的基本概念、系统要求,然后详述了其安装步骤,包括从源代码、二进制包安装以及容器技术部署的方法。接下来,文章介绍了如何对Madagascar程序进行配置与优化,包括
【Abaqus动力学仿真入门】:掌握时间和空间离散化的关键点

# 摘要
本文综合概述了Abaqus软件在动力学仿真领域的应用,重点介绍了时间离散化和空间离散化的基本理论、选择标准和在仿真实践中的重要性。时间离散化的探讨涵盖了不同积分方案的选择及其适用性,以及误差来源与控制策略。空间离散化部分详细阐述了网格类型、密度、生成技术及其在动力学仿真中的应用。在动力学仿真实践操作中,文中给出了创建模型、设置分析步骤、数据提取和后处理的具体指导。最后,本文还探讨了非线
精确控制每一分电流:Xilinx FPGA电源管理深度剖析
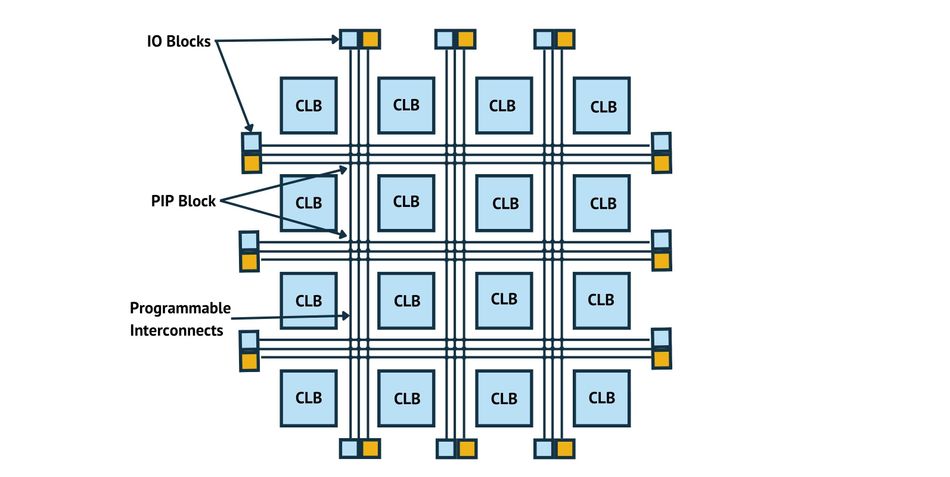
# 摘要
本文全面介绍并分析了FPGA电源管理的各个方面,从电源管理的系统架构和关键技术到实践应用和创新案例。重点探讨了Xilinx F
三维激光扫描技术在行业中的12个独特角色:从传统到前沿案例
# 摘要
三维激光扫描技术是一种高精度的非接触式测量技术,广泛应用于多个行业,包括建筑、制造和交通。本文首先概述了三维激光扫描技术的基本概念及其理论基础,详细探讨了其工作原理、关键参数以及分类方式。随后,文章通过分析各行业的应用案例,展示了该技术在实际操作中的实践技巧、面临的挑战以及创新应用。最后,探讨了三维激光扫描技术的前沿发展和行业发展趋势,强调了技术创新对行业发展的推动作用。本研究旨在为相关行业提供技术应用和发展的参考,促进三维激光扫描技术的进一步普及和深化应用。
# 关键字
三维激光扫描技术;非接触式测量;数据采集与处理;精度与分辨率;多源数据融合;行业应用案例
参考资源链接:[三维
【深入EA】:揭秘UML数据建模工具的高级使用技巧

# 摘要
UML数据建模是软件工程中用于可视化系统设计的关键技术之一。本文旨在为读者提供UML数据建模的基础概念、工具使用和高级特性分析,并探讨最佳实践以及未来发展的方向。文章从数据建模的基础出发,详细介绍了UML数据建模工具的理论框架和核心要素,并着重分析了模型驱动架构(MDA)以及数据建模自动化工具的应用。文章进一步提出了数据建模的优化与重构策略,讨论了模式与反模式,并通过案例研究展示了UML数据建模
CPCI标准2.0合规检查清单:企业达标必知的12项标准要求

# 摘要
CPCI标准2.0作为一项广泛认可的合规性框架,旨在为技术产品与服务提供清晰的合规性指南。本文全面概述了CPCI标准2.0的背景、发展、核心内容及其对企业和行业的价值。通过对标准要求的深入分析,包括技术、过程及管理方面的要求,本文提供了对合规性检查工具和方法的理解,并通过案例研究展示了标准的应用与不合规的后果。文章还探讨了实施前的准备工作、实施过程中的
【系统管理捷径】:Win7用户文件夹中Administrator.xxx文件夹的一键处理方案
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/z/U/B8daU9QrCGUjGluubd2Q/2013-02-19-ao-clicar-em-detalhes-reparem
RTD2555T应用案例分析:嵌入式系统中的10个成功运用

# 摘要
RTD2555T芯片作为嵌入式系统领域的重要组件,因其高效能和高度集成的特性,在多种应用场合显示出显著优势。本文首先介绍了RTD2555T芯片的硬件架构和软件支持,深入分析了其在嵌入式系统中的理论基础。随后,通过实际应用案例展示了RTD2555T芯片在工业控制、消费电子产品及汽车电子系统中的多样
按键扫描技术揭秘:C51单片机编程的终极指南

# 摘要
本文全面介绍了按键扫描技术的基础知识和应用实践,首先概述了C51单片机的基础知识,包括硬件结构、指令系统以及编程基础。随后,深入探讨了按键扫描技术的原理,包括按键的工作原理、基本扫描方法和高级技术。文章详细讨论了C51单片机按键扫描编程实践,以及如何实现去抖动和处理复杂按键功能。最后,针对按键扫描技术的优化与应用进行了探讨,包括效率优化策略、实际项目应用实例以及对未来趋势的预
【C语言数组与字符串】:K&R风格的处理技巧与高级应用
# 摘要
本论文深入探讨了C语言中数组与字符串的底层机制、高级应用和安全编程实践。文章首先回顾了数组与字符串的基础知识,并进一步分析了数组的内存布局和字符串的表示方法。接着,通过比较和分析C语言标准库中的关键函数,深入讲解了数组与字符串处理的高级技巧。此外,文章探讨了K&R编程风格及其在现代编程实践中的应用,并研究了在动态内存管理、正则表达式以及防御性编程中的具体案例。最后,通过对大型项目和自定义数据结构中数组与字符串应用的分析,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )