【Bash脚本错误调试技巧】:脚本问题的快速定位与修复方法
发布时间: 2024-09-27 09:29:21 阅读量: 103 订阅数: 37 

果壳处理器研究小组(Topic基于RISCV64果核处理器的卷积神经网络加速器研究)详细文档+全部资料+优秀项目+源码.zip
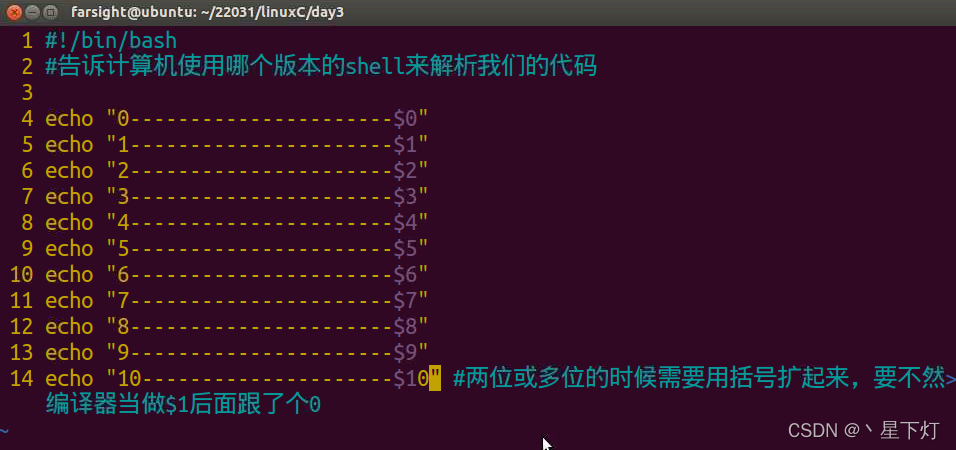
# 1. Bash脚本错误调试概述
## 1.1 调试的重要性
在任何编程领域,调试都是一项关键技能,尤其是对于Bash脚本而言。由于Bash脚本通常用于系统管理任务,一个小错误可能导致系统不稳定甚至损坏。因此,了解和掌握有效调试Bash脚本的方法,对于确保脚本正确运行至关重要。
## 1.2 调试过程的挑战
Bash脚本调试相比其他编程语言可能更具挑战性,部分原因是其运行环境的多样性和脚本本身的灵活性。脚本可能在不同的操作系统版本、不同的环境变量设置中运行,这些因素都可能影响脚本的行为。此外,Bash的某些特性,如管道、子进程、变量扩展等,使得错误追踪变得更加复杂。
## 1.3 调试方法概览
要有效地调试Bash脚本,需要掌握多种技巧。从基本的`echo`输出调试到使用`trap`命令处理信号,再到利用Bash调试模式或第三方工具如BASHDB。本章将概述这些方法,并在后续章节中详细介绍。
文章的开篇旨在为读者描绘Bash脚本调试的必要性和复杂性,同时也介绍了将要学习的主要调试手段,为深入探讨后续章节内容奠定基础。
# 2. 基础调试技术
### Bash脚本的常见错误类型
#### 语法错误
Bash脚本中的语法错误是最常见的错误类型之一,它们通常会在脚本执行时导致立即失败。语法错误可能包括拼写错误、缺少空格、错误的变量名或使用了未定义的变量。
```bash
#!/bin/bash
for file in $HOME/*
do
echo $file
done
```
上述脚本试图列出主目录中的所有文件,但未正确地引用变量,这将导致语法错误。
#### 运行时错误
运行时错误通常在脚本执行过程中发生,例如试图访问不存在的文件,或者当预期的条件不满足时,如除以零的错误。
```bash
#!/bin/bash
file="/some/nonexistent/path/file.txt"
if [ -e "$file" ]; then
cat "$file"
else
echo "File does not exist."
fi
```
在这个例子中,如果文件路径不存在,脚本将报错并停止执行。
#### 逻辑错误
逻辑错误是最难调试的错误类型,因为脚本可能按预期执行,但结果是不正确的。逻辑错误可能源于错误的逻辑判断或者条件处理。
```bash
#!/bin/bash
num=5
if [ $num -gt 10 ]; then
echo "Number is greater than 10."
else
echo "Number is less than or equal to 10."
fi
```
由于变量`num`的值是5,逻辑判断是错误的,但脚本不会报错,仅会给出错误的结果。
### 使用echo调试技巧
#### 输出变量和命令结果
`echo`是一个非常基础的调试工具,可以通过输出变量和命令结果来帮助我们理解脚本的执行流程。
```bash
#!/bin/bash
var="Hello World"
echo "Value of var is: $var"
```
#### 结合条件语句的输出控制
在复杂的脚本中,可以将`echo`语句放置在条件语句中以输出关键信息,仅在调试时启用。
```bash
#!/bin/bash
debug=true
if [ "$debug" = true ]; then
echo "Debug mode enabled"
fi
# The rest of the script goes here...
```
### 使用trap命令处理信号
#### 信号类型及其用途
信号是操作系统用来通知进程发生了某件事情的一种机制。例如,`SIGINT`信号通常由用户通过`Ctrl+C`组合键发送,用于终止正在运行的进程。
#### trap命令的基本用法
`trap`命令可以用来捕获并响应信号。
```bash
#!/bin/bash
# Setup trap for SIGINT
trap 'echo "Caught SIGINT, exiting..."' SIGINT
echo "Waiting for a SIGINT signal (try pressing Ctrl+C)..."
while true; do
sleep 2
done
```
#### 实际案例:优雅地捕捉和处理脚本信号
```bash
#!/bin/bash
# Setup trap for EXIT signal to ensure cleanup is done
cleanup() {
echo "Performing cleanup!"
# Add any necessary cleanup code here
}
trap cleanup EXIT
echo "Script is running..."
# ... script execution ...
```
以上脚本在脚本执行结束时或者接收到SIGINT时,会执行定义的清理函数,确保所有资源得到释放,避免可能的文件系统损坏或资源泄露。
# 3. 高级调试工具与技术
## 3.1 使用Bash的调试模式
### 3.1.1 启动Bash调试模式
Bash的调试模式提供了一个强大的环境用于逐步执行脚本并检查变量值。要启动Bash的调试模式,可以通过在脚本文件前加上`bash -x`来实现,或者在当前shell中通过`set -x`命令来激活调试信息的输出。
例如,有一个名为`script.sh`的脚本,可以通过以下方式启动调试模式:
```bash
bash -x script.sh
```
或者在脚本的开头加入:
```bash
#!/bin/bash
set -x
```
这将使得脚本执行时,每一步的执行细节都会被打印出来。
### 3.1.2 调试命令详解
在Bash调试模式下,存在一系列专用的调试命令,例如`n`(next)、`s`(step)、`c`(continue)、`q`(quit)等。
- `n`命令用于执行脚本的下一行。
- `s`命令会进入当前执行的函数或脚本内部。
- `c`命令会继续执行脚本直到遇到下一个断点。
- `q`命令会立即终止脚本的执行。
此外,调试模式允许设置断点,使用`b`(break)命令来指定在脚本的哪一行停止执行。
### 3.1.3 实战演练:逐行执行和变量检查
假设我们有以下简单的脚本`test.sh`:
```bash
#!/bin/bash
a=1
b=2
c=$((a + b))
echo $c
```
要使用调试模式逐行检查此脚本的执行,可以这样操作:
```bash
bash -x test.sh
```
或者在脚本中使用`set -x`。执行中,你会看到如下输出,显示每行命令的执行详情:
```bash
+ a=1
+ b=2
+ c=3
+ echo 3
```
### 代码逻辑分析
在上述脚本中,每条命令执行前都会输出一个加号(+),后面跟着将要执行的命令,这有助于跟踪每一步操作。Bash调试模式可以显示出当前所有变量的值,这对于理解变量在脚本执行过程中的变化非常有帮助。
## 3.2 利用脚本执行的返回状态
### 3.2.1 $?: 返回状态变量
每次命令执行完毕后,Bash都会保存它的退出状态码在一个特殊的变量`$?`中。退出状态码通常用于指示命令是否成功执行。成功执行返回0,非零值表示有错误发生。
例如,检查命令`false`的执行状态:
```bash
false
echo $? # 输出非零值
```
### 3.2.2 检测和利用返回状态进行调试
在脚本中,通常需要对一些操作进行检查,以确认操作是否成功。利用返回状态,我们可以编写更加健壮的脚本。
例如:
```bash
#!/bin/bash
grep "example" file.txt
if [ $? -eq 0 ]; then
echo "Found it!"
else
echo "Not found."
fi
```
在这个例子中,我们使用`grep`命令搜索字符串"example"在`file.txt`中是否存在。`grep`命令的返回状态被存储在`$?`中,并通过条件语句来判断是否输出"Found it!"或"Not found."。
## 3.3 使用第三方调试工具
### 3.3.1 BASHDB简介
BASHDB是一个开源的Bash脚本调试工具,它是GDB(GNU Debugger)的一个前端,专为Bash脚本设计。BASHDB提供了断点、步进、变量检查、回溯等调试功能,其界面和使用方式与GDB相似。
### 3.3.2 安装和配置BASHDB
BASHDB的安装通常可以通过包管理器来完成,例如在基于Debian的系统中:
```bash
apt-get install bashdb
```
安装后,可以通过以下命令启动BASHDB:
```bash
bashdb your_script.sh
```
### 3.3.3 使用BASHDB进行脚本调试
BASHDB提供了一个交互式界面,允许我们设置断点、单步执行和检查变量。
例如,使用BASHDB调试前面提到的`test.sh`脚本:
```bash
bashdb test.sh
```
在BASHDB提示符`>`下,可以使用`break`命令设置断点,使用`run`命令启动脚本执行。在脚本执行到断点时,BASHDB会暂停执行,并允许用户检查变量值或命令历史。
通过这种方式,开发者可以逐步跟踪脚本的执行过程,及时发现和修复潜在问题。
**注意:** 上述所有代码块中的命令和脚本应当在具备相应权限的环境中执行,并确保相关的测试文件和脚本已经准备就绪。
# 4. 实践案例与技巧分享
在前一章,我们已经了解了基础和高级的Bash脚本调试技术。现在,让我们深入实践中去,分享一些调试技巧、性能分析以及实战演练的过程。在此过程中,我们将具体分析如何解决复杂的脚本问题,以及如何在调试后对代码进行重构和优化。
## 4.1 脚本调试实践技巧
### 4.1.1 脚本的版本控制与回滚
脚本开发中,版本控制是至关重要的。通过版本控制,我们可以追踪代码的变更,进行协作开发,以及在必要时回滚到之前的版本。
#### 使用Git进行版本控制
Git是一个广泛使用的分布式版本控制系统。通过Git,我们可以创建版本库、提交更改、查看差异、切换分支、合并代码以及回滚到之前的状态。让我们通过一个简单的例子展示如何使用Git来管理Bash脚本的版本:
```bash
# 初始化Git仓库
git init
# 添加脚本文件到版本控制
git add my_script.sh
# 提交更改到仓库,附带消息
git commit -m "Initial script version"
# 修改脚本后,再次提交变更
# ...
# 如果需要回滚到之前的版本,可以使用以下命令
git log # 查看提交历史
git checkout <commit-hash> my_script.sh # 回滚到指定提交
```
#### 版本控制实践
在实践中,确保每次重要的更改都进行提交,为每次提交添加描述性的消息,并定期合并主分支到你的工作分支。在脚本出现重大错误时,你可以简单地切换回之前的版本,并重新尝试解决问题。
### 4.1.2 脚本错误日志的记录和分析
脚本错误日志是调试过程中的宝贵信息来源。记录错误日志不仅可以帮助开发者追踪脚本运行中的问题,还可以在将来出现类似问题时快速定位。
#### 记录日志
通常,我们可以使用重定向操作符或将输出追加到日志文件中。以下是示例代码:
```bash
# 将脚本输出重定向到日志文件
./my_script.sh > script_output.log 2>&1
# 使用 tee 命令同时显示在控制台和日志文件
./my_script.sh | tee script_output.log
# 使用 while 循环和 logger 命令记录日志
while read line; do
logger "Script is processing: $line"
# 脚本的其他操作
done < input_file.txt
```
#### 分析日志
分析错误日志时,查找特定的错误模式或异常状态码可以帮助你快速定位问题。在分析时,可以通过 `grep` 命令快速筛选出异常日志条目:
```bash
grep -i 'error' script_output.log
```
此外,如果脚本中记录了时间戳,那么可以使用 `awk` 或 `sed` 命令帮助分析日志中的特定时间段。
## 4.2 脚本性能分析
### 4.2.1 性能分析工具的使用
性能分析是确保脚本高效运行的关键环节。通过使用性能分析工具,可以发现脚本中的瓶颈所在,并进行相应的优化。
#### Bash内建的性能分析
Bash脚本自身提供了一些内建的命令,用于粗略地检查脚本性能。例如,可以使用 `time` 命令来测量脚本执行时间:
```bash
time ./my_script.sh
```
#### 使用专业的性能分析工具
除了 Bash 内建的性能分析之外,还有专门的工具如 `time` 或 `perf` 等,可以提供更详细的时间消耗报告。以 `time` 命令为例:
```bash
/usr/bin/time -v ./my_script.sh
```
#### 性能分析报告解读
执行上述命令后,通常会得到类似如下的输出,可以提供关于脚本运行时资源使用的信息:
```
User time (seconds): 0.00
System time (seconds): 0.01
Percent of CPU this job got: 3%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:01.05
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 2320
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 58
Voluntary context switches: 1
Involuntary context switches: 1
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
```
### 4.2.2 优化脚本性能的策略
在获取了脚本的性能报告后,可以采取一些优化策略来提高脚本的执行效率。
#### 优化文件操作
文件I/O通常是脚本性能瓶颈之一。对于文件操作,考虑以下优化策略:
- 使用临时文件来减少对大文件的操作。
- 尽可能顺序读写文件,避免随机访问。
- 使用高效的数据格式,如二进制或压缩格式,以减少数据大小。
#### 算法和数据结构优化
脚本中的算法选择对性能有很大影响。应当尽量使用时间复杂度低的算法,如使用哈希表来快速检索数据。数据结构的选择同样重要,如避免在循环中频繁添加元素到数组中。
#### 命令和工具的选用
不同命令和工具的性能差异很大。例如,在文本处理中,`awk` 和 `sed` 通常比 `bash` 内建命令执行得更快。在选择工具时,应当测试不同工具的性能。
## 4.3 实战演练:复杂脚本的调试流程
### 4.3.1 问题分析和定位
调试复杂脚本的第一步是问题分析和定位。这一过程包括理解脚本的预期行为、识别异常行为,以及找出与预期行为不符的代码部分。
#### 使用日志和错误报告
在调试过程中,首先检查脚本的错误日志和报告,以获得问题的初步印象。通过日志,通常可以找到脚本出错的大概位置和原因。
#### 逐步追踪
逐步追踪脚本的执行可以帮助你理解脚本的执行流程。可以使用 `set -x` 开启Bash的调试模式,或者使用调试工具如 `bashdb` 进行逐行跟踪。
### 4.3.2 调试步骤详解
在定位到问题的大致位置之后,需要通过逐步调试来精细化问题。
#### 使用调试命令
Bash提供了 `set -x`、`set +x`、`trap` 等调试命令,可以在脚本执行时打印出详细的调试信息。
```bash
set -x # 开启调试模式
# 脚本其他部分
set +x # 关闭调试模式
```
#### 使用调试工具
对于更高级的调试,可以使用 `bashdb` 这样的第三方调试工具。通过设置断点、单步执行和检查变量值,可以深入了解脚本的运行情况。
```bash
# 使用 bashdb 调试脚本
dbsh my_script.sh
```
### 4.3.3 调试后的代码重构和优化
调试完成后,代码的重构和优化是提升脚本质量和可靠性的关键步骤。
#### 重构代码
重构代码的目的是提高代码的可读性、可维护性以及性能。重构可能包括以下活动:
- 将大函数拆分成小函数。
- 为变量和函数添加更具描述性的名称。
- 移除重复的代码段。
#### 性能优化
在重构的同时,还应该考虑性能优化。优化可以从减少不必要的操作、优化算法和数据结构、减少I/O操作等方面入手。
```bash
# 示例:使用子shell优化文件处理
# 在此之前,使用 read 循环来处理文件内容
while IFS= read -r line; do
process "$line"
done < "$file"
# 使用 mapfile 优化读取
mapfile -t lines < "$file"
for line in "${lines[@]}"; do
process "$line"
done
```
#### 代码重构和优化的最佳实践
在重构和优化代码时,应当遵循以下最佳实践:
- 对于每次小的更改,都进行测试和验证。
- 使用自动化测试来确保重构不会引入新的错误。
- 在优化过程中,不断衡量性能改进,以确保你的优化工作是有效的。
- 保留原始代码的备份,以便在优化过程中出现问题可以回滚。
# 5. 避免错误的编程最佳实践
在处理Bash脚本时,预防总是比解决问题来得更加高效。本章节将探讨在编写脚本的过程中应遵循的最佳实践,以减少错误的发生,提高脚本的健壮性和可维护性。
## 5.1 编写可读性强的脚本
良好的脚本不仅应该执行所需的任务,还应该是其他人(以及未来的你)容易理解和维护的。以下是一些增加脚本可读性的建议:
### 5.1.1 脚本命名和组织结构
一个好的脚本命名应该简洁、明确且能够准确描述脚本的功能。例如:
```bash
# BAD
script.sh
# GOOD
backup_files.sh
```
组织结构上,我们应该将相关的命令、函数和逻辑分组,以模块化的方式组织脚本。可以使用注释来划分不同的模块,例如:
```bash
# 备份操作
# -------------------------------
# 创建备份目录
mkdir -p /path/to/backup
# ...后续备份命令...
# 清理旧的备份文件
find /path/to/backup -type f -mtime +7 -exec rm {} \;
```
### 5.1.2 注释的重要性
注释是任何良好脚本不可或缺的一部分,它们提供了关于脚本如何工作的额外信息,并帮助未来的维护者理解代码的目的。注释应尽量详细,但也要保持简洁:
```bash
# 备份当前工作目录到指定路径
# 参数1: 目标备份路径
backup_current_dir() {
local target_dir=$1
# ...备份逻辑...
}
```
## 5.2 使用函数封装复杂逻辑
函数是脚本编写中的重要组成部分,它们有助于保持代码的整洁,并使得重复使用的代码片段更加易于管理。
### 5.2.1 函数的优势和创建方法
使用函数可以将复杂的逻辑抽象成简洁的接口。函数应该拥有单一职责,并且返回清晰的结果:
```bash
# 创建备份函数
create_backup() {
local src_dir=$1
local dest_dir=$2
# ...备份逻辑...
}
```
### 5.2.2 函数的参数和返回值处理
函数参数能够为函数执行提供灵活性。返回值则通过全局变量`$?`来表示函数执行的最终状态:
```bash
# 函数调用示例
create_backup "/path/to/source" "/path/to/destination"
if [ $? -eq 0 ]; then
echo "备份成功"
else
echo "备份失败"
fi
```
## 5.3 错误处理与异常管理
错误处理是编写健壮脚本的关键环节。良好的错误处理机制能够提供清晰的错误信息,并且能够应对异常情况,防止脚本中断执行。
### 5.3.1 设计健壮的错误处理机制
脚本应能捕捉潜在的错误,并且提供有用的反馈。例如,可以通过检查命令的返回值来决定是否应该执行错误处理逻辑:
```bash
if ! command; then
echo "命令执行失败,错误代码为:$?"
# 可以添加更多的错误处理逻辑
exit 1
fi
```
### 5.3.2 异常情况的记录和报告
在异常情况下,脚本应该记录错误信息到日志文件,并且如果可能的话,向管理员报告异常情况:
```bash
{
# ...可能的错误逻辑...
} 2>>"$LOG_FILE"
```
在这里`$LOG_FILE`是脚本日志文件的路径。这种方法允许脚本在发生错误时记录信息,而不会导致程序终止。对于需要上报的情况,可以结合邮件或其他报警系统进行通知。
通过遵循这些最佳实践,你将能够编写出更加健壮、可读性强、易于维护的Bash脚本。这不仅能够提升你的工作效率,还能帮助团队协作更加顺畅。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏名为“bash command”,旨在提供全面的 Bash 脚本编程指南,从入门基础到精通技巧。专栏涵盖了广泛的主题,包括:
* 脚本编程从入门到精通
* 高效命令使用技巧
* 脚本错误调试技巧
* 参数传递与处理
* 函数定义与使用
* 数组和字符串操作
* 文件操作
* 进程管理
* 脚本调试技术
* 脚本测试与验证
* 脚本性能优化
* 跨环境部署
* 错误处理
* 配置文件管理
* 日志记录
通过深入浅出的讲解和丰富的示例,本专栏将帮助您掌握 Bash 脚本编程的各个方面,提升您的命令行效率,并创建健壮可靠的脚本。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达触摸屏宏编程:入门到精通的21天速成指南

# 摘要
本文系统地介绍了台达触摸屏宏编程的全面知识体系,从基础环境设置到高级应用实践,为触摸屏编程提供了详尽的指导。首先概述了宏编程的概念和触摸屏环境的搭建,然后深入探讨了宏编程语言的基础知识、宏指令和控制逻辑的实现。接下来,文章介绍了宏编程实践中的输入输出操作、数据处理以及与外部设备的交互技巧。进阶应用部分覆盖了高级功能开发、与PLC的通信以及故障诊断与调试。最后,通过项目案例实战,展现了如何将理论知识应用
信号完整性不再难:FET1.1设计实践揭秘如何在QFP48 MTT中实现

# 摘要
本文综合探讨了信号完整性在高速电路设计中的基础理论及应用。首先介绍信号完整性核心概念和关键影响因素,然后着重分析QFP48封装对信号完整性的作用及其在MTT技术中的应用。文中进一步探讨了FET1.1设计方法论及其在QFP48封装设计中的实践和优化策略。通过案例研究,本文展示了FET1.1在实际工程应用中的效果,并总结了相关设计经验。最后,文章展望了FET
【MATLAB M_map地图投影选择】:理论与实践的完美结合
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/3470884/1024px-Robinson_projection_SW.0.jpg)
# 摘要
M_map工具包是一种在MATLAB环境下使用的地图投影软件,提供了丰富的地图投影方法与定制选项,用
打造数据驱动决策:Proton-WMS报表自定义与分析教程
# 摘要
本文旨在全面介绍Proton-WMS报表系统的设计、自定义、实践操作、深入应用以及优化与系统集成。首先概述了报表系统的基本概念和架构,随后详细探讨了报表自定义的理论基础与实际操作,包括报表的设计理论、结构解析、参数与过滤器的配置。第三章深入到报表的实践操作,包括创建过程中的模板选择、字段格式设置、样式与交互设计,以及数据钻取与切片分析的技术。第四章讨论了报表分析的高级方法,如何进行大数据分析,以及报表的自动化
【DELPHI图像旋转技术深度解析】:从理论到实践的12个关键点

# 摘要
图像旋转是数字图像处理领域的一项关键技术,它在图像分析和编辑中扮演着重要角色。本文详细介绍了图像旋转技术的基本概念、数学原理、算法实现,以及在特定软件环境(如DELPHI)中的应用。通过对二维图像变换、旋转角度和中心以及插值方法的分析
RM69330 vs 竞争对手:深度对比分析与最佳应用场景揭秘

# 摘要
本文全面比较了RM69330与市场上其它竞争产品,深入分析了RM69330的技术规格和功能特性。通过核心性能参数对比、功能特性分析以及兼容性和生态系统支持的探讨,本文揭示了RM69330在多个行业中的应用潜力,包括消费电子、工业自动化和医疗健康设备。行业案例与应用场景分析部分着重探讨了RM69330在实际使用中的表现和效益。文章还对RM69330的市场表现进行了评估,并提供了应
无线信号信噪比(SNR)测试:揭示信号质量的秘密武器!
# 摘要
无线信号信噪比(SNR)是衡量无线通信系统性能的关键参数,直接影响信号质量和系统容量。本文系统地介绍了SNR的基础理论、测量技术和测试实践,探讨了SNR与无线通信系统性能的关联,特别是在天线设计和5G技术中的应用。通过分析实际测试案例,本文阐述了信噪比测试在无线网络优化中的重要作用,并对信噪比测试未来的技术发展趋势和挑战进行
【UML图表深度应用】:Rose工具拓展与现代UML工具的兼容性探索
# 摘要
本文系统地介绍了统一建模语言(UML)图表的理论基础及其在软件工程中的重要性,并对经典的Rose工具与现代UML工具进行了深入探讨和比较。文章首先回顾了UML图表的理论基础,强调了其在软件设计中的核心作用。接着,重点分析了Rose工具的安装、配置、操作以及在UML图表设计中的应用。随后,本文转向现代UML工具,阐释其在设计和配置方面的
台达PLC与HMI整合之道:WPLSoft界面设计与数据交互秘笈
# 摘要
本文旨在提供台达PLC与HMI交互的深入指南,涵盖了从基础界面设计到高级功能实现的全面内容。首先介绍了WPLSoft界面设计的基础知识,包括界面元素的创建与布局以及动态数据的绑定和显示。随后深入探讨了WPLSoft的高级界面功能,如人机交互元素的应用、数据库与HMI的数据交互以及脚本与事件驱动编程。第四章重点介绍了PLC与HMI之间的数据交互进阶知识,包括PLC程序设计基础、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )