NoSQL数据库入门指南:理解非关系型数据库的优势与应用
发布时间: 2024-05-26 02:19:16 阅读量: 89 订阅数: 38 

主流NOSQL数据库之MongoDB快速入门.docx
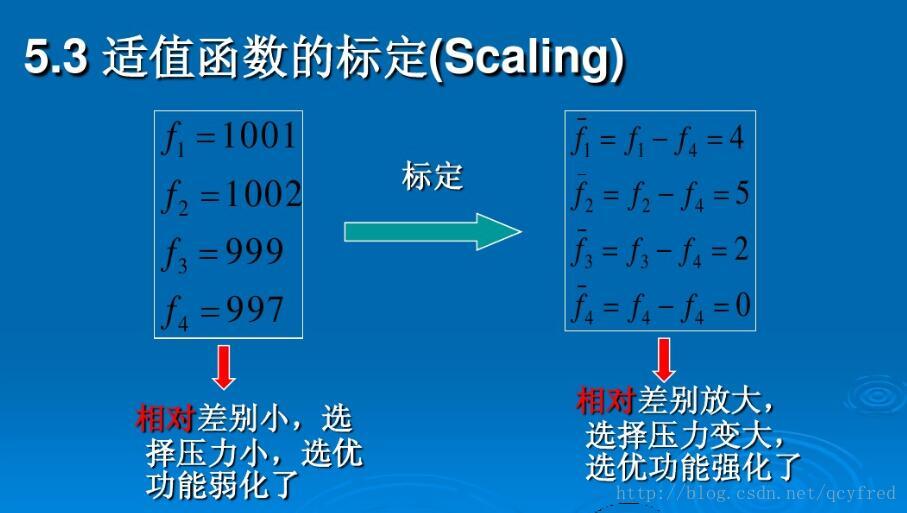
# 1. NoSQL数据库概述**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它打破了传统关系型数据库的限制,提供了更灵活、可扩展和高性能的数据存储解决方案。与关系型数据库相比,NoSQL数据库具有以下主要优势:
- **数据模型灵活性:**NoSQL数据库支持各种数据模型,如文档、键值对、列族和图,可以灵活适应不同类型的数据结构和查询模式。
- **可扩展性和高可用性:**NoSQL数据库通常采用分布式架构,可以轻松扩展以处理海量数据,并通过数据复制和故障转移机制确保高可用性。
# 2. NoSQL数据库类型
### 2.1 文档型数据库
文档型数据库以文档的形式存储数据,文档可以包含各种数据类型,如字符串、数字、数组和嵌套对象。这种数据模型提供了极大的灵活性,允许存储复杂和结构化的数据。
**2.1.1 MongoDB**
MongoDB是最流行的文档型数据库之一。它提供了一个灵活的数据模型,允许用户创建自定义的文档结构。MongoDB还支持丰富的查询语言,可以对文档进行复杂查询。
**代码块:**
```javascript
// 创建一个 MongoDB 客户端
const MongoClient = require('mongodb').MongoClient;
// 连接到数据库
MongoClient.connect('mongodb://localhost:27017', (err, client) => {
if (err) throw err;
// 获取数据库
const db = client.db('my_database');
// 创建一个文档
const doc = { name: 'John Doe', age: 30 };
// 将文档插入到集合中
db.collection('users').insertOne(doc, (err, result) => {
if (err) throw err;
console.log(`文档插入成功:${result.insertedId}`);
});
});
```
**逻辑分析:**
这段代码使用 MongoDB 客户端连接到数据库,并创建一个名为 `my_database` 的数据库。然后,它创建一个文档,并将其插入到名为 `users` 的集合中。`insertOne()` 方法返回一个结果对象,其中包含插入文档的 ID。
**2.1.2 CouchDB**
CouchDB是另一个流行的文档型数据库。它基于Apache CouchDB项目,提供了一个分布式和可复制的数据存储。CouchDB还支持MapReduce查询,这使其非常适合处理大数据集。
### 2.2 键值存储数据库
键值存储数据库使用键值对来存储数据。键是唯一的标识符,而值可以是任何类型的数据。这种数据模型非常简单,但它提供了快速和高效的数据访问。
**2.2.1 Redis**
Redis是最流行的键值存储数据库之一。它提供了一个内存中的数据存储,可以实现极高的性能。Redis还支持各种数据类型,如字符串、列表、哈希和集合。
**代码块:**
```javascript
// 创建一个 Redis 客户端
const redis = require('redis');
// 连接到 Redis 服务器
const client = redis.createClient();
// 设置一个键值对
client.set('name', 'John Doe', (err, reply) => {
if (err) throw err;
console.log(`键值对设置成功:${reply}`);
});
// 获取一个键值
client.get('name', (err, reply) => {
if (err) throw err;
console.log(`键值获取成功:${reply}`);
});
```
**逻辑分析:**
这段代码使用 Redis 客户端连接到 Redis 服务器,并创建一个键值对。`set()` 方法将键 `name` 设置为值 `John Doe`。`get()` 方法获取键 `name` 的值。
**2.2.2 Memcached**
Memcached是另一个流行的键值存储数据库。它是一个开源的、高性能的内存缓存系统。Memcached非常适合缓存经常访问的数据,以提高应用程序的性能。
### 2.3 列族数据库
列族数据库以列族组织数据。列族是一组相关的列,可以存储不同类型的数据。这种数据模型非常适合存储大量结构化数据。
**2.3.1 HBase**
HBase是最流行的列族数据库之一。它是一个开源的、分布式的、基于 Hadoop 的数据库。HBase提供了一个可扩展和高可用的数据存储,非常适合处理大数据集。
**代码块:**
```java
// 创建一个 HBase 客户端
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoo
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了数据库性能优化和管理的方方面面。从入门指南到高级调优技巧,涵盖了 MySQL 数据库性能优化的各个阶段。专栏还提供了表锁问题分析、分库分表策略以及 NoSQL 数据库入门和实战指南。通过深入了解数据库健康状况、调优工具和最佳实践,本专栏旨在帮助数据库管理员和开发人员优化数据库性能,提高数据处理效率,并应对数据量激增等挑战。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SSD1309 OLED驱动开发速成:从入门到精通的完整教程

# 摘要
本文提供了SSD1309 OLED驱动开发的全面概述,涵盖了基础理论、开发实践、高级应用以及故障排除与维护。首先介绍了SSD1309 OLED驱动的理论知识,包括OLED显示技术原理、芯片规格和接口要求。随后,文章详细说明了开发环境的搭建、编程语言选择以及基本和高级显示功能的实现方法。高级应用章节讨论了字符图像处理、用户界面设计和系统集成优化。最后,探讨了故障诊断、系统更新维护以
【特斯拉Model 3终极指南】:电气系统全面精通攻略
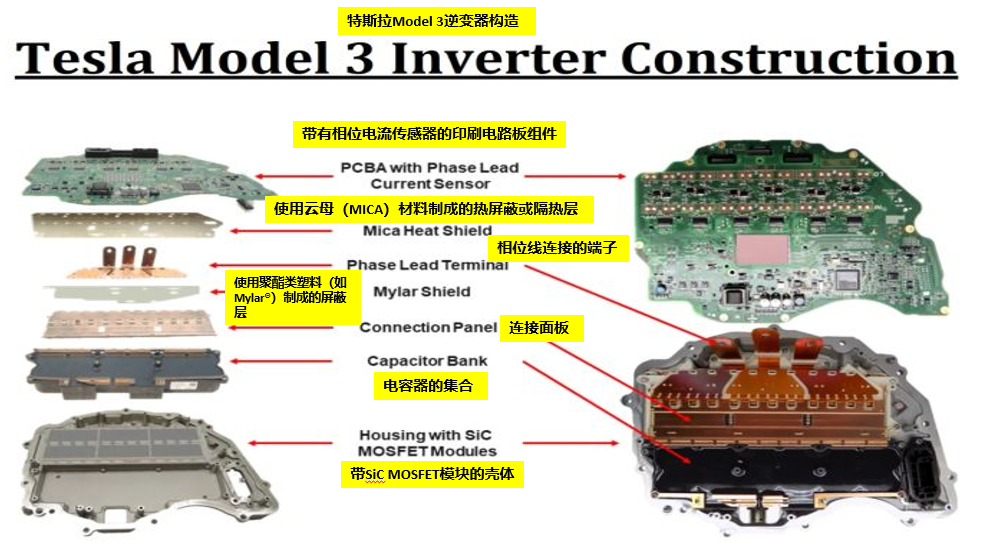
# 摘要
本文全面探讨了特斯拉Model 3的电气系统,涵盖了从基础理论到实际应用的各个方面。首先概述了电动汽车电气系统的基本理论,包括动力系统的结构原理、充电技术和高级电气功能。接着深入实践,讨论了日常维护、性能优化、故障排除和应急处理方法。进一步介绍了特斯拉Model 3在电子控制单元(ECU)编程、先进驾驶辅助系统(
【数据同步大揭秘】:KingSCADA3.8与ERP无缝对接指南
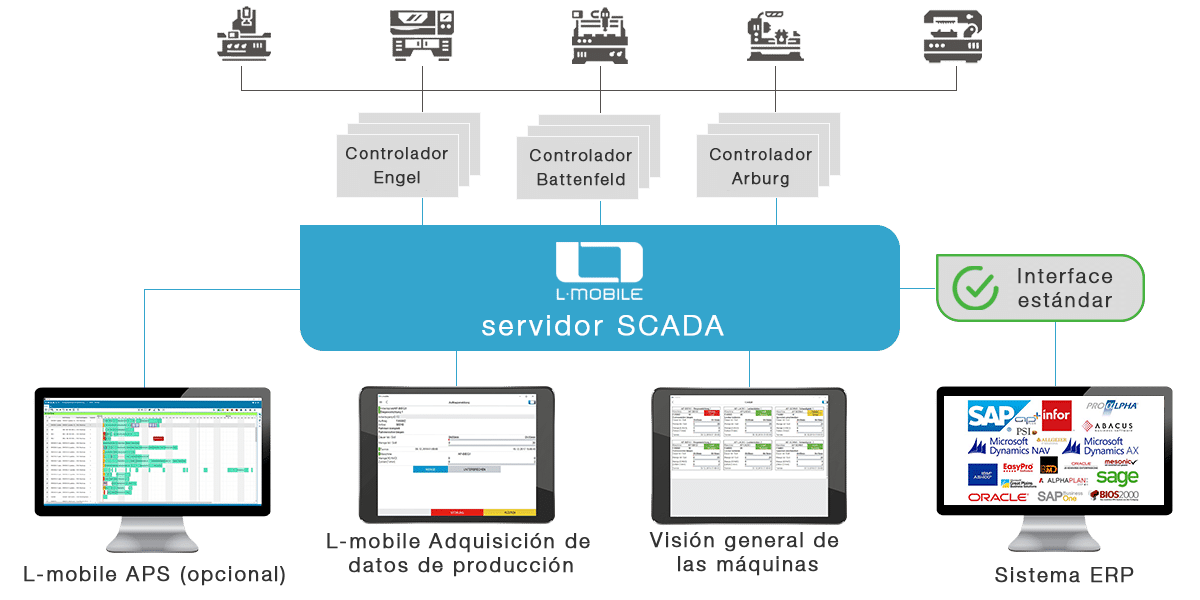
# 摘要
本论文深入探讨了数据同步的概念及其在现代信息系统中的重要性,特别是KingSCADA3.8平台与ERP系统的集成要点。通过对KingSCADA3.8的基础架构、核心特性和数据管理等关键技术的解析,本文揭示了ERP系统数据管理的核心功能及其在企业中的作用。此外,本文详细阐述了KingSCADA3.8与ERP系统实现数据同步的策略、技术、配置与部署方法,并通过案例研究
【负载均衡与扩展性】:构建可扩展的在线考试系统实战指南

# 摘要
本文深入探讨了负载均衡与扩展性的基础理论,并结合实践操作,详细讲解了负载均衡策略的理论与应用。通过分析不同负载均衡算法,如轮询、加权轮询、最少连接、加权最少连接以及响应时间算法,本文揭示了负载均衡器的实现技术,包括硬件与软件负载均衡器及云服务解决方案。文章进一步阐述了构建可扩展在线考试系统架构的系
Swiper自定义分页器秘籍:12个技巧让你的网站动态起来

# 摘要
本文全面介绍了Swiper分页器的基础知识、自定义理论、实践技巧及在不同场景中的应用。首先,对Swiper分页器的结构、工作原理及其API进行概述,并探讨了自定义分页器的基本组成和关键概念。接着,详细阐述了在商品展示、博客和新闻网站以及移动端网站中应用Swiper分页器的方法和优化技术。此外,本文还讨论了Swiper分页器进阶开发中的第三方库
【华为OLT MA5800故障排除】:快速解决网络问题的20个技巧

# 摘要
本文详细探讨了华为OLT MA5800的故障排除方法,涵盖了从故障诊断的理论基础到软硬件故障处理的实用技巧。通过对设备的工作原理、故障排除的流程和方法论的介绍,以及常规检查和高级故障排除技巧的阐述,本文旨在为技术人员提供全面的故障处理指南。此外,通过实践案例的分析,本文展示了如何应用故障排除技巧
【'Mario'框架实战秘籍】:手把手教你编写和运行第一个测试案例

# 摘要
本文全面介绍了'Mario'测试框架,包括其核心概念、安装步骤、测试用例的编写与管理,以及如何在不同项目环境中应用和扩展该框架。文章首先对'Mario'框架进行了简介,并详细描述了如何设置第一个测试案例,包括理解框架的断言机制和测试用例的结构。接着,深入探讨了高级功能,例如数据驱动测试、测试用例管理和自动化测试的实施策略。此外,文章还分析了'Mario'框架在敏捷开发和大型项目中的应用实例,并分享了
【数据安全策略】:Solr数据备份与恢复的终极指南
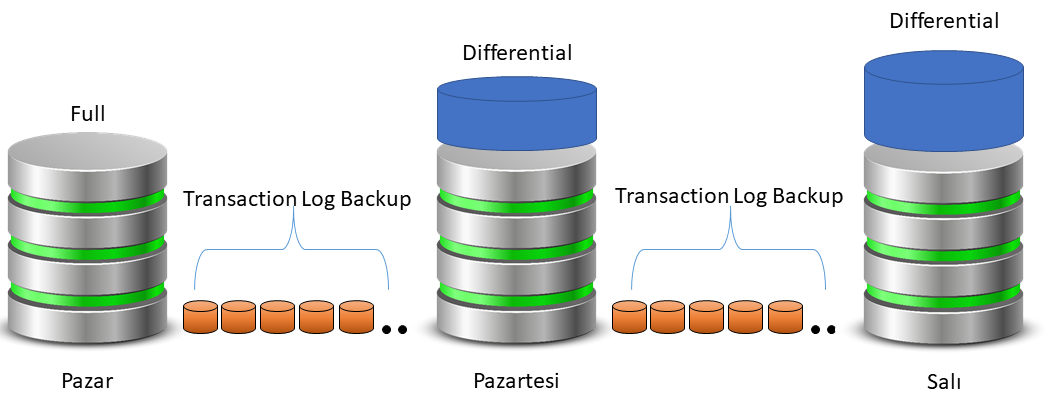
# 摘要
数据安全对于任何企业来说都是至关重要的,而Solr作为一种流行的搜索引擎,其数据备份与恢复机制尤为关键。本文首先介绍了数据安全的重要性以及Solr的基本概念。随后,详细探讨了Solr数据备份的策略,包括备份的定义、类型、配置自动备份流程和手动备份方法,以及备份数据的存储与管理。接着,本文深入分析了Solr数据恢复机制,包括恢复流程和策略的介绍、故障场景的模拟与处理,以及实际恢复实例的详
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )