【Six库在数据分析中的应用】:解决兼容性问题的策略与技巧
发布时间: 2024-10-13 19:35:14 阅读量: 2 订阅数: 2 

# 1. Six库简介与数据分析基础
## 简介
Six库是一个功能强大的数据处理和分析工具,它提供了一系列用于数据操作、清洗、统计分析和可视化的APIs。作为一个开源项目,Six库受到了广大数据科学家和工程师的喜爱,它不仅可以提高数据分析的效率,还能够帮助解决复杂的数据问题。
## 数据分析基础
在深入探讨Six库的具体应用之前,我们需要了解数据分析的一些基础概念。数据分析是指使用统计学和计算方法对数据进行探索、处理和建模的过程。它通常包括以下几个步骤:
1. 数据清洗:去除数据中的错误和不一致性,确保数据质量。
2. 数据探索:通过统计和可视化手段理解数据的特征和模式。
3. 数据建模:使用机器学习或统计模型对数据进行预测或分类。
了解这些基础知识将有助于我们更好地利用Six库进行数据分析。接下来的章节将详细介绍Six库的数据处理功能,并展示它在实际应用中的强大能力。
# 2. Six库在数据分析中的实践应用
## 2.1 Six库的数据处理功能
### 2.1.1 数据清洗与预处理
在数据分析过程中,数据清洗与预处理是至关重要的一步。Six库提供了丰富的工具和函数,帮助我们高效地完成这一任务。数据清洗的目标是确保数据的质量和准确性,以便进行后续的分析。
#### *.*.*.* 缺失值处理
在数据集中,缺失值是常见的问题。Six库提供了多种处理缺失值的方法,包括删除含有缺失值的行或列,或者使用均值、中位数等统计量填充缺失值。
```python
import six
# 假设df是一个DataFrame,其中包含缺失值
df = six.DataFrame({
'A': [1, None, 3],
'B': [4, 5, None]
})
# 删除含有缺失值的行
df_cleaned = df.dropna()
# 使用均值填充缺失值
df_filled = df.fillna(df.mean())
```
#### *.*.*.* 异常值检测
异常值可能会对数据分析的结果产生负面影响。Six库提供了一些统计方法,如Z-score和IQR(四分位数间距),来帮助识别和处理异常值。
```python
from scipy import stats
# 计算Z-score
z_scores = stats.zscore(df[['A', 'B']])
df['Z_score'] = z_scores
# 使用IQR检测异常值
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
# 定义异常值范围
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 标记异常值
df['Outlier'] = df.apply(lambda x: 'Yes' if (x['A'] < lower_bound['A'] or x['A'] > upper_bound['A'] or x['B'] < lower_bound['B'] or x['B'] > upper_bound['B']) else 'No', axis=1)
```
### 2.1.2 数据统计与描述性分析
描述性分析是数据分析的基础,它帮助我们理解数据的基本特征,如中心趋势、分散程度和分布形状。
#### *.*.*.* 描述性统计
Six库提供了丰富的描述性统计函数,如均值、中位数、方差、标准差等,可以直接应用于数据集。
```python
# 描述性统计
mean_value = df['A'].mean()
median_value = df['A'].median()
variance_value = df['A'].var()
std_deviation = df['A'].std()
```
### 2.1.3 数据可视化技术
数据可视化是分析数据的强大工具,它可以帮助我们更直观地理解数据的分布和趋势。
#### *.*.*.* 常用图表
Six库支持创建多种图表,如散点图、直方图、箱线图等,这些图表可以帮助我们直观地展示数据分布。
```python
import matplotlib.pyplot as plt
import seaborn as sns
# 创建散点图
plt.scatter(df['A'], df['B'])
plt.xlabel('Column A')
plt.ylabel('Column B')
plt.title('Scatter plot of A vs B')
plt.show()
# 创建直方图
sns.histplot(df['A'], kde=True)
plt.xlabel('Column A')
plt.title('Histogram of Column A')
plt.show()
# 创建箱线图
sns.boxplot(x=df['A'])
plt.xlabel('Column A')
plt.title('Boxplot of Column A')
plt.show()
```
## 2.2 Six库在不同场景下的应用案例
### 2.2.1 金融数据分析
在金融领域,Six库可以用于风险评估、市场分析和投资组合优化等多种场景。
#### *.*.*.* 风险评估
金融机构经常使用Six库来进行风险评估,通过计算投资组合的收益率和波动率来评估潜在风险。
```python
# 风险评估
returns = df['Portfolio_Returns']
volatility = df['Portfolio_Volatility']
# 计算年化收益率和波动率
annualized_return = (returns.mean() * 252)**0.5
annualized_volatility = (returns.var() * 252)**0.5
# 输出结果
print(f"Annualized Return: {annualized_return:.2%}")
print(f"Annualized Volatility: {annualized_volatility:.2%}")
```
### 2.2.2 生物信息学分析
生物信息学领域中,Six库可用于基因表达数据分析、蛋白质结构预测等。
#### *.*.*.* 基因表达数据分析
在基因表达数据分析中,Six库可以帮助我们识别差异表达基因,进行聚类分析等。
```python
# 基因表达数据分析
expression_data = six.DataFrame({
'Gene1': [100, 150, 200],
'Gene2': [120, 130, 140],
'Gene3': [110, 160, 190]
})
# 计算均值和标准差
mean_expression = expression_data.mean()
std_expression = expression_data.std()
# 输出结果
print("Mean Expression:")
print(mean_expression)
print("\nStandard Deviation of Expression:")
print(std_expression)
```
## 2.3 Six库的性能优化
### 2.3.1 内存管理技巧
在处理大型数据集时,Six库的内存管理技巧可以显著提高性能。
#### *.*.*.* 内存优化
Six库提供了多种方式来优化内存使用,如使用数据类型转换、减少数据冗余等。
```python
# 使用更高效的数据类型
df['A'] = df['A'].astype('int16')
df['B'] = df['B'].astype('int16')
# 减少数据冗余
df.set_index('A', inplace=True)
```
### 2.3.2 执行效率提升方法
#### *.*.*.* 并行处理
Six库支持并行处理,可以利用多核CPU来加速计算。
```python
from multiprocessing import Pool
def compute_function(x):
# 定义计算函数
return x * x
# 创建进程池
pool = Pool(processes=4)
# 并行计算
results = pool.map(compute_function, df['A'])
# 输出结果
print(results)
```
### 2.3.3 多线程与并行处理
#### *.*.*.* 多线程
Six库提供了多线程处理能力,可以在I/O密集型任务中提高性能。
```python
import threading
def thread_function(x):
# 定义线程函数
print(x)
threads = []
# 创建并启
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**Python Six库专栏简介**
本专栏深入探讨Python Six库,这是一个强大的兼容性库,可帮助您跨不同Python版本无缝运行代码。通过一系列文章,您将了解Six库的隐藏功能、高效使用技巧、性能优化秘诀以及与其他兼容性工具的对比。此外,您还将发现Six库在数据分析、企业级应用中的实际应用,以及获得社区支持和学习资源的指南。最后,本专栏还提供了创建自定义兼容性解决方案的扩展指南,帮助您编写可维护且兼容的代码。
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python开发者必备:cmath库在电磁学计算中的应用】:专家指南
# 1. Python中cmath库的概述
Python中的`cmath`库是专门用于处理复数数学运算的库,它是`math`库的一个补充,提供了复数的算术运算、三角函数、双曲函数等数学运算功能。`cmath`库能够处理复数的标准表示形式,并且支持在复平面上进行各种数学计算,使得Python在处理工程计算和科学计算时更为强大和便捷。本章节将介绍`cmath`库的基本
【Django文件字段与其他系统的集成】:如何与AWS S3等云服务无缝对接的6大步骤
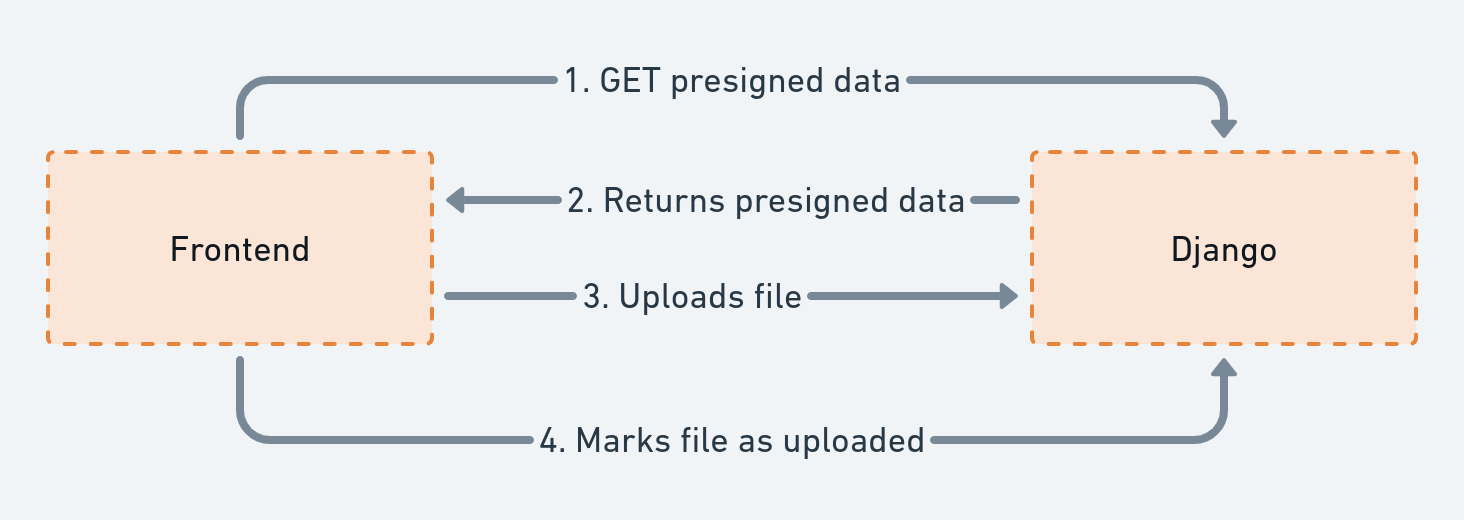
# 1. Django文件字段基础
## 简介
在本章中,我们将深入探讨Django框架中文件字段的基础知识。文件字段是Django模型中的一个特殊字段类型,用于处理文件上传,是构建动态网站和应用程序时不可或缺的一部分。
## 文件字段的基本概念
Django中的文件字段通常通过模型(Models)的`
formsets表单集实例继承:优化表单集结构的专家指南
# 1. formsets表单集的基本概念和原理
## 2.1 formsets表单集的定义和类型
### 2.1.1 formsets表单集的基本定义
formsets是Django框架中用于处理多个表单实例的一个强大工具。它允许开发者在一个页面上动态地添加、删除和编辑多个表单。这种功能在处理具有重复数据集的场景,如表单集合或对象集合时非常有用。
### 2.1.2 formsets表单集的主要类型
Django提供了多种formsets,包括`BaseFormSet`、`ModelFormSet`和`InlineModelFormSet`。`BaseFormSet`是所有formset
【Python时区处理最佳实践】:dateutil.tz在微服务架构中的应用案例
# 1. Python时区处理基础
Python作为一种广泛使用的编程语言,在处理时间和时区方面也拥有强大的库支持。本章节将介绍Python中与时区处理相关的基本概念和方法,为后续深入探讨dateutil.tz库打下基础。
## 1.1 时间和时区的基本概念
时间是连续事件序列的度量,而时区则是地球上根据经度划分的区域,每个区域对
面向服务的架构:twisted.internet.task在大型项目中的运用
# 1. 面向服务的架构与Twisted框架概述
## 1.1 面向服务的架构简介
面向服务的架构(SOA)是一种设计模式,它将应用程序的不同功能单元(称为服务)通过定义良好的接口和协议联系起来。SOA能够提高系统的可维护性、灵活性和可重用性。在SOA中,服务可以独立于应用程序的其余部分进行开发、部署和更新。
## 1.2 Twisted框架与事件驱动编程
Twisted是
【Python JSON编码与解码深度解析】:simplejson.decoder的10个实用技巧
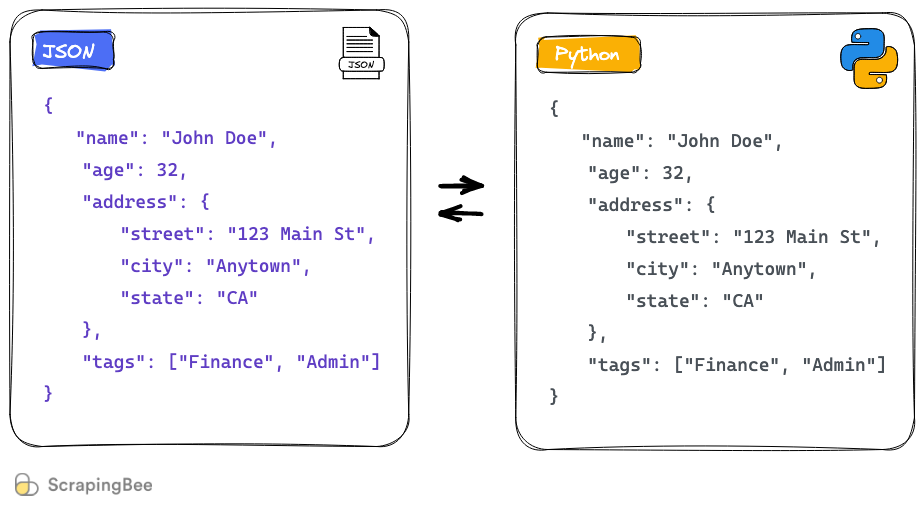
# 1. Python JSON编码与解码基础
## 简介
Python中的JSON处理是现代开发中的一个基本技能。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。Python提供了内置的模块来处理JSON数据,这使得编码和
【深入理解Python Handlers】:揭秘日志处理中的核心角色与功能,提升你的调试技巧
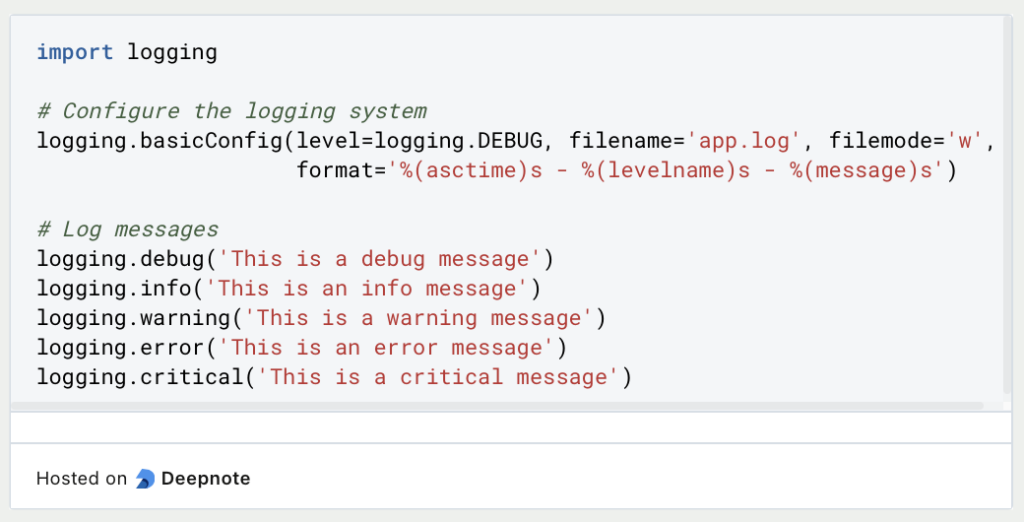
# 1. Python Handlers 概述
Python 的 logging 模块提供了一套灵活而强大的日志管理机制,而 Handlers 在其中扮演着至关重要的角色。Handler 负责将日志消息发送到指定的目的地,无论是控制台、文件,还是网络套接字。理解 Python Handlers 的基本概念和使用方式,对于构建有效的日志记
【colorsys与视频编辑】:视频后期处理中的颜色转换技巧,视频编辑中颜色转换的应用和技巧

# 1. colorsys与视频编辑的基本概念
## 1.1 视频编辑中的颜色空间
在视频编辑领域,颜色空间是理解
SQLAlchemy与MySQL整合:探索不同数据库驱动的特性与限制
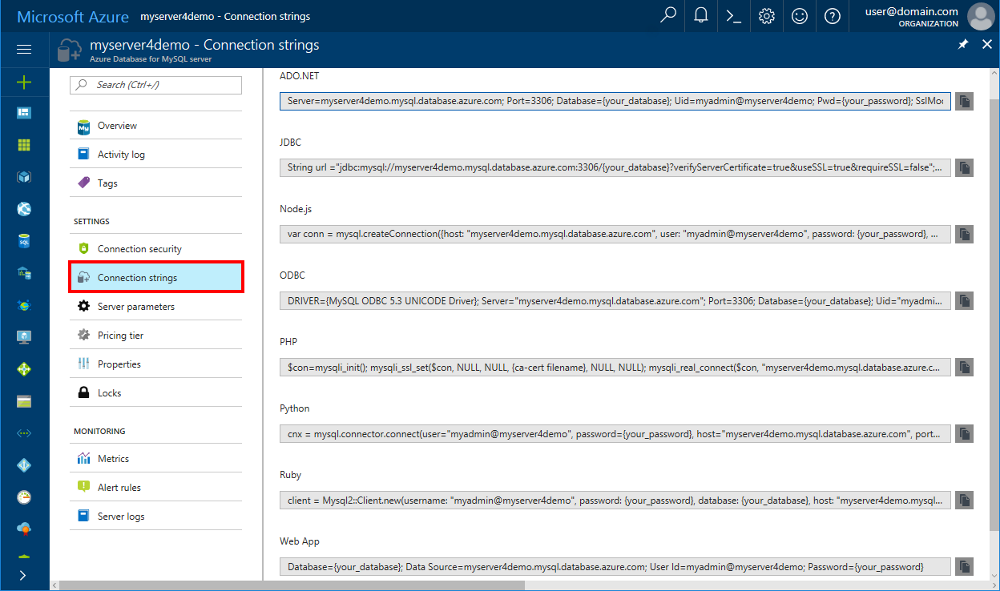
# 1. SQLAlchemy与MySQL整合概述
## 1.1 SQLAlchemy与MySQL整合的意义
在现代的Web开发中,数据库操作是一个不可或缺的环节。SQLAlchemy作为一个强大的数据库工具包,它为Python提供了SQL的抽象层,使得数据库操作更加
【UserString与正则表达式】:高效匹配与替换字符串

# 1. UserString与正则表达式的概述
正则表达式是一种强大的字符串处理工具,广泛应用于文本搜索、匹配和替换等场景。在众多编程语言和工具中,正则表达式都有其身影,其中UserString作为一个特殊的数据结构,提供了对正则表达式操作的封装和优化。
## 1.1 正则表达式的重要性
正则表达式允许开发者以一种简洁的模式匹配复杂或长字符串,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )