MATLAB判断语句陷阱大揭秘:避免逻辑错误和代码缺陷
发布时间: 2024-06-10 00:49:59 阅读量: 84 订阅数: 35 

MATLAB中的基本语法和语句示例代码-综合文档

# 1. MATLAB判断语句基础
MATLAB判断语句是控制程序流的重要工具。它们允许根据条件执行不同的代码块。MATLAB提供了各种判断语句,包括`if-elseif-else`、`switch-case`和`while`循环。
`if-elseif-else`语句是最常用的判断语句。它允许根据一系列条件执行不同的代码块。`if`条件为真时,执行`if`块中的代码。如果`if`条件为假,则检查`elseif`条件。如果任何`elseif`条件为真,则执行相应的代码块。如果所有`if`和`elseif`条件都为假,则执行`else`块中的代码。
`switch-case`语句是一种多路选择语句。它允许根据一个变量的值执行不同的代码块。`case`语句指定要检查的变量值。如果变量值与`case`值匹配,则执行相应的代码块。如果没有任何`case`值与变量值匹配,则执行`otherwise`块中的代码。
# 2. MATLAB判断语句陷阱
### 2.1 常见逻辑错误
#### 2.1.1 比较运算符的误用
MATLAB 中的比较运算符包括:`==`(等于)、`~=`(不等于)、`<`(小于)、`>`(大于)、`<=`(小于或等于)、`>=`(大于或等于)。使用这些运算符时,需要注意以下常见错误:
* **误用`==`和`~=`比较浮点数:**浮点数由于计算机内部表示的误差,可能存在精度问题。因此,不应使用`==`和`~=`比较浮点数,而应使用`eps`或`tol`进行模糊比较(见第 5.2 节)。
* **使用`>`和`<`比较字符串:**字符串比较时,MATLAB 会根据 Unicode 代码点进行字典序比较。因此,使用`>`和`<`比较字符串可能会产生意外结果。建议使用`strcmp()`或`strcmpi()`函数进行字符串比较。
#### 2.1.2 布尔运算符的优先级
MATLAB 中的布尔运算符包括:`&`(与)、`|`(或)、`~`(非)。这些运算符的优先级如下:
```
~ > & > |
```
这意味着`~`运算符优先级最高,其次是`&`运算符,最后是`|`运算符。在编写判断语句时,应注意运算符的优先级,并使用括号明确运算顺序。
#### 2.1.3 逻辑短路
逻辑短路是指当布尔表达式的第一个操作数为`false`时,后面的操作数不会被求值。这可能会导致意外结果,例如:
```
if (a == 0) && (b / a > 10)
% 此代码不会执行,因为 a == 0 为 false
end
```
为了避免逻辑短路,应使用`&&`和`||`运算符显式地控制运算顺序。
### 2.2 代码缺陷和最佳实践
#### 2.2.1 避免使用`==`和`~=`比较浮点数
如前所述,浮点数比较存在精度问题。为了避免错误,应使用`eps`或`tol`进行模糊比较。例如:
```
if (abs(x - y) < eps)
% x 和 y 被视为相等
end
```
#### 2.2.2 正确使用`if-elseif-else`结构
`if-elseif-else`结构用于编写多重判断语句。使用时,应注意以下最佳实践:
* **使用`elseif`而不是嵌套`if`:**嵌套`if`语句会使代码难以阅读和维护。应使用`elseif`分支来处理不同的情况。
* **使用`else`分支处理所有其他情况:**`else`分支用于处理所有未在`if`和`elseif`分支中处理的情况。
#### 2.2.3 避免在`if`条件中使用赋值语句
在`if`条件中使用赋值语句会导致代码难以理解和调试。应将赋值语句与判断语句分开编写。例如:
```
% 错误的用法
if (a = 0)
% ...
end
% 正确的用法
if (a == 0)
% ...
end
```
# 3.1 调试判断语句
#### 3.1.1 使用`disp()`和`keyboard`进行调试
在调试判断语句时,可以使用`disp()`函数输出中间结果或变量值,以帮助识别逻辑错误。例如:
```matlab
% 检查变量x的值
disp(x);
% 检查比较结果
disp(x == 5);
% 在代码中设置断点
keyboard;
```
使用`keyboard`函数可以在代码执行到指定位置时暂停,并允许用户检查变量值和执行流程。
#### 3.1.2 利用MATLAB调试器
MATLAB调试器是一个强大的工具,可以帮助用户逐步执行代码,检查变量值并设置断点。要使用调试器,请在代码中设置断点,然后在命令窗口中输入`dbstop`命令。
```matlab
% 在第10行设置断点
dbstop in myFunction at 10;
% 运行代码
myFunction();
```
当代码执行到断点时,调试器将暂停,并允许用户检查变量值和执行流程。
### 3.2 优化判断语句
#### 3.2.1 避免冗余的判断
避免在代码中重复相同的判断条件,这会降低代码的可读性和可维护性。例如,以下代码可以简化为一个`if`语句:
```matlab
% 冗余的判断
if x > 0
disp('x is positive');
end
if x > 0
disp('x is greater than zero');
end
```
```matlab
% 简化的判断
if x > 0
disp('x is positive and greater than zero');
end
```
#### 3.2.2 使用向量化操作提高效率
对于涉及数组或矩阵的判断,使用向量化操作可以提高代码效率。向量化操作一次对整个数组或矩阵进行操作,避免了循环和逐个元素比较。
例如,以下代码使用向量化操作比较数组`x`中的所有元素是否大于0:
```matlab
% 向量化比较
x > 0
```
这比以下循环要高效得多:
```matlab
% 循环比较
for i = 1:length(x)
if x(i) > 0
disp('x(i) is positive');
end
end
```
# 4.1 嵌套判断语句
### 4.1.1 多重`if-elseif-else`语句
当需要根据多个条件执行不同的操作时,可以使用多重`if-elseif-else`语句。其语法如下:
```matlab
if condition1
statements1
elseif condition2
statements2
elseif condition3
statements3
else
statements4
end
```
其中,`condition1`、`condition2`、`condition3`是判断条件,`statements1`、`statements2`、`statements3`、`statements4`是执行的语句块。
**示例:**
```matlab
% 根据成绩等级输出评语
grade = 90;
if grade >= 90
disp('优秀')
elseif grade >= 80
disp('良好')
elseif grade >= 70
disp('中等')
elseif grade >= 60
disp('及格')
else
disp('不及格')
end
```
### 4.1.2 使用`switch-case`语句
当需要根据一个变量的值执行不同的操作时,可以使用`switch-case`语句。其语法如下:
```matlab
switch variable
case value1
statements1
case value2
statements2
case value3
statements3
otherwise
statements4
end
```
其中,`variable`是要判断的变量,`value1`、`value2`、`value3`是判断的值,`statements1`、`statements2`、`statements3`、`statements4`是执行的语句块。
**示例:**
```matlab
% 根据水果类型输出价格
fruit = 'apple';
switch fruit
case 'apple'
price = 1;
case 'banana'
price = 2;
case 'orange'
price = 3;
otherwise
price = 0;
end
```
## 4.2 逻辑函数和匿名函数
### 4.2.1 使用`logical()`函数和`@`符号
`logical()`函数可以将任何表达式转换为布尔值。`@`符号可以创建匿名函数。
**示例:**
```matlab
% 判断一个数字是否为偶数
isEven = @(x) mod(x, 2) == 0;
if logical(isEven(10))
disp('10 is even')
end
```
### 4.2.2 创建和使用匿名函数
匿名函数是一种没有名称的函数,可以使用`@`符号创建。
**示例:**
```matlab
% 创建一个计算圆周率的匿名函数
piFunction = @(x) 4 * atan(1) * x;
% 使用匿名函数计算圆周率
piValue = piFunction(1);
```
# 5. MATLAB判断语句的特殊情况
### 5.1 空值和NaN
**5.1.1 比较空值和NaN**
MATLAB中的空值和NaN(非数字)是特殊值,在判断语句中需要特殊处理。空值表示变量未定义或未赋值,而NaN表示一个无效的数字。
比较空值和NaN时,使用`isnan()`和`isinf()`函数:
```matlab
% 比较变量x是否为NaN
if isnan(x)
% x是NaN
end
% 比较变量y是否为无穷大
if isinf(y)
% y是无穷大
end
```
**5.1.2 处理空值和NaN的最佳实践**
处理空值和NaN时,应遵循以下最佳实践:
* 使用`isnan()`和`isinf()`函数明确检查空值和NaN。
* 避免使用`==`和`~=`比较空值和NaN,因为这些运算符会返回错误。
* 在比较之前,使用`isnan()`和`isinf()`将空值和NaN转换为有效值。
* 考虑使用`coalesce()`函数将空值和NaN替换为默认值。
### 5.2 模糊比较和容差
**5.2.1 使用`eps`和`tol`进行模糊比较**
在浮点数比较中,由于舍入误差,可能出现轻微差异。为了容忍这些小误差,可以使用`eps`(机器精度)和`tol`(容差)参数。
```matlab
% 使用eps比较浮点数x和y
if abs(x - y) < eps
% x和y相等(在机器精度内)
end
% 使用tol比较浮点数x和y,容差为0.01
if abs(x - y) < 0.01
% x和y相等(在0.01的容差内)
end
```
**5.2.2 容忍小误差的最佳实践**
容忍小误差时,应遵循以下最佳实践:
* 使用`abs()`函数计算浮点数之间的绝对差。
* 根据应用程序的具体要求选择合适的容差值。
* 避免使用`==`和`~=`进行模糊比较,因为这些运算符不适用于浮点数。
* 考虑使用`allclose()`函数进行模糊比较,该函数使用相对容差和绝对容差。
# 6. MATLAB判断语句的最佳实践**
**6.1 可读性、可维护性和可扩展性**
为了编写出可读性、可维护性和可扩展性高的MATLAB代码,在使用判断语句时应遵循以下最佳实践:
**6.1.1 使用清晰的命名约定**
变量、函数和语句块的名称应清晰、简洁且能反映其用途。避免使用模糊或通用的名称,如`x`或`y`。相反,使用描述性名称,如`input_data`或`validation_result`。
**6.1.2 注释代码以解释判断逻辑**
注释可以帮助其他开发者和未来的自己理解代码的意图和功能。在判断语句中,注释应解释条件的含义以及语句块执行的具体操作。
**6.1.3 遵循代码风格指南**
遵循一致的代码风格指南有助于提高代码的可读性和可维护性。MATLAB提供了一个内置的代码格式化工具,可以帮助自动格式化代码并确保其符合最佳实践。
**示例:**
```matlab
% 检查输入数据是否为空
if isempty(input_data)
% 如果输入数据为空,显示错误消息
error('输入数据不能为空!');
end
```
在这个示例中,变量名称`input_data`清楚地表示了它的用途。注释解释了条件的含义,即检查输入数据是否为空。如果条件为真,将显示一条错误消息。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 MATLAB 判断语句专栏!
本专栏将深入探讨 MATLAB 中判断语句的奥秘,从逻辑运算的基础到高级用法。我们将揭示判断语句的陷阱,帮助您避免逻辑错误和代码缺陷。此外,您还将学习优化判断语句性能的秘诀,提升代码效率和可读性。
本专栏涵盖了广泛的应用领域,包括数据分析、图像处理、科学计算、财务建模、控制系统、信号处理、计算机视觉、Web 开发、移动应用开发、游戏开发、教育和研究。通过深入了解判断语句,您将能够构建复杂逻辑控制流程,解决各种现实世界问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Xshell与Vmware交互解析】:打造零故障连接环境的5大实践

# 摘要
本文旨在探讨Xshell与Vmware的交互技术,涵盖远程连接环境的搭建、虚拟环境的自动化管理、安全交互实践以及高级应用等方面。首
火电厂资产管理系统:IT技术提升资产管理效能的实践案例
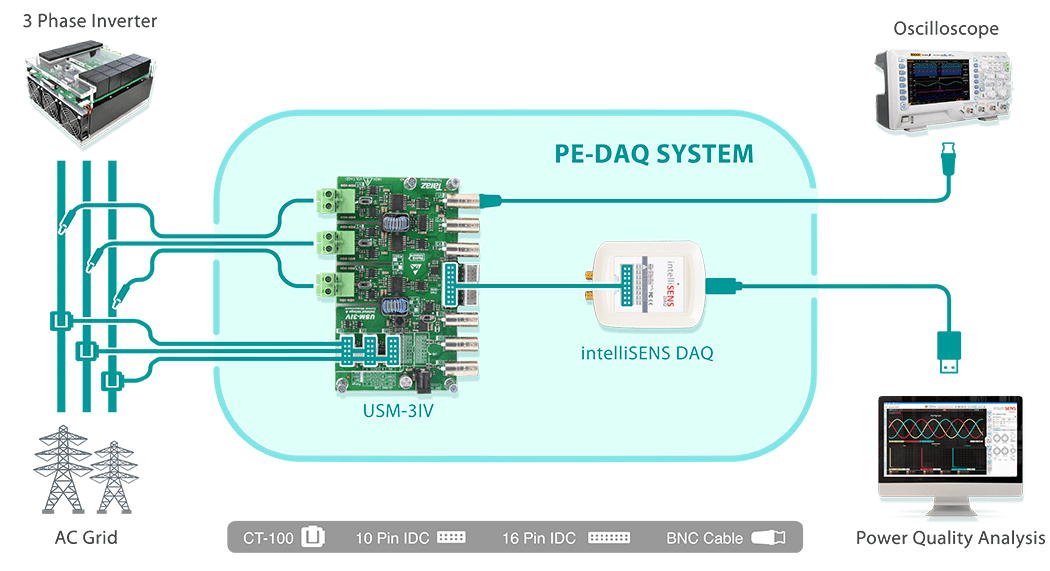
# 摘要
本文深入探讨了火电厂资产管理系统的背景、挑战、核心理论、实践开发、创新应用以及未来展望。首先分析了火电厂资产管理的现状和面临的挑战,然后介绍了资产管理系统的理论框架,包括系统架构设计、数据库管理、流程优化等方面。接着,本文详细描述了系统的开发实践,涉及前端界面设计、后端服务开发、以及系统集成与测试。随后,文章探讨了火电厂资产管理系统在移动端应用、物联网技术应用以及
Magento多店铺运营秘籍:高效管理多个在线商店的技巧
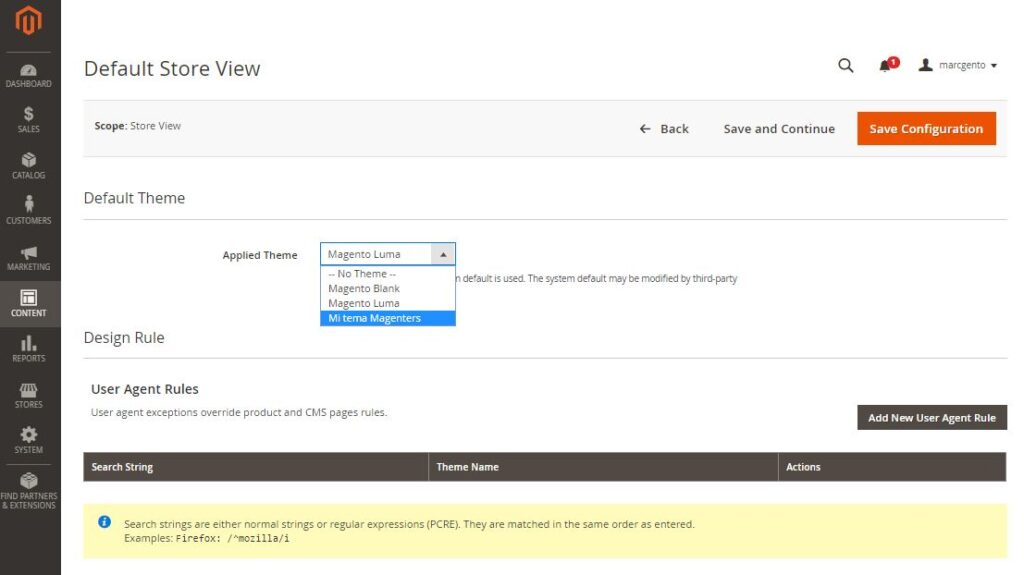
# 摘要
随着电子商务的蓬勃发展,Magento多店铺运营成为电商企业的核心需求。本文全面概述了Magento多店铺运营的关键方面,包括后台管理、技术优化及运营实践技巧。文中详细介绍了店铺设置、商品和订单管理,以及客户服务的优化方法。此外,本文还探讨了性能调优、安全性增强和第三方集成技术,为实现有效运营提供了技术支撑。在运营实践方面,本文阐述了有效的营销
【实战攻略】MATLAB优化单脉冲测角算法与性能提升技巧

# 摘要
本文全面探讨了MATLAB环境下优化单脉冲测角算法的过程、技术及应用。首先介绍了单脉冲测角算法的基础理论,包括测角原理、信号处理和算法实现步骤。其次,文中详细阐述了在MATLAB平台下进行算法性能优化的策略,包括代码加速、并行计算和G
OPA656行业案例揭秘:应用实践与最佳操作规程

# 摘要
本文深入探讨了OPA656行业应用的各个方面,涵盖了从技术基础到实践案例,再到操作规程的制定与实施。通过解析OPA656的核心组件,分析其关键性能指标和优势,本文揭示了OPA656在工业自动化和智慧城市中的具体应用案例。同时,本文还探讨了OPA656在特定场景下的优化策略,包括性能
【二极管热模拟实验操作教程】:实验室中模拟二极管发热的详细步骤

# 摘要
本文通过对二极管热模拟实验基础的研究,详细介绍了实验所需的设备与材料、理论知识、操作流程以及问题排查与解决方法。首先,文中对温度传感器的选择和校准、电源与负载设备的功能及操作进行了说明,接着阐述了二极管的工作原理、PN结结构特性及电流-电压特性曲线分析,以及热效应的物理基础和焦耳效应。文章进一步详述了实验操作的具体步骤,包括设备搭建、二极管的选取和安装、数据采
重命名域控制器:专家揭秘安全流程和必备准备
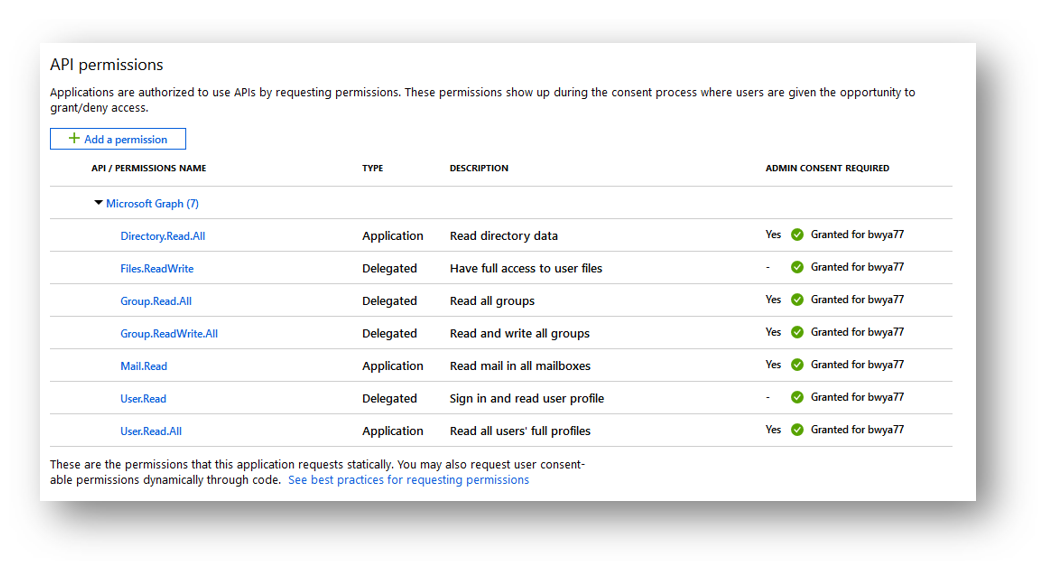
# 摘要
本文深入探讨了域控制器重命名的过程及其对系统环境的影响,阐述了域控制器的工作原理、角色和职责,以及重命名的目的和必要性。文章着重介绍了重命名前的准备工作,包括系统环境评估、备份和恢复策略以及变更管理流程,确保重命名操作的安全性和系统的稳定运行。实践操作部分详细说明了实施步骤和技巧,以及重命名后的监控和调优方法。最后,本文讨论了在重命名域控制器过程中的安全最佳实践和合规性检查,以满足信息安全和监管要求。整体而言,
【精通增量式PID】:参数调整与稳定性的艺术

# 摘要
增量式PID控制器是一种常见的控制系统,以其结构简单、易于调整和较高的控制精度广泛应用于工业过程控制、机器人系统和汽车电子等领域。本文深入探讨了增量式PID控制器的基本原理,详细分析了参数调整的艺术、稳定性分析与优化策略,并通过实际应用案例,展现了其在不同系统中的性能。同时,本文介绍了模糊控制、自适应PID策略和预测控制技术与增量式PID结合的
CarSim参数与控制算法协同:深度探讨与案例分析

# 摘要
本文介绍了CarSim软件的基本概念、参数系统及其与控制算法之间的协同优化方法。首先概述了CarSim软件的特点及参数系统,然后深入探讨了参数调整
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )