【R语言热力图定制专家】:掌握个性化d3heatmap热力图的制作
发布时间: 2024-11-08 15:53:31 阅读量: 40 订阅数: 33 
# 1. R语言和热力图概述
## 1.1 R语言简介
R语言是一门专为统计分析和图形表示设计的编程语言和环境。它在数据挖掘、机器学习、生物信息学等多个领域中得到了广泛应用。R语言拥有大量强大的包(Package),这使得它能够处理各种复杂的数据分析任务,包括数据清洗、模型建立、结果展示等。
## 1.2 热力图定义
热力图(Heatmap)是一种可视化技术,通常用于展示矩阵或数据表中的数据大小和模式。在热力图中,数据值由颜色的强度来表示,颜色越深表示数值越大。热力图能够直观地揭示数据中的趋势和异常点,常用于基因表达数据分析、市场研究等多个领域。
## 1.3 R语言与热力图的结合
R语言通过热力图包,如`heatmap.2`, `pheatmap`, `ComplexHeatmap`以及`d3heatmap`等,能够方便地生成各种样式和定制化的热力图。这些包不仅提供了基本的热力图生成功能,还支持颜色定制、行列分组、交互式探索等多种高级特性,使得R语言在热力图的绘制方面具有高度的灵活性和强大的表现力。
# 2. d3heatmap包的基础使用
热力图是数据分析和可视化中的一种强大工具,它能够直观地表示数据矩阵中的值大小,通过颜色的深浅来展示数据的强弱关系。在R语言中,`d3heatmap`包是创建热力图的一种流行选择,它基于D3.js技术,提供了一系列的定制化选项来生成丰富的交互式热力图。本章我们将详细介绍`d3heatmap`包的基本使用方法,颜色定制技巧,以及如何调整热力图的尺寸和缩放功能。
## 2.1 d3heatmap包简介
### 2.1.1 d3heatmap包的安装与加载
首先,您需要在R环境中安装`d3heatmap`包。这可以通过以下命令完成:
```r
install.packages("d3heatmap")
```
安装完成后,使用`library`函数加载该包,以便我们可以调用它的函数和特性:
```r
library(d3heatmap)
```
### 2.1.2 基本热力图的生成方法
创建一个基本的热力图相当简单。假设您有一个数据矩阵`data_matrix`,您可以使用以下命令生成一个热力图:
```r
d3heatmap(data_matrix)
```
这里`data_matrix`应该是一个数值型矩阵或者数据框,其中的值将通过颜色的深浅来展示。生成的热力图是一个交互式图表,可以在RStudio的Viewer面板中查看。
## 2.2 热力图的颜色定制
颜色是热力图中最直观的元素,通过定制颜色方案可以更加突出数据的特点。
### 2.2.1 颜色方案的选择
`d3heatmap`包提供了几种预设的颜色方案,例如`"blueWhiteRed"`, `"redBlackBlue"`, `"blueYellowRed"`等。您可以在绘制热力图时使用`colors`参数指定颜色方案:
```r
d3heatmap(data_matrix, colors = "blueWhiteRed")
```
### 2.2.2 自定义颜色映射
如果您对预设的颜色方案不满意,还可以自定义颜色映射。您需要提供一个R颜色向量,按照从最小值到最大值的顺序排列:
```r
color_vector <- colorRampPalette(c("blue", "white", "red"))(10)
d3heatmap(data_matrix, colors = color_vector)
```
上面的代码首先使用`colorRampPalette`函数创建了一个包含10个颜色的向量,然后将其传递给`colors`参数。
## 2.3 热力图的尺寸与缩放
在处理大规模数据时,热力图的尺寸和缩放功能变得尤为重要。
### 2.3.1 热力图尺寸的调整
调整热力图的尺寸可以通过`width`和`height`参数实现,单位是像素:
```r
d3heatmap(data_matrix, width = 800, height = 600)
```
上述命令将热力图的宽度和高度分别设置为800像素和600像素。
### 2.3.2 缩放功能的实现和优化
`d3heatmap`包允许用户缩放热力图以查看更详细的信息。这通常通过点击和拖动来实现,但也可以通过代码中的`zoom`参数来启用:
```r
d3heatmap(data_matrix, zoom = TRUE)
```
将`zoom`设置为`TRUE`允许用户使用鼠标缩放热力图。此外,还可以通过`scale`参数控制是否显示缩放条:
```r
d3heatmap(data_matrix, zoom = TRUE, scale = "none")
```
上面的命令在启用缩放的同时,隐藏了缩放条。
在本章节中,我们介绍了`d3heatmap`包的基础使用方法,包括如何安装、加载,以及创建基本热力图。接着,我们详细讲解了如何定制热力图的颜色,并介绍了不同的颜色方案及其选择。最后,我们探讨了调整热力图尺寸的技巧以及如何实现和优化缩放功能,为读者展示了如何在R环境中创建和定制交互式热力图。
在下一章中,我们将深入探讨数据的准备和预处理过程,这是创建高质量热力图的前提。我们会详细介绍如何进行数据筛选与清洗、归一化与标准化处理、以及数据的分组和标注,这些都是制作专业热力图不可或缺的步骤。
# 3. 热力图数据准备与预处理
在对热力图进行深入分析之前,对数据进行适当的准备和预处理是至关重要的。本章将聚焦于如何有效筛选、清洗、归一化/标准化,以及如何对数据进行分组和标注,以保证热力图能够准确反映数据的特征和关系。
## 3.1 数据筛选与清洗
在数据科学项目中,数据质量往往决定了分析结果的可靠性。热力图作为一种数据可视化手段,也不例外。准确的数据筛选和清洗步骤能极大提升热力图的质量。
### 3.1.1 缺失值处理
缺失值是数据分析中最常见的问题之一。处理缺失值的方法有很多,如删除包含缺失值的行或列、填充缺失值(使用均值、中位数、众数或其他算法)等。在R语言中,可以使用`na.omit`函数删除包含缺失值的行,或使用`impute`包中的函数填充缺失值。
```r
# 假设有一个名为data的矩阵或数据框
# 删除包含缺失值的行
cleaned_data <- na.omit(data)
# 使用均值填充缺失值
library(impute)
data_imputed <- impute(data, what = "mean")
```
在处理缺失值时,选择的方法取决于缺失值的分布情况以及数据本身的特点。通常,填充缺失值更为常见,因为这样可以保留更多的数据信息。
### 3.1.2 异常值处理
异常值可能扭曲分析结果,因此在进行热力图绘制之前需要对它们进行处理。异常值检测可以基于统计学的方法,比如使用箱线图识别离群点。一旦识别出异常值,可以选择删除、修正或保留它们。
```r
# 使用箱线图方法识别异常值
Q1 <- quantile(data$column_name, 0.25)
Q3 <- quantile(data$column_name, 0.75)
IQR <- Q3 - Q1
lower_bound <- Q1 - 1.5 * IQR
upper_bound <- Q3 + 1.5 * IQR
outliers <- data[data$column_name < lower_bound | data$column_name > upper_bound, ]
# 选择性删除异常值
clean_data <- data[data$column_name >= lower_bound & data$column_name <= upper_bound, ]
```
在处理异常值时,分析师需要根据具体案例和领域知识来决定最合适的处理方法。在某些情况下,异常值可能蕴含重要的信息,因此在没有充分理由的情况下轻易丢弃它们是不明智的。
## 3.2 数据归一化与标准化
由于数据集中的不同变量往往有不同的量纲和数值范围,直接绘制热力图可能会导致某些变量因数值差

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 R 语言中强大的 d3heatmap 数据包,为数据可视化和分析提供了全面指南。从初学者到高级用户,本专栏涵盖了广泛的主题,包括:
* d3heatmap 热力图的创建和自定义
* 交互式热力图的构建
* 大数据热力图分析
* 与其他 R 数据包(如 shiny、ggplot2、dplyr)的集成
* 生物信息学、金融和统计学中的应用案例
* 从 CRAN 到 GitHub 的数据包获取和安装
* 自定义数据包开发以扩展 d3heatmap 功能
* 结合 d3heatmap 和 plotly 实现高级热力图交互
* 复杂热力图结果的解读和分析
通过深入的教程、示例和案例研究,本专栏将帮助您掌握 d3heatmap 的各个方面,并将其应用于各种数据分析和可视化任务。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
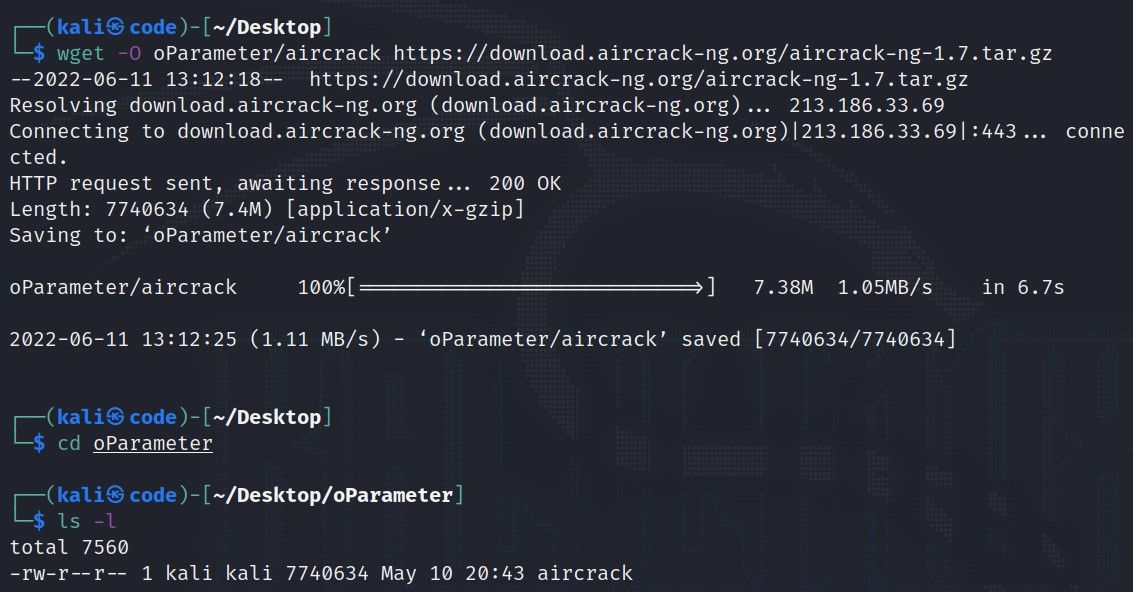
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )