【构建高效数据导入导出系统】:POI企业实践揭秘
发布时间: 2024-12-28 10:56:42 阅读量: 7 订阅数: 9 

Springboot+Poi实现Excel的导入导出

# 摘要
数据导入导出系统对于数据密集型应用至关重要,它要求高效、准确地处理大量数据。本文从需求分析开始,逐步深入介绍Apache POI库的基础知识、高级特性、性能优化及在实际应用中的案例。特别强调了POI在Excel和Word文件处理中的读写机制,以及在自动化和扩展性设计上的实现。通过探讨数据导入导出系统的安全性,本文提供了确保数据安全和完整性的策略。最后,本文展望了云服务和大数据技术对数据导入导出的影响,以及持续学习和技术创新的重要性。
# 关键字
数据导入导出;Apache POI;性能优化;安全性分析;自动化脚本;可扩展性设计;云服务;大数据;技术创新
参考资源链接:[POI深入指南:创建Excel对象与操作详解](https://wenku.csdn.net/doc/64812ac6d12cbe7ec35f9f53?spm=1055.2635.3001.10343)
# 1. 数据导入导出系统的重要性与需求分析
## 1.1 数据导入导出系统概述
在信息时代,数据处理是企业运营和决策的核心。数据导入导出系统作为一种工具,能够实现数据在不同格式和平台之间的高效转换。它不仅优化了数据流转流程,还减少了因手动操作导致的错误和时间成本。
## 1.2 重要性分析
数据导入导出系统对于企业来说至关重要,原因有三:
1. 效率提升:自动化的数据处理避免了繁琐的手动操作,提高了工作效率。
2. 准确性增强:减少了人为错误,确保数据导入导出过程中的准确性。
3. 业务灵活性:支持多源数据整合,为数据分析和报告生成提供灵活性。
## 1.3 需求分析
对于构建数据导入导出系统,以下是关键需求:
1. 兼容性:支持常见的数据格式,如CSV、Excel、Word等。
2. 可靠性:保证数据在导入导出过程中的完整性和一致性。
3. 性能:高效处理大量数据,同时保证系统稳定运行。
4. 扩展性:系统应具备良好的模块化设计,易于扩展和维护。
数据导入导出系统在今天的信息处理领域中扮演着至关重要的角色,它不仅满足了快速、准确处理数据的需求,还在企业管理和决策支持中发挥着不可替代的作用。下一章节我们将深入探讨Apache POI库,它是Java环境下处理Microsoft Office文档的重要工具。
# 2. Apache POI库基础
## 2.1 Apache POI概述
### 2.1.1 POI项目介绍
Apache POI是Apache Software Foundation提供的一个Java库,用于读取和写入Microsoft Office格式的文件。它支持Microsoft Office 97-2008格式,包括HSSF(用于Excel文件,后缀名.xls),XSSF(用于Excel文件,后缀名.xlsx),HWPF(用于Word文件,后缀名.doc),以及HSLF(用于PowerPoint文件)等。
POI项目主要基于Microsoft的官方文件格式文档,确保生成的文件可以被Office应用程序识别。此外,Apache POI也支持读写压缩的Excel文件以及加密的Word文档。
### 2.1.2 POI在数据导入导出中的作用
Apache POI为开发者提供了方便的API来处理Microsoft Office文件,这在数据导入导出系统中至关重要。它可以用来导入数据到Excel或Word模板,也可以从这些模板导出数据,广泛应用于报表生成、数据验证和各种自动化办公处理。
使用Apache POI,开发者可以:
- 读取Excel和Word文件中的数据,以便进一步分析或处理。
- 编辑现有Excel和Word文件,如更新报表、修改文档等。
- 创建全新的Excel和Word文档,自动化生成各种格式的报表。
## 2.2 POI库中的Excel处理
### 2.2.1 Excel文件的读取
Apache POI通过HSSFSheet类提供了读取Excel文件的功能。使用这个类,开发者可以遍历单元格(Cell),获取它们的值,并处理这些值。以下是一个简单的示例,演示了如何读取Excel文件的单元格数据:
```java
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.File;
import java.io.FileInputStream;
public class ExcelReader {
public static void main(String[] args) throws Exception {
FileInputStream excelFile = new FileInputStream(new File("example.xlsx"));
Workbook workbook = new XSSFWorkbook(excelFile);
Sheet sheet = workbook.getSheetAt(0);
for (Row row : sheet) {
for (Cell cell : row) {
// 根据单元格类型获取数据
switch (cell.getCellType()) {
case STRING:
System.out.print(cell.getStringCellValue() + "\t");
break;
case NUMERIC:
System.out.print(cell.getNumericCellValue() + "\t");
break;
case BOOLEAN:
System.out.print(cell.getBooleanCellValue() + "\t");
break;
// 处理其他单元格类型...
}
}
System.out.println();
}
workbook.close();
}
}
```
### 2.2.2 Excel文件的写入
Apache POI同样提供强大的API用于创建和修改Excel文件。创建一个新的Excel文件,通常包括创建工作簿(Workbook)、工作表(Sheet)、行(Row)和单元格(Cell)对象,然后设置单元格的值和格式。以下是一个简单的示例,演示了如何创建一个新的Excel文件:
```java
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
public class ExcelWriter {
public static void main(String[] args) throws Exception {
Workbook workbook = new XSSFWorkbook();
Sheet sheet = workbook.createSheet("Example Sheet");
Row row = sheet.createRow(0);
Cell cell = row.createCell(0);
cell.setCellValue("Hello, World!");
try (FileOutputStream outputStream = new FileOutputStream("example.xlsx")) {
workbook.write(outputStream);
}
workbook.close();
}
}
```
## 2.3 POI库中的Word处理
### 2.3.1 Word文档的读取
Apache POI通过HWPFDocument类提供了读取Word文档的功能。开发者可以打开Word文件,遍历其中的段落(Paragraph)和范围(Range),读取文本内容。以下是一个简单的示例,演示了如何读取Word文档的内容:
```java
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.usermodel.Para;
import java.io.FileInputStream;
public class WordReader {
public static void main(String[] args) throws Exception {
FileInputStream fileIn = new FileInputStream("example.doc");
HWPFDocument document = new HWPFDocument(fileIn);
Range range = document.getRange();
for (Para para : range.getParagraphs()) {
System.out.println(para.text());
}
fileIn.close();
}
}
```
### 2.3.2 Word文档的写入
Apache POI同样提供了用于创建和修改Word文档的API。创建一个新的Word文档包括创建HWPFDocument对象和Paragraph对象,然后添加文本内容。以下是一个简单的示例,演示了如何创建一个新的Word文档:
```java
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.usermodel.Paragraph;
import org.apache.poi.hwpf.usermodel.Range;
import java.io.FileOutputStream;
public class WordWriter {
public static void main(String[] args) throws Exception {
HWPFDocument document = new HWPFDocument();
Range range = document.getRange();
Paragraph para = range.appendParagraph();
para.setParagraphFormat(document.createParagraphFormat());
para.setParagraphFormat().setAlignment(1); // 段落居中对齐
para.appendText("This is a test paragraph.");
try (FileOutputStream out = new FileOutputStream("example.doc")) {
document.write(out);
}
document.close();
}
}
```
Apache POI库为处理Excel和Word文件提供了强大的支持,简化了数据导入导出系统中的文件处理工作。无论是在数据读取和写入操作中,还是在自动化处理和数据格式转换场景下,Apache POI都能够提供灵活和高效的解决方案。通过本章节内容的介绍,可以为读者提供一个深入理解Apache POI库的基础,为后续章节的高级特性和实际应用案例打下坚实的基础。
# 3. Apache POI的高级特性与优化
在掌握了Apache POI库基础之后,本章节将深入探讨POI的高级特性与优化策略。我们将介绍性能优化、模板与样式应用以及错误处理和兼容性问题。通过高级特性的学习与优化的实施,可以显著提高应用程序在数据导入导出方面的效率和可靠性。
## 3.1 POI的性能优化策略
### 3.1.1 内存管理与优化
Apache POI处理大型文件时,内存消耗是一个关键问题。内存优化不仅包括减少内存的使用,还包括提高内存的使用效率。
**代码示例:**
```java
// 读取Excel文件时,避免一次性加载整个文件到内存中
SXSSFWorkbook workbook = new SXSSFWorkbook(new SXSSFSheetFactory(), 100); // 限制行的缓存数量
```
**参数说明:**
`SXSSFWorkbook` 是一个低内存消耗的版本,它适用于处理大量行的Excel文件。构造函数中的参数 `100` 指定了内存中保持的行数,超出部分的行会被转移到临时文件中。
**逻辑分析:**
在处理大型Excel文件时,为了避免内存溢出异常,应使用 `SXSSFWorkbook` 替代传统的 `HSSFWorkbook`。此外,合理设置行缓存的数量能够有效控制内存的使用。在写入文件时,也应分批次写入,而不是一次性写入全部数据。
### 3.1.2 文件流处理优化
文件流的处理涉及到数据的读写效率。合理管理文件流,可以在处理文件时减少I/O操作的开销。
**代码示例:**
```java
try (FileInputStream fis = new FileInputStream("example.xlsx")) {
Workbook workbook = WorkbookFactory.create(fis);
// 进行文件读写操作
} catch (IOException e) {
e.printStackTrace();
}
```
**参数说明:**
`FileInputStream` 用于打开文件流,`WorkbookFactory.create` 用于从文件流中创建工作簿。
**逻辑分析:**
通过使用try-with-resources语句,可以确保文件流在读写完成后自动关闭,这有助于释放系统资源。此外,在写入大型文件时,应考虑使用输出流的缓冲机制,以减少磁盘I/O操作的次数。
## 3.2 POI的模板与样式应用
### 3.2.1 Excel模板的应用与生成
在数据导入导出中,使用模板可以简化数据处理流程,提高数据处理的效率。
**代码示例:**
```java
// 加载一个Excel模板
FileInputStream templateStream = new FileInputStream("template.xlsx");
Workbook templateWorkbook = WorkbookFactory.create(templateStream);
Sheet sheet = templateWorkbook.getSheetAt(0);
// 在模板上填充数据
Row row = sheet.getRow(1); // 获取第二行
Cell cell = row.getCell(0); // 获取第一列
cell.setCellValue("填充的数据");
// 保存填充后的文件
try (FileOutputStream outputStream = new FileOutputStream("filled_template.xlsx")) {
templateWorkbook.write(outputStream);
}
```
**逻辑分析:**
在该代码段中,我们首先打开一个名为 `template.xlsx` 的Excel模板文件,并获取了其中的第一张表单。然后,在第二行第一列的单元格中填充了字符串“填充的数据”。最后,将修改后的工作簿保存为 `filled_template.xlsx`。使用模板可以重复利用表单结构,减少重复布局的工作。
### 3.2.2 Word样式模板的应用
在处理Word文档时,模板同样可以提高效率,特别是对于结构和格式相同的文档。
**代码示例:**
```java
// 加载一个Word模板
XWPFDocument templateDocument = new XWPFDocument(new FileInputStream("template.docx"));
XWPFParagraph paragraph = templateDocument.getParagraphArray(0).clone(); // 克隆第一段作为新段落
// 添加新的段落
paragraph.setAlignment(ParagraphAlignment.CENTER); // 设置段落居中
paragraph.setSpacingAfter(120); // 设置段落间距
paragraph.setIndentationFirstLine(720); // 设置首行缩进
// 向段落中添加文本
XWPFRun run = paragraph.createRun();
run.setText("这是添加的文本内容");
// 保存填充后的文件
try (FileOutputStream outputStream = new FileOutputStream("filled_template.docx")) {
templateDocument.write(outputStream);
}
```
**逻辑分析:**
代码首先打开一个名为 `template.docx` 的Word模板文件,然后克隆了模板中的第一段,并在该段落中添加了新的文本内容。最后,将修改后的文档保存为 `filled_template.docx`。在处理大型文档时,合理地使用模板和样式可以显著提高操作的效率。
## 3.3 POI的错误处理与兼容性
### 3.3.1 常见错误分析与处理
在使用POI处理数据时,常见的错误包括文件格式错误、读写异常等。正确地处理这些错误对于提高系统的稳定性至关重要。
**代码示例:**
```java
try {
FileInputStream fis = new FileInputStream("invalid_file.xlsx");
Workbook workbook = WorkbookFactory.create(fis);
} catch (InvalidFormatException e) {
System.out.println("文件格式错误");
} catch (IOException e) {
System.out.println("文件读写错误");
}
```
**逻辑分析:**
在尝试打开一个名为 `invalid_file.xlsx` 的文件时,我们可能会遇到格式错误或I/O错误。通过捕获这些异常,我们可以给出明确的错误提示,并采取相应的措施来处理这些异常情况,从而提高应用程序的健壮性。
### 3.3.2 文件格式兼容性问题
由于Excel和Word格式的不同版本之间存在一定的差异,处理这些格式的兼容性是一个挑战。
**表格展示:**
| 格式版本 | Excel 2007/2010 | Excel 2013/2016 |
|---------|-----------------|-----------------|
| 扩展名 | .xlsx | .xlsx |
| 默认样式 | Office Open XML | Office Open XML |
| 兼容性 | 兼容高版本 | 高版本兼容 |
表格展示了Excel文件的两种主流格式的扩展名、默认样式以及与不同版本Excel的兼容性情况。了解这些差异有助于处理不同版本文件时可能出现的兼容性问题。
**逻辑分析:**
在使用POI处理不同版本的Excel文件时,需要考虑到不同的文件格式可能带来的兼容性问题。例如,较新版本的Excel可能包含一些老版本无法识别的功能或格式。为了解决这个问题,POI提供了一些兼容性工具类,比如 `XSSFCompatibilityHelper`,可以用来处理这些问题。
在本章中,我们深入探讨了Apache POI库的高级特性和优化策略。从性能优化到模板和样式应用,再到错误处理与兼容性问题,每一个部分都是确保数据导入导出系统高效稳定运行的关键。通过合理地应用这些高级特性,开发者可以构建出更加健壮、高效的系统。在下一章节中,我们将通过实际应用案例,进一步加深对数据导入导出系统的理解。
# 4. 数据导入导出系统的实际应用案例
数据导入导出系统在实际应用中,是IT运维、数据分析、业务报告生成等环节不可或缺的一环。本章节将通过具体的案例,展示如何利用Apache POI库实现数据的有效导入与导出,同时对于系统的安全性进行分析。
## 4.1 数据导入功能实现
数据导入功能,特别是从不同格式源文件导入数据至Excel或Word文档中,是办公自动化与数据分析中的重要环节。Apache POI通过提供的API使得这一过程变得简单高效。
### 4.1.1 从CSV导入数据到Excel
CSV文件因其格式简单、兼容性好而广泛被使用。通过Apache POI库,我们可以快速将CSV文件中的数据导入到Excel文件中,从而进行进一步的处理和分析。下面是一个简单的代码示例,展示如何从CSV文件读取数据并写入Excel文件:
```java
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.stream.Stream;
public class CSVtoExcel {
public static void main(String[] args) {
String csvFilePath = "path/to/input.csv"; // CSV文件路径
String excelFilePath = "path/to/output.xlsx"; // Excel文件路径
// 使用BufferedReader读取CSV文件
try (BufferedReader br = Files.newBufferedReader(Paths.get(csvFilePath), StandardCharsets.UTF_8)) {
// 创建一个新的Excel文件
Workbook workbook = new XSSFWorkbook();
Sheet sheet = workbook.createSheet("Sheet1");
// 读取CSV文件并逐行处理
Stream<String> stream = Files.lines(Paths.get(csvFilePath), StandardCharsets.UTF_8);
stream.forEach(rowStr -> {
String[] rowArr = rowStr.split(",");
Row row = sheet.createRow(sheet.getLastRowNum() + 1);
for (int i = 0; i < rowArr.length; i++) {
row.createCell(i).setCellValue(rowArr[i]);
}
});
stream.close();
// 将数据写入到Excel文件中
try (FileOutputStream outputStream = new FileOutputStream(excelFilePath)) {
workbook.write(outputStream);
workbook.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
### 4.1.2 实现复杂数据的批量导入
在实际应用中,常常需要处理各种复杂的表格数据,Apache POI提供的丰富API可以满足各种需求。以下是一个处理复杂数据批量导入的例子,其中涉及到日期、数字格式以及表头的处理。
```java
// 代码省略...
// 示例中需要处理日期格式和数字格式,Apache POI提供了强大的CellStyle功能来定制单元格的显示样式
// 以下是创建数字格式样式的一个例子:
CreationHelper createHelper = workbook.getCreationHelper();
CellStyle dateStyle = workbook.createCellStyle();
dateStyle.setDataFormat(createHelper.createDataFormat().getFormat("m/d/yy"));
CellStyle numberStyle = workbook.createCellStyle();
numberStyle.setDataFormat(createHelper.createDataFormat().getFormat("#,##0.00"));
// 示例中需要处理表头,例如设置字体加粗、居中显示等
CellStyle headerStyle = workbook.createCellStyle();
Font headerFont = workbook.createFont();
headerFont.setBold(true);
headerStyle.setFont(headerFont);
headerStyle.setAlignment(HorizontalAlignment.CENTER);
```
上述代码展示了从CSV导入数据到Excel的基础逻辑,包括流式处理、行数据处理以及写入Excel文件的过程。在实际应用中,您可能还需要添加错误处理、数据校验以及对特殊格式的处理(例如日期和数字),这些都是确保数据导入准确性的重要步骤。
## 4.2 数据导出功能实现
数据导出功能是将系统中整理好的数据导出为用户可读或可编辑的文件,例如Excel或Word文档。Apache POI提供了丰富的API来实现这一需求。
### 4.2.1 从数据库导出数据到Excel
从数据库导出数据到Excel是一个常见需求,可以通过Apache POI结合JDBC来实现。以下是一个简单的例子,展示如何从MySQL数据库导出数据到Excel文件中:
```java
// 代码省略...
// 示例中需要从数据库获取数据,可以通过JDBC API实现
String query = "SELECT * FROM your_table";
try (Connection conn = DriverManager.getConnection("jdbc:mysql://your_host:port/dbname", "username", "password");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(query)) {
// 从数据库获取数据
while (rs.next()) {
// 处理数据,例如绑定到特定对象或直接操作行与列
// ...
}
// 创建Excel文件和sheet
Workbook workbook = new HSSFWorkbook(); // 或者使用XSSFWorkbook
Sheet sheet = workbook.createSheet("Sheet1");
// 将数据写入Excel,逻辑类似于CSV到Excel的过程
// ...
// 写入到文件输出流中
// ...
} catch (SQLException e) {
e.printStackTrace();
}
```
### 4.2.2 生成报告并导出为Word文档
有时候数据的输出形式不仅仅是表格,例如,生成的报告文档需要有格式的排版和样式,这时可以使用Apache POI的XWPF(XML Word Processor Format)来处理Word文档。
```java
// 代码省略...
// 创建Word文档和段落
XWPFDocument document = new XWPFDocument();
XWPFParagraph title = document.createParagraph();
XWPFRun titleRun = title.createRun();
titleRun.setText("报告标题");
titleRun.setBold(true);
titleRun.setFontSize(22);
// 添加表格到Word文档
XWPFTable table = document.createTable(3, 3);
table.getRow(0).getCell(0).setText("列1");
// ...
// 设置段落样式
XWPFParagraph paragraph = document.createParagraph();
XWPFRun run = paragraph.createRun();
run.setText("这里是报告的内容...");
run.setFontSize(16);
// ...
// 写入到文件输出流中
// ...
```
在生成报告时,您可能还需要设置页边距、页眉页脚、页码、分页符、图片插入等多种复杂操作,Apache POI提供了丰富的API支持这些操作,从而满足您生成具有专业外观的报告文档的需求。
## 4.3 数据导入导出系统的安全性分析
数据导入导出系统是数据交互的重要环节,因此安全性的考量是不可或缺的。数据泄露和数据损坏的风险需要通过相应的技术和管理措施来降低。
### 4.3.1 防止数据泄露的措施
数据泄露是一个重要的安全问题,特别是在处理敏感数据时。为了防止数据泄露,可以采取以下措施:
- **使用加密技术:** 对于敏感数据,应该在存储和传输过程中使用加密技术,例如SSL/TLS、AES加密。
- **权限控制:** 严格控制数据访问权限,确保只有授权的用户才能访问特定的数据。
- **审计日志:** 记录所有数据访问和操作的日志,以便在发生问题时可以进行追踪。
### 4.3.2 数据校验与完整性控制
保证数据导入导出的准确性,是数据完整性的基础。以下是一些基本的数据校验和完整性控制策略:
- **数据格式校验:** 在数据导入时,对数据格式进行校验,如日期、金额、电话号码等数据格式。
- **数据范围校验:** 检查数据是否在合理的范围内,例如年龄、分数等。
- **数据关联校验:** 核对数据之间的关联性,如身份证号码与姓名是否一致,账户余额与交易记录是否相符。
- **数据完整性检查:** 在数据导出后,检查文件的完整性,比如文件的MD5校验值。
以上通过案例分析了数据导入导出系统的实现方法,并探讨了系统安全性的相关问题。在下一章节中,我们将进一步探讨如何实现数据导入导出系统的自动化以及如何设计具有高度扩展性的系统架构。
# 5. 数据导入导出系统的自动化与扩展性
随着企业数据量的不断增长,自动化和扩展性成为了数据处理系统设计的核心考量。本章节将介绍如何使用自动化脚本提升数据处理效率,并讨论如何设计一个具有良好扩展性的数据导入导出系统。
## 5.1 自动化脚本在数据处理中的应用
自动化脚本可以显著提高重复性任务的处理速度,减少人为错误,并确保数据处理流程的标准化和一致性。本节将探讨如何将Shell脚本与Apache POI库结合,实现数据处理任务的自动化。
### 5.1.1 Shell脚本与POI结合自动化任务
使用Shell脚本自动化处理Excel文件,可以将日常操作转换为脚本命令,通过命令行快速执行。下面是一个简单的Shell脚本示例,用于读取一个Excel文件,并打印出文件中的每个单元格内容。
```bash
#!/bin/bash
# Shell脚本文件:excel_reader.sh
# 引入POI的shell库,这里假设已经配置了poi.sh及其依赖
# source poi.sh
# 指定Excel文件路径
FILE_PATH="path/to/your/excel/file.xlsx"
# 读取Excel文件并逐个单元格输出
# 使用poi.sh中的函数来处理Excel文件
for i in $(poi_list_cells "$FILE_PATH")
do
echo "Cell: $i Value: $(poi_get_cell_value "$FILE_PATH" $i)"
done
```
**代码逻辑解读分析:**
- `#!/bin/bash`:声明这个脚本应该用Bash来执行。
- `source poi.sh`:加载Apache POI的shell库文件。需要确保`poi.sh`脚本及其依赖已经正确配置在系统中。
- `FILE_PATH`:指定要读取的Excel文件路径。
- `poi_list_cells`:调用POI提供的函数列出Excel文件的所有单元格。
- `poi_get_cell_value`:调用POI提供的函数获取指定单元格的值。
使用此脚本时,只需在命令行中运行`./excel_reader.sh`,即可自动化完成Excel数据的读取任务。
### 5.1.2 定时任务的设置与执行
Shell脚本可以与操作系统的定时任务调度器结合,例如Linux的cron工具。通过设置定时任务,可以周期性地执行数据导入导出操作。以下是一个设置cron定时任务的示例:
```bash
# 打开cron任务列表
crontab -e
# 添加以下行以每天凌晨1点执行脚本
0 1 * * * /path/to/your/excel_reader.sh >> /path/to/your/logfile.log 2>&1
```
**代码逻辑解读分析:**
- `crontab -e`:编辑当前用户的cron任务列表。
- `0 1 * * *`:设置任务的执行时间,这里表示每天凌晨1点执行。
- `/path/to/your/excel_reader.sh`:指定要执行的脚本路径。
- `>> /path/to/your/logfile.log 2>&1`:将脚本执行的日志输出到指定的日志文件中。
通过这种方式,可以将数据处理任务自动化,并减少人工干预,提高系统的整体效率和可靠性。
## 5.2 系统的可扩展性设计
良好的系统设计应该考虑未来可能的变更和扩展。本节将探讨如何通过设计模式和模块化设计来增强系统的可扩展性。
### 5.2.1 设计模式在数据导入导出中的应用
设计模式提供了一种解决特定问题的通用框架,有助于实现代码的解耦和重用。例如,策略模式允许在运行时选择不同的算法实现,对于数据处理来说非常有用。
假设我们有一个数据导出任务,需要支持多种文件格式的导出(如CSV、Excel、PDF等),可以使用策略模式来实现这一功能。
```java
public interface ExportStrategy {
void export(List<String> data);
}
public class CSVExportStrategy implements ExportStrategy {
@Override
public void export(List<String> data) {
// CSV导出逻辑
}
}
public class ExcelExportStrategy implements ExportStrategy {
@Override
public void export(List<String> data) {
// Excel导出逻辑
}
}
// 使用策略模式
ExportStrategy strategy = new CSVExportStrategy();
List<String> data = getDataFromSomewhere();
strategy.export(data);
```
**代码逻辑解读分析:**
- `ExportStrategy`:定义了一个导出策略的接口,其中包含`export`方法。
- `CSVExportStrategy`和`ExcelExportStrategy`:分别实现了`ExportStrategy`接口,代表不同的导出策略。
- 在使用策略模式时,可以根据需要动态切换导出策略,而无需修改现有的业务逻辑代码。
### 5.2.2 系统模块化设计思路
模块化设计允许将系统分解为独立的、可替换的模块,每个模块负责一组特定的逻辑。这种设计方式不仅有助于提高代码的可维护性,还有利于独立开发和测试。
以下是一个简化的模块化设计思路示例,展示了如何将数据导入导出系统分解为模块:
```
DataImportExportSystem
├── ImportModule
│ ├── CSVImporter
│ ├── ExcelImporter
│ └── DatabaseImporter
├── ExportModule
│ ├── CSVExporter
│ ├── ExcelExporter
│ └── WordExporter
├── DataProcessor
└── FileFormatConverter
```
在这个结构中:
- `ImportModule`:负责不同格式数据的导入功能。
- `ExportModule`:负责不同格式数据的导出功能。
- `DataProcessor`:处理数据的转换和处理逻辑。
- `FileFormatConverter`:负责不同文件格式之间的转换逻辑。
模块之间通过定义良好的接口进行通信,确保系统的各个部分可以独立更新和扩展,而不会影响整个系统的稳定性和功能。
通过模块化设计,数据导入导出系统能够更好地应对未来的变更需求,同时也便于团队协作和代码维护。
# 6. 未来趋势与技术展望
随着技术的不断进步,数据导入导出系统也在不断地演进以适应新的挑战。在这一章,我们将探讨未来云服务与大数据环境下的数据导入导出技术,以及持续学习与技术创新的重要性。
## 6.1 云服务与大数据环境下的数据导入导出
### 6.1.1 云存储服务的数据处理
在云服务的大背景下,数据的存储与处理方式发生了变化。云存储服务如Amazon S3、Google Cloud Storage和Azure Blob Storage提供了弹性、可扩展的存储解决方案。POI虽然主要用于本地文件处理,但通过一些技巧也能与云服务整合。
例如,可以将POI与云存储API结合使用,先将文件下载到本地再进行处理,或者直接在内存中处理然后上传到云存储。以下是一个使用Java代码示例,展示如何使用Amazon S3 API下载一个文件进行处理后上传:
```java
// 假设bucketName和objectKey是存储在S3上的文件的桶名和对象键
String bucketName = "example-bucket";
String objectKey = "example-file.xlsx";
// 下载文件到本地临时路径
AmazonS3 s3Client = AmazonS3ClientBuilder.standard().build();
S3Object s3Object = s3Client.getObject(new GetObjectRequest(bucketName, objectKey));
File downloadFile = File.createTempFile("download", ".xlsx");
s3Object.getObjectContent().transferTo(Files.newOutputStream(downloadFile.toPath()));
// 使用Apache POI读取Excel文件
InputStream excelFile = new FileInputStream(downloadFile);
Workbook workbook = WorkbookFactory.create(excelFile);
// ... 对workbook进行处理
// 将处理后的文件上传到S3
FileOutputStream outputStream = new FileOutputStream(downloadFile);
workbook.write(outputStream);
s3Client.putObject(new PutObjectRequest(bucketName, "processed-" + objectKey, downloadFile));
// 关闭资源
s3Object.getObjectContent().close();
outputStream.close();
workbook.close();
```
### 6.1.2 大数据框架与数据导入导出的整合
大数据框架如Apache Hadoop和Apache Spark提供了处理大规模数据集的能力。整合这些框架与数据导入导出系统,可以有效地处理与分析数据。Apache Spark提供了一个与Hadoop类似的文件系统抽象,但它对数据处理进行了优化,比如它的RDDs和DataFrames,允许更高效的数据处理和转换。
POI可以用于读取和写入HDFS上的文件,但可能需要针对大数据场景做适当的扩展或优化。例如,使用Apache Spark处理数据时,我们可以将文件读入DataFrame,进行必要的数据处理后,再将结果导出到新的文件中。
## 6.2 持续学习与技术创新
### 6.2.1 POI社区的新功能跟进
Apache POI社区不断有新的功能发布,如改进的内存管理、更高效的文件格式处理能力等。作为一名IT从业者,持续关注POI社区的发展和新发布,对于提高数据处理的效率和质量至关重要。可以通过参与社区讨论、阅读官方文档更新、使用新版本API来跟上技术的发展。
### 6.2.2 探索新的技术栈以满足更复杂的数据需求
尽管POI是一个非常强大的库,但随着业务需求的增加,我们可能需要探索其他的解决方案或技术栈来满足复杂的数据需求。比如,使用Node.js的exceljs库处理Excel文件,或者使用python的pandas库进行数据分析等。了解和掌握这些技术可以为数据处理提供更多的灵活性和能力。
接下来的章节将进一步探讨如何将这些新技术与现有的技术栈整合,以及如何对数据导入导出系统进行持续优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
POI详细教程(中文版)专栏提供了全面的POI操作指南,涵盖从基础入门到性能优化、企业实践、动态报表生成、大数据处理、表格美化、开发实战、批量创建、Web集成、移动端应用、图表制作、高级功能等各个方面。专栏旨在帮助开发者掌握POI的各种功能,提高Excel操作效率,构建高效的数据导入导出系统,并解决大数据时代下的POI挑战。通过深入浅出的讲解和丰富的实践案例,专栏为开发者提供了全方位的POI操作知识和最佳实践,帮助他们提升开发能力,应对各种Excel操作需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ANSYS单元生死应用实战手册】:仿真分析中单元生死技术的高级运用技巧
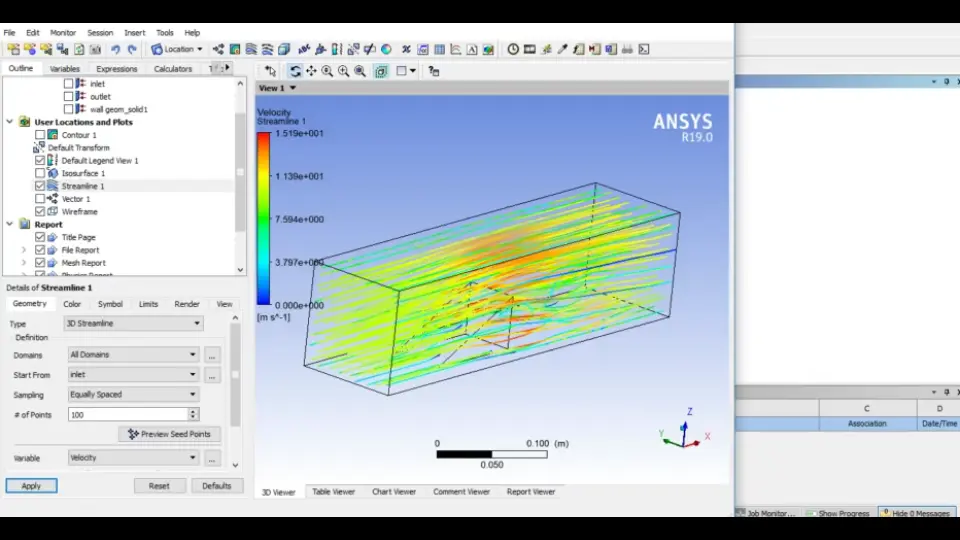
# 摘要
ANSYS单元生死技术是结构仿真、热分析和流体动力学领域中一种强大的分析工具,它允许在模拟过程中动态地激活或删除单元,以模拟材料的添加和移除、热传递或流体域变化等现象。本文首先概述了单元生死技术的基本概念及其在ANSYS中的功能实现,随后深入探讨了该技术在结构仿真中的应用,尤其是在模拟非线性问题时的策略和影响。进
HTML到PDF转换工具对比:效率与适用场景深度解析
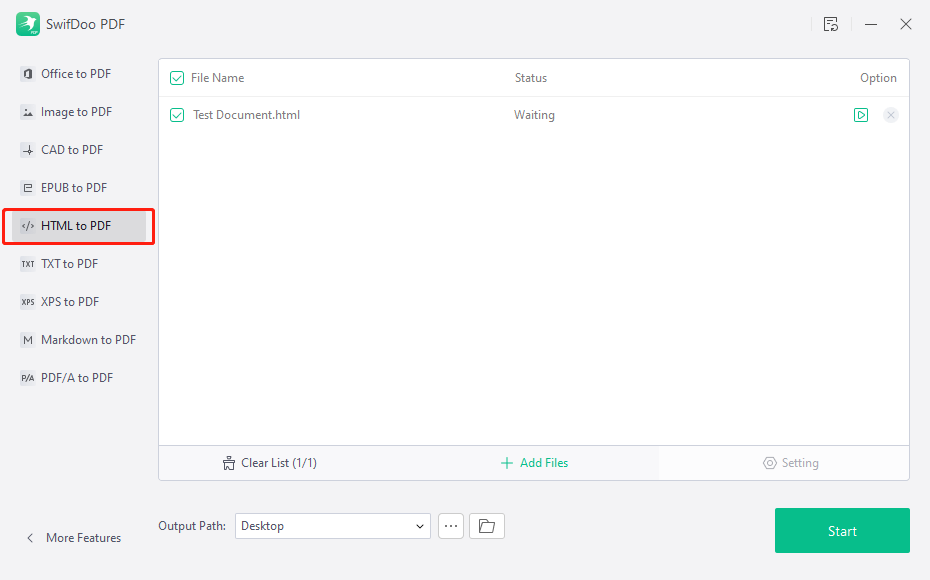
# 摘要
随着数字内容的日益丰富,将HTML转换为PDF格式已成为文档管理和分发中的常见需求。本文详细介绍了HTML到PDF转换工具的基本概念、技术原理,以及转换过程中的常见问题。文中比较了多种主流的开源和商业转换工具,包括它们的使用方法、优势与不足。通过效率评估,本文对不同工具的转换速度、资源消耗、质量和批量转换能力进行了系统的测试和对比。最后,本文探讨了HTML到PD
Gannzilla Pro新手快速入门:掌握Gann分析法的10大关键步骤
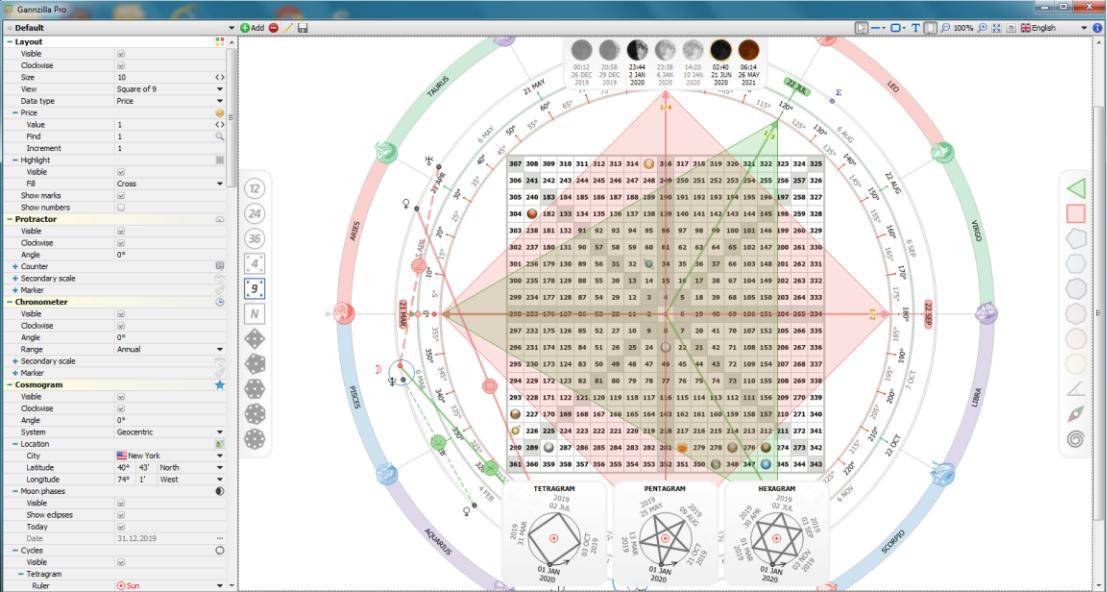
# 摘要
Gann分析法是一种以金融市场为对象的技术分析工具,它融合了几何学、天文学以及数学等学科知识,用于预测市场价格走势。本文首先概述了Gann分析法的历史起源、核心理念和关键工具,随后详细介绍Gannzilla Pro软件的功能和应用策略。文章深入探讨了Gann分析法在市场分析中的实际应用,如主要Gann角度线的识别和使用、时间循环的识别,以及角度线与图表模式的结合。最后,本文探讨了Gannzilla Pro的高级应
高通8155芯片深度解析:架构、功能、实战与优化大全(2023版)
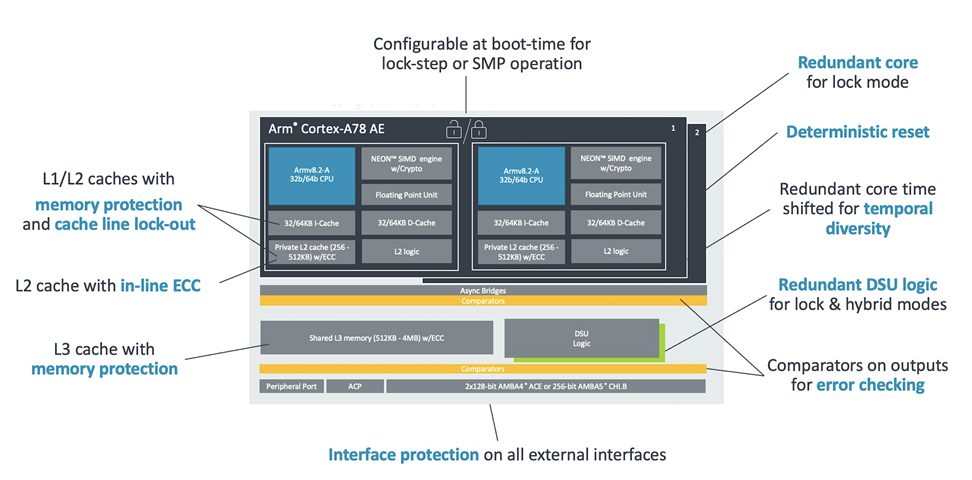
# 摘要
本文旨在全面介绍和分析高通8155芯片的特性、架构以及功能,旨在为读者提供深入理解该芯片的应用与性能优化方法。首先,概述了高通8155芯片的设计目标和架构组件。接着,详细解析了其处理单元、
Zkteco中控系统E-ZKEco Pro安装实践:高级技巧大揭秘

# 摘要
本文详细介绍了Zkteco中控系统E-ZKEco Pro的安装、配置和安全管理。首先,概述了系统的整体架构和准备工作,包括硬件需求、软件环境搭建及用户权限设置。接着,详细阐述了系统安装的具体步骤,涵盖安装向导使用、数据库配置以及各系统模块的安装与配置。文章还探讨了系统的高级配置技巧,如性能调优、系统集成及应急响应
【雷达信号处理进阶】
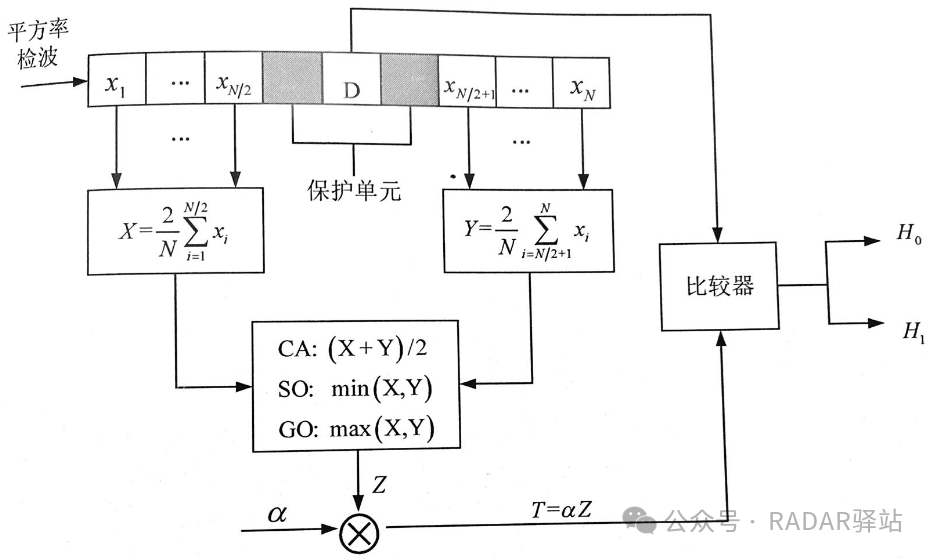
# 摘要
雷达信号处理是现代雷达系统中至关重要的环节,涉及信号的数字化、滤波、目标检测、跟踪以及空间谱估计等多个关键技术领域。本文首先介绍了雷达信号处理的基础知识和数字信号处理的核心概念,然后详细探讨了滤波技术在信号处理中的应用及其性能评估。在目标检测和跟踪方面,本文分析了常用算法和性能评估标准,并探讨了恒虚警率(CFAR)技术在不同环境下的适应性。空间谱估计与波束形成章节深入阐述了波达方向估计方法和自适应波束
递归算法揭秘:课后习题中的隐藏高手
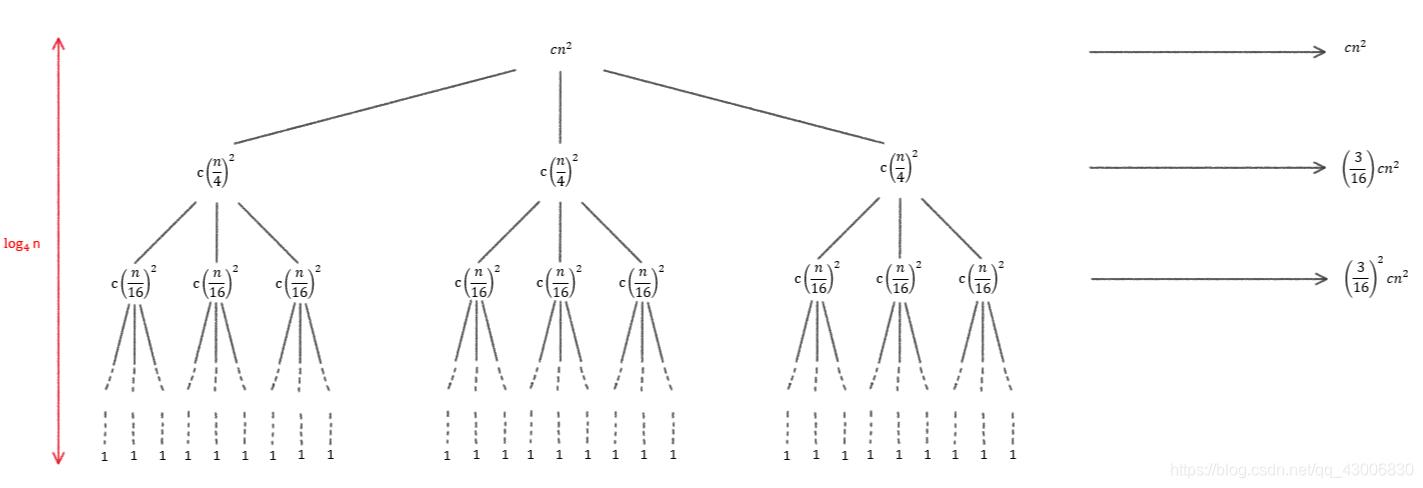
# 摘要
递归算法作为计算机科学中的基础概念和核心技术,贯穿于理论与实际应用的多个层面。本文首先介绍了递归算法的理论基础和核心原理,包括其数学定义、工作原理以及与迭代算法的关系
跨平台连接HoneyWell PHD数据库:技术要点与实践案例分析
# 摘要
随着信息技术的快速发展,跨平台连接技术变得越来越重要。本文首先介绍了HoneyWell PHD数据库的基本概念和概述,然后深入探讨了跨平台连接技术的基础知识,包括其定义、必要性、技术要求,以及常用连接工具如ODBC、JDBC、OLE DB等。在此基础上,文章详细阐述了HoneyWell PHD数据库的连接实践,包括跨平台连接工具的安装配置、连接参数设置、数据同步
现场案例分析:Media新CCM18(Modbus-M)安装成功与失败的启示

# 摘要
本文详细介绍了Media新CCM18(Modbus-M)的安装流程及其深入应用。首先从理论基础和安装前准备入手,深入解析了Modbus协议的工作原理及安装环境搭建的关键步骤。接着,文章通过详细的安装流程图,指导用户如何一步步完成安装,并提供了在安装中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )