IP地址安全保护及防护措施
发布时间: 2024-03-05 12:02:01 阅读量: 65 订阅数: 39 

网络安全及其防范措施
# 1. IP地址的基础知识
## 1.1 IP地址的概念及作用
IP地址(Internet Protocol Address)是指分配给网络上设备的标识符,用于在网络中唯一标识设备。它是网络通信中的重要组成部分,可以帮助数据在网络中的正确传输和路由。
在计算机网络中,IP地址扮演着类似于“门牌号”的角色,它能够确保数据包能够准确地被发送到目标设备,并且能够从源设备正确地返回。IP地址的作用包括标识设备、定位设备所在网络、实现数据包的路由等。
## 1.2 IP地址的分类和分配方式
根据不同的标准和需求,IP地址可以根据网络规模、用途等进行分类。其中,IPv4地址通过32位二进制数表示,通常以“xxx.xxx.xxx.xxx”的形式展示。而IPv6地址则通过128位二进制数表示,通常以较长的十六进制数字符串展示。
IP地址的分配方式通常包括公有IP地址和私有IP地址。公有IP地址可在全球范围内唯一标识一个设备,用于在因特网上通信。私有IP地址则用于内部网络,不直接暴露在因特网上,通常在局域网内使用。
## 1.3 IPv4和IPv6的区别及应用
IPv4和IPv6是目前广泛使用的两个IP地址协议。IPv4地址空间有限,导致IP地址资源短缺问题日益突出,而IPv6地址空间极为庞大,可以有效缓解IPv4的地址枯竭问题。
IPv4与IPv6在地址表示、地址分配、路由协议等方面存在显著差异。随着IPv6逐渐成为主流协议,它将逐步取代IPv4成为主要的网络通信协议。
以上是IP地址的基础知识介绍,下一章将对IP地址的安全威胁进行分析。
# 2. IP地址的安全威胁分析
IP地址作为网络通信的基础,承载着重要的信息传输任务,但同时也存在各种安全威胁。在本章中,我们将对IP地址的安全威胁进行分析,深入探讨IP地址可能面临的风险和攻击方式。
### 2.1 IP地址泄露的危害
IP地址泄露可能带来以下危害:
- **位置跟踪**:通过IP地址可以定位用户的地理位置,造成隐私泄露。
- **网络入侵**:黑客可利用IP地址进行针对性攻击,入侵用户网络或系统。
- **监控和数据窃取**:泄露IP地址可能导致个人信息被监控或窃取。
### 2.2 IP地址被攻击的方式
IP地址可能受到以下攻击方式:
- **DDoS攻击**:通过向IP地址发送大量恶意流量,造成服务不可用。
- **IP欺骗**:攻击者伪造IP地址,冒充合法用户进行攻击或欺诈。
- **端口扫描**:对IP地址进行端口扫描,探测系统漏洞进行攻击。
### 2.3 常见的IP地址安全问题案例分析
1. **DNS劫持**:攻击者篡改DNS记录,将用户访问的合法网站导向恶意网站。
2. **IP地址欺诈**:通过伪造IP地址,冒充信任网站进行诈骗或钓鱼攻击。
3. **IP地址泄露**:在P2P下载、邮件传输等过程中,IP地址泄露用户隐私信息。
通过对IP地址的安全威胁分析,我们能更好地了解如何保护IP地址安全,避免不法分子利用这些漏洞进行攻击。接下来,我们将介绍IP地址安全保护技术以及应对措施。
# 3. IP地址安全保护技术
IP地址是计算机网络中非常重要的组成部分,保护IP地址安全对于网络安全至关重要。在本章中,我们将介绍几种常见的IP地址安全保护技术,包括防火墙的作用和配置、VPN技术在IP地址安全中的应用,以及IP地址隐藏技术及其原理。
#### 3.1 防火墙的作用和配置
防火墙是保护网络安全的重要设备,可以控制网络流量,监控数据包,并根据预先设定的规则对数据包进行筛选。要保护IP地址安全,正确配置防火墙非常关键。
以下是一个简单的使用Python编写的防火墙配置示例:
```python
# 导入防火墙配置库
import iptc
# 创建一个新的防火墙链
chain = iptc.Chain(iptc.Table(iptc.Table.FILTER), "INPUT")
# 设置规则:拒绝来自特定IP地址的流量
rule = iptc.Rule()
rule.src = "192.168.1.100"
rule.target = iptc.Target(rule, "DROP")
# 将规则添加到防火墙链
chain.insert_rule(rule)
```
代码总结:这段代码使用Python的`iptc`库创建了一个防火墙链,并向其中添加了一条规则,拒绝来自IP地址为192.168.1.100的流量。
结果说明:经过这样的配置后,防火墙将拒绝来自该特定IP地址的流量,从而保护了IP地址的安全。
#### 3.2 VPN技术在IP地址安全中的应用
VPN(Virtual Private Network,虚拟专用网络)技术可以通过加密和隧道技术,为用户提供安全的网络连接,有效保护IP地址安全。
以下是一个使用Java编写的简单VPN连接示例:
```java
// 导入VPN连接库
import java.net.*;
public class VpnConnection {
public static void main(String[] args) {
try {
// 创建VPN连接
Socket vpnSocket = new Socket("vpn-server-ip", 8888);
// 进行数据传输...
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
代码总结:这段Java代码通过Socket建立了与VPN服务器的连接,进行安全的数据传输。
结果说明:利用VPN技术,用户可以通过加密的隧道与VPN服务器建立安全连接,在互联网上安全地传输数据,有效保护IP地址安全。
#### 3.3 IP地址隐藏技术及其原理
IP地址隐藏技术通过代理、重定向或加密等手段隐藏真实的IP地址,提高网络安全性。
以下是一个简单的使用Go语言编写的IP地址隐藏技术示例:
```go
package main
import (
"fmt"
"net/http"
"net/url"
)
func main() {
proxyURL, _ := url.Parse("http://proxy-server-ip:8080")
client := &http.Client{
Transport: &http.Transport{
Proxy: http.ProxyURL(proxyURL),
},
}
req, _ := http.NewRequest("GET", "https://www.example.com", nil)
resp, _ := client.Do(req)
defer resp.Body.Close()
// 处理响应...
}
```
代码总结:这段Go语言代码使用代理服务器将真实IP地址隐藏,通过代理服务器向目标服务器发起请求。
结果说明:通过利用代理服务器,用户的真实IP地址得以隐藏,保护了IP地址的安全性。
通过本章的介绍,我们了解了防火墙、VPN技术和IP地址隐藏技术在保护IP地址安全中的作用和应用,这些技术对于保护IP地址安全至关重要。
# 4. IP地址隐私保护的法律法规
在网络安全领域,IP地址作为重要的网络标识,涉及到用户隐私和数据安全。因此,IP地址的隐私保护成为全球范围内的热点问题。本章将介绍与IP地址隐私保护相关的法律法规,以及在企业环境中如何遵守相关规定。
#### 4.1 个人隐私保护相关法律法规分析
- **GDPR(通用数据保护条例)**:欧洲联盟颁布的GDPR对于个人数据的保护提出了严格要求,其中包括IP地址也被视为可以识别个人身份的敏感信息之一。任何收集、处理和储存IP地址的行为都需要符合GDPR的规定,以保护用户隐私。
- **《个人信息保护法》**:作为中国个人信息保护的基础法律,明确规定了个人信息的范围和保护原则。其中,IP地址作为个人身份信息的一部分,应当受到合法合规的保护,未经授权不得泄露和滥用。
#### 4.2 关于IP地址数据保护的国际标准
- **ISO/IEC 27001**:该标准是信息安全管理系统(ISMS)的国际标准,要求组织在管理IP地址时要确保其保密性、完整性和可用性,有效防范IP地址泄露和未授权访问行为。
- **PCI DSS**:针对信用卡行业的数据安全标准,也对IP地址的保护提出了具体要求,要求在数据传输和存储中采取加密措施,同时限制对IP地址的访问权限,防止数据泄露。
#### 4.3 在企业环境中的IP地址隐私合规问题
在企业网络中,管理和保护IP地址涉及到企业数据资产的安全和合规性。企业需要建立完善的IP地址管理机制,包括IP地址的分配、使用和监控,确保在符合法律法规的前提下保护IP地址的隐私安全。
总结:合规管理IP地址隐私不仅是法律的要求,也是企业自身信息安全保护的需要。企业应当结合相关法律法规和国际标准,建立完善的IP地址保护机制,确保用户数据安全和隐私保护。
# 5. IP地址安全管理及监控
在网络安全中,IP地址的安全管理及监控是至关重要的,同时也是保护网络不被攻击和滥用的重要手段。本章将介绍IP地址管理的最佳实践、IP地址访问控制及权限管理,以及IP地址安全事件的监控与响应。
### 5.1 IP地址管理的最佳实践
在进行IP地址管理时,需要遵循以下最佳实践:
- 确保所有设备都有唯一的IP地址,避免IP地址冲突;
- 使用DHCP服务器来动态分配IP地址,便于集中管理和避免手动配置错误;
- 建立IP地址的规划和管理策略,包括IP地址段划分、子网划分等;
- 定期清理和回收长时间未使用的IP地址,避免资源浪费和安全风险。
### 5.2 IP地址访问控制及权限管理
通过访问控制列表(ACL)和权限管理,可以对IP地址进行精细化控制和管理:
```python
# Python示例代码
# 设置访问控制列表(ACL)
acl = {
"allow": ["192.168.1.0/24", "10.0.0.1"],
"deny": ["172.16.0.0/16"]
}
# 检查IP地址是否被允许访问
def check_ip_access(ip):
if ip in acl["allow"]:
return True
elif any(ip.startswith(i) for i in acl["allow"]):
return True
elif any(ip.startswith(i) for i in acl["deny"]):
return False
else:
return True
```
以上代码演示了如何使用ACL进行IP地址访问控制,同时允许列表和拒绝列表的管理。
### 5.3 IP地址安全事件监控与响应
针对IP地址安全事件,需要建立完善的监控系统和响应机制,及时发现并应对安全威胁:
```java
// Java示例代码
// 监控IP地址安全事件
public class IPAddressMonitor {
public void monitorIPAddressEvents() {
// 实时监控IP地址访问情况
}
public void respondToEvents() {
// 根据监控结果及时做出响应
}
}
```
以上Java示例代码展示了监控IP地址安全事件并实时响应的基本框架。
希望以上内容能够满足您的需求。如果还需要其他内容或有其他问题,欢迎提出建议。
# 6. IP地址安全防护策略实例分享
在IP地址安全防护中,制定有效的策略至关重要。以下是一些实际案例和策略分享,帮助您更好地保护IP地址安全。
#### 6.1 实际案例分析:IP地址泄露及解决方法
**场景描述:** 某公司的内部网站存在IP地址泄露问题,导致敏感信息外泄,造成严重后果。现需要采取解决措施以防止IP地址泄漏。
**解决方法:**
1. 使用反向代理服务器:通过反向代理服务器隐藏真实服务器的IP地址,对外只暴露代理服务器的IP,增加保护层。
```python
# 反向代理服务器示例代码
from flask import Flask
from flask_reverse_proxy import FlaskReverseProxied
app = Flask(__name__)
proxied = FlaskReverseProxied(app)
@app.route('/')
def index():
return "Welcome to the internal site!"
if __name__ == '__main__':
app.run()
```
**代码总结:** 通过反向代理服务器,实现隐藏真实服务器IP地址的目的,增加安全性。
**结果说明:** 外部访问者只能看到代理服务器的IP地址,无法直接获取到真实服务器的IP信息,提高了IP地址的安全性。
#### 6.2 设定IP地址安全策略的最佳实践
**最佳实践建议:**
- 定期审查和更新防火墙规则,限制不必要的IP地址访问。
- 使用网络隔离技术,将内部网络和外部网络分离,减少内部IP地址暴露的可能性。
- 实施强密码策略和多因素认证,降低IP地址被非法访问的风险。
#### 6.3 IP地址安全措施的未来发展趋势
**未来发展趋势:**
- 强化智能化安全防护:利用AI技术对IP地址访问行为进行实时监测和分析,提高安全防护的智能化水平。
- 加强协同防护:IP地址安全需要跨部门、跨组织的合作,未来趋势是建立更加紧密的协同机制,共同应对安全挑战。
- 深度集成安全解决方案:将IP地址安全融入整个网络安全体系,实现深度集成,提供全方位的安全保护。
通过以上实例分享和趋势展望,可以更好地制定和完善IP地址安全防护策略,提升网络安全水平。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
华为MA5800-X15 OLT操作指南:GPON组网与故障排除的5大秘诀

# 摘要
本论文首先概述了华为MA5800-X15 OLT的基本架构和功能特点,并对GPON技术的基础知识、组网原理以及网络组件的功能进行了详细阐述。接着,重点介绍了MA5800-X15 OLT的配置、管理、维护和监控方法,为运营商提供了实用的技术支持。通过具体的组网案例分析,探讨了该设备在不同场
【电源管理秘籍】:K7开发板稳定供电的10个绝招
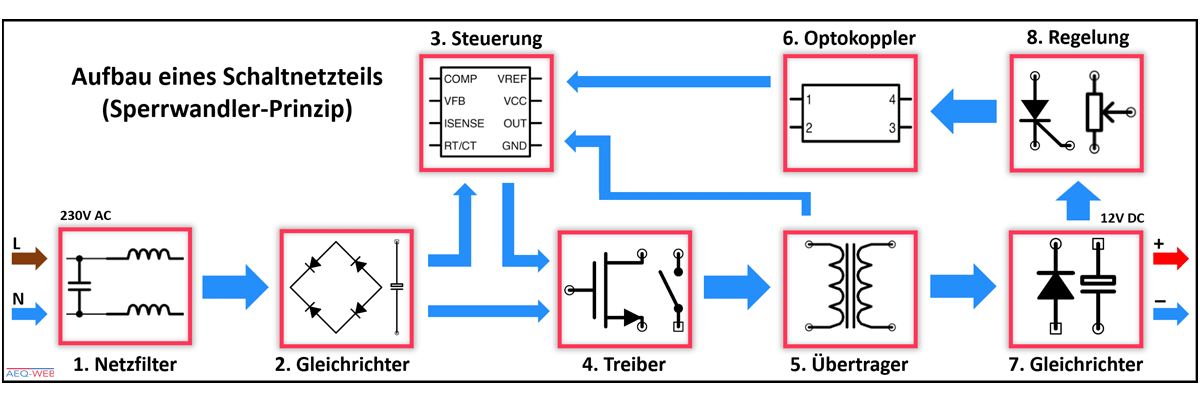
# 摘要
电源管理对于K7开发板的稳定性和性能至关重要。本文首先介绍了电源管理的基本理论,包括供电系统的组成及关键指标,并探讨了K7开发板具体的供电需求。接着,本文深入讨论了电源管理实践技巧,涉及电源需求分析、电路设计、测试与验证等方面。此外,本文还探讨了实现K7开发板稳定供电的绝招,包括高效开关电源设计、散热与热管理策略,以及电源故障的诊断与恢复。最后,
【悬浮系统关键技术】:小球控制系统设计的稳定性提升指南
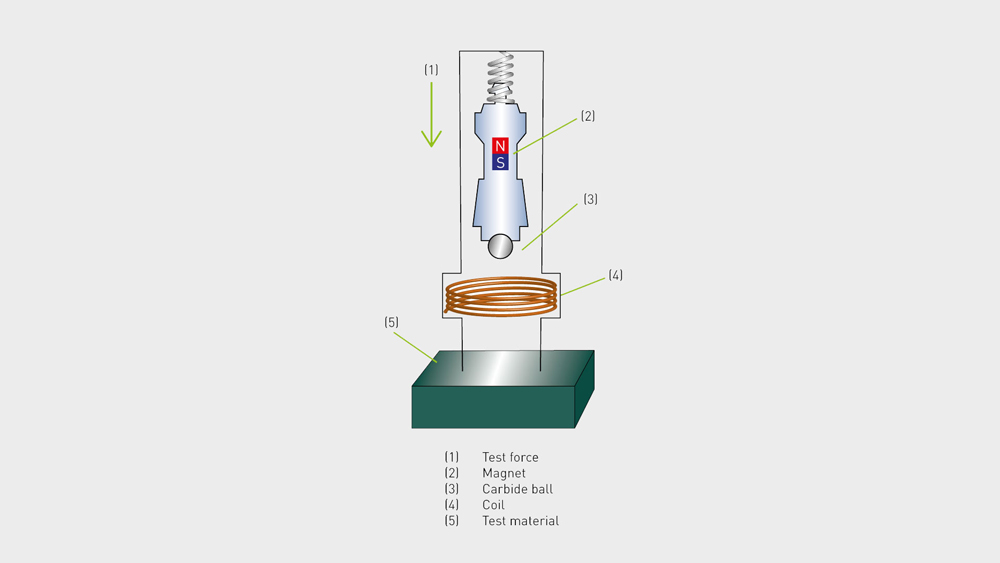
# 摘要
本文旨在探讨悬浮系统和小球控制基础理论与实践设计,通过对悬浮系统稳定性进行理论分析,评估控制理论在悬浮系统中的应用,并讨论系统建模与分析方法。在小球控制系统的实践设计部分,文章详细阐述了硬件和软件的设计实现,并探讨了系统集成与调试过程中的关键问题。进一步地,本文提出悬浮系统稳定性的提升技术,包括实时反馈控制、前馈控制与补偿技术,以及鲁棒控制与适应性控制技术的应用。最后,本文通过设计案例与分析
聚合物钽电容故障诊断与预防全攻略:工程师必看

# 摘要
本文系统地介绍了聚合物钽电容的基础知识、故障机理、诊断方法、预防措施以及维护策略,并通过实际案例分析深入探讨了故障诊断和修复过程。文章首先阐述了聚合物钽电容的电气特性和常见故障模式,包括电容值、容差、漏电流及等效串联电阻(ESR)等参数。接着,分析了制造缺陷、过电压/过电流、环境因
【HyperBus时序标准更新】:新版本亮点、挑战与应对

# 摘要
HyperBus作为一种先进的内存接口标准,近年来因其高速度和高效率在多个领域得到广泛应用。本文首先概述了HyperBus的基本时序标准,并详细分析了新版本的亮点,包括标准化改进的细节、性能提升的关键因素以及硬件兼容性和升级路径。接着,本文探讨了面对技术挑战时的战略规划,包括兼容性问题的识别与解决、系统稳定性的保障措施以及对未来技术趋势的预判与适应。在应用与优化方面
【Linux必备技巧】:xlsx转txt的多种方法及最佳选择
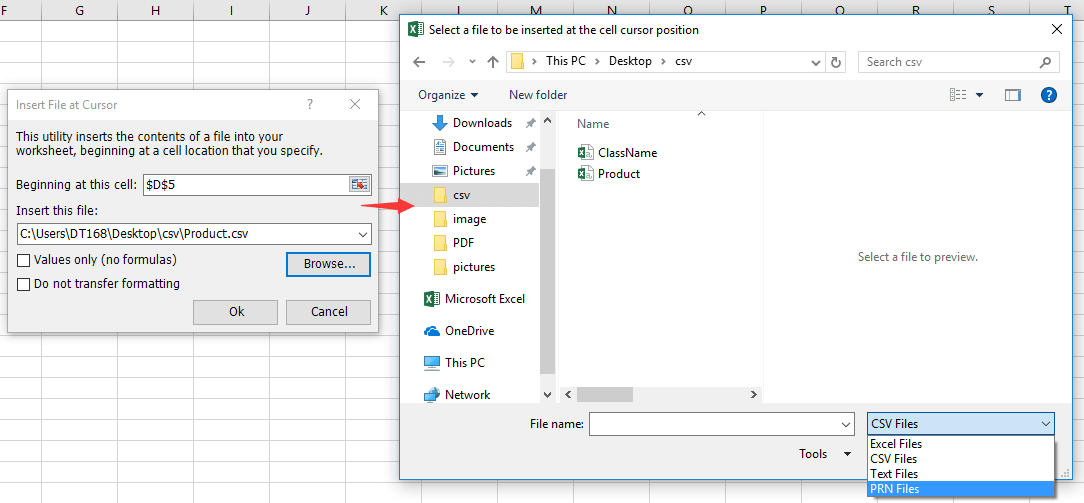
# 摘要
本文探讨了xlsx到txt格式转换的需求背景和多种技术实现方法。首先分析了使用命令行工具在Linux环境下进行格式转换的技术原理,然后介绍了编程语言如Python和Perl在自动化转换中的应用。接着,文中详述了图形界面工具,包括LibreOffice命令行工具和在线转换工具的使用方法。文章还探讨了处理大量文件、保留文件格式和内容完整性以及错误处理和日志记录的进阶技巧。
SPD参数调整终极手册:内存性能优化的黄金法则
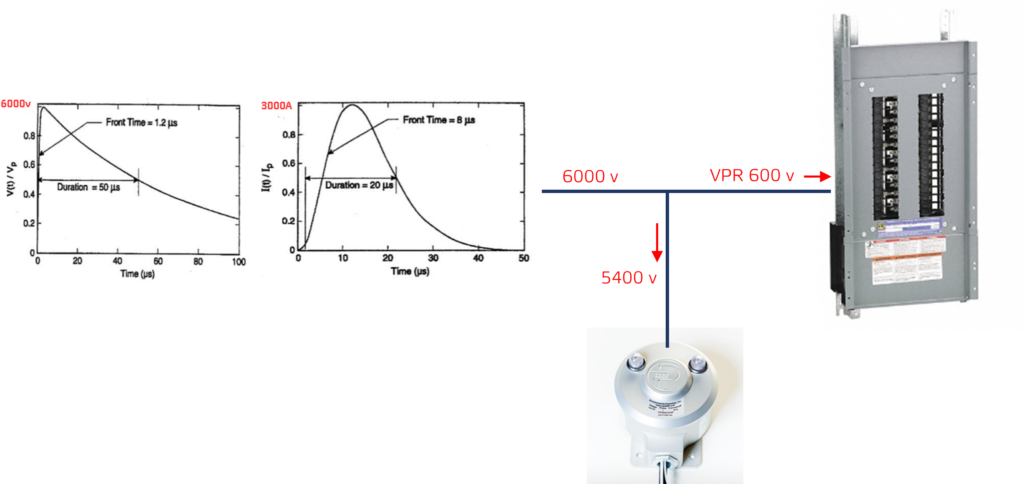
# 摘要
SPD(Serial Presence Detect)参数是内存条上存储的关于其性能和规格信息的标准,直接影响内存的性能表现。本文首先介绍了SPD参数的基础知识和内存性能的关系,然后详细解读了SPD参数的结构、读取方法以及优化策略,并通过具体案例展示了SPD参数调整实践。文章进一步探讨了高级SPD参数调整技巧,包括时序优化、
【MVS系统架构深度解析】:掌握进阶之路的9个秘诀
# 摘要
本文系统地介绍了MVS系统架构的核心概念、关键组件、高可用性设计、操作与维护以及与现代技术的融合。文中详尽阐述了MVS系统的关键组件,如作业控制语言(JCL)和数据集的定义与功能,以及它们在系统中所扮演的角色。此外,本文还分析了MVS系统在高可用性设计方面的容错机制、性能优化和扩展性考虑。在操作与维护方面,提供了系统监控、日志分析以及维护策略的实践指导。同时,本文探讨了MVS系统如何
【PvSyst 6中文使用手册入门篇】:快速掌握光伏系统设计基础

# 摘要
PvSyst 6是一款广泛应用于光伏系统设计与模拟的软件工具,本文作为其中文使用手册的概述,旨在为用户提供一份关于软件界面、操作方法以及光伏系统设计、模拟与优化的综合性指南。通过本手册,用户将掌握PvSyst 6的基本操作和界面布局,了解如何通过软件进行光伏阵列布局设计、模拟系统性能,并学习如何优化系统性能及成本。手册还介绍了PvSyst 6
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )