R语言基础与统计分析入门
发布时间: 2023-12-20 18:49:41 阅读量: 14 订阅数: 12 
# 第一章:R语言基础
## 1.1 R语言简介
R语言是一种专门用于统计分析和数据可视化的编程语言,由纽西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发。它具有强大的数据处理能力和丰富的数据分析函数库,是数据科学领域最流行的语言之一。R语言与Python一起成为数据科学领域的两大主流编程语言之一。
## 1.2 R语言安装与环境搭建
### 安装R语言
您可以在[R官方网站](https://www.r-project.org/)下载适合您操作系统的R语言安装包,并按照提示完成安装。
### 安装RStudio
RStudio是一个集成开发环境(IDE),提供了一套便于使用、专业的工具,用于R语言的编写、调试、数据可视化和交互式数据分析。您可以在[RStudio官方网站](https://www.rstudio.com/)下载适合您操作系统的RStudio安装包。
## 1.3 R语言基本语法与数据结构
### 基本语法
R语言的基本语法与大多数编程语言类似,包括变量赋值、函数调用、条件语句和循环语句等。
```R
# 变量赋值
x <- 10
y <- "Hello, World!"
# 函数调用
print(x)
print(y)
# 条件语句
if (x > 5) {
print("x大于5")
}
# 循环语句
for (i in 1:5) {
print(i)
}
```
### 数据结构
R语言中常用的数据结构包括向量(vector)、矩阵(matrix)、数据框(data frame)和列表(list)等。
```R
# 向量
vec <- c(1, 2, 3, 4, 5)
# 矩阵
mat <- matrix(1:6, nrow=2, ncol=3)
# 数据框
df <- data.frame(name=c("Tom", "Jerry"), age=c(25, 30))
# 列表
lst <- list(a=1, b="Hello", c=TRUE)
```
## 1.4 变量和函数
### 变量
在R语言中,变量使用`<-`或`=`进行赋值,无需提前声明变量类型。
```R
x <- 10
y <- "Hello, World!"
```
### 函数
R语言中的函数使用`function`关键字定义,可以包含参数和返回值。
```R
# 定义函数
my_function <- function(a, b) {
result <- a + b
return(result)
}
# 调用函数
print(my_function(3, 5))
```
## 1.5 控制流程与循环
### 控制流程
R语言支持`if-else`条件语句和`switch`语句来控制程序流程。
```R
# if-else条件语句
if (x > 5) {
print("x大于5")
} else {
print("x小于等于5")
}
# switch语句
score <- 85
grade <- switch(
floor(score/10),
"优秀",
"良好",
"及格"
)
print(grade)
```
### 循环
R语言支持`for`、`while`和`repeat`循环来进行迭代操作。
```R
# for循环
for (i in 1:5) {
print(i)
}
# while循环
j <- 1
while (j <= 5) {
print(j)
j <- j + 1
}
```
## 1.6 R语言常用包介绍
R语言拥有丰富的包资源,使得数据处理和分析更加高效。常用的包包括`dplyr`、`ggplot2`、`tidyr`等,它们提供了丰富的函数和工具来支持数据处理和可视化。
- `dplyr`:用于数据处理和变换的包
- `ggplot2`:用于数据可视化的包
- `tidyr`:用于数据整理的包
## 第二章:数据输入与输出
数据输入与输出是数据分析的基础,本章将介绍R语言中数据的导入、导出,以及数据类型转换、数据框和列表的操作,数据清洗与处理,以及数据可视化基础。让我们一起来深入了解吧!
### 第三章:统计分析基础
#### 3.1 描述统计学概念
描述统计学是统计学的一个重要分支,用于定量描述和总结数据的基本特征。常见的描述统计学方法包括均值、中位数、众数、标准差、方差、四分位数等,通过这些指标可以对数据集的整体情况进行描述。
```python
# Python示例代码
import numpy as np
data = np.array([3, 5, 7, 2, 8, 10, 6, 4, 7, 9])
# 计算均值
mean = np.mean(data)
print("均值:", mean)
# 计算中位数
median = np.median(data)
print("中位数:", median)
# 计算众数
mode = np.argmax(np.bincount(data))
print("众数:", mode)
# 计算标准差
std_dev = np.std(data)
print("标准差:", std_dev)
# 计算方差
variance = np.var(data)
print("方差:", variance)
# 计算四分位数
q1 = np.percentile(data, 25)
q3 = np.percentile(data, 75)
print("第一四分位数:", q1)
print("第三四分位数:", q3)
```
以上代码演示了如何使用Python进行描述统计学的常见计算,包括均值、中位数、众数、标准差、方差、四分位数的计算及输出结果。
#### 3.2 中心趋势与离散程度
中心趋势主要用来表示数据的集中程度,常见的指标包括均值、中位数和众数;离散程度用来衡量数据的波动程度,常见的指标包括极差、标准差和变异系数。
```java
// Java示例代码
import org.apache.commons.math3.stat.descriptive.DescriptiveStatistics;
double[] data = {3, 5, 7, 2, 8, 10, 6, 4, 7, 9};
DescriptiveStatistics stats = new DescriptiveStatistics(data);
// 计算均值
double mean = stats.getMean();
System.out.println("均值: " + mean);
// 计算中位数
double median = stats.getPercentile(50);
System.out.println("中位数: " + median);
// 计算标准差
double stdDev = stats.getStandardDeviation();
System.out.println("标准差: " + stdDev);
// 计算极差
double range = stats.getMax() - stats.getMin();
System.out.println("极差: " + range);
```
以上Java代码展示了如何使用常用的DescriptiveStatistics类计算数据的均值、中位数、标准差和极差,以及输出相应的结果。
#### 3.3 分布形态与相关性分析
分布形态描述了数据分布的形状特征,主要包括正态分布、偏态分布和峰态分布;相关性分析用来衡量两个变量之间的相关程度,常见的指标包括皮尔逊相关系数和斯皮尔曼相关系数。
```go
// Go示例代码
package main
import (
"fmt"
"github.com/gonum/stat"
)
func main() {
dataX := []float64{3, 5, 7, 2, 8, 10, 6, 4, 7, 9}
dataY := []float64{4, 6, 8, 3, 9, 11, 7, 5, 8, 10}
// 计算皮尔逊相关系数
pearsonCorr := stat.Correlation(dataX, dataY, nil)
fmt.Println("皮尔逊相关系数:", pearsonCorr)
// 计算斯皮尔曼相关系数
spearmanCorr := stat.Spearman(dataX, dataY, nil)
fmt.Println("斯皮尔曼相关系数:", spearmanCorr)
}
```
以上Go语言代码展示了如何使用gonum包计算数据的皮尔逊相关系数和斯皮尔曼相关系数,并输出相应的
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 15个月+AI工具集
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《数据分析入门到精通》专栏涵盖了数据分析领域的广泛内容,旨在帮助读者从数据分析的基础概念逐步深入,直至精通各种工具和技术。专栏涉及了从Excel数据分析技巧到Python数据分析库Pandas的基础教程,从数据可视化入门到SQL在数据分析中的基本应用,再到数据清洗与预处理技术的详细解析。此外,专栏还包括了探索性数据分析(EDA)、机器学习、数据挖掘、时间序列分析以及文本分析等内容。同时也介绍了数据仓库与ETL流程、大数据分析与Hadoop生态系统、网络分析基础以及高级数据可视化工具Tableau的应用。此外,专栏还介绍了Python中的数据处理技术、情感分析与情感识别技术、数据科学中的统计学方法论,以及深度学习在数据分析中的应用。无论你是刚入门数据分析领域,还是希望深挖数据分析技术的高级研究人员,这个专栏都将对你有所帮助。
专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB圆形Airy光束前沿技术探索:解锁光学与图像处理的未来

# 2.1 Airy函数及其性质
Airy函数是一个特殊函数,由英国天文学家乔治·比德尔·艾里(George Biddell Airy)于1838年首次提出。它在物理学和数学中
【未来人脸识别技术发展趋势及前景展望】: 展望未来人脸识别技术的发展趋势和前景
# 1. 人脸识别技术的历史背景
人脸识别技术作为一种生物特征识别技术,在过去几十年取得了长足的进步。早期的人脸识别技术主要基于几何学模型和传统的图像处理技术,其识别准确率有限,易受到光照、姿态等因素的影响。随着计算机视觉和深度学习技术的发展,人脸识别技术迎来了快速的发展时期。从简单的人脸检测到复杂的人脸特征提取和匹配,人脸识别技术在安防、金融、医疗等领域得到了广泛应用。未来,随着人工智能和生物识别技术的结合,人脸识别技术将呈现更广阔的发展前景。
# 2. 人脸识别技术基本原理
人脸识别技术作为一种生物特征识别技术,基于人脸的独特特征进行身份验证和识别。在本章中,我们将深入探讨人脸识别技
爬虫与云计算:弹性爬取,应对海量数据

# 1. 爬虫技术概述**
爬虫,又称网络蜘蛛,是一种自动化程序,用于从网络上抓取和提取数据。其工作原理是模拟浏览器行为,通过HTTP请求获取网页内容,并
【未来发展趋势下的车牌识别技术展望和发展方向】: 展望未来发展趋势下的车牌识别技术和发展方向

# 1. 车牌识别技术简介
车牌识别技术是一种通过计算机视觉和深度学习技术,实现对车牌字符信息的自动识别的技术。随着人工智能技术的飞速发展,车牌识别技术在智能交通、安防监控、物流管理等领域得到了广泛应用。通过车牌识别技术,可以实现车辆识别、违章监测、智能停车管理等功能,极大地提升了城市管理和交通运输效率。本章将从基本原理、相关算法和技术应用等方面介绍
卡尔曼滤波MATLAB代码在预测建模中的应用:提高预测准确性,把握未来趋势
# 1. 卡尔曼滤波简介**
卡尔曼滤波是一种递归算法,用于估计动态系统的状态,即使存在测量噪声和过程噪声。它由鲁道夫·卡尔曼于1960年提出,自此成为导航、控制和预测等领域广泛应用的一种强大工具。
卡尔曼滤波的基本原理是使用两个方程组:预测方程和更新方程。预测方程预测系统状态在下一个时间步长的值,而更新方程使用测量值来更新预测值。通过迭代应用这两个方程,卡尔曼滤波器可以提供系统状态的连续估计,即使在存在噪声的情况下也是如此。
# 2. 卡尔曼滤波MATLAB代码
### 2.1 代码结构和算法流程
卡尔曼滤波MATLAB代码通常遵循以下结构:
```mermaid
graph L
【高级数据可视化技巧】: 动态图表与报告生成
# 1. 认识高级数据可视化技巧
在当今信息爆炸的时代,数据可视化已经成为了信息传达和决策分析的重要工具。学习高级数据可视化技巧,不仅可以让我们的数据更具表现力和吸引力,还可以提升我们在工作中的效率和成果。通过本章的学习,我们将深入了解数据可视化的概念、工作流程以及实际应用场景,从而为我们的数据分析工作提供更多可能性。
在高级数据可视化技巧的学习过程中,首先要明确数据可视化的目标以及选择合适的技巧来实现这些目标。无论是制作动态图表、定制报告生成工具还是实现实时监控,都需要根据需求和场景灵活运用各种技巧和工具。只有深入了解数据可视化的目标和调用技巧,才能在实践中更好地应用这些技术,为数据带来
:YOLO目标检测算法的挑战与机遇:数据质量、计算资源与算法优化,探索未来发展方向
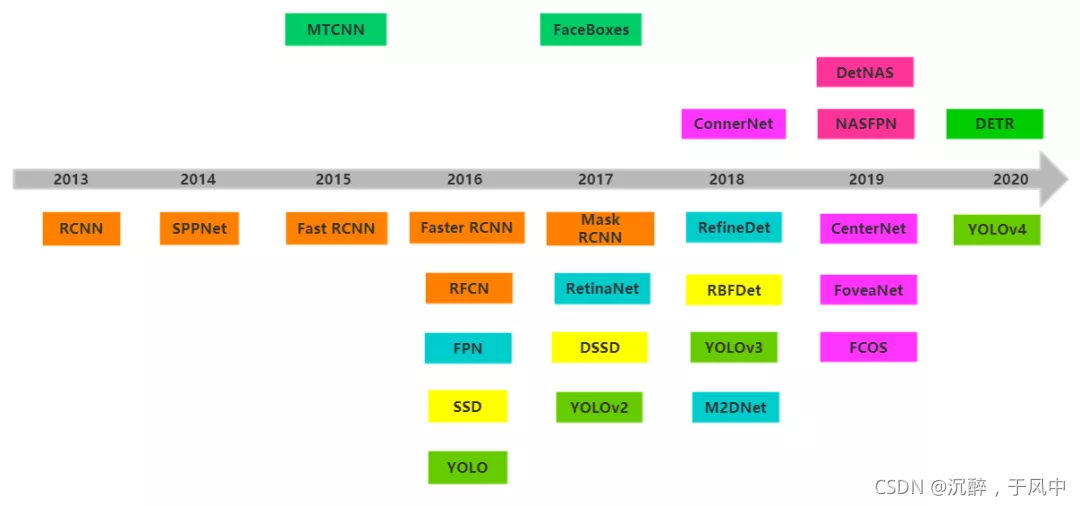
# 1. YOLO目标检测算法简介
YOLO(You Only Look Once)是一种
【人工智能与扩散模型的融合发展趋势】: 探讨人工智能与扩散模型的融合发展趋势

# 1. 人工智能与扩散模型简介
人工智能(Artificial Intelligence,AI)是一种模拟人类智能思维过程的技术,其应用已经深入到各行各业。扩散模型则是一种描述信息、疾病或技术在人群中传播的数学模型。人工智能与扩散模型的融合,为预测疾病传播、社交媒体行为等提供了新的视角和方法。通过人工智能的技术,可以更加准确地预测扩散模型的发展趋势,为各
MATLAB稀疏阵列在自动驾驶中的应用:提升感知和决策能力,打造自动驾驶新未来
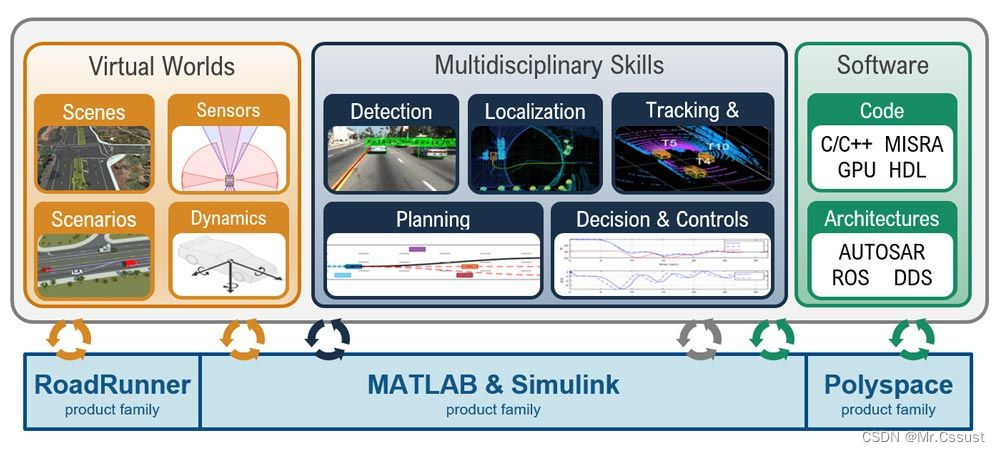
# 1. MATLAB稀疏阵列基础**
MATLAB稀疏阵列是一种专门用于存储和处理稀疏数据的特殊数据结构。稀疏数据是指其中大部分元素为零的矩阵。MATLAB稀疏阵列通过只存储非零元素及其索引来优化存储空间,从而提高计算效率。
MATLAB稀疏阵列的创建和操作涉及以下关键概念:
* **稀疏矩阵格式:**MATLAB支持多种稀疏矩阵格式,包括CSR(压缩行存
【YOLO目标检测中的未来趋势与技术挑战展望】: 展望YOLO目标检测中的未来趋势和技术挑战
# 1. YOLO目标检测简介
目标检测作为计算机视觉领域的重要任务之一,旨在从图像或视频中定位和识别出感兴趣的目标。YOLO(You Only Look Once)作为一种高效的目标检测算法,以其快速且准确的检测能力而闻名。相较于传统的目标检测算法,YOLO将目标检测任务看作一个回归问题,通过将图像划分为网格单元进行预测,实现了实时目标检测的突破。其独特的设计思想和算法架构为目标检测领域带来了革命性的变革,极大地提升了检测的效率和准确性。
在本章中,我们将深入探讨YOLO目标检测算法的原理和工作流程,以及其在目标检测领域的重要意义。通过对YOLO算法的核心思想和特点进行解读,读者将能够全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )