【Django文件处理终极指南】:从入门到精通,提升你的文件处理技能
发布时间: 2024-10-13 01:35:42 阅读量: 35 订阅数: 40 

# 1. Django文件处理基础
## 1.1 文件处理的重要性
在Web开发中,文件处理是一个不可或缺的功能,它涉及到用户上传的文件存储、管理以及下载等多个方面。Django作为一款强大的Python Web框架,提供了丰富的内置功能来支持文件的处理。
## 1.2 Django中的文件处理组件
Django内置了`django.core.files`模块,其中包含了处理文件上传和存储的核心组件。它允许开发者处理用户上传的文件,包括图片、文档等,并提供了一套机制来存储这些文件。
## 1.3 文件上传的步骤
实现文件上传的基本步骤包括:在表单中添加文件上传字段、处理表单提交、保存文件到服务器。以下是一个简单的示例代码:
```python
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
from django.views.decorators.http import require_POST
from .forms import UploadFileForm
import os
@require_POST
@csrf_exempt
def upload_file(request):
form = UploadFileForm(request.POST, request.FILES)
if form.is_valid():
file = request.FILES['file']
# 文件保存逻辑
file_path = os.path.join('uploads', file.name)
with open(file_path, 'wb+') as f:
for chunk in request.FILES['file'].chunks():
f.write(chunk)
return HttpResponse('File uploaded successfully.')
return HttpResponse('Upload failed.')
```
在这个例子中,我们首先定义了一个处理POST请求的视图函数`upload_file`,它使用了`UploadFileForm`来验证上传的文件,并将文件保存到服务器的`uploads`目录中。
# 2. Django文件上传处理
## 2.1 Django中的文件上传机制
### 2.1.1 Django表单与文件上传
在本章节中,我们将深入了解Django如何通过表单处理文件上传。文件上传是Web应用中常见的需求,Django通过内置的表单类来支持文件上传功能,提供了简单而强大的方式来处理这一需求。
#### 基本原理
Django表单上传机制基于HTML的`<input type="file">`元素。当用户选择文件后,浏览器会将文件内容以及表单中的其他数据一起发送到服务器。在服务器端,Django的表单类可以处理这些数据。
#### 示例代码
```python
from django import forms
from django.http import HttpResponseRedirect
from django.shortcuts import render
class UploadFileForm(forms.Form):
title = forms.CharField(max_length=50)
file = forms.FileField()
def upload(request):
if request.method == 'POST':
form = UploadFileForm(request.POST, request.FILES)
if form.is_valid():
# 在这里处理上传的文件
# ...
return HttpResponseRedirect('/success/')
else:
form = UploadFileForm()
return render(request, 'upload.html', {
'form': form
})
```
#### 代码逻辑解读分析
- **UploadFileForm类**定义了一个表单,其中包含一个文本字段`title`和一个文件字段`file`。
- **upload视图**处理POST请求,接收表单数据和文件数据。
- **form.is_valid()**验证表单数据是否有效。如果有效,则可以访问`request.FILES`来获取上传的文件。
#### 参数说明
- `forms.CharField`定义了一个文本输入字段,`max_length`参数限制了输入的最大长度。
- `forms.FileField`定义了一个文件上传字段。
### 2.1.2 ModelForm与文件上传
ModelForm是Django提供的一个快捷方式,用于创建基于模型的表单。它简化了数据的验证和保存过程,同样支持文件上传。
#### 基本原理
通过定义一个继承自`forms.ModelForm`的类,可以创建一个表单,它将直接映射到模型的字段。文件字段同样可以被包含在ModelForm中。
#### 示例代码
```python
from django.forms import ModelForm
from .models import Document
from django.shortcuts import render
class DocumentForm(ModelForm):
class Meta:
model = Document
fields = ['title', 'file']
def upload_document(request):
if request.method == 'POST':
form = DocumentForm(request.POST, request.FILES)
if form.is_valid():
form.save()
return HttpResponseRedirect('/success/')
else:
form = DocumentForm()
return render(request, 'upload_document.html', {
'form': form
})
```
#### 代码逻辑解读分析
- **DocumentForm类**定义了一个ModelForm,映射到`Document`模型的`title`和`file`字段。
- **upload_document视图**处理文件上传,使用ModelForm来简化数据处理流程。
#### 参数说明
- `ModelForm`的`Meta`类中的`model`属性指定了对应的模型。
- `fields`属性定义了包含在表单中的模型字段。
## 2.2 文件存储系统
### 2.2.1 默认文件存储系统
Django提供了灵活的默认文件存储系统,允许开发者自定义文件的存储方式。默认情况下,所有上传的文件都会存储在服务器的文件系统中。
#### 基本原理
Django的`DEFAULT_FILE_STORAGE`设置定义了文件存储的后端。默认情况下,使用的是`django.core.files.storage.FileSystemStorage`类,它将文件存储在`MEDIA_ROOT`设置所指定的目录。
#### 示例代码
```python
from django.conf import settings
from django.core.files.storage import FileSystemStorage
def save_file(request):
fs = FileSystemStorage()
file_name = fs.save('example.txt', request.FILES['myfile'])
return file_name
```
#### 代码逻辑解读分析
- **FileSystemStorage**实例化了一个默认的文件存储对象。
- `save`方法将文件内容保存到服务器,并返回文件的名称。
#### 参数说明
- `MEDIA_ROOT`设置指定文件存储的根目录。
- `FileSystemStorage`类提供了存储文件的方法。
### 2.2.2 自定义文件存储系统
当默认的文件存储系统不满足需求时,可以自定义存储系统来满足特定的需求,例如将文件存储到远程服务器或云存储服务。
#### 基本原理
通过继承`django.core.files.storage.Storage`类,可以创建一个自定义的存储类。这个类必须实现几个特定的方法,例如`save`和`open`。
#### 示例代码
```python
from django.core.files.storage import Storage
import boto
class S3Storage(Storage):
def __init__(self, access_key, secret_key, bucket):
self.access_key = access_key
self.secret_key = secret_key
self.bucket = bucket
self.connection = boto.connect_s3(self.access_key, self.secret_key)
def _open(self, name, mode='rb'):
# 实现文件的打开逻辑
pass
def _save(self, name, content):
# 实现文件的保存逻辑
pass
# 其他必要的方法...
```
#### 代码逻辑解读分析
- **S3Storage类**继承了`Storage`类,并实现了`_open`和`_save`方法。
- 这个类可以用来将文件存储到Amazon S3。
#### 参数说明
- `access_key`和`secret_key`是AWS的认证密钥。
- `bucket`是存储文件的S3桶。
## 2.3 文件安全性处理
### 2.3.1 文件验证和清理
在文件上传过程中,验证和清理上传的文件是非常重要的步骤,以确保安全性和防止恶意攻击。
#### 基本原理
Django提供了内置的验证机制,可以在ModelForm中使用`clean_<field_name>`方法来验证上传的文件。
#### 示例代码
```python
from django.core.exceptions import ValidationError
from .models import Document
class DocumentForm(ModelForm):
class Meta:
model = Document
fields = ['title', 'file']
def clean_file(self):
file = self.cleaned_data.get('file')
if file.content_type not in ['application/pdf', 'image/jpeg']:
raise ValidationError('Invalid file type')
return file
```
#### 代码逻辑解读分析
- `clean_file`方法验证上传文件的MIME类型。
- 如果文件类型不符合要求,将抛出`ValidationError`。
#### 参数说明
- `clean_<field_name>`方法用于验证特定的字段。
### 2.3.2 文件权限和访问控制
除了验证上传的文件外,还需要控制对文件的访问权限,确保只有授权的用户可以访问或下载文件。
#### 基本原理
可以通过中间件、装饰器或视图逻辑来实现文件访问权限的控制。
#### 示例代码
```python
from django.http import Http404
from .models import Document
def document_download(request, doc_id):
try:
document = Document.objects.get(id=doc_id)
except Document.DoesNotExist:
raise Http404
if not request.user.is_authenticated:
raise Http404
if not request.user.has_perm('documents.view_document', document):
raise Http404
# 文件下载逻辑...
```
#### 代码逻辑解读分析
- **document_download视图**检查用户是否认证并且是否有权访问文件。
- 如果用户未通过检查,则抛出`Http404`异常。
#### 参数说明
- `is_authenticated`属性检查用户是否登录。
- `has_perm`方法检查用户是否有特定的权限。
# 3. Django文件下载实现
## 3.1 文件响应与下载
在Web开发中,文件下载是一个常见的功能,用户可以通过点击链接下载文件。在Django中,文件下载的实现主要依赖于HTTP响应对象。我们将详细介绍如何在Django中实现文件响应与下载,包括静态文件的配置和动态文件下载的处理。
### 3.1.1 Django文件响应对象
Django提供了一个`FileResponse`类,它是`StreamingHttpResponse`类的一个子类,专门用于处理文件下载。`FileResponse`对象可以更高效地处理大文件,因为它支持HTTP/1.1的分块传输编码(chunked transfer encoding)。
```python
from django.http import FileResponse
def download_file(request, file_path):
with open(file_path, 'rb') as f:
return FileResponse(f, as_attachment=True, filename='example.txt')
```
在上述代码中,我们首先导入了`FileResponse`类,然后定义了一个`download_file`函数。该函数接收一个请求对象和文件路径作为参数,使用`with`语句打开文件,以二进制读取模式。`FileResponse`被初始化时,文件对象被传递给它,并且设置了`as_attachment=True`,告诉浏览器这是一个附件,会触发文件下载。`filename`参数用于指定下载文件的名称。
### 3.1.2 动态文件下载处理
有时候我们需要动态生成文件,比如基于用户输入或数据库中的数据。在这种情况下,我们需要构建文件内容,然后再将其发送给客户端。
```python
from django.http import FileResponse
import csv
def dynamic_download(request):
# 假设我们根据数据库中的数据生成CSV文件
data = [['Name', 'Age'], ['Alice', 24], ['Bob', 27]]
output = io.StringIO()
writer = csv.writer(output)
for row in data:
writer.writerow(row)
output.seek(0)
response = FileResponse(output, as_attachment=True, filename='data.csv')
return response
```
在这个例子中,我们首先导入了`FileResponse`和`csv`模块,然后定义了一个`dynamic_download`函数。这个函数创建了一个CSV格式的数据,并使用`io.StringIO`对象作为中间缓冲区。`csv.writer`用于将数据写入`StringIO`对象。之后,我们将文件指针重置到开始位置,以便从头开始读取数据。最后,我们创建了一个`FileResponse`对象,并将其返回给用户。
## 3.2 静态文件管理
静态文件是Web应用中的一类特殊文件,通常包括JavaScript、CSS、图片等。Django提供了一套静态文件管理系统,用于管理这些文件。
### 3.2.1 静态文件配置
在`settings.py`文件中,我们可以配置静态文件的存储路径和URL。
```python
# settings.py
STATIC_URL = '/static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static'),
]
STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')
```
- `STATIC_URL`定义了静态文件的URL前缀。
- `STATICFILES_DIRS`定义了Django在哪些目录中查找静态文件。
- `STATIC_ROOT`定义了在收集静态文件时,这些文件将被存储在哪里。
### 3.2.2 静态文件服务和CDN集成
为了提高性能,我们通常会使用内容分发网络(CDN)来服务静态文件。
```python
# settings.py
STATICFILES_STORAGE = '***pressedManifestStaticFilesStorage'
```
- `STATICFILES_STORAGE`定义了用于存储和服务静态文件的后端。`whitenoise`是一个Python库,它可以让你的服务静态文件,无需额外的Web服务器,如Nginx或Apache。
## 3.3 高级文件传输技术
除了基本的文件下载功能,Django还支持一些高级的文件传输技术,如分块传输编码和断点续传。
### 3.3.1 分块传输编码
分块传输编码允许服务器以多个块的形式发送文件,而不是一次性发送整个文件。这对于大文件下载非常有用,因为它可以减少服务器内存的使用。
```python
from django.http import StreamingHttpResponse
def stream_large_file(request, file_path):
with open(file_path, 'rb') as f:
stream = StreamingHttpResponse(f, content_type='application/octet-stream')
stream['Content-Disposition'] = 'attachment; filename="largefile.zip"'
return stream
```
在这个例子中,我们使用了`StreamingHttpResponse`类来创建一个响应对象。这个类允许我们以流的形式发送文件,而不是一次性加载到内存中。
### 3.3.2 断点续传实现
断点续传是一种文件传输技术,允许用户在下载中断后,从上次中断的地方继续下载,而不是重新开始。
```python
from django.http import FileResponse
def resume_download(request, file_path, start=0):
if 'Range' in request.headers:
range_header = request.headers['Range']
range_parts = range_header.replace('bytes=', '').split('-')
start = int(range_parts[0])
if len(range_parts) > 1:
end = int(range_parts[1])
else:
end = os.path.getsize(file_path) - 1
else:
end = os.path.getsize(file_path) - 1
with open(file_path, 'rb') as f:
f.seek(start)
data = f.read(end - start + 1)
response = FileResponse(data, content_type='application/octet-stream')
response['Content-Length'] = end - start + 1
response['Content-Range'] = f"bytes {start}-{end}/{os.path.getsize(file_path)}"
response['Accept-Ranges'] = 'bytes'
return response
```
在这个例子中,我们首先检查请求头中是否包含`Range`字段,该字段指定了用户希望下载的文件范围。然后,我们根据这个范围读取文件的一部分,并将其发送给用户。我们还设置了`Content-Length`、`Content-Range`和`Accept-Ranges`响应头,以支持断点续传。
通过本章节的介绍,我们了解了Django中文件下载的实现方式,包括使用`FileResponse`进行文件响应和下载,静态文件的配置和管理,以及如何实现分块传输编码和断点续传。这些知识点对于开发高性能的Web应用至关重要,可以有效地减少服务器负载,提高用户体验。
# 4. Django文件操作高级功能
在本章节中,我们将深入探讨Django框架中关于文件操作的高级功能,这些功能能够帮助开发者更有效地管理和处理项目中的文件资源。我们将从文件元数据处理开始,逐步了解如何进行文件系统交互,以及文件处理的最佳实践。
## 4.1 文件元数据处理
文件元数据提供了关于文件的额外信息,比如文件大小、类型、修改时间等。这些信息在文件管理和用户界面设计中至关重要。Django通过内置的方法提供了访问和操作这些元数据的手段。
### 4.1.1 文件大小、类型和修改时间
Django的`os.path`模块和标准库的`os`模块可以帮助我们获取文件的元数据。
```python
import os
# 获取文件大小
file_size = os.path.getsize('example.txt')
# 获取文件修改时间
file_modified_time = os.path.getmtime('example.txt')
# 获取文件类型
file_extension = os.path.splitext('example.txt')[1]
```
在上述代码中,我们使用了`os.path.getsize`方法来获取文件大小,`os.path.getmtime`来获取文件的最后修改时间,以及`os.path.splitext`来获取文件的扩展名,从而推断文件类型。
### 4.1.2 文件的读写权限
文件的读写权限是系统安全的重要组成部分。在Django中,我们可以使用标准库中的`os`模块来检查和修改文件权限。
```python
import os
# 检查文件是否存在且可读
if os.path.isfile('example.txt') and os.access('example.txt', os.R_OK):
print("The file exists and is readable.")
else:
print("The file doesn't exist or is not readable.")
# 设置文件权限
os.chmod('example.txt', 0o644) # 设置文件权限为 644
```
在上面的代码示例中,我们首先检查了一个文件是否存在并且可读,然后使用`os.chmod`方法设置了一个新的权限模式。`0o644`代表文件所有者具有读写权限,组用户和其他用户只有读权限。
## 4.2 文件系统交互
文件系统交互是指在Django项目中进行文件的创建、删除和重命名等操作。这些操作对于实现文件管理功能非常重要。
### 4.2.1 文件的创建、删除和重命名
在Django中,我们可以使用Python的`os`和`shutil`模块来执行文件的创建、删除和重命名操作。
```python
import os
import shutil
# 创建文件
with open('new_file.txt', 'w') as ***
***'Some text.')
# 删除文件
os.remove('new_file.txt')
# 重命名文件
shutil.move('old_file.txt', 'new_file.txt')
```
上述代码展示了如何使用`open`函数创建一个新文件并写入内容,使用`os.remove`删除文件,以及使用`shutil.move`来重命名文件。
### 4.2.2 目录遍历和文件搜索
目录遍历是指列出一个目录及其子目录中的所有文件和目录。文件搜索则是找到符合特定条件的文件。以下是一个简单的目录遍历和文件搜索的示例。
```python
import os
# 目录遍历
for root, dirs, files in os.walk('.'):
for name in files:
print(os.path.join(root, name))
# 文件搜索
def search_files(directory, pattern):
matches = []
for root, dirs, files in os.walk(directory):
for file in files:
if pattern in ***
***
***
* 使用文件搜索函数
found_files = search_files('.', '.txt')
for file in found_files:
print(file)
```
在这个代码段中,我们首先使用`os.walk`遍历当前目录及其子目录中的所有文件。然后定义了一个`search_files`函数来搜索所有包含特定模式的文件,并返回匹配的文件列表。
## 4.3 文件处理的最佳实践
文件处理的最佳实践包括性能优化和异常处理策略,这些都是确保文件操作高效和安全的关键。
### 4.3.1 文件处理性能优化
性能优化通常涉及减少不必要的磁盘I/O操作和优化文件处理逻辑。
```python
# 代码示例:使用with语句优化文件处理
with open('large_file.txt', 'r') as ***
***
* 代码示例:使用生成器避免大文件加载到内存
def read_large_file(file_path):
with open(file_path, 'r') as ***
***
***
* 使用生成器处理文件
for line in read_large_file('large_file.txt'):
# 处理每一行数据
```
在这个例子中,我们使用`with`语句来确保文件正确关闭,并且使用生成器来逐行读取大文件,从而避免一次性将整个文件加载到内存中。
### 4.3.2 文件处理异常处理策略
异常处理是确保文件操作健壮性的重要部分。我们应该始终处理可能发生的异常。
```python
try:
with open('nonexistent_file.txt', 'r') as ***
***
***"File not found.")
except Exception as e:
print(f"An error occurred: {e}")
```
在上述代码中,我们使用`try`和`except`块来捕获和处理文件操作中可能发生的`FileNotFoundError`和其他异常。
通过本章节的介绍,我们已经了解了Django中文件操作的高级功能,包括文件元数据处理、文件系统交互以及文件处理的最佳实践。这些高级功能对于开发复杂的文件处理逻辑和构建高效、安全的Django项目至关重要。在下一章中,我们将通过实际的项目案例来应用这些知识,并进一步探索Django项目中的文件处理实战技巧。
# 5. Django项目中的文件处理实战
## 5.1 多媒体文件处理
### 5.1.1 图像处理与优化
在Django项目中处理图像通常涉及以下几个步骤:上传、存储、处理以及优化。图像处理的目的是为了减少图像文件的大小,提高网站加载速度,同时保持图像质量。Python中有多个库可以帮助我们完成这项工作,比如Pillow。
#### 图像上传
首先,我们需要一个模型来处理图像上传:
```python
from django.db import models
class Photo(models.Model):
image = models.ImageField(upload_to='photos/%Y/%m/%d')
```
#### 图像存储
Django默认将文件存储在服务器的本地文件系统中。我们可以通过修改`settings.py`来改变存储方式,例如使用Amazon S3。
#### 图像处理
使用Pillow库,我们可以对图像进行裁剪、旋转、缩放等操作。以下是一个简单的图像缩放示例:
```python
from PIL import Image
from django.core.files.base import ContentFile
from io import BytesIO
def compress_image(image_field):
# 打开图像文件
image = Image.open(image_field)
output_io = BytesIO()
# 设置缩放尺寸
size = (128, 128)
# 缩放图像
image.thumbnail(size, Image.ANTIALIAS)
# 保存图像到内存
image.save(output_io, image_field.content_type)
# 创建一个新的ContentFile对象
return ContentFile(output_io.getvalue(), image_field.name)
```
#### 图像优化
图像优化通常涉及减少文件大小而不显著降低质量。我们可以使用Pillow的`save`方法,并指定`optimize=True`参数来实现。
```python
from PIL import Image
def optimize_image(image_path):
image = Image.open(image_path)
optimized_image = image.copy()
optimized_image.save(image_path, format='JPEG', optimize=True)
```
### 5.1.2 视频和音频文件处理
处理视频和音频文件通常比处理图像更复杂,因为它们的文件大小更大,处理起来需要更多的计算资源。
#### 视频处理
在Django中处理视频,我们可以使用`moviepy`库。以下是一个简单的视频裁剪示例:
```python
from moviepy.editor import VideoFileClip
def clip_video(video_path, start_time, end_time, output_path):
# 加载视频
clip = VideoFileClip(video_path)
# 裁剪视频
clip短视频 = clip.subclip(start_time, end_time)
# 输出视频
短视频.write_videofile(output_path)
```
#### 音频处理
对于音频文件,我们可以使用`pydub`库。以下是一个简单的音频文件合并示例:
```python
from pydub import AudioSegment
def merge_audio(audio_paths, output_path):
# 加载所有音频文件
audios = [AudioSegment.from_file(path) for path in audio_paths]
# 合并音频
merged = sum(audios, AudioSegment.silent)
# 输出音频
merged.export(output_path, format="mp3")
```
## 5.2 文件版本控制
### 5.2.1 文件版本管理的需求与实现
在Django项目中,文件版本控制可以帮助我们追踪文件的变更历史,特别是在多人协作的项目中。我们可以使用Git来实现版本控制,但在Django项目中,我们可能需要对文件的版本进行额外的管理。
#### 文件版本管理需求
- 跟踪文件的历史变更
- 恢复到旧版本
- 比较不同版本之间的差异
#### 文件版本控制实现
我们可以在Django的模型中添加一个字段来存储文件的版本信息,并使用Git作为版本控制工具。
```python
from django.db import models
class File(models.Model):
version = models.CharField(max_length=100)
content = models.FileField(upload_to='files/%Y/%m/%d')
```
### 5.2.2 文件哈希和一致性校验
为了确保文件的完整性和一致性,我们可以使用哈希算法来生成文件的哈希值。以下是使用SHA256算法的示例:
```python
import hashlib
def calculate_sha256(file_path):
sha256_hash = hashlib.sha256()
try:
with open(file_path, "rb") as f:
# 读取文件内容
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
except FileNotFoundError:
return None
```
## 5.3 文件处理自动化工具
### 5.3.1 Django命令行工具开发
在Django项目中,我们可以开发自定义的命令行工具来自动化文件处理任务。以下是一个简单的自定义命令示例:
```python
from django.core.management.base import BaseCommand
from django.conf import settings
import os
class Command(BaseCommand):
help = 'Process and optimize images'
def handle(self, *args, **options):
for root, dirs, files in os.walk(settings.MEDIA_ROOT):
for file in files:
if file.endswith('.jpg'):
image_path = os.path.join(root, file)
compressed_image = compress_image(image_path)
new_image_path = image_path.replace('.jpg', '_optimized.jpg')
with open(new_image_path, 'wb+') as f:
f.write(compressed_image.read())
self.stdout.write(f"Processed {file}")
```
### 5.3.2 自动化文件处理工作流
自动化文件处理工作流可以提高效率,减少重复劳动。我们可以使用Celery这样的任务队列来实现异步处理。
#### 工作流设计
1. 用户上传文件
2. 文件被存储在服务器上
3. 触发Celery任务处理文件
4. 文件处理完成后,将结果存储或发送到另一个服务
#### Celery任务定义
```python
from celery import shared_task
@shared_task
def process_file(file_path):
# 处理文件的逻辑
pass
```
#### Celery任务调度
```python
from celery.schedules import crontab
from celery.task import periodic_task
@periodic_task(run_every=crontab(minute='*/10'))
def schedule_process_files():
# 调度文件处理任务
pass
```
通过本章节的介绍,我们了解了在Django项目中如何进行多媒体文件的处理,包括图像和视频文件的处理方法,以及如何实现文件版本控制和自动化文件处理工作流。这些技能对于构建高效、可靠的Web应用是至关重要的。在下一章节中,我们将探索Django文件处理扩展库和未来趋势,进一步拓展我们的知识边界。
# 6. Django文件处理扩展与未来趋势
在本章中,我们将深入探讨Django文件处理的扩展库、前沿技术以及未来的发展趋势。这些内容将帮助你进一步扩展Django项目中的文件处理能力,并为未来的挑战做好准备。
## 6.1 文件处理扩展库
Django作为一个强大的框架,它提供了多种扩展库来帮助开发者更高效地处理文件。这些库不仅可以简化开发流程,还能提供额外的功能和性能优化。
### 6.1.1 第三方库介绍
Django社区有很多优秀的第三方库,它们可以用于文件的压缩、转换、分析等操作。例如:
- `django-allauth`:提供用户认证和社交登录功能,支持文件上传的用户认证。
- `django-picklefield`:允许在Django模型中存储和检索Python pickle对象。
- `django-storages`:为Django提供多个自定义存储后端,如Amazon S3、Google Cloud Storage等。
### 6.1.2 应用第三方库进行文件处理
让我们通过一个简单的例子来演示如何使用`django-storages`库将文件存储在Amazon S3上。
首先,安装`django-storages`和`boto3`(AWS SDK for Python):
```bash
pip install django-storages boto3
```
然后,在`settings.py`中配置S3存储:
```python
INSTALLED_APPS = [
...,
'storages',
...,
]
DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'
AWS_ACCESS_KEY_ID = 'your-access-key-id'
AWS_SECRET_ACCESS_KEY = 'your-secret-access-key'
AWS_STORAGE_BUCKET_NAME = 'your-bucket-name'
AWS_S3_REGION_NAME = 'your-region-name'
```
接下来,创建一个模型,使用`S3Boto3Storage`作为文件的存储系统:
```python
from django.db import models
from storages.backends.s3boto3 import S3Boto3Storage
class MyModel(models.Model):
file = models.FileField(storage=S3Boto3Storage())
```
通过这种方式,文件将被存储在指定的S3桶中,而不是本地服务器。
## 6.2 Django文件处理的前沿技术
随着技术的发展,Django文件处理也在不断进步,引入了许多前沿技术。
### 6.2.1 大文件处理技术
处理大文件时,需要考虑内存管理和性能优化。例如,可以使用以下方法:
- 分块读取和处理文件,避免一次性加载整个文件到内存。
- 使用异步任务队列(如Celery)来处理耗时的文件操作,提高响应速度。
### 6.2.2 云存储集成
随着云计算的普及,集成云存储服务成为了一个趋势。Django通过`django-storages`库可以轻松集成多种云存储服务,如AWS S3、Azure Blob Storage等。
## 6.3 文件处理的发展趋势
未来,文件处理技术将持续发展,带来新的挑战和机遇。
### 6.3.1 云原生架构对文件处理的影响
云原生架构强调模块化、可扩展性和弹性。在这样的架构下,文件处理将更加依赖于云服务,如:
- 使用云函数(如AWS Lambda)进行文件处理,无需管理服务器。
- 利用Kubernetes进行容器化部署,实现文件处理服务的自动化扩展。
### 6.3.2 文件处理安全性挑战与解决方案
随着文件处理需求的增长,安全问题也日益突出。以下是几个常见的安全性挑战和解决方案:
- **数据泄露**:确保所有文件传输都使用加密(如HTTPS)。
- **非法访问**:实施严格的访问控制和身份验证机制,如使用IAM角色。
- **恶意软件**:使用病毒扫描和内容过滤工具来防止恶意软件上传。
在本章中,我们探讨了Django文件处理的扩展库、前沿技术以及未来的发展趋势。这些知识将帮助你在Django项目中实现更高效、更安全的文件处理解决方案。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Django 文件处理的各个方面,提供从入门到精通的全面指南。它涵盖了 django.core.files 库的深度剖析,包括其文件存储机制和 API 使用技巧。专栏还提供了 Django 文件上传安全指南,确保高效且安全的上传功能。此外,它还介绍了 django.core.files 与 Celery 的实战应用,展示了异步文件处理的最佳实践。专栏还深入探讨了 Django 高级文件操作技巧、文件元数据应用、文件上传模型构建、文件存储后端自定义、数据库交互优化和文件流高效处理。最后,它提供了构建支持文件上传的 REST API 的技巧,并指导如何创建专业的文件管理后台界面。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【性能优化】:提升Virtex-5 FPGA RocketIO GTP Transceiver效率的实用指南
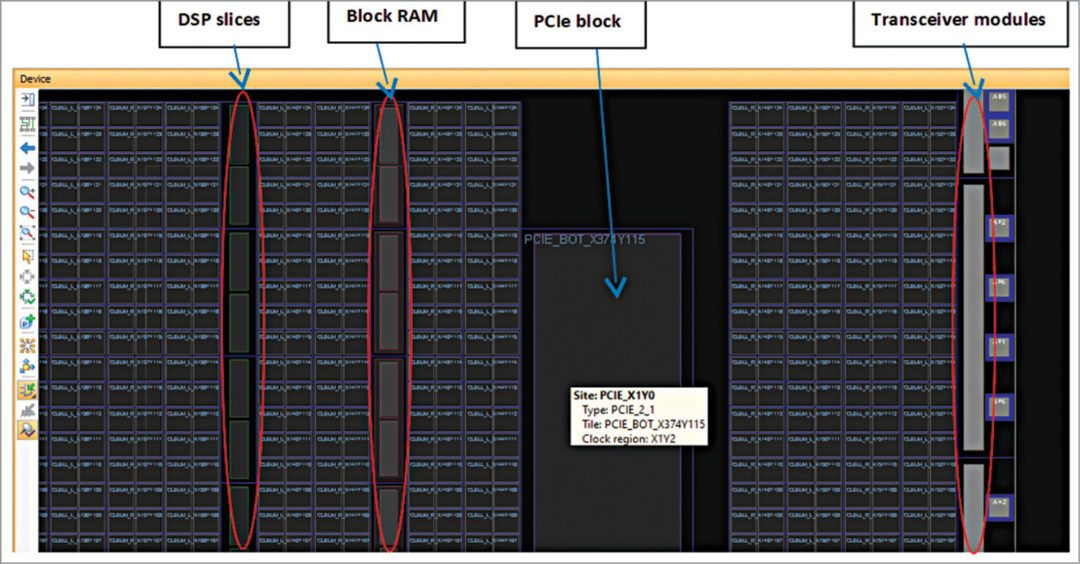
# 摘要
本文针对Virtex-5 FPGA RocketIO GTP Transceiver的性能优化进行了全面的探讨。首先介绍了GTP Transceiver的基本概念和性能优化的基础理论,包括信号完整性、时序约束分析以及功耗与热管理。然后,重点分析了硬件设计优化实践,涵盖了原理图设计、PCB布局布线策略以及预加重与接收端均衡的调整。在固件开发方面,文章讨论了GTP初始化与配置优化、串行协议栈性能调优及专用IP核的
【LBM方柱绕流模拟中的热流问题】:理论研究与实践应用全解析

# 摘要
本文全面探讨了Lattice Boltzmann Method(LBM)在模拟方柱绕流问题中的应用,特别是在热流耦合现象的分析和处理。从理论基础和数值方法的介绍开始,深入到流场与温度场相互作用的分析,以及热边界层形成与发展的研究。通过实践应用章节,本文展示了如何选择和配置模拟软
MBIM协议版本更新追踪:最新发展动态与实施策略解析

# 摘要
随着移动通信技术的迅速发展,MBIM(Mobile Broadband Interface Model)协议在无线通信领域扮演着越来越重要的角色。本文首先概述了MBIM协议的基本概念和历史背景,随后深入解析了不同版本的更新内容,包括新增功能介绍、核心技术的演进以及技术创新点。通过案例研究,本文探讨了MB
海泰克系统故障处理快速指南:3步恢复业务连续性
# 摘要
本文详细介绍了海泰克系统的基本概念、故障影响,以及故障诊断、分析和恢复策略。首先,概述了系统的重要性和潜在故障可能带来的影响。接着,详细阐述了在系统出现故障时的监控、初步响应、故障定位和紧急应对措施。文章进一步深入探讨了系统
从零开始精通DICOM:架构、消息和对象全面解析
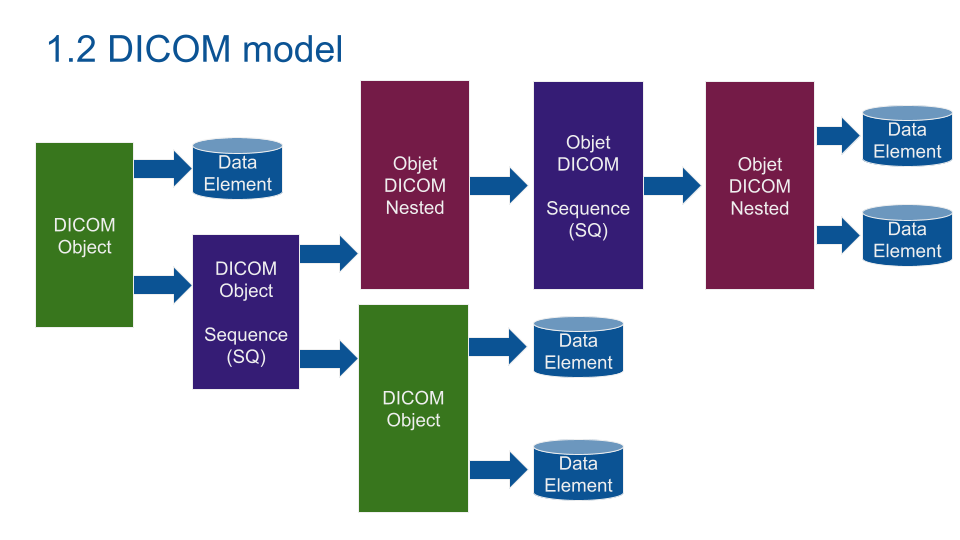
# 摘要
DICOM(数字成像和通信医学)标准是医疗影像设备和信息系统中不可或缺的一部分,本文从DICOM标准的基础知识讲起,深入分析了其架构和网络通信机制,消息交换过程以及安全性。接着,探讨了DICOM数据对象和信息模型,包括数据对象的结构、信息对象的定义以及映射资源的作用。进一步,本文分析了DICOM在医学影像处理中的应用,特别是医学影像设备的DICOM集成、医疗信息系统中的角色以及数据管理与后处理的
配置管理数据库(CMDB):最佳实践案例与深度分析

# 摘要
本文系统地探讨了配置管理数据库(CMDB)的概念、架构设计、系统实现、自动化流程管理以及高级功能优化。首先解析了CMDB的基本概念和架构,并对其数据模型、数据集成策略以及用户界面进行了详细设计说明。随后,文章深入分析了CMDB自
【DisplayPort over USB-C优势大揭秘】:为何技术专家力荐?

# 摘要
DisplayPort over USB-C作为一种新兴的显示技术,将DisplayPort视频信号通过USB-C接口传输,提供了更高带宽和多功能集成的可能性。本文首先概述了DisplayPort over USB-C技术的基础知识,包括标准的起源和发展、技术原理以及优势分析。随后,探讨了在移动设备连接、商
RAID级别深度解析:IBM x3650服务器数据保护的最佳选择

# 摘要
本文全面探讨了RAID技术的原理与应用,从基本的RAID级别概念到高级配置及数据恢复策略进行了深入分析。文中详细解释了RAID 0至RAID 6的条带化、镜像、奇偶校验等关键技术,探讨了IBM x3650服务器中RAID配置的实际操作,并分析了不同RAID级别在数据保护、性能和成本上的权衡。此外,本文还讨论了RAID技术面临的挑战,包括传统技术的局限性和新兴技术趋势,预测了RAID在硬件加速和软件定义存储领域的发展方向。通过对RAID技术的深入
【jffs2数据一致性维护】

# 摘要
本文全面探讨了jffs2文件系统及其数据一致性的理论与实践操作。首先,概述了jffs2文件系统的基本概念,并分析了数据一致性的基础理论,包括数据一致性的定义、重要性和维护机制。接着,详细描述了jffs2文件系统的结构以及一致性算法的核心组件,如检测和修复机制,以及日志结构和重放策略。在实践操作部分,文章讨论了如何配置和管理jffs2文件系统,以及检查和维护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )