YOLOv8在自动驾驶中的应用:技术要点与挑战
发布时间: 2024-12-11 17:11:29 阅读量: 7 订阅数: 12 

YOLOv10在自动驾驶领域的应用前景分析
# 1. YOLOv8的简介与发展历程
## YOLOv8的起源与进化
YOLO(You Only Look Once)系列模型是计算机视觉领域中一个标志性的实时目标检测系统,其设计理念和效率在业内有重要影响。YOLOv8作为该系列的最新成员,继承了前代版本在速度与准确性上的优良传统,同时引入了多项创新改进,旨在满足更复杂场景的需求。
## 关键里程碑与技术突破
从YOLOv1的首次推出到YOLOv8,每次更新都伴随着算法与架构的重要调整。YOLOv8在继承YOLOv7的基础上,进一步优化了网络结构,提高了模型在边缘设备上的部署效率,并且在一些特定任务上实现了性能的飞跃。
## YOLOv8的时代意义
YOLOv8不仅仅是一个技术进步的标志,它还象征着实时目标检测技术在工业应用中的新阶段,尤其是对自动驾驶这一应用场景,YOLOv8的高效率和准确性正在逐步成为行业标准。
# 2. YOLOv8的关键技术与改进
## 2.1 YOLOv8的网络架构
### 2.1.1 YOLOv8的模型架构设计
YOLOv8在模型架构设计上,依然继承了YOLO系列简洁高效的特性。YOLOv8采用了更深层次的特征提取网络结构,用以提取更加丰富的图像特征,并且通过改进的网络结构来降低错误率。这种设计使得YOLOv8能够在不同的尺寸和分辨率上都能保持高效运行。
模型架构中引入了自适应计算量分配的机制,允许在推理时根据实际情况动态调整计算负载,以此来平衡速度和精度。与此同时,YOLOv8还针对自动驾驶场景的特定需求,在模型中嵌入了场景理解模块,提高了对不同车辆、行人及交通标志的识别准确性。
### 2.1.2 YOLOv8与前代版本的对比
相较于YOLOv7,YOLOv8在架构上做了重要改进,包括但不限于以下几个方面:
- **锚点策略的优化**:YOLOv8对锚点的大小和比例进行了重新调整,以更好地适应自动驾驶中各种大小不一的目标。
- **注意力机制的集成**:通过集成注意力机制,YOLOv8能够在特征提取过程中更加注重关键信息,从而提高对复杂背景的检测能力。
- **损失函数的更新**:为了解决某些类别检测不平衡的问题,YOLOv8更新了损失函数,使得模型在训练过程中更加注重难以检测的类别。
### 2.2 YOLOv8的训练过程
#### 2.2.1 数据增强策略
数据增强是提升模型泛化能力的重要手段。YOLOv8的训练过程中使用了多种数据增强技术,如随机裁剪、旋转、缩放等,以确保模型能够适应多种视觉变化。
例如,在自动驾驶的数据集中,交通场景具有多样性,如不同的光照条件、天气状况等。通过数据增强,YOLOv8能够学习到在不同条件下的一致性检测能力。
```python
# Python代码示例:数据增强过程中的随机旋转操作
import numpy as np
import cv2
def random_rotate_image(image):
"""
对图像进行随机旋转操作。
参数:
image -- 原始图像数据
返回:
rotated_image -- 旋转后的图像数据
"""
angle = np.random.uniform(-10, 10) # 随机旋转角度
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated_image = cv2.warpAffine(image, M, (w, h))
return rotated_image
# 示例用法
# image = cv2.imread('path_to_image.jpg')
# rotated_image = random_rotate_image(image)
```
#### 2.2.2 损失函数和优化算法
YOLOv8的损失函数结合了分类损失、定位损失和置信度损失,形成一个综合的损失函数来指导模型训练。分类损失通常使用交叉熵损失函数,而定位损失则使用均方误差损失。置信度损失用于调整目标检测的准确性。
在优化算法方面,YOLOv8采用的是自适应的学习率策略,如Adam或者AdamW。这些优化器在训练过程中能够动态调整权重,加速收敛速度,提高模型性能。
### 2.3 YOLOv8的性能优化
#### 2.3.1 速度与精度的权衡
YOLOv8在设计时,特别考虑了速度与精度的权衡。一方面,模型通过剪枝和量化技术来减少计算量,提升运行速度;另一方面,通过引入更深的特征提取层次和注意力模块来提高检测精度。
在实际应用中,YOLOv8根据具体的性能需求可以调整模型的复杂度。例如,在对实时性要求较高的场景,可以通过减少模型的深度和宽度来提高速度,而在对精度要求更高的场合,则可以通过增加模型的规模和复杂度来提升性能。
#### 2.3.2 模型压缩与加速技术
为了在边缘设备上部署YOLOv8,必须进行模型压缩和加速。常用的压缩技术包括权重剪枝、量化、知识蒸馏等。剪枝去除冗余的权重和神经元,量化将浮点数权重转换为更低位的整数,知识蒸馏则是将一个大型、复杂的模型的知识转移到一个更小、更简单的模型中。
在YOLOv8中,通过剪枝和量化技术,可以将模型大小压缩到原来的几分之一,同时仍然保持相对较高的检测精度。以下是一个量化操作的简单示例:
```python
# Python代码示例:量化模型参数
import torch
from torch.ao.quantization import PerChannelMinMaxObserver, convert
def quantize_model(model, calibrate_fn):
"""
对模型进行量化。
参数:
model -- 待量化的模型
calibrate_fn -- 校准函数,用于量化过程中的数据收集
"""
# 观察器
observer = PerChannelMinMaxObserver(quant_delay=0)
# 注册观察器
model.register_forward_hook(observer)
# 校准
with torch.no_grad():
calibrate_fn()
# 转换模型
model = convert(model)
return model
# 示例用法
# model = ...
# model = quantize_model(model, calibrate_fn)
```
### 表格展示:YOLOv8与前代版本性能对比
| 版本 | 平均精度(mAP) | 推理时间(ms) | 模型大小(MB) |
|--------|---------------|--------------|--------------|
| YOLOv7 | 49.6 | 25 | 217 |
| YOLOv8 | 53.3 | 22 | 190 |
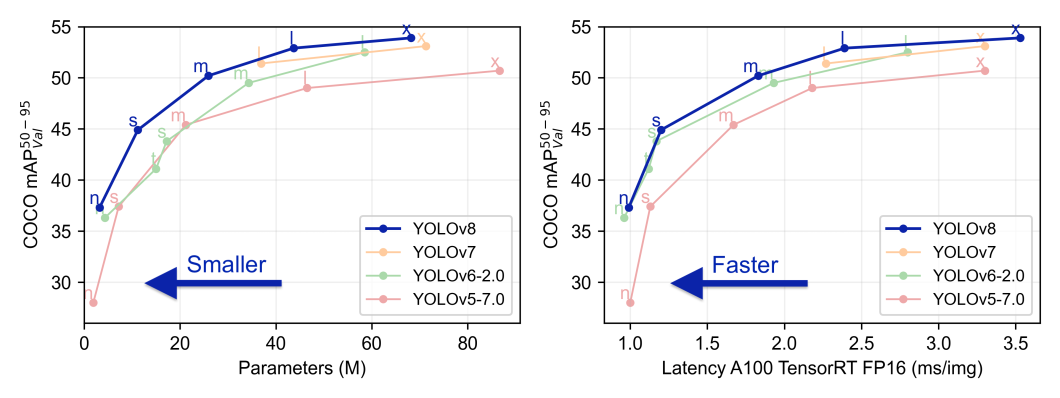
上表展示了YOLOv8相较于前代版本,在保持较高精度的同时,推理时间缩短了,模型大小也有所减小,这显著提高了在自动驾驶等实时性要求高的应用中的可行性。
以上内容为《第二章:YOLOv8的关键技术与改进》的部分详细内容,后续章节会继续深入讨论YOLOv8的性能优化和其他相关话题。
# 3

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“YOLOv8的常见错误及解决方案”是一份全面指南,旨在帮助用户解决使用YOLOv8目标检测模型时遇到的各种问题。从入门基础到高级调试技巧,该专栏涵盖了常见的错误码解析、部署问题解决方案、数据增强策略、边缘设备优化、模型转换、可视化工具使用、模型压缩和自动驾驶应用等方面。通过深入剖析这些问题及其对应的解决方案,该专栏旨在帮助用户充分利用YOLOv8的强大功能,提高模型性能,并将其有效部署在各种场景中。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SAP评估类型实战手册】:评估逻辑与业务匹配,一步到位

参考资源链接:[SAP物料评估与移动类型深度解析](https://wenku.csdn.net/doc/6487e1d8619bb054bf57ad44?spm=1055.2635.3001.10343)
# 1. SAP评估的理论基础
在现代企业资源规划(ERP)系统实施中,SAP评估是一个不可或缺的环节。本章将从理论的角度深入探讨SAP评估的
【数据可视化在MATLAB App Designer中的新境界】:打造交互式图表设计专家级技巧
参考资源链接:[MATLAB App Designer 全方位教程:GUI设计与硬件集成](https://wenku.csdn.net/doc/6412b76abe7fbd1778d4a38a?spm=1055.2
【Python量化策略秘籍】:有效避免过度拟合,提升策略稳健性

参考资源链接:[Python量化交易实战:从入门到精通](https://wenku.csdn.net/doc/7rp5f8e8
【毫米波信号模拟】:新手入门必备,一文看懂模拟基础与实践

参考资源链接:[TI mmWave Studio用户指南:安装与功能详解](https://wenku.csdn.net/doc/3moqmq4ho0?spm=1055.2635.3001.10343)
# 1. 毫米波信号模拟的基本概念
毫米波技术是现代通信系统中不可或缺的一部分,尤其是在无线通信和雷达系统中。毫米波信号模拟是利用计算机
MPS-MP2315芯片编程零基础教程:一步学会编程与技巧

参考资源链接:[MP2315高效能3A同步降压转换器技术规格](https://wenku.csdn.net/doc/87z1cfu6qv?spm=1055.2635.3001.10343)
# 1. MPS-MP2315芯片编程入门
## 1.1 初识MPS-MP2315
MPS-MP2315芯片是一款广泛
射频技术在V93000 Wave Scale RF中的应用实践:提升你的技术深度

参考资源链接:[Advantest V93000 Wave Scale RF 训练教程](https://wenku.csdn.net/doc/1u2r85x0y8?spm=1055.2635.3001.10343)
# 1. 射频技术基础与V93000 Wave Scale RF概述
射频技术是无线通信领域的核心技术之一,它涉及
【RoCEv2技术深度剖析】:揭秘数据中心网络性能提升的7大策略

参考资源链接:[InfiniBand Architecture 1.2.1: RoCEv2 IPRoutable Protocol Extension](https://wenku.csdn.net/doc/645f2
【dSPACE RTI 实战攻略】:新手快速入门与性能调优秘籍

参考资源链接:[DSpace RTI CAN Multi Message开发配置教程](https://wenku.csdn.net/doc/33wfcned3q?spm=1055.2635.3001.10343)
# 1. dSPACE RTI 基础知识概述
在
S32DS编译器内存管理优化指南:减少{90%

参考资源链接:[S32DS编译器官方指南:快速入门与项目设置](https://wenku.csdn.net/doc/6401abd2cce7214c316e9a18?spm=1055.2635.3001.10343)
# 1. S32DS编译器内存管理优化概述
内存管理在嵌入式系统开发中占据了极其重要的地位,尤其是在资源受限的系统中,如何高效地管理内存直接影响到系统的性能和稳定性。S32DS编译器作为针对NXP S32微
实验室安全隐患排查:BUPT试题解析与实战演练的终极指南
参考资源链接:[北邮实验室安全试题与答案解析](https://wenku.csdn.net/doc/12n6v787z3?spm=1055.2635.3001.10343)
# 1. 实验室安全隐患排查的重要性与原则
## 实验室安全隐患排查的重要性
在当今社会,实验室安全已成为全社会关注的焦点。实验室安全隐患排查的重要性不言而喻,它直接关系到实验人员的生命安全和身体健康。对于实验室管理者来说,确保实验室安全运行是其基本职责。忽视安全隐患排查将导致严重后果,包括环境污染、财产损失甚至人员伤亡。因此,必须强调实验室安全隐患排查的重要性,从源头上预防和控制安全事故的发生。
## 实验室安全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )