【命令执行加速】:5个commands库技巧让你的Python脚本飞起来
发布时间: 2024-10-01 03:27:37 阅读量: 6 订阅数: 7 

# 1. Python命令执行概述
Python作为一种编程语言,其强大的命令行执行能力为开发者提供了极大的便利。从简单的脚本运行到复杂的命令行工具构建,Python命令执行的灵活性和易用性是其在系统管理、自动化和数据分析等领域广泛应用的关键因素之一。
在本章中,我们将首先对Python命令执行的含义和基本概念进行简要介绍。我们会探讨如何通过命令行直接运行Python脚本,以及其背后的工作原理。此外,我们还将涉及一些基本的命令行参数传递和接收机制,为后续章节中介绍的高级技巧和最佳实践打下基础。
一个简单的Python脚本示例可以帮助我们理解Python命令执行的核心概念:
```python
# hello.py
if __name__ == "__main__":
print("Hello, World!")
```
执行上述脚本的命令为:
```sh
python hello.py
```
这个例子虽然简单,但它展示了如何通过Python解释器来执行脚本。本章将逐步揭开这一过程背后的原理,为接下来深入探索如何优化、提高效率、处理错误和记录日志,以及探索高级应用场景奠定坚实的基础。
# 2. 优化Python命令执行的基础技巧
## 2.1 命令行参数解析
### 2.1.1 理解sys.argv的局限性
在Python中,`sys.argv` 是一个列表,它包含了传递给脚本的命令行参数。`sys.argv[0]` 是脚本名称,其余元素是额外传递给脚本的参数。`sys.argv` 的局限性在于它只能进行非常基本的参数解析,不支持选项(如 `-v` 或 `--verbose`),也无法处理参数的默认值、类型转换、帮助信息或错误处理等。
```python
import sys
print("Script name:", sys.argv[0])
print("Arguments:", sys.argv[1:])
```
在这个例子中,如果用户没有提供任何参数,脚本将抛出 `IndexError`。此外,`sys.argv` 不能很好地处理含有空格的参数,因为对于命令行来说,空格是参数分隔符。因此,对于复杂的命令行应用,`sys.argv` 可能不足以应对需求。
### 2.1.2 使用argparse提升命令行处理能力
`argparse` 是Python的标准库之一,用于编写用户友好的命令行接口。通过定义期望的命令行参数,`argparse` 可以自动产生帮助和使用手册,并在用户提供了无效参数时抛出适当的错误。
```python
import argparse
# 创建解析器
parser = argparse.ArgumentParser(description='Process some integers.')
# 添加参数
parser.add_argument('integers', metavar='N', type=int, nargs='+',
help='an integer for the accumulator')
parser.add_argument('--sum', dest='accumulate', action='store_const',
const=sum, default=max,
help='sum the integers (default: find the max)')
# 解析参数
args = parser.parse_args()
print(args.accumulate(args.integers))
```
这个例子中,我们定义了一个整数列表参数 `integers` 和一个可选参数 `--sum`,它改变了 `accumulate` 函数的默认行为。`argparse` 解析 `sys.argv` 中的参数,并将结果存储在 `args` 对象中,这样我们的脚本可以更灵活地处理参数。
## 2.2 选择合适的库进行命令执行
### 2.2.1 标准库subprocess的使用
`subprocess` 模块允许你从Python程序中运行新的程序,并与它们的输入/输出/错误管道连接,获取返回码,以及其它一些特性。这比 `os.system` 和 `os.spawn` 提供了更多的灵活性。
```python
import subprocess
# 启动一个子进程来运行命令
result = subprocess.run(['ls', '-l'], capture_output=True, text=True)
# 捕获输出和错误
print('输出:', result.stdout)
print('错误:', result.stderr)
```
在上面的代码中,`subprocess.run()` 执行了一个 `ls -l` 命令,捕获输出,并将其作为字符串返回。我们还可以检查命令的返回码以了解其退出状态。
### 2.2.2 外部库如Plumbum和Click的介绍
`Plumbum` 和 `Click` 是两个流行的第三方库,它们提供了更高级别的命令行处理功能。`Plumbum` 是一个库,用于编写脚本和命令行工具,它允许以面向对象的方式来创建和执行命令。`Click` 则是一个用于创建命令行界面的装饰器库,它使得编写复杂的命令行工具变得简单。
```python
# 使用Click创建命令行接口
***mand()
@click.argument('filename', type=click.Path(exists=True))
def inspect_file(filename):
"""Inspect a file."""
click.echo(f'Filename is: {filename}')
if __name__ == '__main__':
inspect_file()
```
上面使用 `Click` 的代码片段创建了一个简单命令行工具,它接受一个文件名参数并输出它。这个工具可以有更多复杂的选项和参数,`Click` 会自动处理帮助文本的生成。
使用这些高级库可以大大简化命令行工具的开发,使代码更加模块化和可重用,同时也使得命令行接口更加友好和功能丰富。
# 3. ```
# 第三章:提高Python命令执行效率的方法
## 3.1 利用并发执行命令
### 3.1.1 多线程命令执行
多线程是实现命令并发执行的简单而有效的方式。Python中的`threading`模块提供了基本的线程支持。需要注意的是,由于Python的全局解释器锁(GIL)的存在,对于CPU密集型任务,多线程可能不会带来性能上的显著提升。但对于IO密集型任务,如网络请求或读写操作,多线程可以大幅提升效率,因为IO操作可以释放GIL,让线程在等待IO响应时交替执行。
下面是一个使用Python的`threading`模块来并发执行多个命令的示例代码。
```python
import threading
import subprocess
import time
def execute_command(command):
process = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE)
out, err = ***municate()
print(out.decode())
if __name__ == '__main__':
# 创建线程执行命令列表
thread_list = []
for i in range(5):
command = f"ping -c ***.*.*.* > /dev/null 2>&1"
thread = threading.Thread(target=execute_command, args=(command,))
thread_list.append(thread)
thread.start()
for thread in thread_list:
thread.join()
print("All commands executed!")
```
在这个例子中,我们创建了五个线程来执行`ping`命令。每个线程都
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中的 commands 模块,提供了一系列文章,涵盖从命令行自动化到系统管理等广泛主题。通过专家指导和实用技巧,您将了解如何利用 commands 模块提升开发效率、加速命令执行、简化开发流程、实现系统管理自动化、执行并发命令、打造高效自动化脚本、探索命令行交互新玩法、创建命令执行工具箱、自动化运维任务,以及跨平台执行命令。无论您是 Python 初学者还是经验丰富的开发人员,本专栏都将为您提供宝贵的见解,帮助您充分利用 commands 模块,简化开发流程并提升自动化能力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Redis Python客户端进阶:自定义命令与扩展redis-py功能

# 1. Redis与Python的结合
在现代的软件开发中,Redis与Python的结合应用是构建高效、稳定的应用架构的一个重要方向。Redis,作为一个开源的内存数据结构存储系统,常被用作数据库、缓存和消息代理。Python,作为一种广泛应用于服务器端开发的编程语言,具有简洁易读的语法和丰富的库支持。
## 1.1 Redis与Python的结合
【Pytest与Selenium实战教程】:自动化Web UI测试框架搭建指南
# 1. Pytest与Selenium基础介绍
## 1.1 Pytest介绍
Pytest是一个Python编写的开源测试框架,其特点在于易于上手、可扩展性强,它支持参数化测试用例、插件系统,以及与Selenium的无缝集成,非常适合进行Web自动化测试。它能够处理从简单的单元测试到复杂的集成测试用例,因其简洁的语法和丰富的功能而深受测试工程师的喜爱。
## 1.2 Selenium介绍
Selenium是一个用于Web应用程序测试的
Python开发者看过来:提升Web应用性能的Cookie存储策略

# 1. Web应用性能优化概述
## 1.1 性能优化的重要性
在数字化浪潮中,Web应用已成为企业与用户交互的重要渠道。性能优化不仅提升了用户体验,还直接关联到企业的市场竞争力和经济效益。一个响应速度快、运行流畅的Web应用,可以显著减少用户流失,提高用户满意度,从而增加转化率和收入。
## 1.2 性能优化的多维度
性能优化是一个多维度的过
【Django ORM数据校验守则】:保证数据准确性与合法性的黄金法则

# 1. Django ORM数据校验概论
## 引言
数据校验是构建健壮Web应用的重要环节。Django,作为全栈Web框架,提供了强大的ORM系统,其数据校验机制是保障数据安全性和完整性的基石。本章将对Django ORM数据校验进行概述,为后续深入探讨打下
【多租户架构】:django.core.paginator的应用案例
# 1. 多租户架构的基础知识
多租户架构是云计算服务的基石,它允许多个客户(租户)共享相同的应用实例,同时保持数据隔离。在深入了解django.core.paginator等具体技术实现之前,首先需要掌握多租户架构的核心理念和基础概念。
## 1.1 多租户架构的定义和优势
多租户架
GTK+3中的自定义控件:提升应用交互体验的3大策略

# 1. GTK+3自定义控件概述
## 1.1 GTK+3控件的基础
GTK+3作为一套丰富的GUI开发库,提供了大量预定义的控件供开发者使用。这些控件
Dev-C++ 5.11数据库集成术:在C++中轻松使用SQLite

# 1. SQLite数据库简介与Dev-C++ 5.11环境准备
在这一章节中,我们将首先介绍SQLite这一强大的轻量级数据库管理系统,它以文件形式存储数据,无需单独的服务器进程,非常适用于独立应用程序。接着,我们将讨论在Dev-C++ 5.11这一集成开发环境中准备和使用SQLite数据库所需的基本步骤。
## 1.1 SQLite简介
SQLite是实现了完整SQL数据库引擎的小型数据库,它作为一个库被
C++安全编程手册:防御缓冲区溢出与注入攻击的10大策略

# 1. C++安全编程概述
## 1.1 安全编程的必要性
在C++开发中,安全编程是维护系统稳定性和保障用户信息安全的重要环节。随着技术的发展,攻击者的手段越发高明,因此开发者必须对潜在的安全风险保持高度警惕,并在编写代码时采取相应的防御措施。安全编程涉及识别和解决程序中的安全隐患,防止恶意用户利用这些漏洞进行攻击。
## 1.2 C++中的安全挑战
由于C+
Python异常处理的边界案例:系统信号和中断的处理策略
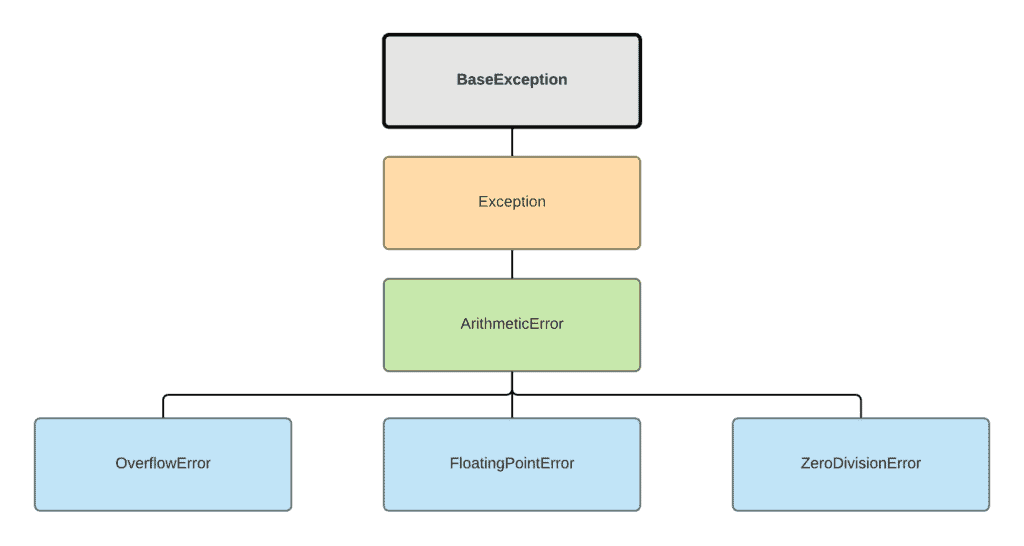
# 1. 异常处理基础知识概述
异常处理是软件开发中保障程序稳定运行的重要手段。本章将介绍异常处理的基础知识,并为读者建立一个扎实的理论基础。我们将从异常的概念入手,探讨其与错误的区别,以及在程序运行过程中异常是如何被引发、捕获和处理的。此外,本章还会简介异常的分类和处理方法,为进一步深入学习异常处理的高级技巧打下基础。
C语言内联函数深度探索:性能提升与注意事项
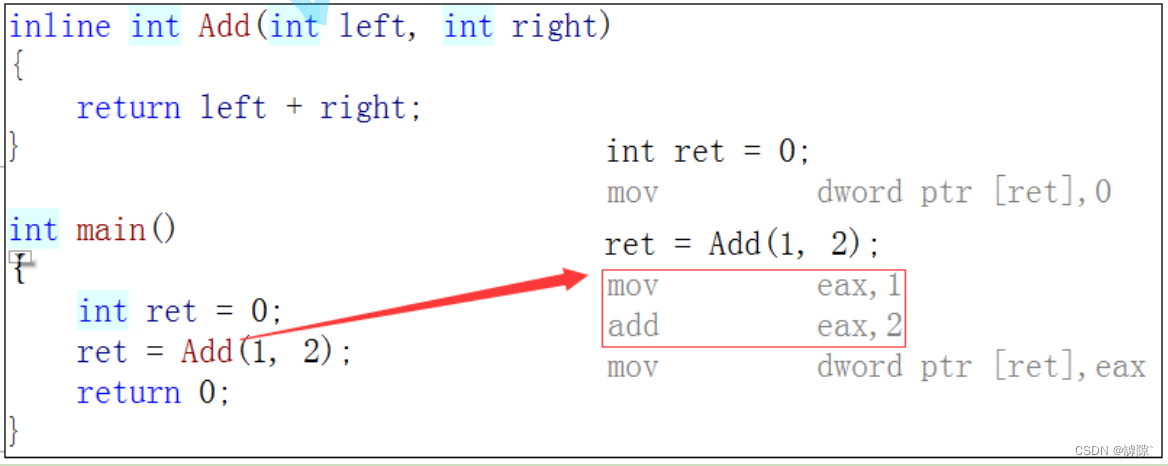
# 1. 内联函数的基础概念与作用
## 1.1 内联函数定义
内联函数是C++语言中一种特殊的函数,它的基本思想是在编译时期将函数的代码直接嵌入到调用它的地方。与常规的函数调用不同,内联函数可以减少函数调用的开销,从而提高程序运行的效率。
## 1.2 内联函数的作用
内联函数在编译后的目标代码中不存在一个单独的函数体,这意味着它可以减少程序运行时的上下文切换,提高执行效率。此外,内联函数的使用可以使得代
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )