应用性能提升术:Spring异步处理机制与实践
发布时间: 2024-09-26 23:36:59 阅读量: 59 订阅数: 44 

# 1. Spring异步处理机制概述
在当今的应用程序开发中,用户对响应速度的要求越来越高。传统的同步处理方式在某些场景下会导致用户体验不佳,例如在数据处理、文件上传等耗时操作时。为了提高用户体验,应用需要能够异步处理这些任务,同时不阻塞主线程。Spring框架作为Java开发者最喜爱的工具之一,很早就意识到了这一需求,并在不同版本中不断增强和优化了其异步处理的能力。
Spring异步处理机制允许开发者将长时间运行的任务委托给后台线程,从而不会延迟Web层的响应。使用@Async注解,开发者可以轻松地标记一个方法为异步,而无需关心底层的线程管理。这种机制可以大幅提高应用程序的性能和吞吐量,并且让代码的结构更加清晰。
随着技术的不断进步,异步处理的应用场景也在不断扩展,不仅限于Web应用,还包括微服务架构中的服务通信,甚至在云原生应用中也扮演着重要角色。接下来的章节中,我们将深入探讨Spring异步处理的原理、配置、优化,以及如何在实际项目中运用这一强大的特性。
# 2. 深入理解Spring异步处理原理
## 2.1 异步处理的理论基础
### 2.1.1 同步与异步的对比
在软件开发中,同步与异步是处理任务执行顺序的两种基本机制。同步执行意味着程序的执行流按照代码的编写顺序,一步一步地执行,当前一个任务没有完成之前,后续的任务无法开始执行。同步执行的优点是逻辑简单,易于理解和维护,但在处理耗时操作时会造成程序响应时间的延长,用户体验变差。
相对而言,异步处理则允许在当前任务尚未完成时,程序继续执行后续代码,而不是等待当前任务完成。这种处理方式可以大幅提高程序的响应性和吞吐量,尤其适用于网络请求、文件操作等耗时任务。
### 2.1.2 异步处理在Web应用中的作用
Web应用的用户界面需要提供快速响应来提升用户体验。通过异步处理,服务器可以在不阻塞主线程的情况下处理耗时的任务,比如数据持久化、消息发送等操作。这样,当用户提交一个耗时的请求后,用户界面可以立即返回一个响应,告知用户任务已经接收并开始处理,而不是等到任务完全处理完成。
此外,异步处理还可以提高服务器的利用率,允许服务器同时处理更多的请求。它是一种将计算资源分配到多个任务的有效方法,能够提升应用的可伸缩性,并减少系统资源的浪费。
## 2.2 Spring异步处理架构解析
### 2.2.1 Spring框架中的异步支持组件
Spring框架提供了一系列支持异步处理的组件,其中主要包含两个核心组件:`@Async` 注解和 `AsyncTaskExecutor` 接口。`@Async` 注解用于标注方法,使得该方法在调用时会异步执行。`AsyncTaskExecutor` 则是用于执行异步任务的执行器,Spring提供了多种实现,如 `SimpleAsyncTaskExecutor`、`ConcurrentTaskExecutor` 等,它们各自有不同的特性和使用场景。
### 2.2.2 异步任务执行流程与原理
当一个方法被 `@Async` 注解标注后,Spring会在调用这个方法时,委托给配置的 `AsyncTaskExecutor` 来执行。默认情况下,Spring使用 `SimpleAsyncTaskExecutor`,它会为每个异步任务创建一个新的线程来执行。
为了深入理解执行流程,我们可以参考以下步骤:
1. 配置异步任务执行器,可以使用XML配置或者Java配置类。
2. 在需要异步执行的方法上标注 `@Async` 注解。
3. 调用被 `@Async` 标注的方法时,Spring会通过代理机制拦截调用,并将任务提交给异步执行器执行。
## 2.3 异步处理的配置与优化
### 2.3.1 配置异步任务执行器
配置异步任务执行器通常有两种方式:XML配置和Java配置。
XML配置示例:
```xml
<task:annotation-driven executor="myExecutor"/>
<task:executor id="myExecutor" pool-size="50"/>
```
Java配置示例:
```java
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {
@Bean
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(50);
executor.setMaxPoolSize(100);
executor.setQueueCapacity(2000);
executor.initialize();
return executor;
}
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return new CustomAsyncExceptionHandler();
}
}
```
配置异步任务执行器时,需要考虑线程池的大小、队列容量等因素,这些参数会影响到异步任务的处理能力和系统的整体性能。
### 2.3.2 异步处理的性能调优策略
性能调优策略涉及多方面,包括但不限于线程池的参数设置、任务执行器的选择、任务执行策略的调整等。
线程池参数包括核心线程数、最大线程数、空闲线程的存活时间、任务队列的类型和容量等。合理的配置能够保证线程的最大利用率,同时避免资源浪费和性能瓶颈。
任务执行策略的调整也需要根据实际的业务场景,考虑任务的类型和执行频率。例如,对于IO密集型任务,可以适当增加线程数量,而对于CPU密集型任务,则应当控制线程数量,避免线程间的频繁切换。
为了更深入地了解和掌握这些配置和策略,建议在生产环境中进行详尽的测试,观察线程的行为和性能指标,以此作为调优的依据。
# 3. Spring异步处理实战指南
## 3.1 创建异步任务
### 3.1.1 使用@Async注解标注异步方法
在Spring框架中,创建异步任务的最简单方式是使用`@Async`注解。该注解可以放在Spring管理的bean的方法上,以此来声明该方法为异步执行。为了启用`@Async`的支持,需要在Spring配置中启用异步执行,通常是通过`@EnableAsync`注解实现。
```java
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.EnableAsync;
***ponent;
@EnableAsync
@Component
public class AsyncService {
@Async
public void executeAsyncTask() {
System.out.println("Execute method asynchronously - " + Thread.currentThread().getName());
}
}
```
上面的代码定义了一个`AsyncService`类,使用`@EnableAsync`开启异步方法的支持,然后通过`@Async`注解标注了`executeAsyncTask`方法,表明该方法在被调用时将在另一个线程中异步执行。需要注意的是,`@Async`注解不会自动阻塞当前线程,如果需要等待异步任务执行完毕,需要使用其他机制来实现。
### 3.1.2 返回值和异常处理机制
在异步方法中,返回值的处理方式和同步方法有所不同。由于异步执行的结果可能在方法执行完毕时无法立即获得,因此Spring提供了`Future`或`CompletableFuture`的返回值支持。这样可以异步获取方法执行的结果。
```java
import org.springframework.scheduling.annotation.Async;
***ponent;
***pletableFuture;
@Component
public class AsyncService {
@Async
public CompletableFuture<String> asyncTaskWithResult() {
System.out.println("Execute method asynchronously - " + Thread.currentThread().getName());
try {
Thread.sleep(2000); // Simulate processing time
} catch (InterruptedException e) {
throw new IllegalStateException(e);
}
***pletedFuture("Task completed");
}
}
```
异常处理机制方面,如果异步任务执行过程中出现异常,这些异常会被传递回调用者。Spring内部会封装在一个`CompletionException`中,通过调用`Future.get()`方法可以获取到这个异常,进行相应处理。
## 3.2 异步

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Java Spring 内置工具专栏,这里汇集了提升开发效率和应用性能的实用指南。专栏涵盖了各种主题,包括:
* 提升性能和安全的最佳实践
* 监控和管理应用的解决方案
* 面向切面编程指南
* 消息驱动编程技术
* 事务管理策略
* 事件驱动模型设计
* 批量处理技术
* 企业级集成技巧
* Bean 生命周期管理
* SpEL 语言应用
* 缓存机制详解
* 异步处理机制
通过深入探讨这些工具和技术,开发者可以掌握 Spring 框架的强大功能,构建高效、可扩展和可靠的 Java 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
全球高可用部署:MySQL PXC集群的多数据中心策略

# 1. 高可用部署与MySQL PXC集群基础
在IT行业,特别是在数据库管理系统领域,高可用部署是确保业务连续性和数据一致性的关键。通过本章,我们将了解高可用部署的基础以及如何利用MySQL Percona XtraDB Cluster (PXC) 集群来实现这一目标。
## MySQL PXC集群的简介
MySQL PXC集群是一个可扩展的同步多主节点集群解决方案,它能够提供连续可用性和数据一致
【电子密码锁用户交互设计】:提升用户体验的关键要素与设计思路

# 1. 电子密码锁概述与用户交互的重要性
## 1.1 电子密码锁简介
电子密码锁作为现代智能家居的入口,正逐步替代传统的物理钥匙,它通过数字代码输入来实现门锁的开闭。随着技术的发展,电子密码锁正变得更加智能与安全,集成指纹、蓝牙、Wi-Fi等多种开锁方式。
## 1.2 用户交互
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
直播推流成本控制指南:PLDroidMediaStreaming资源管理与优化方案
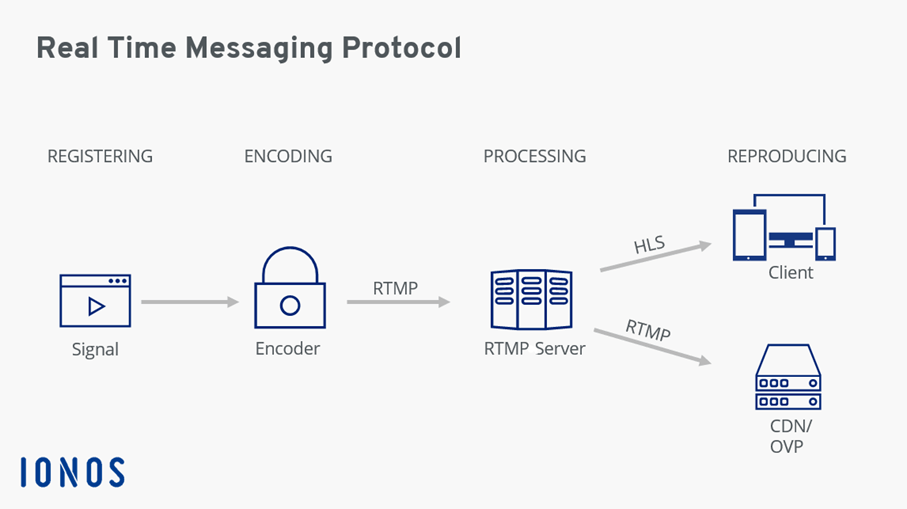
# 1. 直播推流成本控制概述
## 1.1 成本控制的重要性
直播业务尽管在近年来获得了爆发式的增长,但随之而来的成本压力也不容忽视。对于直播平台来说,优化成本控制不仅能够提升财务表现,还能增强市场竞争力。成本控制是确保直播服务长期稳定运
Python字典推导式与集合推导式

# 1. Python推导式概述
Python 推导式是一种从其他迭代器构建容器类型(如列表、字典和集合)的简洁方式。它提供了一种快速、高效的构建数据结构的方法,同时保持代码的可读性和简洁性。
在本章中,我们将了解 Python 推导式的基本概念,包括列表推导式、字典推导式和集合推导式。我们将探讨推导式的基本结构,其核心优势以及如何在日常编程实践中应用它。
为了更好地掌握推导式的精髓,我们首先需要理解其语
【MATLAB雷达信号处理】:理论与实践结合的实战教程
# 1. MATLAB雷达信号处理概述
在当今的军事与民用领域中,雷达系统发挥着至关重要的作用。无论是空中交通控制、天气监测还是军事侦察,雷达信号处理技术的应用无处不在。MATLAB作为一种强大的数学软件,以其卓越的数值计算能力、简洁的编程语言和丰富的工具箱,在雷达信号处理领域占据着举足轻重的地位。
在本章中,我们将初步介绍MATLAB在雷达信号处理中的应用,并
Android二维码实战:代码复用与模块化设计的高效方法

# 1. Android二维码技术概述
在本章,我们将对Android平台上二维码技术进行初步探讨,概述其在移动应用开发中的重要性和应用背景。二维码技术作为信息交换和移动互联网连接的桥梁,已经在各种业务场景中得到广泛应用。
## 1.1 二维码技术的定义和作用
二维码(QR Code)是一种能够存储信息的二维条码,它能够以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )