【人工智能与控制理论】:结合状态方程的智能系统设计入门
发布时间: 2025-01-03 19:11:38 阅读量: 24 订阅数: 33 
# 摘要
随着人工智能技术的快速发展,其与控制理论的结合越来越紧密,成为推动现代智能系统设计的关键力量。本文从人工智能与控制理论的基础出发,系统介绍了状态空间模型及其在智能系统设计中的重要应用。文章深入探讨了智能系统设计的核心概念、控制理论的应用、以及如何结合状态方程进行智能系统的设计实践。此外,本文通过具体案例分析,阐述了智能系统在自动驾驶和工业机器人领域的应用,并对未来研究方向和应用前景进行了展望,特别关注了人工智能与控制理论融合的新趋势和创新思路。
# 关键字
人工智能;控制理论;状态空间模型;智能系统设计;模型预测控制;多智能体系统
参考资源链接:[离散系统状态方程解-状态转移矩阵详解](https://wenku.csdn.net/doc/4f4n9chz5u?spm=1055.2635.3001.10343)
# 1. 人工智能与控制理论基础
## 1.1 人工智能的兴起与发展
人工智能(AI)作为科技领域的一次重大飞跃,已经从科幻概念转变为现实世界的强大工具。AI的迅速发展不仅推动了技术革新,也深刻改变了人类的工作和生活方式。其核心目标是通过模拟和拓展人类智能,让机器能够执行复杂的任务,如图像识别、自然语言处理、智能推荐系统等。
## 1.2 控制理论的演进与应用
控制理论是研究控制系统动态行为、设计和分析的数学基础学科。从古典控制理论到现代控制理论,控制理论的发展历程与人工智能技术的融合,共同推动了智能控制系统的发展。控制理论中的核心概念,如稳定性、可控性、可观测性等,对于理解复杂系统的行为至关重要。
## 1.3 人工智能与控制理论的融合
随着AI技术与控制理论的深入融合,智能控制系统的出现为自动化和智能化提供了新的可能性。AI技术的加入让系统具备了学习和适应环境的能力,而控制理论则确保了系统在满足性能指标的同时实现最优操作。两者的结合不仅提高了系统的智能化水平,还拓展了其应用范围,从工业自动化到消费电子产品,随处可见其身影。
在本章中,我们将探索AI和控制理论的初步交集,为深入理解智能系统设计打下坚实的基础。
# 2. 状态空间模型简介
### 2.1 状态方程的定义与特性
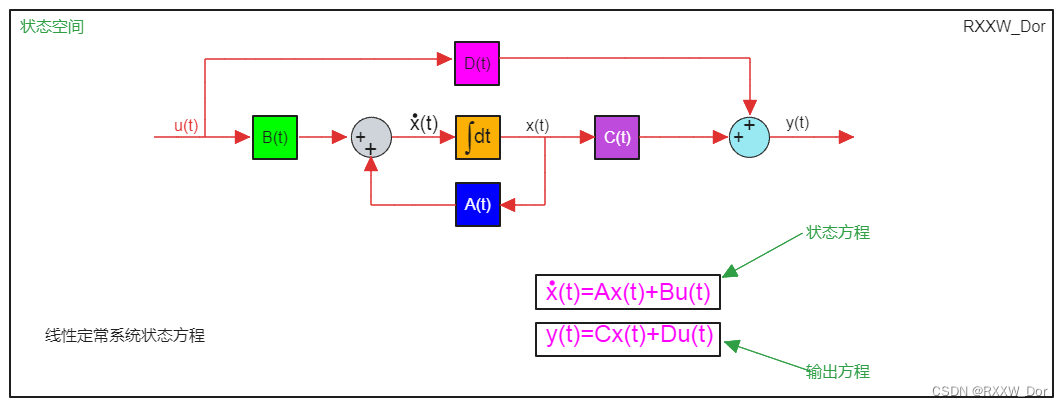
状态空间模型是控制系统理论中的一个基础概念,它为动态系统的分析和设计提供了一个框架。该模型将系统的时间响应用状态变量的形式表示出来,并通过状态方程来描述系统的动态行为。
#### 2.1.1 状态变量和动态系统
状态变量是表征系统内部动态特性的变量,它们构成了系统的状态向量。在任何给定时间点,状态向量描述了系统的所有历史信息。换言之,了解了状态向量,理论上可以预测系统未来的所有行为。
```math
x(t+1) = Ax(t) + Bu(t)
```
上述公式中,`x(t)`表示当前状态向量,`u(t)`表示输入向量,`A`是系统动态矩阵,`B`是输入矩阵。每一个状态向量都是之前状态和输入的函数,这体现了系统的记忆特性。
#### 2.1.2 状态空间模型的数学描述
状态空间模型由一组线性微分方程组成,其中包括状态方程和输出方程。状态方程描述了系统内部状态变量如何随时间演化,而输出方程则定义了系统输出与状态变量和输入之间的关系。
对于一个线性时不变系统,状态空间模型通常表示为:
```math
\begin{align}
\dot{x}(t) &= Ax(t) + Bu(t) \\
y(t) &= Cx(t) + Du(t)
\end{align}
```
其中,`x(t)`是状态向量,`u(t)`是输入向量,`y(t)`是输出向量,`A`是系统矩阵,`B`是输入矩阵,`C`是输出矩阵,`D`是直接传递矩阵,而点号(`˙`)表示对时间的导数。
### 2.2 状态方程在控制系统中的作用
#### 2.2.1 描述系统动态行为
状态方程能够准确描述系统的动态行为。在控制系统中,动态行为可以理解为系统状态随时间变化的路径。通过分析状态方程,可以研究系统对输入的响应以及它如何随时间发展。
#### 2.2.2 系统稳定性和可控性分析
状态方程对于分析系统的稳定性和可控性至关重要。稳定性的判断可以基于系统矩阵`A`的特征值,如果系统矩阵的特征值都位于复平面的左半部分,则系统是稳定的。可控性则通过可控性矩阵来检验,如果可控性矩阵满秩,则系统是完全可控的。
为了更深入理解状态空间模型在控制系统设计中的作用,下面将通过一个简单的例子来展示其应用。
```python
import numpy as np
from scipy.linalg import place
# 定义系统矩阵 A 和输入矩阵 B
A = np.array([[1, 1], [0, 1]])
B = np.array([[0], [1]])
# 求解状态反馈矩阵 K 使得闭环系统特征值在 -1 和 -2
eigenvalues = np.array([-1, -2])
K, _, _ = place(A, B, eigenvalues)
print(f"反馈增益矩阵 K: \n{K}")
```
在上述代码中,使用了`scipy.linalg.place`函数,该函数计算反馈增益矩阵`K`,使得闭环系统的特征值位于指定位置。当系统矩阵`A`和输入矩阵`B`被实际值替换时,这段代码将帮助设计出一个状态反馈控制器,以实现期望的系统动态。
通过上述内容的介绍,我们已经对状态空间模型的定义和特性有了基本的了解。接下来,我们将探讨状态方程在控制系统中的具体应用,从而进一步展示状态空间模型的强大功能。
# 3. 智能系统设计的核心概念
智能系统的设计是将智能技术与控制理论相结合,创造出能自动适应环境变化、解决复杂问题、执行任务的系统。与传统控制系统相比,智能系统拥有学习和适应能力,这使得它们在处理不确定性和复杂环境时更为有效。
### 智能系统与传统控制系统的比较
智能系统与传统控制系统在设计原理和方法上存在明显差异。传统控制系统依赖预设的规则和模型,通过精确计算和逻辑判断实现控制。相比之下,智能系统强调通过机器学习、模式识别和决策支持技术来提高系统的智能化水平。例如,在复杂环境下的机器人导航,传统控制系统可能依赖预设的地图和路径规划,而智能系统则能够根据实时的环境变化动态调整路径。
### 智能系统设计的目标和方法
智能系统设计的目标通常包括提高自动化水平、增强决策能力、优化资源使用和增强适应性。为了实现这些目标,智能系统设计采用的方法包括但不限于:
- **机器学习:** 使系统能够从数据中学习和提取规律,不断优化其性能。
- **模糊逻辑:** 用于处理不精确或含糊的信息,使系统能够做出符合人类经验的判断。
- **神经网络:** 模拟人脑的神经元网络结构,使系统能够处理复杂的非线性问题。
## 控制理论在智能系统中的应用
控制理论为智能系统提供了坚实的基础,尤其是在系统的稳定性和可控性方面,同时,随着技术的发展,控制理论也与人工智能技术相结合,产生了如模型预测控制和自适应控制策略等新型控制方法。
### 模型预测控制(MPC)
模型预测控制是一种先进的控制策略,它利用系统模型对未来的行为进行预测,并在此基础上优化当前的控制动作。MPC特别适合于处理具有复杂动态特性和约束条件的系统。
```mermaid
graph LR
A[开始] --> B{建立模型}
B --> C[定义目标函数]
C --> D[设定约束条件]
D --> E[优化算法]
E --> F[计算最优控制动作]
F --> G[应用控制动作]
G --> H{到达新状态}
H --> B
```
### 自适应控制策略
自适应控制策略允许系统根据环境变化调整其控制参数,以保持最优性能。自适应控制能够处理系统参数不确定性和外部扰动的问题。
### 强化学习与反馈控制
强化学习是机器学习的一个分支,它通过试错来优化决策过程。在智能系统中,强化学习可以与反馈控制相结合,通过系统对环境的响应来调整控制策略,从而实现性能的持续提升。
### 代码示例和逻辑分析
以强化学习在智能系统中的一个具体应用为例,我们可以考虑一个机器人在未知环境中寻找目标点的问题。这里使用 Q-learning 算法,一个无模型的强化学习算法。
```python
import numpy as np
# 假设环境状态为离散的10x10网格,目标点在网格(9,9)
states = 100
actions = ['left', 'right', 'up', 'down']
q_table = np.zeros((states, len(actions)))
# 学习参数
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.9 # 探索概率
epsilon_min = 0.01 # 探索概率的最小值
epsilon_decay = 0.99 # 探索概率衰减率
def epsilon_greedy_policy(state):
if np.random.rand() <= epsilon:
return actions[np.random.randint(0, len(actions))]
else:
return actions[np.argmax(q_table[state])]
# 强化学习训练过程
for episode in range(1000):
state = 0 # 假设初始状态为网格的(0,0)
done = False
while not done:
action = epsilon_greedy_policy(state)
# 这里简化处理,假设每个动作会直接移动到目标位置
next_state = state + 1 if action == 'up' else state - 1 if action == 'down' else state + 10 if action == 'right' else state - 10
next_state = min(max(next_state, 0), states - 1)
# 奖励设置为到达目标点的逆距离,但目标点是(99)
reward = -abs((next_state - 99) / 10)
q_table[state][actions.index(action)] += alpha * (reward + gamma * np.max(q_table[next_state]) - q_table[state][actions.index(action)])
state = next_state
done = state == 99 # 假设到达(99)状态即为完成目标
epsilon = max(epsilon_min, epsilon_decay * epsilon)
print(q_table)
```
在这个代码示例中,我们创建了一个简单的Q-learning算法来模拟一个机器人在10x10网格中寻找目标点的过程。算法通过不断地尝试不同的动作(上下左右移动),并根据获得的奖励来更新Q值表。通过这种方式,机器人学会了一组最优的动作序列以达到目标点。
在强化学习中,奖励函数的设置至关重要,它直接决定了算法能否正确地学习到任务。此外,探索与利用(exploration-exploitation)的平衡也是算法设计中的一个关键问题。在这个例子中,我们使用了一个简单的epsilon-greedy策略来平衡探索与利用。
在智能系统设计中,通过结合控制理论和人工智能技术,系统可以学习并适应不断变化的环境,从而完成更加复杂和精确的任务。这不仅适用于工业机器人,还广泛应用于自动驾驶汽车、无人机、智能交通系统等多个领域。随着技术的不断进步,未来的智能系统将更加智能化、高效化和自主化。
# 4. 结合状态方程的智能系统设计实践
## 4.1 设计智能系统的状态空间模型
### 4.1.1 状态观测器设计
在智能系统中,状态观测

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析离散系统状态方程,涵盖了数学基础、解法、应用实例和高级教程。专家深入分析离散时间动态系统,揭秘状态方程的稳定性与最优控制。专栏还提供了数字控制算法设计技巧、离散系统状态估计方法、系统辨识艺术、信号处理中的状态方程应用、状态反馈设计原理、鲁棒控制与状态方程、状态方程的数值解法与仿真、系统能控性与能观性分析、离散事件系统中的状态方程应用、人工智能与控制理论结合、以及工业过程控制中的稀缺实战技巧。通过深入学习本专栏,读者将掌握离散系统状态方程的全面知识和应用能力。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Trace32工具全方位解读:从基础入门到高级应用及性能优化秘籍(共20个核心技巧)
# 摘要
Trace32是一种广泛应用于嵌入式系统的调试工具,本文详细介绍了Trace32的安装、基础操作、高级应用、数据可视化及报告生成等方面。首先,本文概述了Trace32工具的基本信息及安装流程。随后,针对用户界面、基本命令、进程与线程追踪、内存和寄存器分析等基础操作提供了详细指导。文章进一步探讨了Trace32在性能分析、多核多线程调试以及脚本编程和自动化测试的高级应用。在数据可视化与报告方
新版本AIF_Cookbook v4.0全面剖析:掌握每个新特性
# 摘要
本文针对AIF_Cookbook v4.0版本进行了全面的介绍和分析,重点探讨了该版本新特性的理论基础、实践指南、性能优化、故障排除以及集成与部署策略。首先,文章概览了新版本的核心概念及其对实践应用的影响,并探讨了新引入算法的原理及其在效率和准确性上的提升。接着,通过核心功能的实践案例和数
LDAP集成新手必读:掌握Java与LDAP的20个实战技巧

# 摘要
本论文系统地阐述了LDAP基础及其与Java的集成技术。首先介绍了LDAP的数据模型、目录结构以及基本的查看和管理方法,为后续深入探讨Java与LDAP的交互操作打下基础。接着,文章详细说明了如何使用Java LDAP API进行基础的交互操作,包括搜索、用户和组管理等。进一步地,本文深入分析了LDAP的认证机制和安全配置,包括安全连接的配置与优化以及访问控制与权限管理。文章还
【安捷伦万用表技术优势】:揭秘专业用户为何偏爱6位半型号

# 摘要
本文系统介绍了安捷伦万用表的技术细节、行业应用案例以及未来技术趋势。首先概述了安捷伦万用表的基本情况,随后深入解析了其技术规格,包括精准度、分辨率、采样率、数据吞吐以及隔离和安全性能。接着,本文探讨了安捷伦6位半万用表在实验室精密测试、制造业质量控制以及研究与开发中的创新应用。此外,还分析了安捷伦万用表软件工具的功能,如数据采集与分析、自动化测试与控制和远程操作与维护。最后,本文
故障清零:WhateverGreen.kext_v1.5.6在黑果安装中的问题解决专家

# 摘要
WhateverGreen.kext是一款在MacOS黑果安装中广泛使用的内核扩展,它为不同的显卡提供了必要的驱动支持与配置选项。本文首先介绍了WhateverGreen.kext的作用及其重要性,然后详细阐述了在黑果安装中的基础设置步骤和基本配置方法,包括安装过程和修改配置文件的技巧。此外,还探讨了在安装和运行过程中可能遇到的常见问题及其解决策略,
AD630物联网应用挑战与机遇:深入解读与应对策略!
# 摘要
物联网作为技术进步的产物,为各行业提供了全新的应用模式和业务发展机会。本文首先介绍了物联网的定义,并对AD630芯片的技术规格及其在物联网领域的优势进行了概述。随后,探讨了物联网架构的关键技术,包括传感器、通信协议和数据处理技术,并分析了物联网安全与隐私保护的重要性和相关策略。通过智能家居、工业物联网和健康医疗等实践案例,展示了AD630芯片的多样化应用,并讨论了在这些应用中遇到的技术挑战
破解Windows XP SP3:驱动集成的高级技巧与最佳实践
# 摘要
Windows XP Service Pack 3(SP3)是微软公司推出的最后一个针对Windows XP操作系统的更新,它改进了系统的安全性、性能和兼容性。本文首先对Windows XP SP3进行概述,并在此基础上探讨驱动集成的理论基础,包括驱
【电源设计进阶】:MOS管驱动电路热管理的策略与实践
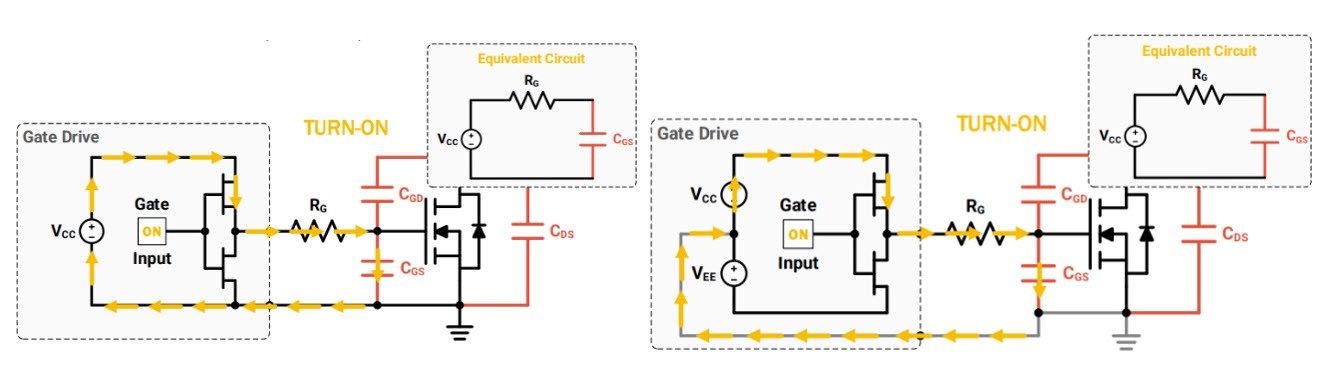
# 摘要
本文探讨了电源设计中MOS管驱动的重要性,分析了MOS管的基本原理与特性及其在电源设计中的作用,同时重点研究了MOS管驱动电路面临的热管理挑战。文章详细介绍了热效应的产生、影响,以及驱动电路中热量分布的关键因素,探讨了有效的散热策略和热管理技术。此外,本文还基于理论基础,讨论了热管理的计算方法、模拟仿真,以及热设计的数
【充电机安全标准完全手册】:国际规范的设计与实施

# 摘要
充电机作为电动汽车关键基础设施,其安全性对保障车辆和用户安全至关重要。本文首先强调了充电机安全标准的必要性和意义,随后全面回顾了充电机国际安全标准的演变历程及其关键要求,如安全性能和电磁兼容性。在理论基础方面,文章深入探讨了充电机设计原则、结构安全性分析和智能化安全监控。实践应用案例章节提供了商用充电桩、家用充电机以及维修更新方面的安全指南。最后,文章展望了未来充电机安全标准的发展趋势,重点分析了新兴技术、政策法规以及跨界合作对充电机
【MATLAB控制策略设计】:机电系统仿真中的关键应用
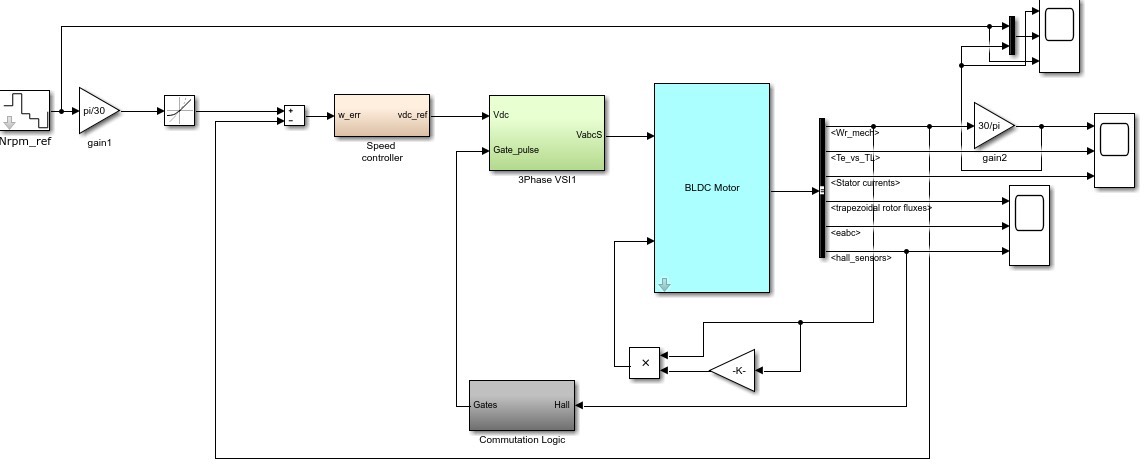
# 摘要
本文全面探讨了MATLAB在机电系统仿真中的应用,从基础理论到控制策略的设计与实现,再到未来发展方向。首先介绍了MATLAB在机电系统仿真中的基础理论和控制策略理论基础,包括控制系统的基本概念和数学模型。接着,详细阐述了在MATLAB中构建机电系统模型、仿真实现以及结果分析与优化的过程。此外,本文深入探讨了MATLAB控制策略在典型机电系统中的应用案例,并对自适应控
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )