MySQL索引优化秘籍:提升查询性能,打造高效数据库
发布时间: 2024-07-25 18:50:52 阅读量: 26 订阅数: 28 

supplyChainSystem:供应链系统优化:服务器:spring+springmvc+mybatis 数据库:mysql 5.7 前端:bootstrap 算法:dijkstra
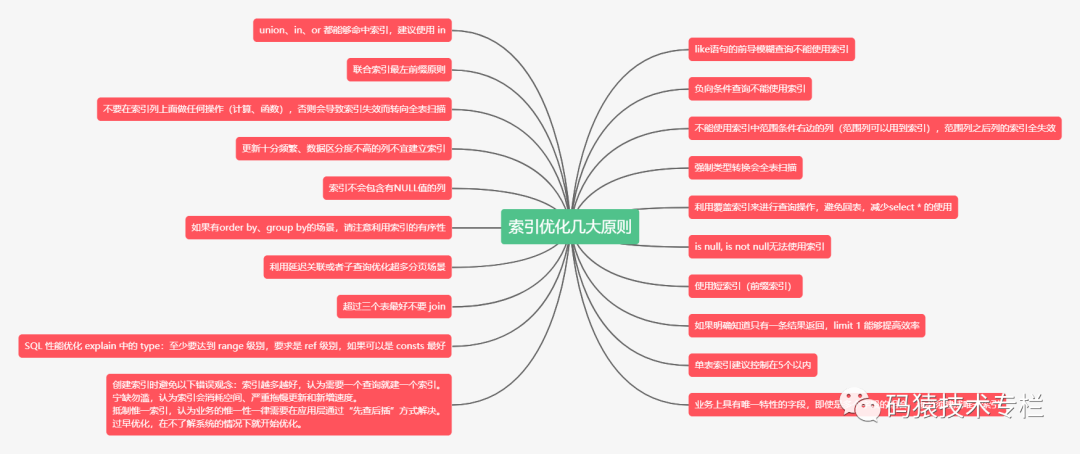
# 1. MySQL索引基础**
索引是MySQL中一种重要的数据结构,用于加速对数据的访问。它通过在表中创建额外的列来实现,其中包含指向表中实际数据的指针。当查询使用索引时,MySQL可以直接跳到数据所在的位置,而无需扫描整个表。
索引可以显着提高查询性能,特别是对于大型表。它们通过减少磁盘I/O操作和CPU处理时间来实现这一点。在设计和使用索引时,需要考虑以下几个关键因素:
- **索引类型:**MySQL支持多种索引类型,包括B-Tree索引、哈希索引和全文索引。选择正确的索引类型对于优化查询性能至关重要。
- **索引设计:**索引设计应遵循一些最佳实践,例如最左前缀原则和避免冗余索引。这些原则有助于确保索引有效且不会对性能产生负面影响。
- **索引维护:**索引需要定期维护,包括重建和监控。这有助于确保索引保持最新且高效。
# 2. 索引优化策略
### 2.1 索引类型选择
**2.1.1 B-Tree索引**
B-Tree索引是一种平衡搜索树,它将数据按顺序存储在多个级别中。每个级别都包含指向下一级别的指针,从而形成一个树形结构。B-Tree索引支持快速查找,因为算法可以快速跳过不相关的节点,直接定位到目标数据。
**参数说明:**
* `key_length`:索引键的长度。
* `block_size`:每个节点的大小。
* `degree`:每个节点最多可以包含的子节点数。
**代码块:**
```sql
CREATE INDEX idx_name ON table_name (column_name) USING BTREE;
```
**逻辑分析:**
此代码创建了一个名为`idx_name`的B-Tree索引,用于对`table_name`表中的`column_name`列进行索引。
**2.1.2 哈希索引**
哈希索引将数据映射到一个哈希表中,每个哈希表项都存储一个键和一个指向相应数据的指针。哈希索引支持非常快速的查找,因为算法可以直接根据键计算出数据的位置。
**参数说明:**
* `key_length`:索引键的长度。
* `bucket_size`:哈希表中每个桶的大小。
**代码块:**
```sql
CREATE INDEX idx_name ON table_name (column_name) USING HASH;
```
**逻辑分析:**
此代码创建了一个名为`idx_name`的哈希索引,用于对`table_name`表中的`column_name`列进行索引。
### 2.2 索引设计原则
**2.2.1 最左前缀原则**
最左前缀原则是指在创建联合索引时,应该将最经常使用的列放在索引的最左边。这可以确保索引可以用于范围查询,从而提高查询效率。
**表格:**
| 索引顺序 | 查询效率 |
|---|---|
| (a, b, c) | 低 |
| (b, a, c) | 中等 |
| (c, a, b) | 高 |
**2.2.2 避免冗余索引**
冗余索引是指对同一列或一组列创建多个索引。这会浪费存储空间,并降低索引维护的效率。因此,在设计索引时,应该避免创建冗余索引。
### 2.3 索引维护
**2.3.1 索引重建**
随着时间的推移,索引可能会变得碎片化,从而降低查询效率。索引重建可以重新组织索引,消除碎片,提高查询速度。
**代码块:**
```sql
ALTER TABLE table_name REBUILD INDEX idx_name;
```
**逻辑分析:**
此代码重建了`table_name`表中名为`idx_name`的索引。
**2.3.2 索引监控**
定期监控索引的使用情况可以帮助识别需要重建或调整的索引。可以通过以下命令查看索引的使用统计信息:
```sql
SHOW INDEX FROM table_name;
```
# 3. 索引优化实践
### 3.1 查询分析与索引选择
#### 3.1.1 EXPLAIN命令的使用
EXPLAIN命令是MySQL中用于分析查询执行计划的强大工具。它可以提供有关查询如何执行、使用的索引以及查询成本的详细信息。
要使用EXPLAIN命令,只需在查询前加上EXPLAIN关键字即可。例如:
```sql
EXPLAIN SELECT * FROM table_name WHERE column_name = 'value';
```
EXPLAIN命令的输出是一个表格,其中包含以下列:
- **id:**查询中每个步骤的ID。
- **select_type:**查询类型,例如SIMPLE、PRIMARY等。
- **table:**正在访问的表。
- **type:**访问类型,例如ALL、index、range等。
- **possible_keys:**可能用于查询的索引。
- **key:**实际使用的索引。
- **rows:**估计的行数。
- **Extra:**其他信息,例如使用覆盖索引、使用临时表等。
通过分析EXPLAIN命令的输出,我们可以了解查询的执行计划,并确定是否需要优化索引。
#### 3.1.2 索引覆盖率分析
索引覆盖率是指查询中所需的所有列都包含在索引中。当索引覆盖率较高时,查询可以从索引中直接获取数据,而无需访问表数据。这可以显著提高查询性能。
要分析索引覆盖率,可以使用以下查询:
```sql
SELECT SUM(IF(index_name IS NULL, 1, 0)) AS uncovered_fields
FROM information_schema.columns
WHERE table_name = 'table_name'
AND column_name IN (
SELECT column_name
FROM information_schema.statistics
WHERE table_name = 'table_name'
AND index_name = 'index_name'
);
```
如果uncovered_fields的值为0,则表示查询中所需的所有列都包含在索引中。否则,需要考虑添加覆盖索引。
### 3.2 索引调整案例
#### 3.2.1 添加索引提升查询速度
假设我们有一个名为`orders`的表,其中包含以下列:
```
| id | product_id | customer_id | order_date |
```
如果我们经常需要根据`product_id`和`customer_id`查询订单,则可以使用以下查询:
```sql
SELECT * FROM orders WHERE product_id = 1 AND customer_id = 2;
```
使用EXPLAIN命令分析查询,我们发现没有使用索引:
```
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | orders | ALL | NULL | NULL | NULL | NULL | 1000 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
```
为了优化查询,我们可以添加一个联合索引:
```sql
CREATE INDEX idx_product_customer ON orders (product_id, customer_id);
```
再次使用EXPLAIN命令分析查询,我们发现使用了联合索引:
```
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | orders | ref | idx_product_customer | idx_product_customer | 8 | const | 1 | Using index |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
```
通过添加联合索引,查询性能得到了显著提升。
#### 3.2.2 删除冗余索引优化性能
有时,我们可能会创建不必要的索引,这会降低查询性能。冗余索引是指与其他索引重复的索引。
例如,如果我们已经创建了`idx_product_customer`索引,再创建`idx_customer_product`索引是冗余的。因为这两个索引都包含相同的列,并且在查询中使用时,只会使用一个索引。
为了优化性能,我们可以删除冗余索引:
```sql
DROP INDEX idx_customer_product ON orders;
```
通过删除冗余索引,查询性能可以得到改善。
# 4. 高级索引优化技巧
### 4.1 联合索引
#### 4.1.1 联合索引的创建和使用
联合索引是一种将多个列组合成一个索引的数据结构。当查询涉及多个列时,使用联合索引可以显著提高查询性能。
创建联合索引的语法如下:
```sql
CREATE INDEX index_name ON table_name (column1, column2, ...);
```
例如,创建一个名为 `idx_name_age` 的联合索引,用于 `name` 和 `age` 列:
```sql
CREATE INDEX idx_name_age ON employees (name, age);
```
使用联合索引时,查询将使用索引中第一个匹配的列。例如,如果查询条件为 `name = 'John' AND age = 30`,则索引 `idx_name_age` 将被使用,因为 `name` 是索引中的第一个列。
#### 4.1.2 联合索引的优化原则
设计联合索引时,应遵循以下优化原则:
- **最左前缀原则:**联合索引中的列应遵循最左前缀原则,即查询中使用的列应按顺序出现在索引中。
- **避免冗余列:**联合索引中不应包含冗余列,即已包含在其他索引中的列。
- **选择最常用的列:**联合索引中的列应是查询中使用最频繁的列。
### 4.2 分区索引
#### 4.2.1 分区索引的原理和优势
分区索引是一种将索引划分为多个分区的数据结构。每个分区包含特定范围的数据,例如日期范围或值范围。
分区索引的优势包括:
- **缩小索引大小:**分区索引将索引划分为较小的部分,从而减少了索引的大小。
- **提高查询性能:**当查询涉及特定范围的数据时,分区索引可以快速定位该范围内的分区,从而提高查询性能。
- **简化索引维护:**分区索引可以简化索引维护,因为可以单独重建或删除特定分区。
#### 4.2.2 分区索引的创建和管理
创建分区索引的语法如下:
```sql
CREATE INDEX index_name ON table_name (column)
PARTITION BY RANGE (column) (
PARTITION p1 VALUES LESS THAN (value1),
PARTITION p2 VALUES LESS THAN (value2),
...
);
```
例如,创建一个名为 `idx_date_range` 的分区索引,用于 `date` 列,并将其划分为三个分区:
```sql
CREATE INDEX idx_date_range ON orders (date)
PARTITION BY RANGE (date) (
PARTITION p1 VALUES LESS THAN ('2023-01-01'),
PARTITION p2 VALUES LESS THAN ('2023-04-01'),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
```
管理分区索引时,可以使用以下命令:
- **ALTER TABLE ... REORGANIZE PARTITION:**重新组织分区,以优化索引性能。
- **ALTER TABLE ... DROP PARTITION:**删除指定分区。
# 5.1 索引监控与维护
### 5.1.1 索引使用率监控
索引的使用率监控对于识别和优化未充分利用或使用过度索引至关重要。MySQL提供了多种方法来监控索引的使用情况:
- **EXPLAIN命令:** EXPLAIN命令可以提供有关查询如何使用索引的信息。通过分析EXPLAIN输出中的`Extra`列,可以确定查询是否使用了索引,以及使用了哪个索引。
- **information_schema.innodb_index_stats表:** 此表包含有关InnoDB索引使用情况的统计信息,包括读取次数、写入次数、更新次数和删除次数。
- **监控工具:** MySQL Workbench和pt-index等监控工具提供了图形化界面和报告,用于跟踪索引使用情况并识别需要优化的索引。
### 5.1.2 索引碎片整理
随着时间的推移,索引可能会变得碎片化,从而降低查询性能。索引碎片整理可以重新组织索引结构,提高查询速度。MySQL提供了以下方法来整理索引:
- **ALTER TABLE ... REORGANIZE INDEX:** 此语句可以对指定表上的索引进行碎片整理。
- **OPTIMIZE TABLE:** 此语句可以优化表,包括整理索引。
- **pt-index工具:** pt-index工具提供了强大的索引碎片整理功能,包括在线碎片整理和按页碎片整理。
**代码示例:**
```sql
ALTER TABLE table_name REORGANIZE INDEX index_name;
```
**参数说明:**
- `table_name`:要整理索引的表名。
- `index_name`:要整理的索引名。
**执行逻辑说明:**
此语句将对`table_name`表上的`index_name`索引进行碎片整理。碎片整理过程将重新组织索引结构,提高查询速度。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MySQL 专栏深入探讨了 MySQL 数据库的各个方面,从其架构和数据类型到索引优化、锁机制和性能调优。该专栏提供了全面的指南,涵盖了备份和恢复、复制技术、集群架构和死锁分析。此外,它还提供了表锁问题的解析、慢查询优化技巧、查询优化器原理和存储引擎比较。通过对 MySQL 数据库的全面理解,该专栏旨在帮助读者优化数据库性能、提升稳定性并满足业务需求。从数据库设计最佳实践到运维指南和故障排查技巧,该专栏为 MySQL 数据库管理员和开发人员提供了宝贵的资源,帮助他们充分利用 MySQL 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S7-1200 1500 SCL编程实践:构建实际应用案例分析

# 摘要
本文全面介绍了S7-1200/1500可编程逻辑控制器(PLC)的SCL(Structured Control Language)编程技术。从基础理论出发,详细解析了SCL的语法、关键字、数据类型、程序结构、内存管理等基础要素,并探讨了编程实践中的高效编程方法、实时数据处理、调试和性能优化技巧。文章通过实际应用案例分析,展
深入理解93K:体系架构与工作原理,技术大佬带你深入浅出

# 摘要
本文全面介绍了93K技术的架构、应用和进阶学习资源。首先概述了93K的技术概览和理论基础,
KST Ethernet KRL 22中文版:高级功能解锁,案例解析助你深入应用
# 摘要
本文全面介绍了KST Ethernet KRL 22中文版的概览、核心功能及其理论基础,并深入探讨了其在高级数据处理与分析、网络通信以及设备控制方面的应用。文章首先概述了KRL语言的基本构成、语法特点及与标准编程语言的差异,然后详细阐述了KST Ethernet KRL 2
农业决策革命:揭秘模糊优化技术在作物种植中的强大应用
# 摘要
模糊优化技术作为处理不确定性问题的有效工具,在作物种植领域展现出了巨大的应用潜力。本文首先概述了模糊优化技术的基本理论,并将其基础与传统作物种植决策模型进行对比。随后,深入探讨了模糊逻辑在作物种植条件评估、模糊优化算法在种植计划和资源配置中的具体应用。通过案例分析,文章进一步揭示了模糊神经网络和遗传算法等高级技术在提升作物种植决策质量中的作用。最后,本文讨论了模糊优化技术面临
泛微E9流程与移动端整合:打造随时随地的办公体验

# 摘要
随着信息技术的不断进步,泛微E9流程管理系统与移动端整合变得日益重要,本文首先概述了泛微E9流程管理系统的核心架构及其重要性,然后详细探讨了移动端整合的理论基础和技术路线。在实践章节中,文章对移动端界面设计、用户体验、流程自动化适配及安全性与权限管理进行了深入分析。此外,本文还提供了企业信息门户和智能表单的高级应用案例,并对移动办公的未来趋势进行了展望。通过分析不同行业案例
FANUC-0i-MC参数高级应用大揭秘:提升机床性能与可靠性
# 摘要
本论文全面探讨了FANUC-0i-MC数控系统中参数的基础知识、设置方法、调整技巧以及在提升机床性能方面的应用。首先概述了参数的分类、作用及其基础配置,进而深入分析了参数的调整前准备、监控和故障诊断策略。接着,本文着重阐述了通过参数优化切削工艺、伺服系统控制以及提高机床可靠性的具体应用实例。此外,介绍了参数编程实践、复杂加工应用案例和高级参数应用的创新思路。最后,针对新技术适应性、安全合规性以及参数技术的未来发展进行了展望,为实现智能制造和工业4.0环境下的高效生产提供了参考。
# 关键字
FANUC-0i-MC数控系统;参数设置;故障诊断;切削参数优化;伺服系统控制;智能化控制
Masm32函数使用全攻略:深入理解汇编中的函数应用
# 摘要
本文从入门到高级应用全面介绍了Masm32函数的使用,涵盖了从基础理论到实践技巧,再到高级优化和具体项目中的应用案例。首先,对Masm32函数的声明、定义、参数传递以及返回值处理进行了详细的阐述。随后,深入探讨了函数的进阶应用,如局部变量管理、递归函数和内联汇编技巧。文章接着展示了宏定义、代码优化策略和错误处理的高级技巧。最后,通过操作系统底层开发、游戏开发和安全领域中的应用案例,将Masm32函数的实际应用能力展现得淋漓尽致。本文旨在为开发者提供全面的Masm32函数知识框架,帮助他们在实际项目中实现更高效和优化的编程。
# 关键字
Masm32函数;函数声明定义;参数传递;递归
ABAP流水号管理最佳实践:流水中断与恢复,确保业务连续性

# 摘要
ABAP流水号管理是确保业务流程连续性和数据一致性的关键机制。本文首先概述了流水号的基本概念及其在业务连续性中的重要性,并深入探讨了流水号生成的不同策略,包括常规方法和高级技术,以及如何保证其唯一性和序列性。接着,文章分析了流水中断的常见原因,并提出了相应的预防措施和异常处理流程。对于流水中断后如何恢复,本文提供了理论分析和实践步骤,并通过案例研究总结了经验教训。进
金融服务领域的TLS 1.2应用指南:合规性、性能与安全的完美结合

# 摘要
随着金融服务数字化转型的加速,数据传输的安全性变得愈发重要。本文详细探讨了TLS 1.2协议在金融服务领域的应用,包括其核心原理、合规性要求、实践操作、性能优化和高级应用。TLS 1.2作为当前主流的安全协议,其核心概念与工作原理,特别是加密技术与密钥交换机制,是确保金融信息安全的基础。文章还分析了合规性标准和信息安全威胁模型,并提供了一系列部署和性能调优的建议。高级应用部
约束优化案例研究:分析成功与失败,提炼最佳实践
# 摘要
约束优化是数学规划中的一个重要分支,它在工程、经济和社会科学领域有着广泛的应用。本文首先回顾了约束优化的基础理论,然后通过实际应用案例深入分析了约束优化在实际中的成功与失败因素。通过对案例的详细解析,本文揭示了在实施约束优化过程中应该注意的关键成功因素,以及失败案例中的教训。此外,本文还探讨了约束优化在实践中常用策略与技巧,以及目前最先进的工具和技术。文章最终对约束优化的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )