K8S_Linux-使用kubectl管理Kubernetes容器平台-使用kubectl管理Kubernetes集群
发布时间: 2024-02-26 14:29:44 阅读量: 48 订阅数: 24 

WindowsQwen2.5VL环境搭建-执行脚本
# 1. 简介
## 1.1 什么是Kubernetes(K8S)及其在容器编排中的作用
Kubernetes,简称K8S,是一个开源的容器编排引擎,用于自动化部署、扩展和管理容器化应用程序。它可以帮助用户更高效地管理大规模容器化应用,提供自动化的容器部署、扩展、缩容以及健康检查等功能,同时具备强大的容错能力。
Kubernetes通过将容器打包成一个逻辑单元,统一部署、升级和管理应用程序,提高了开发和运维的效率。它实现了跨主机集群的自动化容器部署和管理,使用户能够专注于应用程序的开发,而不用过多关注底层的基础设施。
## 1.2 kubectl工具的作用和重要性
kubectl是Kubernetes的命令行工具,用于与Kubernetes集群进行交互,管理集群中的各种资源对象。通过kubectl,用户可以方便地创建、删除、查询各种资源对象(如Pod、Deployment、Service等),查看集群状态,并进行各种操作,如日志查看、应用更新、端口转发等。
kubectl是Kubernetes管理的重要工具之一,它提供了丰富的命令选项和参数,能够满足用户在不同场景下对集群的管理需求。熟练掌握kubectl的使用方法和技巧,对于提高Kubernetes集群的管理效率和操作便捷性具有非常重要的意义。
# 2. Kubernetes基础知识
容器编排平台 Kubernetes 是如今流行的开源平台之一,它为容器化应用程序提供了自动化部署、扩展和管理的功能。在 Kubernetes 中,kubectl 是一种命令行工具,用于与 Kubernetes 集群进行交互和管理。
### Kubernetes架构概述
Kubernetes 架构包括 Master 组件和 Node 组件。Master 负责集群的控制和管理,包括 API Server、Controller Manager、Scheduler 和 etcd。Node 是集群中的工作节点,每个 Node 上运行着容器化的应用程序,包括 kubelet、kube-proxy 和 Docker 等组件。
### 容器化应用程序与服务的部署与管理
在 Kubernetes 中,用户可以使用 **Deployment** 对象来定义应用程序的部署方式,包括副本数量、升级策略等。另外,**Service** 对象可以暴露应用程序在集群内外的访问端点,实现负载均衡和服务发现。
### Kubernetes对象和资源描述文件的概念
在 Kubernetes 中,一切皆为对象,通过使用 YAML 或 JSON 格式的描述文件来定义和配置这些对象。常见的对象包括 Pod、Namespace、Service、Deployment 等,每个对象都有自己的规格和控制字段。kubectl 可以通过这些描述文件对 Kubernetes 集群进行操作和管理。
# 3. 安装与配置kubectl
在本章中,我们将介绍如何安装和配置kubectl工具,以便与Kubernetes集群进行交互。
#### 3.1 kubectl安装的步骤和方法
要安装kubectl,可以根据你的操作系统执行相应的安装步骤。以下是一些常用操作系统的安装方法:
- **Linux**:
```bash
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
chmod +x kubectl
sudo mv kubectl /usr/local/bin/
```
- **Mac**:
```bash
brew install kubernetes-cli
```
- **Windows**:
1. 下载kubectl.exe文件
2. 将kubectl.exe添加到系统的环境变量中
#### 3.2 配置kubectl连接到目标Kubernetes集群
安装kubectl后,需要配置kubectl连接到目标Kubernetes集群。可以通过以下命令完成配置:
```bash
kubectl config set-cluster my-cluster --server=https://cluster-api-url --certificate-authority=ca.crt
kubectl config set-credentials my-user --client-certificate=user.crt --client-key=user.key
kubectl config set-context my-context --cluster=my-cluster --user=my-user
kubectl config use-context my-context
```
#### 3.3 kub

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏“使用kubectl管理Kubernetes容器平台”涵盖了多个关键主题,包括微服务架构师课程介绍、深入学习kubectl语法、完善及扩展kubectl命令、管理Kubernetes集群、部署应用程序、网络管理与负载均衡、安全管理与认证授权、自动化与扩展、备份与恢复、跨云平台管理以及大规模部署等内容。通过本专栏,读者将系统学习如何使用kubectl进行各种操作及管理任务,帮助他们更好地利用Kubernetes容器平台搭建和管理应用程序环境。无论是初学者还是有一定经验的专业人士,都能在本专栏中找到有价值的知识和实践经验,助力他们提升在容器化部署和管理领域的技能水平。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【惠普ProBook 440 G4内存升级深度指南】:专业步骤与关键注意事项

# 摘要
本论文以惠普ProBook 440 G4笔记本电脑为研究对象,系统地介绍了内存升级的理论基础、准备工作、操作指南及优化维护策略。首先,概述了内存技术的发展历程及其在笔记本电脑中的应用。接着,详细分析了ProBook 440 G4的原厂内存规格和升级影响因素,包括硬件兼容性和操作系统需求。然后,本论文提供了内存升级的详细步骤
Java课设实验报告(聊天程序+白板程序):项目规划与执行要点揭秘
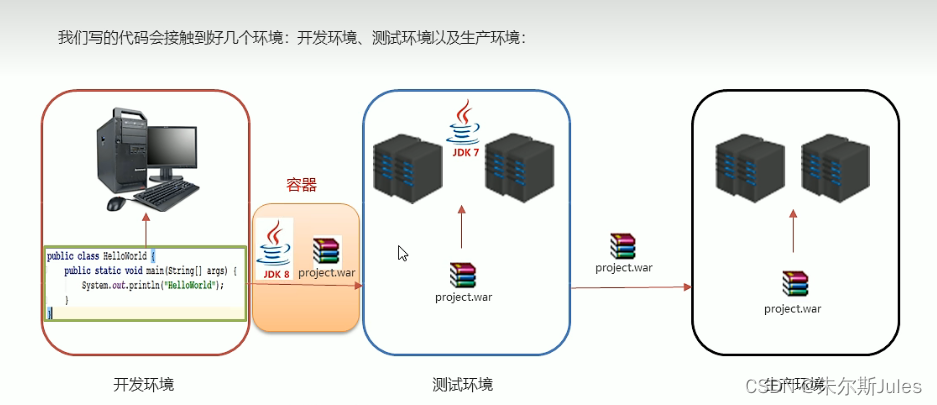
# 摘要
本论文详细介绍了聊天程序和白板程序的设计与实现过程。首先进行项目概述与需求分析,强调了Java编程基础及网络通信原理在开发中的重要性。随后,分别探讨了聊天程序和白板程序的设计理念、关键技术点、编码实践和测试过程。在项目测试与评估章节中,本文阐述了测试策略、方法以及如何根据测试结果进行问题修复。最后,在项目总结与经验分享章节中,本文回顾了项目实施过程,总结了项目管理的经验,并对未来
【光猫配置秘籍】:db_user_cfg.xml文件完全解读与高效应用

# 摘要
本文全面介绍了db_user_cfg.xml文件的各个方面,包括其概述、结构解析、配置实践、高级应用技巧以及未来展望。首先,概述了db_user_cfg.xml文件的用途和重要性,然后详细分析了文件的结构和核心配置元素,如用户账户配置、网络设置和安全权限管理。在配置实践部分,文章讨论了如何执行常见的配置任务和故障排查,以及如何通过调整配置项来优化系统
GAMIT批处理错误处理手册:10大常见问题与解决方案

# 摘要
GAMIT批处理作为一款广泛应用于地球科学领域的数据处理软件,其批处理功能对于处理大量数据至关重要。本文首先介绍了GAMIT批处理的基本概念和环境配置,然后详细阐述了GAMIT批处理的基本操作,包括命令语法、文件操作技巧和条件与循环控制。文章接着分析了GA
新能源汽车智能座舱软件测试用例设计精要:案例研究与技巧大公开

# 摘要
随着新能源汽车市场的快速发展,智能座舱作为其核心组成部分,对软件测试的要求日益提高。本文全面概述了智能座舱的软件测试理论基础,详细探讨了测试用例设计的重要性、不同测试类型与方法论,以及测试用例设计原则与模板。在实践中,本文深入分析了功能、性能和安全性测试用例的设计,同时关注测试用例管理与优化,包括版本控制、复用与维护,以及效果评估与优化策略。最后,
ANSYS TurboGrid应用实例详解:从新手到专家的快速通道

# 摘要
本文全面介绍了ANSYS TurboGrid的使用流程、复杂案例分析以及与CFD软件的集成应用。文章首先概述了TurboGrid的基本功能和操作界面,然后深入讲解了网格生成的基础、网格质量评估与优化策略。在案例分析部分,文章通过实际案例探讨了网格构建流程、高级网格技术的应用以及网格独立性验证和优化。此外,本文还探讨了TurboGrid与CFD软件集成中的数据
【LAT1173定时器终极指南】:掌握高精度同步的10大秘诀
# 摘要
高精度定时器在现代电子系统中扮演着核心角色,从基础的硬件构成到复杂的软件配置,其重要性贯穿于硬件与软件的交互之中。本文首先介绍了高精度定时器的基本概念及其在系统中的重要性,随后探讨了定时器的硬件基础,包括其组成、工作原理和影响精度的关键因素。文章进一步深入到软件层面,详细描述了定时器的配置要点、中断服务程序编写以及同步技术。在实际应用中,本文分析了编程实践和案例,并讨论了常见问题的解决方案。最后,文章展望了定时器
Qt拖拽事件高级处理:撤销、重做与事务管理的完整策略

# 摘要
本论文深入探讨了Qt框架中拖拽事件处理、撤销与重做机制以及事务管理的原理和实践应用。通过对撤销与重做机制的理论分析和实现技术研究,文章阐述了历史记录栈的设计、操作的保存与恢复机制、性能优化策略以及数据状态的快照技术。事务管理章节则侧重于解释事务的基本概念、ACID属性及在多种场景下的实
W5500编程秘籍:提升网络通信效率的高级技巧

# 摘要
本文全面介绍了W5500芯片的功能、通信原理以及编程方法。首先,概述了W5500芯片的特点及其网络通信的基本原理。接着,详细探讨了W5500的基础编程,包括寄存器操作、网络初始化配置、数据包的发送与接收。在高级网络编程方面,文章分析了TCP/UDP协议栈的应用、内存管理优化技巧,并通过实战案例展示了物联网设备和多线程网络通信的应用场景。此外,本文还涉及了W5500在A
Jpivot从入门到精通:揭秘数据分析师的进阶秘籍

# 摘要
Jpivot作为一款强大的数据可视化和分析工具,在企业级应用中扮演着重要角色。本文首先介绍了Jpivot的基本概念、安装配置以及核心功能,包括数据透视表的创建、编辑、数据源连接和模型构
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )