YOLOv8模型硬件加速部署:GPU与TPU利用完全指南
发布时间: 2024-12-12 04:38:40 阅读量: 12 订阅数: 12 

实现SAR回波的BAQ压缩功能
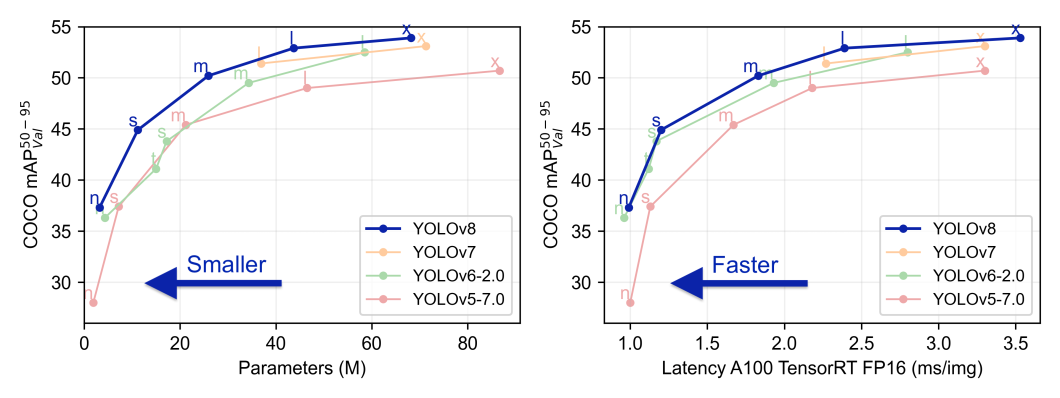
# 1. YOLOv8模型硬件加速概述
YOLOv8(You Only Look Once version 8)是当前最受欢迎的目标检测模型之一,它的高效性、快速性让它在实时检测领域尤为突出。然而,为了进一步提升模型的执行速度和响应能力,硬件加速成为关键的优化途径。硬件加速不仅能够增强模型的处理能力,还能在有限的计算资源下,实现更高的性能和效率。
在本章节中,我们将从宏观的角度来审视YOLOv8模型以及硬件加速的概念和重要性。随后,我们将深入探讨如何利用GPU和TPU这两种主流的硬件加速技术来实现YOLOv8模型的高效部署。通过分析不同的硬件加速方法,我们将为读者展示如何根据实际需求和场景选择最适合的加速方案,并提供对硬件加速未来发展趋势的前瞻性分析。
# 2. GPU加速部署YOLOv8模型
## 2.1 GPU硬件加速基础
### 2.1.1 GPU工作原理
GPU(Graphics Processing Unit),即图形处理器,最初是为图形处理而设计,现在已经被广泛应用于科学计算领域。GPU是由大量的小型处理单元组成的并行架构,这使得它在处理高度并行的任务时比CPU(Central Processing Unit)更加高效。这种设计允许它在短时间内执行大量的浮点运算,这是深度学习训练和推理过程中的关键要求。
在深度学习领域,GPU是通过其大规模并行处理能力来加速计算的。一个典型的GPU拥有成百上千的处理核心,可以同时处理大量的数据。当处理复杂的神经网络模型时,如YOLOv8模型,这些核心可以并行地执行矩阵运算和卷积操作,大大缩短了运算时间。
### 2.1.2 GPU在深度学习中的作用
GPU在深度学习中的作用主要体现在它的高效并行计算能力上。当一个神经网络模型需要进行前向传播或反向传播时,大量的数据需要被处理。在这些操作中,每一层的输出都是下一层输入的一部分,而这些操作可以被分解成许多小的子任务。GPU利用其大量核心可以同时处理这些子任务,从而加速整个计算过程。
由于深度学习模型通常包含数百万个参数,并且需要在数据集上进行大量迭代,因此传统CPU架构的串行处理模式在处理这些任务时效率很低。相比之下,GPU的并行处理架构能够在相同的时间内处理更多的数据,大幅度提升模型训练和推理的速度。
## 2.2 GPU部署YOLOv8的理论基础
### 2.2.1 YOLOv8模型架构理解
YOLOv8(You Only Look Once)是一种先进的实时目标检测算法,其架构设计旨在高效地进行目标检测任务。YOLOv8通过将目标检测任务划分为多个子任务,如边界框预测、置信度评估和类别概率计算,使得模型可以快速、准确地识别图像中的对象。
YOLOv8继承了YOLO系列算法的核心优势,即在检测速度和准确性之间取得良好的平衡。通过引入卷积神经网络(CNN),YOLOv8能够学习图像数据的层次化特征表示,从而有效地识别目标。YOLOv8的每个像素点都参与预测,这使得模型能够检测出图像中多个不同尺度的目标。
### 2.2.2 硬件加速对模型性能的影响
硬件加速对于提高深度学习模型性能至关重要。在YOLOv8模型中,硬件加速可以显著提升处理速度和效率,从而实现实时目标检测。GPU的并行处理能力可以加速YOLOv8中的卷积运算,使得模型能够快速处理图像数据,缩短检测时间。
除了速度,硬件加速还能提高模型的处理能力,允许使用更复杂、参数更多的模型来提升检测的准确性。在有限的时间内,GPU能够执行更多的计算任务,这对于需要大量计算资源的模型特别有益。此外,硬件加速还降低了系统功耗,提高了能效比,使得部署在移动设备或边缘设备上成为可能。
## 2.3 GPU部署YOLOv8的实践操作
### 2.3.1 环境搭建和依赖安装
为了在GPU上成功部署YOLOv8模型,首先需要搭建一个适合深度学习的环境。这通常涉及安装CUDA(Compute Unified Device Architecture)和cuDNN(CUDA Deep Neural Network Library),这两个库是由NVIDIA提供的,分别用于通用GPU计算和深度神经网络的加速。
安装CUDA后,需要下载对应版本的cuDNN库,确保其版本与CUDA相兼容。除了CUDA和cuDNN,还需要安装深度学习框架,如TensorFlow或PyTorch,它们提供了运行YOLOv8所需的接口。以下是使用PyTorch框架进行安装的示例命令:
```bash
# 安装CUDA和cuDNN
# 这里假设安装CUDA 11.3和cuDNN 8.2,具体步骤根据官方网站指引进行
# 安装PyTorch和依赖
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# 检查GPU是否可以被正确识别和使用
python -c "import torch; print(torch.cuda.is_available())"
```
如果命令执行正确,系统将输出"True",表明GPU已经被PyTorch框架识别并且可以使用。
### 2.3.2 模型加载与推理优化技巧
一旦环境搭建完成,下一步是将YOLOv8模型加载到GPU中并进行推理操作。在加载模型时,使用PyTorch的`torch.load`函数可以将模型权重加载到GPU。具体代码如下:
```python
import torch
# 加载模型权重到GPU
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
model.cuda() # 模型移动到GPU
```
为了进一步优化推理速度,可以采取一些常见的技巧,比如使用混合精度推理(half-precision)和开启Tensor Core。这些优化可以使得模型在保持精度的同时,利用GPU的硬件特性来提升推理速度。
```python
# 混合精度推理
scaler = torch.cuda.amp.GradScaler() # GradScaler用于混合精度训练,这里用于推理
with torch.cuda.amp.autocast():
results = model(data) # data是预处理后的输入数据
```
### 2.3.3 性能监控与故障排查
部署YOLOv8模型到GPU后,需要持续监控其性能,以确保模型稳定运行。性能监控通常涉及追踪GPU的利用率、内存使用量、功耗等指标。通过这些指标,可以了解模型是否在GPU上充分优化。
如果发现性能瓶颈,可以通过以下方式进行故障排查:
- 确认GPU驱动是否为最新版本。
- 检查GPU内存是否足够。
- 使用NVIDIA的NvTop工具监控GPU运行状态。
此外,还可以通过调整

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供有关 YOLOv8 模型导出和部署的全面指南,涵盖从模型导出到跨平台部署和硬件加速等各个方面。专栏中的文章包括:
* 一步到位的性能提升秘籍:YOLOv8 模型导出与部署终极指南
* 快速解答与全面解决方案:YOLOv8 模型部署常见问题
* 模型瘦身与效率提升的专家指南:YOLOv8 模型量化技术
* 兼容性与效率分析:跨平台部署 YOLOv8 模型案例研究
* 完美解决方案:YOLOv8 模型集成到现有系统
* 一步搞定:云服务集成 YOLOv8 模型部署(AWS、Azure、Google Cloud)
* GPU 与 TPU 利用完全指南:YOLOv8 模型硬件加速部署
* 流媒体处理高效技巧:YOLOv8 模型实时性部署提升
* 优化部署的黄金法则:YOLOv8 模型负载均衡与服务发现机制
本专栏旨在为开发人员和工程师提供全面的资源,帮助他们高效地导出、部署和优化 YOLOv8 模型,以实现最佳性能和可扩展性。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【解密ISO 11898-2】:7大案例揭示CAN总线技术的实际应用
参考资源链接:[ISO 11898-2中文版:道路车辆CAN高速物理层标准解析](https://wenku.csdn.net/doc/26ogdo5nba?spm=1055.2635.3001.10343)
# 1. CAN总线技术概述
## 1.1 CAN总线的起源与定义
控制器局域网络(CAN)总线是一种广泛应用于电子控制单元(ECU)之间的可靠通信协议。它最初由德国博世公司为汽车内部网络通信开发,以取
Max-Log-MAP与SOVA:Turbo码性能与应用的双重视角

参考资源链接:[ Turbo码译码算法详解:MAP、Max-Log-MAP、Log-MAP与SOVA](https://wenku.csdn.net/doc/67u
【STM32F407终极指南】:7大技巧带你从新手到实战专家
参考资源链接:[STM32F407 Cortex-M4 MCU 数据手册:高性能、低功耗特性](https://wenku.csdn.net/doc/64604c48543f8444888dcfb2?spm=1055.2635.3001.10343)
# 1. STM32F407概述和开发环境搭建
## 1.1 STM32F407简介
STM32F407是由STMicroelectronics(意法
电子称校准秘籍:掌握这3个艺术级技巧,确保精准无误
参考资源链接:[梅特勒-托利多电子称全面设置教程](https://wenku.csdn.net/doc/10hjvgjrbf?spm=1055.2635.3001.10343)
# 1. 电子称校准的基础知识
## 1.1 校准的重要性
校准是确保电子称量设备精确性和可靠性的关键步骤。在日常使用过程中,多种因素如温度变化、机械磨损等可能导致电子称的读数偏离真实值。定期进行校准可以保证测量结果的准确性,符合行业标准和法律法规的要求。
## 1.2 校准的定义和目的
电子称校准是指使用已知精度的标准砝码或其他校准工具,对照电子称的显示值进行比对和调整,以消除误差或偏差,保证称量结果的准确可靠
坐标系统的秘密:Tecplot从笛卡尔到极坐标的高级应用解析

参考资源链接:[Tecplot入门教程:数据可视化与图形处理](https://wenku.csdn.net/doc/3e4i6cw3r9?spm=1055.2635.3001.10343)
# 1. Tecplot软件概览及坐标系统基础
## 1.1 Tecplot软件的介绍
Tecplot是一款广泛应用于科学和工程领域的数据分析和可视化软件。它提供了丰富的坐
SINAMICS S120电源模块详解:正确安装与维护的黄金法则

参考资源链接:[西门子SINAMICS S120伺服系统调试指南](https://wenku.csdn.net/doc/64715846d12cbe7ec3ff8638?spm=1055.2635.3001.10343)
# 1. SINAMICS S120电源模块概述
SIN
动态规划在MATLAB中的实现:案例分析与实用技巧

参考资源链接:[最优化方法Matlab程序设计课后答案详解](https://wenku.csdn.net/doc/6472f573d12cbe
揭秘DCDC-Boost电路仿真:10个案例深度分析与性能优化策略
参考资源链接:[LTspice新手指南:DC/DC Boost电路仿真](https://wenku.csdn.net/doc/1ue4eodgd8?spm=1055.2635.3001.10343)
# 1. DCDC-Boost电路仿真基础
## 1.1 电路仿真概述
电路仿真技术是一种利用计算工具模拟电路行为的过程,它能够帮助工程师在实际搭建电路前预测电路的性能。在电力电子领域,DCDC-Boost电路作为提
SINAMICS G120 CU240B-2_CU240E-2应用技巧: 参数手册中的隐藏功能全面挖掘

参考资源链接:[SINAMICS G120 CU240B/CU240E变频器参数手册(2016版)](https://wenku.csdn.net/doc/64658f935928463033ceb8af?spm=1055.2635.3
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )